-
Layer의 재사용에 대하여Research/NLP_YS2024 2024. 12. 3. 23:48
3개의 논문에서 제시하는 모델은 각각 다른 쓰임새와 독특한 특징을 보여주지만
기저에 관통하는 공통된 concept이 있어서 흥미롭다.
"Reusing early layers"
early layer의 feature representation을 leveraging함으로써 efficiency & performance improvement를 추구한다.
내가 동경하는 이상적 논문 형태
"simple but effective!"
1. Efficient Transfer Learning driven by Layer-wise Features Aggregation
https://openreview.net/pdf?id=Q0tfRYadhc
https://github.com/MLAI-Yonsei/LFA
* Motivation
Transfer learning make it possible to leverage learned patterns from pre-trained model to new tasks with less data and training time. But it is challanging to adapt large-scale pre-trained model efficiently to downstream task.
* Previous methods
Prompt-tuning, Adapter, LoRA optimize models using smaller datasets and parameters.
* Limitation of previous methods
performance improvement & efficiency are limited. Although these methods freeze the pre-trained parameters, it is still required gradients to pass through the entire model thereby requires computational resources. In addition, these methods only focus on final layer, and ignore the useful features from earlier layers.
* Proposed method: LFA (Layer-wise Feature Aggregation)
LFA employs an attention mechanism that dynamically weights and aggregates features across all layers, allowing the model to focus on the most relevant features for a given task while leveraging the abundant information available. The paper also theoretically verifys that the low-level features are robust and invariant to domain shifts.
* Contributions
(1) Transfer learning performance improvement
by capturing hierarchical features from low-level to high-level, LFA improve performance on both domain shift and few-shot scenarios.
(2) Transfer learning efficiency
it only requires optimization on top of large pre-trained model thereby does not need to backpropagate through entire model. reducing training time and memory usage.
(3) Transfer learning flexibility
easily applicable with existing CLIP-based SOTA models.
* Details
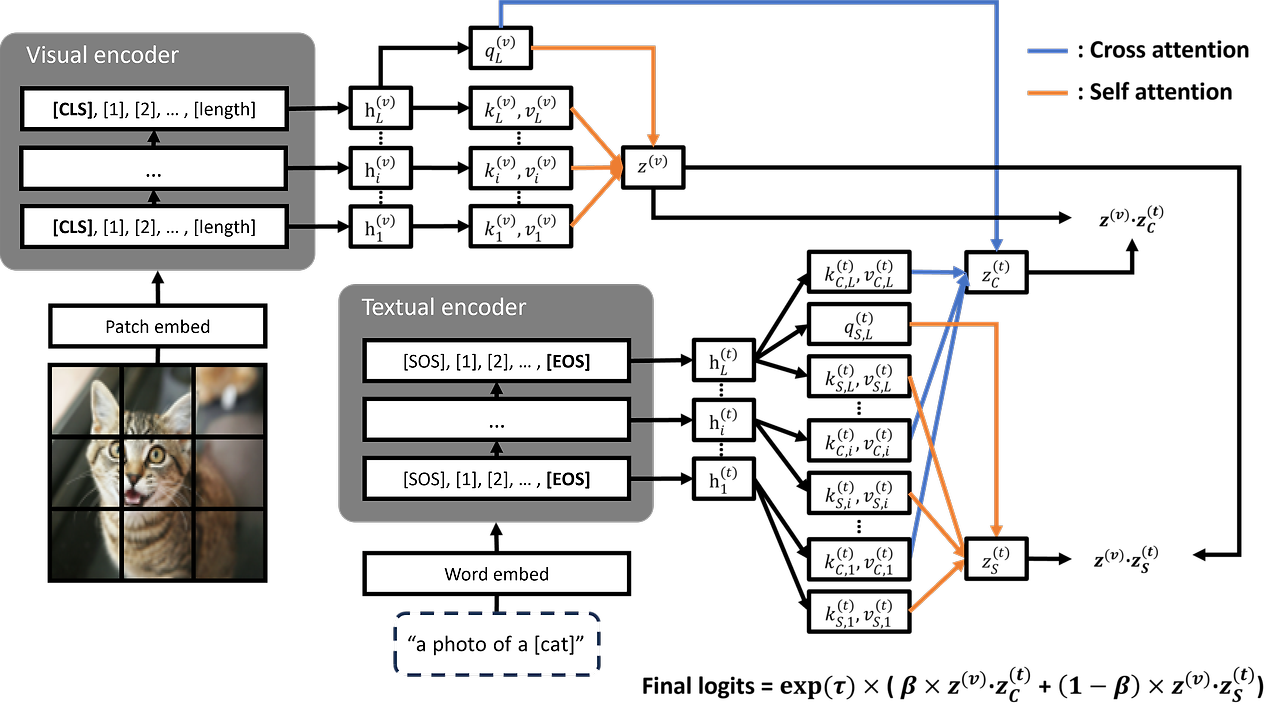
(1) Feature Extraction
For visual part, use hidden state of CLS token, and for textual part, use hidden state of EOS token that might contain context information.
(2) Attention-Based Feature Aggregation
- For each modality, use self-attention to aggregate relavant information across all layers. Querying the last layer's feature vector and activate the appropriate layers according to the training input data.
- For alignment between two modalities, use cross-attention to enhance textual features by incorporating visual information.
(3) Merge Similarities and Prediction
- The attention outputs from both modalities are merged using a hyperparameter β, balancing the contributions of self-attention and cross-attention and logits are calculated.
* Experiments
(1) Domain Generalization
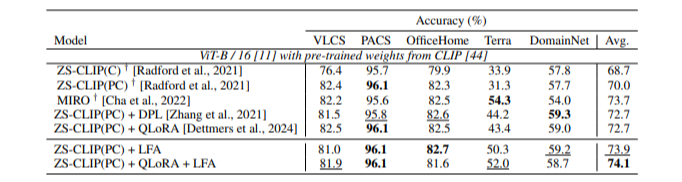
CLIP+LFA outperforms other models on the PACS and OfficeHome datasets and achieves the highest average performance.
(2) Few-shot Image Classification
Evaluated LFA's impact on pre-trained CLIP-based models, including Zero-Shot CLIP, LinearProbing CLIP, CoOp, CLIP-Adapter, and MaPLe.

(3) Learning Efficiency
Evaluated the model's computational and memory efficiency by measuring the peak memory usage during a single epoch and recording the number of learnable parameters on the DomainBed benchmark.
LFA and LinearProbing CLIP does not extend backpropagation through the pre-trained CLIP model, thereby demonstrate superior learning efficiency compared to the DPL method which allows backpropagation through the pretrained model.
The paper suggests "CLIP + LFA*" which reduces the count of trainable parameters by applying LoRA to attention mechanism. Specifically, initialize the weight matrices Wq, Wk, Wv using the pretrained projection matrices from CLIP and freeze them. And incorporate the learnable update weight matrices △Wq, △Wk, △Wv by adding them to the initialized weight matrices. Each update weight matrix is composed of the product of low rank matrices A and B. By adjusting the rank, the trade-off between learning performance and the number of learned parameters can be controlled.

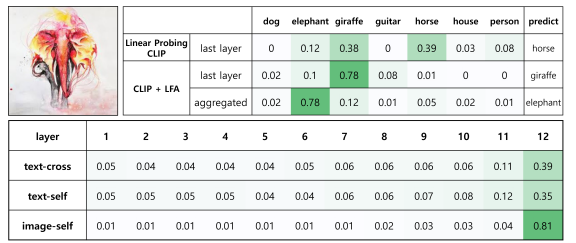
(4) Qualitative Result
LFA method which aggregates and utilizes features extracted from each layer, exhibits robust domain generalization performance.
* Conclusion
- LFA method leverages logits from multiple layers through attention mechanism and improves Domain Generalization performance.
- Since experiments focus on the CLIP-based models, future work should extend LFA's application to other models and tasks and further optimize it for larger models and resource-constrained environments.
* Code review
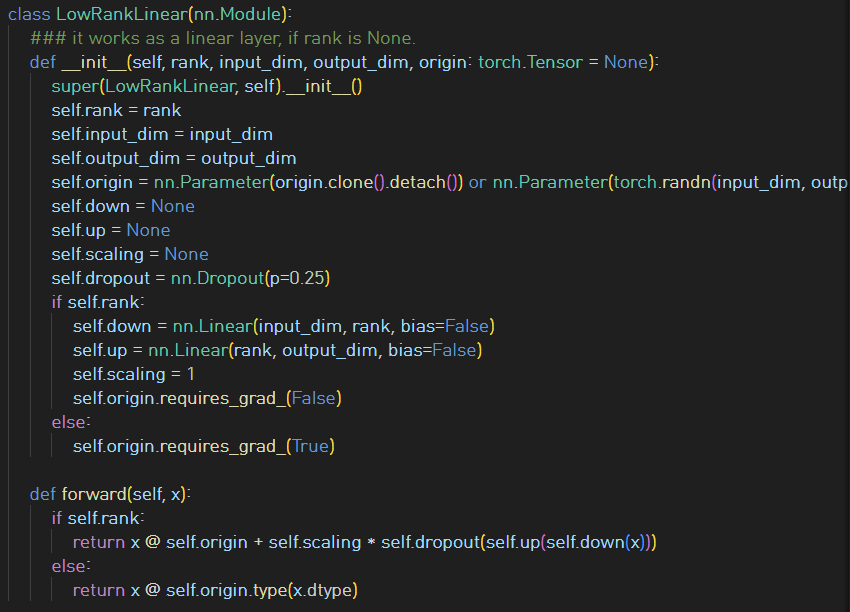
특이하게도.. projection layer가 low rank approximation을 할 수 있도록 구현되어 있다.
아.. 좋다..
좋아요. 좋은 거 배웠습니다.
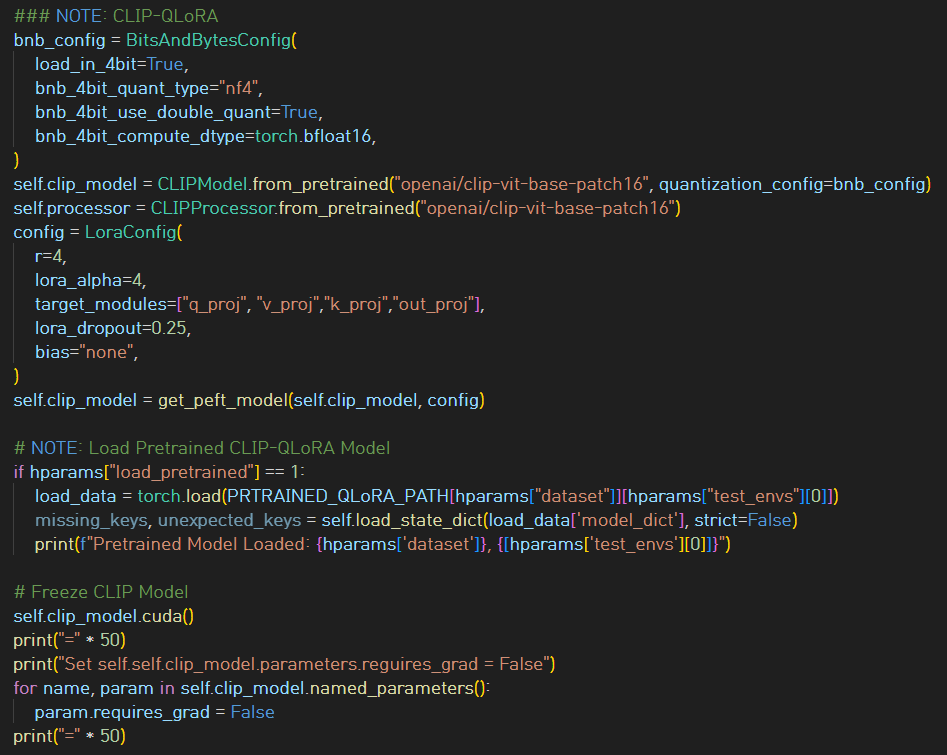
4bit로 double quantize하고 nf4 type을 사용한다.
전반적으로 efficiency에 상당히 신경을 많이 쓴 느낌이 든다.

forward pass를 거치며 각 layer의 attention block output을 받아온다.


self & cross-attention

final logit 계산
이 아름다운 코드들은 누가 짜셨을까..
paper에 사전 지식에 대한 언급이 없으셔서, 선행 연구 공부하고, 코드도 뒤져보고 돌아왔습니다.. ㅎㅎ
나처럼 사전 지식이 없는 사람은 MaPLe을 본 후에 본 논문을 보면 이해가 잘 될 것 같다.
MaPLe이 아주 상세하면서 github에 필요한 모든 코드가 잘 정리되어 있다. baseline들과 함께 training, testing 전반적으로 다 코드를 돌려보고 싶은 분들에게는 MaPLe git이 아주 요긴할 것 같다.
2. TroL: Traversal of Layers for Large Language and Vision Models
(EMNLP 2024)
https://arxiv.org/pdf/2406.12246v3
https://github.com/ByungKwanLee/TroL* Motivation
In order to bootstrap the vision language performances of large language and vision models (LLVMs), several studies have increased the model sizes or employing additional modules. However, directly scaling the model size up or using additional modules may not be considered a fundamental solution to enlarging learning capabilities regarding complex question-answering pairs. This is because they physically add a considerable number of training parameters or borrow richer knowledge from external modules. In addition, these models have a large number of layers and demand costly, high-end resources for both training and inference. It remains unexplored how LLVMs with smaller model sizes can effectively enhance learning capabilities despite their inherent physical limitations. Further research into the intrinsic mechanisms of LLVMs without scaling models or leveraging additional modules is needed.
* Proposed method: TroL (Traversal of Layers)
The paper present an efficient LLVM family with 1.8B, 3.8B and 7B LLM model sizes, Traversal of Layers (TroL), which enables the reuse of layers in a token-wise manner.
To overcome the limitations of smaller-sized LLVMs, TroL opt to increase the number of forward propagations rather than physically adding more layers. This technique, layer traversing, allows LLVMs to retrace and re-examine the answering stream, akin to human retrospection and careful thought before responding with an answer.
TroL-Mixer serves as the token-wise mixing operation under lightweight additional parameters: 49K, 98K and 131K in total layers which is significantly tiny number compared with the 1.8B, 3.8B and 7B model sizes.
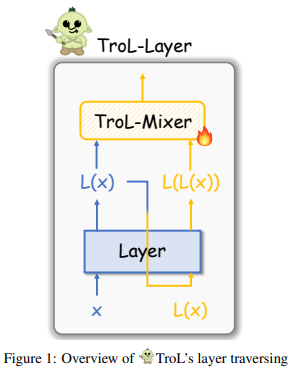
To successfully apply layer traversing to LLVMs, the authors employ a two-step training process.
The first step involves training a vision projector and all TroL-Mixers for each TroL-Layer. The first step not only aligns vision and language information but also tunes the TroL-Mixers with the answering stream in backbone multimodal LLMs, thereby facilitating the use of layer traversing.
The second step includes further training of these components along with the backbone multimodal LLMs. To achieve efficient training, the authors use Q-LoRA for the backbone multimodal LLMs under 4/8-bit quantization.
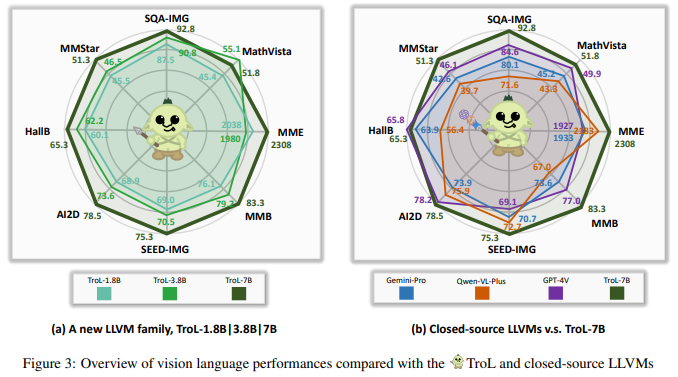

* Contributions
(1) Efficiency
introducing an efficient LLVM family—1.8B, 3.8B, and 7B, Traversal of Layers (TroL), which enables the reuse of layers, simulating the effect of retracing the answering stream.
(2) Superior performance
TroL proves its superior effectiveness on various evaluation benchmarks compared with substantially sized open- and closed-source LLVMs without directly scaling up the model size and without any additional modules.
* Details
(1) Model Architecture
- TroL is composed of a vision encoder, a vision projector, and a backbone multimodal large language model (MLLM) based on a pre-trained LLM.
- Vision encoder: CLIP-L, and Intern ViT for the vision encoder, which are text-aligned vision encoders based on image-text contrastive learning with a small text encoder (CLIP) and QLLaMA-8B (Intern ViT), respectively.
- Vision projector: two fully-connected layers with the GELU activation function.
- backbone multimodal LLM: Phi-3-mini with a 3.8B model size, and InternLM2 with 1.8B and 7B model sizes. 3.3T and 2T tokens are used during the pre-training of these LLMs, respectively.
(2) Visual Instruction Tuning Dataset
- gathering a wide range of visual instruction tuning datasets requiring diverse capabilities such as fundamental image understanding, common-sense knowledge, non-object concepts (e.g., charts, diagrams, documents, signs, symbols), math problems, and their integrated capabilities to make TroL encompass diverse capabilities for vision language tasks.
- selectively choose samples from existing visual instruction tuning datasets: ShareGPT4V-Caption/Instruct, ALLaV4V-Text, MiniGemini-Instruct, Doc-Downstream/Reason, GLLaVA-Align/Instruct, and Math-Vision/Instruct/Plus.
- Collect 899K real-world image/text-only samples, 627K samples for documents, charts, diagrams, signs, and symbols, and 747K math samples (180.5K with images and 566.8K text-only), the number of visual instruction tuning samples used to build TroL totals 2.3M samples.
(3) Layer Traversing

1) input token x ∈ R^N×D (i.e. vision language features), where N denotes the number of tokens and D denotes the hidden dimension of a layer, is given, then a layer outouts L(x) from the input token.
2) Layer traversing makes the output of the layer forward in the equal layer once again: L(L(x)).
3) TroL-Mixer provides a mixing operation with L(x) and L(L(x)), where TroL Gating is introduced to determine how much reused vision language feature L(L(x)) is needed for the next layer, by looking at the feature status of the first propagation output L(x). More specifically, the output L(x) is propagated into the TroL Gating and it produces a mixing ratio w ∈ R^N for each token. It is used for token-wise multiplication ⊙ with L(x) and L(L(x)).
4) The mixed output (1 − w) ⊙ L(x) + w ⊙ L(L(x)) propagate to the next layer and it is continually operated as it goes layers.
The layer traversing stimulate the effect of retracing and looking back at the answering stream once again, thereby enlarging the learning capabilities.
(4) Training Strategy
TroL-Layer is appllied to backbone multimodal LLMs. A Two-step training process was conducted to effectively implement layer traversing, creating a LLVM family named TroL.
1) First step: training a vision projector and all TroL-Mixers for every TroL-Layer. It is essential for aligning vision and language information while synchronizing the TroL-Mixers with the response stream in the backbone multimodal LLMs, thus facilitating the understanding of layer traversing operation.
2) Second step: additional training of above elements alongside the backbone multimodal LLMs together.
* Experiments
(1) Implementation Detail
1) Backbone multimodal LLMs: Phi-3-mini 3.8B consists of 32 layers with hidden dimension of 3072, and InternLM2 1.8B | 7B features 24 | 32 layers with hidden dimension of 2048 | 4096, respectively.
2) Vision encoders: CLIP-L, and Intern ViT each comprising 428M | 300M parameters, with 24 layers and hidden dimension of 1024.
3) Vision projector: consists of an MLP that adjusts the hidden dimension from 1024 to 2048 | 3072 | 4096 to match the hidden dimension of backbone multimodal LLMs. This MLP contains two fully-connected layers with GELU activation.
4) TroL Gating: a single fully-connected layer that converts the hidden dimension from 2048 | 3072 | 4096 to 1, resulting in a total of 2048 x 24 = 49K, 3072 x 32 = 98K, and 4096 x 32 = 131K parameters for each.
5) The training and evaluation of TroL are conducted with 8xNVIDIA Tesla A100 80GB and 8xNVIDIA RTX A6000 48GB, each.
6) To optimize the training process, use one epoch of training for each step under 4/8-bit quantization and bfloat16 data type for each backbone multimodal LLM: TroL-1.8B (4-bit), TroL-3.8B (8-bit), and TroL-7B (4-bit). The 4-bit quantization employs double quantization and normalized float 4-bit (nf4). QLoRA is used to train the multimodal LLMs with 64 rank and 64 alpha parameters.
7) Adam W optimizer, cosine annealing to schedule the learning rate from 1e-4 to 1e-6 in each training step.
8) Gradient checkpointing. With gradient accumulation of 6, batch sizes are totally set to 768 for each training step, and each step takes approximately one to three days.
9) For inference, validate TroL under the same quantization bit, employ deterministic beam search (n=5) for text generation, apply layer traversing technique only to the user questions.
10) FlashAttention2 for speed-up attention computation.
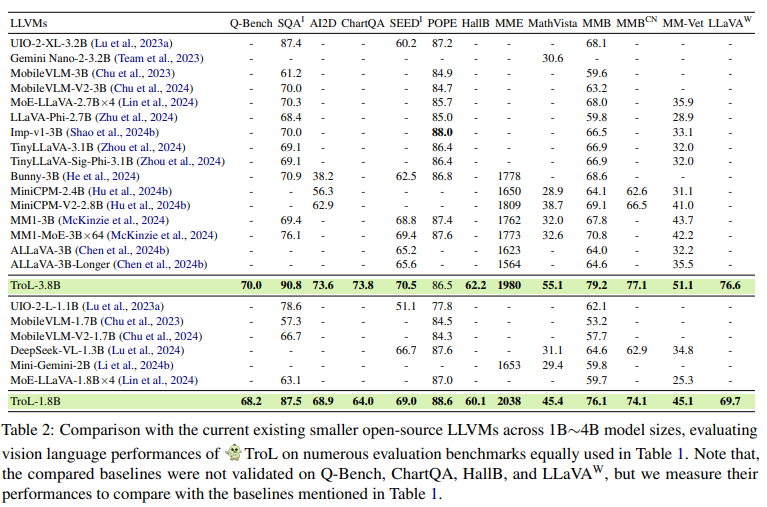
(2) Validation on Evaluation Benchmarks
Despite limited model size, TroL demonstrated super vision language performances, which is attributed to the enhanced learning capabilities by layer traversing.
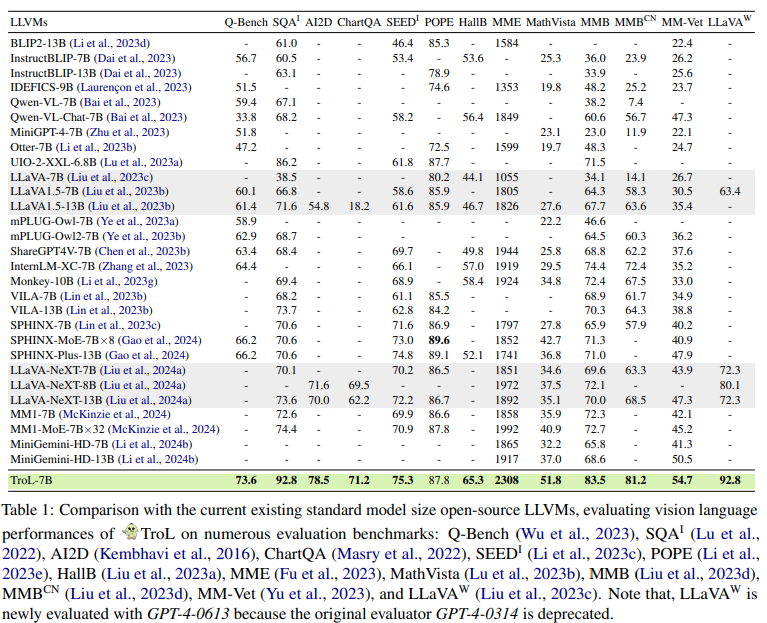


* Conclusion
- A new LLVM family, TroL, has demonstrated significant advancements in vision language performance despite its inherent limitation of having smaller layers compared to larger model sizes in both open- and closed-source LLVMs.
- reusing layers through layer traversing can be an effective alternative to incorporating additional modules.
- when analyzing all mixing ratios for each layer, the layer traversing event of looking back and retracing the answering stream mostly occurs in shallower layers, while the deeper layers are not involved in traversing. This suggests that recursively enhancing vision language features continues until they are fully matured.
이건 LFA에서 early layer를 leveraging하는 것이 중요하다는 걸 강조한 것과 상통한다!
- Advanced techniques beyond quantization for reducing the training computational burden should be further developed to enable the AI community to handle large models more effectively.
- Future research might equip TroL with numerous bootstrapping methods.
* Code review


3. Dense Connector for MLLMs
(NeurlPS 2024)
https://arxiv.org/pdf/2405.13800v1
https://github.com/HJYao00/DenseConnector/blob/main/README.md* Motivation
Recently, MLLMs have demonstrated outstanding performance in multimodal understanding. However, the focus has predominantly been on the linguistic side, without fully utilizing the potential of the visual encoder in MLLMs. While larger and higher-quality instruction datasets, as well as larger LLMs, have evolved, visual signals have been underutilized by MLLMs, often being reduced to the final high-level features extracted by a frozen visual encoder.
* Proposed method: Dense Connector
In addition to the common practice of feeding the connector with final high-level visual features from visual encoder, an intuitive yet overlooked idea is to integrate visual features from various layers to complement the high-level features.
Attention maps from different layers of a 24-layer CLIP pretrained ViT-L show that different layers of the same visual encoder emphasize different regions of interest.
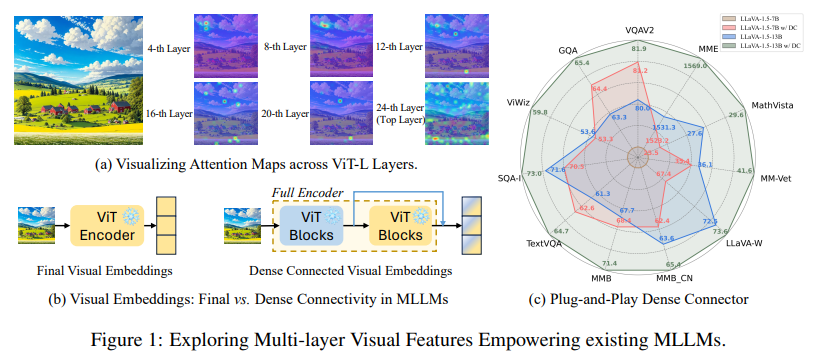
The paper introduces the Dense Connector - a simple, effective, and plug-and-play vision-language connector that significantly enhances exsting MLLMs by leveraging multi-layer visual features, with minimal additional computational overhead.
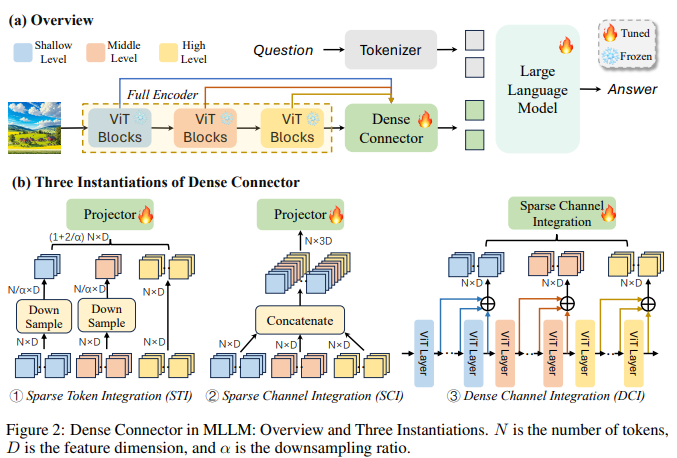
The paper propose three instantiations for the Dense Connector:
(1) Sparse Token Integration (STI): explicitly increase the number of visual tokens by aggregating visual tokens from different specified layers and the final visual token. These tokens are fed into a learnable projector for mapping into the text space.
(2) Sparse Channel Integration (SCI): to avoid increasing the number of tokens, concatenate visual tokens from different specified layers in the feature dimension. They are then passed to the projector, which not only maps visual tokens into the text space but also serves to reduce the feature dimensionality.
(3) Dense Channel Integration (DCI): In addition to incorporating features from specified layers, further utilize visual features from all layers.
All of instantiations yield significant improvements while utilizing just one simple learnable projector (comprising two linear layers) without introducing any extra parameters.
Experimental results across various vision encoders, image resolutions, training dataset scales, varying sizes of LLMs and diverse architectures of MLLMs validate the versatility and scalability of proposed method, achieving state-of-the-art performance on across 19 image and video benchmarks.
* Contributions
(1) simple, effective, and plug-and-play Dense Connector
- enhances the visual representation of existing MLLMs with minimal additional computational overhead.
(2) versatility and scalability
- across various visual encoders, image resolutions (336px → 768px), training dataset scales, varying sizes of LLMs (2B→70B), diverse MLLMs architectures (e.g., LLaVA, Mini-Gemini).
(3) Performance improvement
- exhibits exceptional performance across 11 image benchmarks and achieves state-of-the-art results on 8 video benchmarks without tne need for specific video tuning.
* Details
(1) Model Architecture
1) Visual Encoder: utilize a CLIP pre-trained Vision Transformer (ViT) as the visual encoder for extracting visual features. ViT partitions an image Xi ∈ R H×W×C into a sequence of non-overlapping patches. Each patch is then processed via convolution to produce visual tokens, which are subsequently input into ViT. This procedure yields L layers of visual features V ∈ R L×N×Dv , where N denotes the number of the visual tokens and Dv denotes the feature dimension.
2) Dense Connector: comprises two components. The first integrates multi-layer visual features, the second employs a learnable MLP to map the integrated visual features to the LLM's text space. The MLP consists of two linear layers with a GELU activation function sandwiched between them. The first layer adjusts the visual hidden size Dv to align with the LLM’s hidden dimension Dt, while the second layer maintains the dimensionality at Dt. Upon processing through the Dense Connector, we acquire visual embeddings ev ∈ R N×Dt that encapsulate information from multiple layers.
3) Large Language Model: The LLM processes textual data using a tokenizer and text embedding module to convert language into its input feature space. These text embeddings are concatenated with transformed visual embeddings before being fed into the LLM for subsequent predictions.
(2) Dense Connector
While existing methods typically rely solely on features from the final layer as the visual representation input for the LLM, DC approach diverges from this by integrating features from multiple layers to enrich the visual input for the LLM.
Sparse Token Integration (STI) and Sparse Channel Integration (SCI) sparsely select visual features from K layers out of the total L layers of ViT, while Dense Channel Integration (DCI) utilizes features from all layers. These features are then fed into Dense Connector to generate visual embedding that can be "understood" by LLM.
Recognizing that higher-level features contain richer semantic information crucial for visual signal perception in VLMs, we maintain the final layer features unchanged while downsampling additional visual features from other layers by using average pooling with a stride α. This downsampling reduces the number of visual tokens to N′ = N/α, mitigating computational overhead and redundancy.
1) Sparse Token Integration (STI): Visual features from various layers are concatenated along the token dimension and processed through a shared MLP(·), yielding more robust visual embedding ev ∈ R (N+(k−1)×N′ )×Dt :

2) Sparse Channel Integration (SCI): connecting multi-level features along the channel dimension. Subsequently, this feature is processed through an MLP projector to obtain visual embedding ev ∈ R N×Dt :

3) Dense Channel Integration (DCI): Concatenating all visual feature layers using STI or SCI leads to excessively high dimensions, posing challenges during training. To address these issues, we propose DCI, which builds upon the SCI method by integrating adjacent layers to reduce redundancy and high dimensionality. This approach ensures dense connectivity across a wider range of visual layers. Specifically, we partition the features of L layers into G groups, where each group comprises M adjacent visual features, with M = L/G. Summing the features within each group, denoted as GVg, finally yields G fused visual representations:
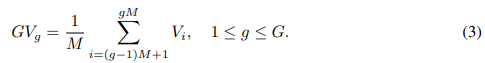
Subsequently, we concatenate these features from the G groups with the final layer’s features along the channel dimension before passing them through an MLP:

* Experiments
(1) Implementation Details
1) Architecture
- Visual Encoders: CLIP-ViT-L-336px, SigLIP-ViT-SO
- LLMs: s Phi-2-2.7B, Vicuna-7B&13B, Hermes-2-Yi-34B, Llama3-8B&70B-Instruct
- Dense Connector: for 24-layer CLIP-ViT-L-336px, 8th, 16th, and final 24th layers for both STI and SCI. For STI, downsampling factor of α = 8 for the features from the 8th and 16th layers. For DCI, divide all layer features into two groups, each containing 12 layers.
2) Training Dataset
- LLaVA-1.5 pre-training dataset comprises 558K image captions, instruction tuning dataset contains 665K conversations.
- Mini-Gemini builds upon LLaVA-1.5, offering a larger dataset with 1.2M image-text caption pairs for alignment and 1.5M conversations for instruction tuning.
3) Training Recipe
- training all models on 8 Nvidia A100 GPUs with 40GB VRAM, except for the 70B model, which utilizes 16 Nvidia A100 GPUs with 80GB VRAM.
- training process comprises two stages: pre-training and instruction fine-tuning.
- pre-training phase: initialize the visual encoder and LLM with pre-trained weights, while the Dense Connector is randomly initialized. Freeze the visual encoder and the LLM, updating only the parameters of the Dense Connector. The model undergoes pre-training for one epoch with a global batch size of 256 and a learning rate of 1e-3.
- instruction fine-tuning stage: maintain the visual encoder frozen while updating the Dense Connector and the LLM. Fine-tuning is performed for 1 epoch with a global batch size of 128 and a learning rate of 2e-5. When scaling up the LLM to larger parameter sizes, such as Hermes-2-Yi-34B and LLama-3-70B-Instruct, due to memory constraints, freeze the LLM and utilize LoRA for fine-tuning. Set the LoRA rank to 128 and LoRA alpha to 256.
4) Evaluation
- comprehensive results across various image evaluation benchmarks.
- GQA, VQAV2, SQAI, TextVQA, POPE, MathVista, MMBench, MM-Vet, MMMU, LLaVA-Bench-In-the-Wild, MME.
(2) Main Results
1) Comparison with SoTAs in Image Understanding
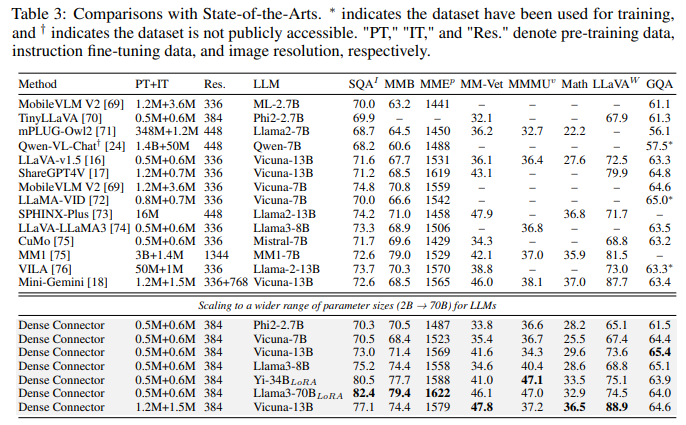
- scale the LLMs from 2.7B to 70B parameters and compare them with state-of-the-art MLLMs. When considering lightweight models, Dense Connector surpasses the previous state-of-the-art MLLM, TinyLlava, achieving a 1.7% enhancement on the MM-Vet benchmark using the same fine-tuning data and foundation model. Furthermore, using same training data and LLM, Dense Connector outperforms the LLaVA-1.5, Vicuna 13B with substantial gains of 2.1%, 3.7%, and 5.5% on the GQA, MMB, and MM-Vet benchmarks, respectively. Notably, even with data solely from LLaVA-1.5, our 13B model achieves performance comparable to state-of-the-art high-resolution models, such as Mini-Gemini, which are trained on larger datasets, including 1.2M+1.5M data. Moreover, utilizing the state-of-the-art open-source LLM Llama3-8B-Instruct, our model significantly surpasses LLAVALLama3 with improvements of 5.5%, and 52 on MMB, and MMEp, respectively, highlighting the contribution of our Dense Connector. By scaling up the LLM to 34B and 70B, our Dense Connector achieves further improvements leveraging more powerful language models. Our 70B model attains scores of 82.4% on SQA and 79.4% on MMBench. However, due to computational limitations, we employ LoRA fine-tuning for both the 34B and 70B models, which may impact the performance. In the future, we plan to provide results with full fine-tuned LLM.
2) Qualitative Results

* Conclusion
- Dense Connector: a plug-and-play module that enhances visual perception capabilities of MLLMs by densely integrating multi-layer visual features.
- Instantiating three types of Dense Connector and validating the efficacy of it across a diverse array of vision encoders, LLMs, and training datasets, demonstrating substantial improvements in performance across multiple evaluation benchmarks.
- Dense Connector can be easily integrated into existing MLLMs.
- By incorporating the Dense Connector into LLaVA and Mini-Gemini, demonstrating its versatility and generalization capabilities.
- Future research will focus on discovering more efficient ways to connect visual and language models for better modality alignment.
* Code review
on-going
My Thoughts
정말 흥미진진하게 3개의 technique을 살펴보았다!
각각의 module이 적용되는 target task는 다르지만, previous layer를 leveraging하여 efficiency와 performance boost를 지향한다는 공통점이 있다.
그리고 그 목적을 구현하는 방식이 서로 다르다는 게 관전 포인트.
LFA는 attention mechanism을 적용하여 low-level부터 high-level까지 features들을 capture하여 좀 더 풍부한 information을 추출함으로써 domain-shift와 few-shot learning scenario에서의 performance를 향상시켰고, 이에 더불어 back-propagation이 top-level에서만 이루어질 수 있으므로 efficiency까지 두 마리 토끼를 모두 잡았다.
visual representation이 final layer에만 의존하지 않고, multiple layer의 features를 integrating함으로써 더 풍부한 정보를 LLM에 넣어준다는 것은 DC와 LFA의 공통점이다.
다만, DC는 relevant한 정보만을 extract하는 방식이 아닌, 명시적으로 previous layer의 hidden representation들을 concatenate했다. concatenate을 token dimension으로 하든, channel dimension으로 하든 성능 향상이 상당하다는 것이 놀라웁다.
LFA와 다르게, efficiency를 논하기는 어렵지만, projector에 DC를 통합하였기 때문에 parameter 추가나 computation burden을 발생시키지 않으면서 소기의 목적을 이룬다는 점에서 efficient하다고 할 수 있겠다.
또 한가지 LFA와 다른 점은 text encoder 에는 적용하지 않았다. 대부분 MLLM이 LLM쪽에 focusing이 맞춰져있고 vision쪽의 power를 좀더 leveraging하려는 노력이 등한시 되는 경향이 있는데, 이러한 문제를 해결하는 게 논문의 취지라서 그런 것 같다.
DC를 LFA의 attention mechanism을 적용하여 upgrade해보면 어떨까?
LFA처럼 text encoder와 연결해보면 어떨까?
LFA처럼 efficiency를 향상시켜보면 어떨까?
혹은.
relevant한 information을 extract해오는데에 cross-attention만한 건 없다고 생각하지만, gating mechanism이나 MoE의 Routing으로 feature를 mixing해보는 건 어떨까 궁금하다.
(gating으로 information을 selective하게 inject하는 게 가능할까?
MoE의 routing 방식이 parallel 하지 않고 sequential한 layer의 hierarchy에 대해서도 가능할까?)
-> 처음 LFA를 보았을 때, "오오! 신박쓰~" 하며, "gating, routing은 어떨까?" 를 떠올렸는데
TroL에서 gating mechanism을 쓰는 것을 보며, 사람 생각은 다 비슷하구나 싶었다 ㅎ
또 한 가지 흥미로운 것은, LFA는 ELMO의 추억을 소환하고, TroL은 LSTM의 추억을 소환한다는 점이다.
고전을 간과하면 안되는 이유이다. ㅎ
아주 흥미로운 module들을 살펴보았다.
modification을 해볼 수도 있겠고, 혹은 내 연구에서 다른 주제에 접목해볼 수도 있겠다.
※ LFA paper에서 표현을 살짝 수정하면 좀더 명확히 전달이 될 것 같은 부분들, comment하고 싶은 부분들이 있는데.. openreview니까 review 남겨볼까....?
'Research > NLP_YS2024' 카테고리의 다른 글
[MaPLe] Multi-modal Prompt Learning (0) 2024.12.05 [DPLCLIP] Domain Prompt Learning for Efficiently Adapting CLIP to Unseen Domains (0) 2024.12.05 [DomainBed] In Search of Lost Domain Generalization (0) 2024.12.05 A High-level Overview of Large Language Models (0) 2024.12.01