-
[DPLCLIP] Domain Prompt Learning for Efficiently Adapting CLIP to Unseen DomainsNLP/NLP_Paper 2024. 12. 5. 15:28
https://arxiv.org/pdf/2111.12853v3
https://github.com/shogi880/DPLCLIP?tab=readme-ov-file
Abstract
Domain generalization (DG) is a difficult transfer learning problem aiming to learn a generalizable model for unseen domains. Recent foundation models (FMs) are robust to many distribution shifts and, therefore, should substantially improve the performance of DG. In this work, we study generic ways to adopt CLIP, a Visual-Language Foundation Model, for DG problems in image classification. While ERM greatly improves the accuracy with bigger backbones and training datasets using standard DG benchmarks, fine-tuning FMs is not practical in many real-world situations. We propose DPL (Domain Prompt Learning) as a novel approach for domain inference in the form of conditional prompt generation. DPL achieved a significant accuracy improvement with only training a lightweight prompt generator (a three-layer MLP), whose parameter is of equivalent scale to the classification projector in the previous DG literature. Combining DPL with CLIP provides surprising performance, raising the accuracy of zero-shot CLIP from 73.7% to 79.3% on several standard datasets, namely PACS, VLCS, OfficeHome, and TerraIncognita. We hope the simplicity and success of our approach lead to broader adoption and analysis of foundation models in the domain generalization field. Our code is available at https://github.com/shogi880/DPLCLIP
1. Introduction
Pre-training large vision models using web-scale images is an essential ingredient of recent success in computer vision. Fine-tuning pre-trained models, such as ResNet (He et al. 2015) and Vision Transformer (ViT) (Dosovitskiy et al. 2020) is the most popular paradigm for many downstream tasks. However, domain shifts pose a substantial challenge in real-world scenarios for successfully transferring models. Over the past decade, various studies on domain generalization (DG) have sought a systematic way to narrow the gap between source and target domains (Zhou et al. 2021a; Wang et al. 2021; Shen et al. 2021) aiming to build a model that generalizes to unseen domains. Despite the significant work on this front, machine learning systems are still vulnerable to domain shifts even after using DG methods (Gulrajani and Lopez-Paz 2020).
Large pre-trained vision-language models like Contrastive Language-Image Pre-Training (CLIP) are an emerging category of models showing great potential in learning transferable representation across many vision tasks. At the core of CLIP is to learn image representations by contrasting them with the representations of text description of the image, such as ‘a photo of a {class name}’. The text description is often called prompt, and its design is vital in enhancing CLIP performance. Notably, CLIP can handle unseen classes without fine-tuning them by adequately changing the text description using the target class name.
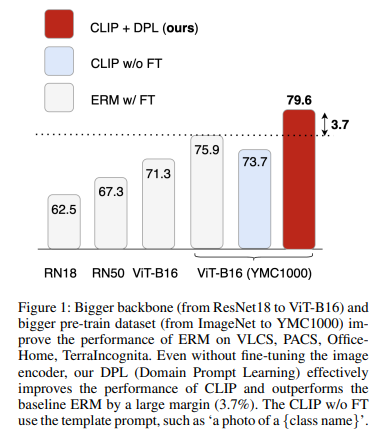
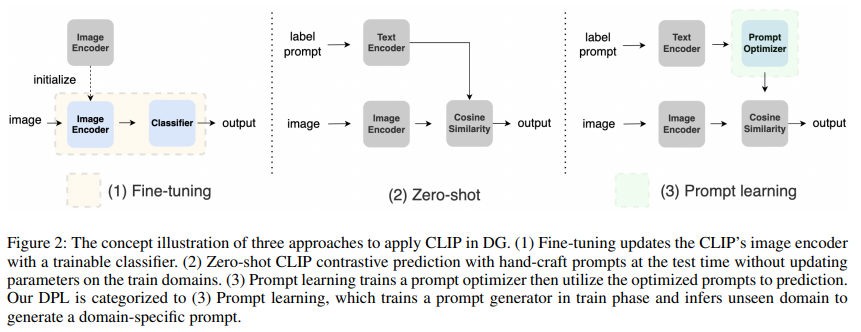
This paper investigates the robustness of CLIP against various distribution shifts using DomainBed (Gulrajani and Lopez-Paz 2020), a recently proposed benchmark for DG setup. While prior works test various DG methods in the benchmark, the most studied only focused on medium-scale pre-trained models, such as ResNet18 or ResNet50. There are two na¨ıve approaches to leveraging CLIP in the DG setup Figure 2. The first approach is fine-tuning the image encoder trained by CLIP, similar to the other vision models such as ResNet and ViT. We show that the backbone networks trained by CLIP substantially outperform many backbone networks trained solely on images, such as ResNet, big transfer (Kolesnikov et al. 2020), and vision transformer (Dosovitskiy et al. 2020). At the same time, however, finetuning sometimes degraded the performance on some domains, suggesting that fine-tuning possibly distorts good properties of pre-trained features (Kumar et al. 2022). Another na¨ıve approach is designing the template prompt, such as ‘a photo of a {class name}’. The clear merit of this approach is that it does not require optimizing any network and, therefore, keeps the representations learned via pretraining. Despite its simplicity, we show that zero-shot CLIP is still more robust on many DG benchmarks than the vision backbones (e.g., ResNet18, ResNet50, ViT-B16) fine-tuned on source domains, while it is inferior to fine-tuning vision backbone trained by CLIP.
Based on the observations, we propose Domain Prompt Learning (DPL), a simple yet effective extension of CLIP in the DG setup. A natural way to adapt the model is to add domain-specific features to the prompt template. However, manually designing a prompt template is challenging in many cases due to its ambiguity. Instead, we propose DPL for automatically generating a prompt that estimates domain-specific features given unlabeled examples from each distribution. More specifically, DPL trains a lightweight prompt generator using source domains, which outputs fixed-length continuous domain prompts given input images of each distribution while freezing other networks. During test-time, the prompt generator generates domain prompt given input images from the target distribution and adds them to the label prompts. Since the entire networks are frozen, the core properties of the pre-training would remain in DPL and are expected to improve CLIP performance in DG stably, as shown in our experiments.
It is worth noting our work is not the first attempt to tune the prompt of CLIP. For example, (Gao et al. 2021; Zhou et al. 2021b) have proposed optimizing continuous prompts on the target datasets, effectively improving CLIP performance. CoCoOp (Zhou et al. 2022), as a contemporary work, trains a meta-net to generate a meta token for adapting to each instance. CoCoOp focuses on unseen classes and demonstrates its performance by transferring from ImageNet to the four specially designed ImageNet variants. This work focuses on the robustness of CLIP against distribution shifts, and proposes a generic way to extract a domain-specific features and improve performance on the target domain at test-time.
We conduct experiments on four standard datasets included in DomainBed to evaluate DPL, following the experiment setup in(Gulrajani and Lopez-Paz 2020; Iwasawa and Matsuo 2021), such as parameter tuning and model selection. We show that CLIP with DPL outperforms the strong baselines by a large margin, raising the accuracy from 73.7% to 79.6% (Table 1). Moreover, since DPL can be seen as a kind of Test-Time Adaptation (TTA) method, we compare it with a series of SoTA TTA methods and demonstrate the efficiency of DPL (Table 2). And lastly, through various ablation studies, we surprisingly found that frozen backbone outperforms fine-tuning on OfficeHome datasets for all of ResNet, DeiT (Touvron et al. 2021), HViT, and ViT-B16 (Table 4). These results prove that DPL is effective, and more importantly, they provide many insights for future works that apply CLIP on DG.
In summary, our main contributions are:
1. We introduce CLIP to standard DG benchmark DomainBed via prompt learning.
2. We propose Domain Prompt Learning (DPL), a novel approach of domain inference, to effectively help domain generalization by utilizing domain-specific features.
3. We demonstrate the impressive empirical performance of DPL by comparing with strong DG baselines and a series of state-of-the-art (SoTA) TTA methods.
2. Related Work
2.1. Domain Generalization
Over the past decade, various approaches have been proposed to solve DG. Most prior works have focused on regularizing the model using the knowledge from multiple source domains. For example, domain-invariant representation learning (Ganin et al. 2016a) is a major branch of domain generalization, aiming to reduce the domain gaps in the space of latent representations. There are many different approaches to measures the domain gaps, including adversarial classifier (Li et al. 2018; Ganin and Lempitsky 2015; Ganin et al. 2016a), kernel mapping (Blanchard, Lee, and Scott 2011; Grubinger et al. 2015), metric learning (Motiian et al. 2017; Jin et al. 2020), and invariant risk minimization (Arjovsky et al. 2020). Similarly, several researchers have sought to generate samples with diverse styles so that models can learn domain-invariant features through them (Shankar et al. 2018; Zhou et al. 2020; Borlino, D’Innocente, and Tommasi 2021). Other methods use meta learning to learn how to regularize the model to improve robustness (Dou et al. 2019; Li et al. 2017b).
Our work investigates the importance of the CLIP (Radford et al. 2021) in DG, and proposes a lightweight way to adapt the CLIP for unseen domains. There are several recent observations to motivate us to benchmark CLIP in the DG setup. First, (Gulrajani and Lopez-Paz 2020) shows that many prior approaches do not provide significant improvement compared to simple supervised learning. The results imply that regularizing the model is not sufficient to achieve high performance in DG. Secondly, despite significant related works, most studies have focused on medium-scale pre-trained models, such as ResNet18 or ResNet50, although very large-scale models often lead to substantial improvements. Notably, the latest work (Iwasawa and Matsuo 2021) compares more large-scale backbone networks, including big transfer (Kolesnikov et al. 2020) (BiT-MR50x3, BiT-M-R101x3, and BiT-M-R152x4), vision transformer (ViTB16 and ViT-L16 (Dosovitskiy et al. 2020), Hybrid ViT, DeiT (Touvron et al. 2021)), and MLP-Mixer (Tolstikhin et al. 2021) (Mixer-L16), and shows that the selection of backbone networks is important in DG. In contrast with (Iwasawa and Matsuo 2021), we herein demonstrate that CLIP performs surprisingly well without fine-tuning the entire model in source domains, which is time-consuming in practice.
From the methodological perspective, our work relates to several prior works that have attempted leveraging domain features rather than discarding them (Ganin et al. 2016a; Zhou et al. 2020; Borlino, D’Innocente, and Tommasi 2021). While these works focused on the standard vision backbone, we propose a CLIP-specific approach to leverage the domain features by combining these features with prompt tuning.
2.2. Test Time Adaptation
Regarding the problem setup, our work can also be seen as Test-Time Adaptation (TTA). The concept of TTA is updating a part of networks to minimize the prediction entropy for adapting the model to an unseen domain robustly at the test time. Pseudo Label (Lee et al. 2013) updates entire networks and Tent (Wang et al. 2020) updates the BN parameters. SHOT(Liang, Hu, and Feng 2020) update feature extractor and minimizes a diversity regularizer and pseudo-label loss, not only prediction entropy. Instead of minimizing prediction entropy at the test time, we infer domain information and generate a domain-specific prompt to adapt CLIP to an unseen target domain.
Our work also relates to (Iwasawa and Matsuo 2021) in that both approaches modulate their prediction given the unlabeled data available at test time. Specifically, (Iwasawa and Matsuo 2021) proposes T3A that replaces the linear classifier using pseudo-labeling and prototypical classification and shows that it stably improves the performance in unseen domains. However, T3A cannot be directly applied to CLIP, as it assumes a simple linear classifier that CLIP does not employ.
2.3. Prompt Learning
The success of GPT-3 demonstrated the importance of prompt tuning. There are various prompting strategies, such as discrete natural language prompts and continuous prompts (Liu et al. 2021a). PADA (Ben-David, Oved, and Reichart 2021) proposed a domain adaptation algorithm that trains T5 (Raffel et al. 2019), a language foundation model, to generate unique domain-relevant features for each input. PADA uses discrete prompts for the NLP applications and differs from our DPL with continuous prompts in computer vision. On the other hand, many recent works (Li and Liang 2021; Lester, Al-Rfou, and Constant 2021) directly tuning prompts in continuous vector forms, and P-Tuning v2 (Liu et al. 2021b) showed that continuous prompt tuning achieves the same performance as fine-tuning in various settings.
Because of the successful applications of CLIP, prompt tuning is also of great interest in computer vision. Context Optimization (CoOp (Zhou et al. 2021b)) demonstrated that CLIP performance is susceptible to prompts and that a suitable prompt can improve performance for the image recognition task. CLIP-Adapter (Gao et al. 2021) was proposed to learn with an additional adapter network. (Ge et al. 2022) adapts CLIP using contrastive learning in the Unsupervised Domain Adaption setup. Unlike these works, which need to access the image or class labels in the target domain, we adapt CLIP to an unseen domain with a generated domain prompt inferred from input images.
3. Method
In this section, we first introduce the notations and definitions of DG following (Wang et al. 2021). Then, we explain how to use CLIP in DG and introduce Domain Prompt Learning to enhance CLIP performance in DG.
3.1. Problem Setup of DG


3.2. Naive Approaches for Using CLIP in DG
CLIP consists of two parts: an image encoder f_clip and a language model g_clip. CLIP classifies the image features based on the similarity between embedding of a text prompt p, such as ‘dog’ or ‘a photo of a class label,’ rather than initially using the classification head trained from scratch. Specifically, given an image x and K class prompt p_k, CLIP output a prediction using both f_clip and g_clip:

where K is the number of categories and <·, ·> is cosine similarity.
To demonstrate how powerful the representation of massively pre-trained models (CLIP) for DG setup, we tested following two na¨ıve approaches to use CLIP in DG setups: fine-tuning and zero-shot. Firstly, we evaluated CLIP in a zero-shot manner; i.e., we freeze both the image encoder and the language model, and substitute the class labels used in each dataset for the text prompt p.
Secondly, we can use the image encoder f_clip as an alternative to the standard image backbones, such as ResNet and ViT. In this setup, we train f_clip by using the datasets S^i from multiple source domains i, similar to the standard DG setup. We can use any algorithms tailored for DG setup, such as DANN and CORAL during fine-tuning. While it is powerful as shown in experiments, it requires additional computational costs to re-train such large models entirely. Besides, good properties of massive pre-training might be distorted during fine-tuning, as highlighted by the performance degradation compared to zero-shot approach.
In summary, zero-shot approach is computationally effective yet less expressive, and fine-tuning can leverage the knowledge of source datasets but it is computationally heavy and possibly distort good representations learned during pretraining. Based on the observation, we propose a novel approach to design the prompt p to improve the performance in an unseen domain without fine-tuning the entire model.
3.3. Domain Prompt Learning for CLIP in DG

As discussed in Section 2.3, designing a prompt is a powerful approach to improve the performance of the transformer-based models. It is powerful and should also be easier to train because the dimension of prompts is significantly smaller than the entire parameters of f and g. For example, supposing we can access a supervised dataset from the target domain, we can optimize a prefix vector p_pre by simple supervised loss:

where p∗k is a concatenation of trainable parameters p_pre and p_k. Particularly, g_clip outputs the fixed length vector regardless of the input dimension (i.e., size of p_k). The size of p_k is a hyperparameter.
Unfortunately, this labeled training data for the target domain is unavailable in DG. Instead, we proposed DPL to replace the optimization process of p_pre in each domain by training novel prompt generators F(·) that generate a prompt p_pre given small unlabeled images from a distribution. Specifically, we use a fully connected network F(·) to generate a prompt p from input images:

4. Experiment
In this section, we experimentally demonstrate the effectiveness of DPL. First, we clarify the important DG settings, including the datasets, hyperparameters, model selection strategy, and other implementation details. Second, we show CLIP + DPL outperforms the strong DG baselines and several SoTA TTA methods on DomainBed benchmark. Finally, our ablation experiments, including variants backbone comparison and different prompt strategies study, provide meaningful insights of applying CLIP + DPL to DG.
Datasets
Following (Iwasawa and Matsuo 2021), we selected four real-world datasets from DomainBed benchmark, including VLCS (Fang, Xu, and Rockmore 2013), PACS (Li et al. 2017a), OfficeHome (Venkateswara et al. 2017), TerraIncognita (Beery, van Horn, and Perona 2018). More details are provided in Appendix A.
Hyperparameters and model selection.
We set up experiments on DomainBed 1 , and implemented DPL based on CLIP 2 . We strictly followed the basic selection criterion (Gulrajani and Lopez-Paz 2020) and selected the hyperparameters using standard training-domain validation. First, we split the data of each domain into 80% and 20% for the training model and select hyperparameters. Then, we ran 20 trials at random across a joint distribution of all hyperparameters. Next, we ran three trials of each hyperparameter setting, reserving one domain for testing and the rest for training. Finally, we selected the hyperparameters that maximize validation accuracy across the training domains and reported overall accuracy averaged across all three trials.
Detail of the implements
As shown as in Figure 3, we only trained a three-layer MLP as the domain prompt generator. We used stochastic gradient descent (Bottou 2012) with momentum as an optimizer. Refer to our source code for implement details.
4.1. Comparison with existing DG methods
Baselines
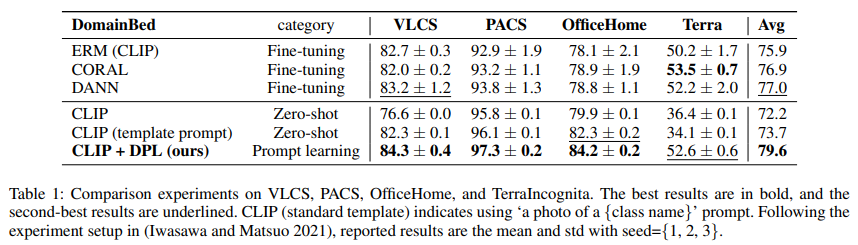
We compared our method to domain generalization algorithms, which fine-tune image features, and the handcrafted prompt for CLIP. For DG, we trained CLIP image features (ViT-B16) using ERM, CORAL (Sun and Saenko 2016), and DANN (Ganin et al. 2016b). Note that, as (Gulrajani and Lopez-Paz 2020) pointed out, ERM is a strong DG baseline when the experiments are fairly performed. For handcrafted prompt, we adopted three types prompt for CLIP including ‘{class name}’, template prompt ‘a photo of a {class name}.’, and Domain Prompt Learning ‘v1, v2, ..., vn {class name}.’.
All experiments listed in Table 1 are based on the CLIP ViT-B16 backbone. We observed that zero-shot CLIP could achieve an average of 72.2% accuracy and an average of 73.7% by using a template prompt. Notably, DPL improves CLIP performance to 79.6% and outperforms all baselines, although ERM, CORAL, and DANN are fine-tuning their image encoder. Based on this result, we infer that DPL should be an effective method in DG.
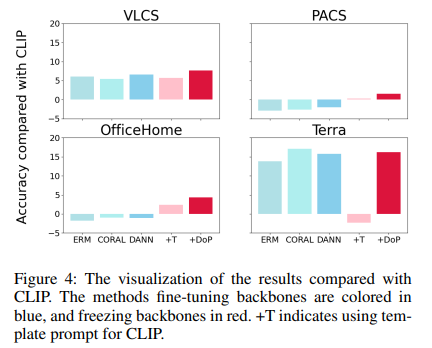
Surprisingly, we found that fine-tuning the backbones hurts performance on PACS and OfficeHome. We consider that fine-tuning causes the model to overfit in the source domain in the case where the pre-training domain is big enough to cover the target domain. On the other hand, the models perform better with fine-tuning on Terra, with a high likelihood of being not covered by the CLIP’s pre-training dataset. It is worth noting that our DPL can effectively tradeoff well between both cases.
4.2. Comparison with existing TTA methods

DPL is generated by extracting domain features from a batch of input images. As discussed in subsection 2.2, DPL can be considered as a TTA method. Therefore, we performed a fair comparison with several TTA algorithms to validate DPL.
Baselines
Following (Iwasawa and Matsuo 2021), we adopted the baselines including Pseudo Label, SHOT, Tent, and T3A with batch size equal to 64 during the test time. We trained all models with the same CLIP ViT-B16 backbone. All the experiments follow the model selection, hyperparameter selection strategy, and evaluation method proposed in T3A and DomainBed.
As shown in Table 2, DPL beats the most effective TTA methods on four datasets. The result demonstrates that DPL can consistently improve the model’s generalization performance at test time. We believe this is sufficient evidence that the central concept of DPL, extracting unseen domain features to help model adapting at the test time, is practical.
4.3. Backbone Ablation
Different Backbones
Many proposed DG methods are evaluated using the standard ResNet backbones. However, more and more large models are being studied, and their validity is being experimentally demonstrated (Bommasani et al. 2021; Wang et al. 2022). Therefore, we reported the performance of ResNet18 and ResNet50, Mixer-16 (Tolstikhin et al. 2021), Vision Transformer (ViT) (Dosovit skiy et al. 2020) and several variations of ViT, such as BiT (Kolesnikov et al. 2020), DeiT (Touvron et al. 2021), HViT, and Mutual Information Regularization with Oracle (MIRO) (Cha et al. 2022) in Table 3.
As a result, we discovered that the CLIP ViT-B16 backbone trained on YFCC100M (Thomee et al. 2016) performs as well as HViT. Moreover, CLIP + DPL surpassed most of the backbones, including HViT and MIRO. Notably, DPL only trains a three-layer MLP, in contrast to others finetuning their backbones. We observed that the SoTA performance is provided by MIRO using RegNetY-16GF backbone with SWAG pre-training and combined with Stochastic Weight Averaging Densely (MIRO + SWAG (Singh et al. 2022) + SWAD (Cha et al. 2021)). The simple DPL can achieve close performance (difference of 1.9%). Although comparing with different pre-training datasets and different parameters is unfair, this result demonstrates that Domain Prompt Learning can efficiently adapt CLIP to unseen domains.
Frozen Backbone
Fine-tuning a large model like CLIP or other Foundation Models necessitates much computing power. DPL also aims to adapt CLIP to the target domain with minimum computing. We wondered if simply training an MLP classifier with the frozen backbone could aid model transfer and conducted the ablation experiments with five different backbones.
From Table 4, we surprisingly found that Frozen ERM outperforms the standard ERM in OfficeHome with all the backbones. In VLCS, the performance of Frozen ERM is also unexpected. These results show that fine-tuning hurts the model more than expected on specific datasets. On the other hand, DPL steadily improving the performance on all datasets demonstrates the robustness of DPL.
A similar phenomenon, fine-tuning does not constantly improve performance in DG, is also observed in subsection 4.1. Due to computing resource constraints, we only evaluated several backbones of varying sizes in this work. We found several recent studies analyzing the same phenomenon, the effect of pre-training datasets and backbones on DG and Out-of-Distribution settings(Kim et al. 2022; Wenzel et al. 2022).


5. Conclusions
We introduce CLIP to DG on DomainBed. For this purpose, we proposed a novel approach called Domain Prompt Learning (DPL) for efficiently adapting CLIP to an unseen domain. By generating the domain prompt conditional on input images, CLIP + DPL brings substantial improvements over strong DG baselines and several effective TTA methods on DomainBed. Then, we conducted ablation experiments with various backbones and Frozen ERM. We verified that DPL can stabilize performance and present meaningful insights about existing datasets and fine-tuning strategy of backbones. We hope that our research will broaden and inspire the roles of prompt learning in domain transfer learning.
5.1. Limitation
Interpretability of Domain Prompt
To better perform, our DPL is directly represented in a continuous vector form, which lacks interpretability. However, improving interpretability is an important research direction in both FM applications and Domain Generalization. We consider producing discrete semantically informative prompts by some means is an exciting extension of DPL, even with some loss of precision.
Label Shift
From the technical perspective, DPL cannot capture the domain shift outside of the images because DPL uses domain features extracted from only images. As a result, DPL has no idea how to record such non-visual domain shift. Unfortunately, the label shift exists in the actual-world applications (Azizzadenesheli et al. 2019). An innovative question is whether adding appropriate information to the Domain Prompt can help solve the label shift problem, such as a detailed textual description of the target domain.
Social impact perspective
Many images and text descriptions of web data are used directly to train CLIP. Though CLIP benefits from low-cost data that do not require manual labeling, it inevitably includes a lot of bias and privacy in CLIP and other foundation models (Bommasani et al. 2021). This requires us to spend more time paying attention to the opportunities and risks of Foundation Models.
5.2. Future Work
First and foremost, interpretability is critical in both Domain Transfer Learning and the Foundation Model. As discussed in subsection 5.1, DPL introduce the possibility of using a large language model in DG in the form of prompt. We will investigate this direction in our future work.
There are two simple and critical approaches to improving the performance of DG. One is to apply visual prompt tuning (Jia et al. 2022) on the pure visual backbones, which can be used to more previous methods. Another is focusing on a data-centric approach since we observe uneven data quality on the widely used datasets.
Finally, several recent studies systematically analyze the performance and shortcomings of large-scale pre-train models in the Out-of-Distribution generalization (Cha et al. 2022; Wenzel et al. 2022). We hope that our results will inspire more research in this direction.
6. Appendix
6.1. Datasets
Following (Iwasawa and Matsuo 2021), we selected four real-world datasets from DomainBed benchmark, including VLCS (Fang, Xu, and Rockmore 2013), PACS (Li et al. 2017a), OfficeHome (Venkateswara et al. 2017), TerraIncognita (Beery, van Horn, and Perona 2018).
VLCS (Fang, Xu, and Rockmore 2013) gathers four photographic datasets d ∈ {Caltech101 (Fei-Fei, Fergus, and Perona 2006), LabelMe (Russell et al. 2008), SUN09 (Choi et al. 2010), VOC2007 (Everingham and Winn 2009)}, containing 10,729 samples of 5 classes. PACS (Li et al. 2017a) comprises four domain datasets d ∈ {art, cartoons, photos, sketches}, with 9,991 samples and 7 classes. OfficeHome (Venkateswara et al. 2017) includes domains d ∈ {art, clipart, product, real}, with 15,588 samples and 65 classes. TerraIncognita (Beery, van Horn, and Perona 2018) includes photos of wild animals taken by a camera at different locations. Following (Gulrajani and Lopez-Paz 2020), we used datasets of d ∈ {Location 100, Location 38, Location 43, Location 46}, with a total of 24,788 samples and classes. We show random samples from each dataset.
VLCS includes four photo datasets, so many objects that are unrelated to class are captured together. We conjecture that training in the source domain can help the model capture the correspondence between images and labels.
However, from the PACS dataset, we can find that the object corresponding to each image is straightforward and clear. This would be a relatively simple task for a CLIP trained on large-scale data. However, the shift of each Domain is evident, and if the large model is trained on the source domain, it will lead to performance degradation.
The dataset characteristics of OfficeHome resemble those of PACS in general, which explains our experimental resultsFigure 4 that fine-tuning hurts CLIP performance on PACS and OfficeHome.
Finally, we found that the models perform well if finetuning on Terra. This is because there is no way for Terra’s image-label correspondence to be learned during pre-training. It is worth noting that the SoTA method MIRO (Cha et al. 2022) not only uses a more advanced backbone than CLIP but also fine-tunes the backbone and adds the SWAD technique. These factors lead to the fantastic result of MIRO reaching 64.3% on Terra.
The real-world domain generalization is similar to the case of Terra (Koh et al. 2021). Therefore, we believe that similar to the MIRO, and it is essential to study FM in the DG domain.




'NLP > NLP_Paper' 카테고리의 다른 글
[MaPLe] Multi-modal Prompt Learning (0) 2024.12.05 [DomainBed] In Search of Lost Domain Generalization (0) 2024.12.05 Layer의 재사용에 대하여 (0) 2024.12.03 A High-level Overview of Large Language Models (0) 2024.12.01 [Project Proposal] Improving the performance of machine-generated text (MGT) detection by identifying the significance of individual tokens (0) 2024.11.11