Methodology


1) Difference-in-Differences (DiD)
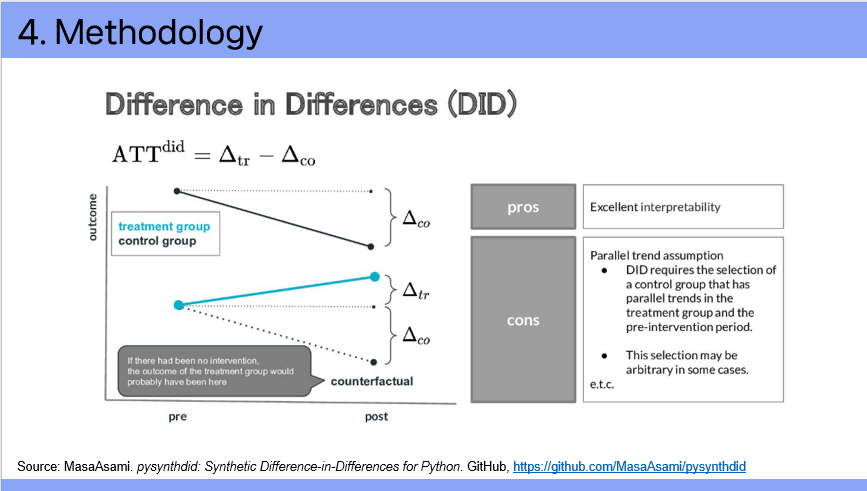
When we have data from both before and after an intervention and want to isolate the impact of the intervention from general trends, one common method is Difference-in-Differences. DID is widely used in policy evaluations.
The idea is to use another city as a control group to estimate the counterfactual—what would have happened in Incheon if the policy had not been implemented.
Specifically, the DID estimator imputes Incheon's post-policy birth rate as the pre-policy birth rate plus a growth factor, which we estimate using the control city.
But this relies on a key assumption: that pre-treatment trends in both cities are similar.
If Incheon’s trend was already different before the policy, the DiD estimate may be biased.
So, to check this, we can plot past birth rate trends.
If the trends don’t align, it means DiD is not a reliable method in this case.
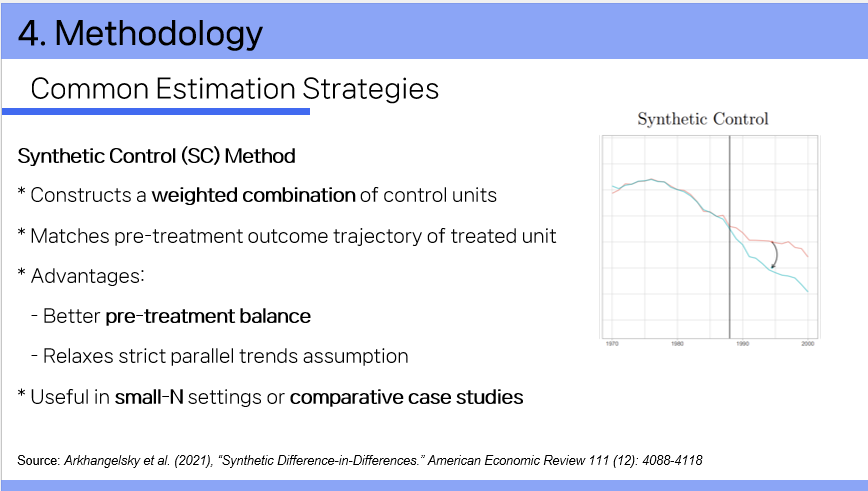
2) Synthetic Control (SC)
To address this problem, we use Synthetic Control, another powerful causal inference method.
Instead of using just one control city, we build a synthetic version of Incheon by combining several other cities.
This synthetic control closely follows Incheon’s birth rate trend before the intervention.
We then compare Incheon’s actual trend to the synthetic one after the policy is introduced.
The gap between the two reflects the treatment effect.
This method allows more flexibility than DiD.
The effect doesn’t have to appear immediately—it can change over time.
And the combination of cities often gives us a more accurate counterfactual than any single city alone.


3) Synthetic-Diff-in-Diff (SDID)
Synthetic Difference-in-Differences, combines the strengths of both DiD and SC.
Like SC, SDID works even when pre-treatment trends are not parallel.
And like DiD, it uses fixed effects for units and time, which helps reduce estimation variance.
SDID also introduces several new features:
It adds an L2 penalty during optimization, which spreads the unit weights more evenly across cities.
It also includes time weights, which are not present in either DID or SC.
Together, these features make SDID more robust in estimating treatment effects.














4) Inference: placebo test
To test whether the estimated effect is statistically significant, we use a placebo test based on Fisher’s exact framework.
We simulate ‘placebo effects’ by pretending control units received the treatment.
We then compare Incheon’s estimated effect to these placebo effects.
If Incheon’s effect is larger than most placebo estimates, we consider the result statistically significant.
We also construct confidence intervals using placebo variance estimation.
We repeatedly run placebo tests, each time pretending a different control unit was treated.
Then we use SDID to estimate those placebo treatment effects.
This process gives us a distribution of effects under the null hypothesis, which we use for inference.