-
High Variance in Policy gradientsResearch/RL_reference 2024. 12. 19. 08:51
https://balajiai.github.io/high_variance_in_policy_gradients
https://github.com/BalajiAI/High-Variance-in-Policy-gradients
1. baseline에 대한 엄밀한 도출
2. GAE (Generalized Advantage Estimation)
- code를 보다보면, 효율적인 연산을 위한 technique이 들어가거나, 선행연구의 code를 base로 해서, 추가적인 공부가 필요한 경우가 많은데, PPO algorithm에서 advantage 연산을 GAE (Generalized Advantage Estimation)로 하는데 이를 이해하기 위한 보충 자료. (공부했던 건데 제대로 이해 못하고 넘어갔던..)
Though vanilla policy gradient is theoretically simple and mathematically proven, it doesn’t seem to work well in practice. The main reason is because of high variance which policy gradient exhibit. High variance comes from the rewards obtained in a trajectory. Due to inherent randomness present in both environment and policy action selection, the rewards obtained by a fixed policy can vary greatly.
Because of the high variance, we need more trajectories for an accurate estimation of the policy gradient.
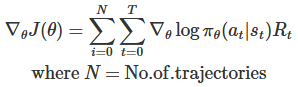

Figure 1. Consider two Random variables X and Y with same expectation value. But Var(Y)>Var(X). So samples drawn from Y will be much far away from the expectation value than the ones drawn from X. In that sense, the difference b/w the sample mean of Y and expectation value will be large. In order to drown out the variance for accurate estimation of sample mean, we've to use large number of samples. Note: Number of samples and variance affects the calculation of sample mean.
But collecting large number of trajectories just for a single policy update is infeasible. So researchers have proposed techniques for reducing the variance in policy gradients in the past decades. One common theme across these variance reduction techniques is, they always try to keep the gradient estimate unbiased (equal to its original value).
It’s because, we can solve the variance problem by using large number of samples to estimate the gradient. But with bias, though we’ve infinite number of samples, our policy might converge to a local optimum or not converge at all. That’s why RL researchers are so cautious about it.
Baselines
One of the well known techniques to reduce variance is to introduce baseline into our policy gradient expression. The idea of baseline comes from the control variates method, which is a popular variance reduction technique used in Monte Carlo methods. So First, we’ll talk about what control variates are and then we can derive baseline from it.
Control Variates


Baseline expression

So the optimal baseline expression is expected return over trajectories weighted by gradient magnitudes. But often in practice, people just use the average return as a baseline,

Another commonly used baseline expression is the state-value v[s]. Whereas Average return is a constant value which don’t vary, state-value varies depending upon the state the agent is in. The following is the generic equation for state-dependent baselines like state-value,

Intuition behind Baseline

Neuroscience behind Baseline
Let’s consider that you’re in a room, where you’ve an access to a button, which when pressed will give you a 5 dollar bill. At the first press, you’ll get an increase in dopamine level (it also means that you’ll experience pleasure). During the 50th press, you’ll still get an increase in dopamine level, but not the same increase that you’ve got in the first press. Even worse, during the 200th press, you won’t get any increase in dopamine level at all, so you won’t experience any joy or pleasure. It’s because at each press, your baseline gets updated slowly and in the 200th press your baseline value gets updated completely such that it entirely cancels out the reward that you’d received.
In RL terms, let’s say the reward that one gets in each press is equivalent to the amount that one receives. So for a 5 dollar bill, the reward is 5 points. In our setup (environment), there is only a single timestep in each episode, so there is no need for the concept of Return. The most important thing here is how the agent perceives the reward. The agent doesn’t perceive the reward r as it is. Instead it perceives the reward as the relative difference to the baseline (r−b). And our baseline b is initially set to zero. So at the first press, the reward which the agent perceives is 5−0=5. In the 50th press, the baseline gets updated to 2.5, so the perceived reward is 5−2.5=2.5. In the 200th press, the baseline gets updated to 5, so the perceived reward becomes 5−5=0.
But you can still feel pleasure, only if you get a reward which is greater than the baseline value. For example, let’s say you’d received a 20 dollar bill instead of a 5 dollar bill, then the perceived reward is 20−5=15. This is the sole reason behind why drug addicts tend to increase their drug dosage in order for them to experience the pleasure.
Actor Critic
After Baselines, the next class of methods which are widely used for variance reduction is Actor Critic methods. As the name suggests, these class of methods has two components, Actor (aka policy) and Critic (aka value function), which are parameterized and learnable. Here the Critic assists in optimizing the Actor. In exact words, instead of using the empirical returns computed from the collected trajectories, the policy uses approximate returns predicted by the value function for its optimization. This reduces the variance and also introduces (some!) bias into our gradient estimates.
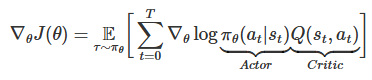
Apart from variance reduction, another nice thing about actor-critic methods is we don’t have to wait for an episode to get completed before updating the policy. Although it’s rarely done in practice.
Advantage Actor Critic (A2C)


Conclusion
So, in this blog, we’ve seen how variance arises in Policy gradient methods and also discussed about the techniques for variance reduction such as Baselines & Actor Critic methods. While Baseline method tries to reduce the variance by following a common approach in Statistics called control variates, in the meanwhile, Actor critic methods takes a radical new approach to the variance reduction by making use of predictions from the value function. Although one can always make use of multiple trajectories to approximate the policy gradient inorder to factor out the variance :)