-
Subword TokenizerNLP/NLP_reference 2024. 4. 10. 16:40
기계에게 아무리 많은 단어를 학습시켜도, 세상의 모든 단어를 알려줄 수는 없는 노릇입니다. 만약, 기계가 모르는 단어가 등장하면 그 단어를 단어 집합에 없는 단어란 의미에서 OOV(Out-Of-Vocabulary) 또는 UNK(Unknown Token)라고 표현합니다. 기계가 문제를 풀 때, 모르는 단어가 등장하면 (사람도 마찬가지지만) 주어진 문제를 푸는 것이 까다로워 집니다. 이와 같이 모르는 단어로 인해 문제를 푸는 것이 까다로워지는 상황을 OOV 문제라고 합니다.
서브워드 분리(Subword segmenation) 작업은 하나의 단어는 더 작은 단위의 의미있는 여러 서브워드들(Ex) birthplace = birth + place)의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩하겠다는 의도를 가진 전처리 작업입니다. 이를 통해 OOV나 희귀 단어, 신조어와 같은 문제를 완화시킬 수 있습니다. 실제로 언어의 특성에 따라 영어권 언어나 한국어는 서브워드 분리를 시도했을 때 어느정도 의미있는 단위로 나누는 것이 가능합니다. 이 책에서는 이런 작업을 하는 토크나이저를 서브워드 토크나이저라고 명명하겠습니다.
이번 챕터에서는 서브워드 토크나이저의 주요 알고리즘인 바이트 페어 인코딩과 실제 실무에서 사용하는 서브워드 토크나이저 구현체인 SentencePiece와 Huggingface의 Tokenizers에 대해서 소개합니다.
1. 바이트 페어 인코딩(Byte Pair Encoding, BPE)
BPE(Byte Pair Encoding)
BPE(Byte pair encoding) 알고리즘은 1994년에 제안된 데이터 압축 알고리즘입니다. 하지만 후에 자연어 처리의 서브워드 분리 알고리즘으로 응용되었는데 이에 대해서는 뒤에 언급하도록 하고, 우선 기존의 BPE의 작동 방법에 대해서 이해해보겠습니다. 아래와 같은 문자열이 주어졌을 때 BPE을 수행한다고 해봅시다.

자연어 처리에서의 BPE(Byte Pair Encoding)
자연어 처리에서의 BPE는 서브워드 분리(subword segmentation) 알고리즘입니다. 기존에 있던 단어를 분리한다는 의미입니다. BPE을 요약하면, 글자(charcter) 단위에서 점차적으로 단어 집합(vocabulary)을 만들어 내는 Bottom up 방식의 접근을 사용합니다. 우선 훈련 데이터에 있는 단어들을 모든 글자(chracters) 또는 유니코드(unicode) 단위로 단어 집합(vocabulary)를 만들고, 가장 많이 등장하는 유니그램을 하나의 유니그램으로 통합합니다.
BPE을 자연어 처리에 사용한다고 제안한 논문(Sennrich et al. (2016))에서 이미 BPE의 코드를 공개하였기 때문에, 바로 파이썬 실습이 가능합니다. 코드 실습을 진행하기 전에 육안으로 확인할 수 있는 간단한 예를 들어보겠습니다.



이 경우 테스트 과정에서 'lowest'란 단어가 등장한다면, 기존에는 OOV에 해당되는 단어가 되었겠지만 BPE 알고리즘을 사용한 위의 단어 집합에서는 더 이상 'lowest'는 OOV가 아닙니다. 기계는 우선 'lowest'를 전부 글자 단위로 분할합니다. 즉, 'l, o, w, e, s, t'가 됩니다. 그리고 기계는 위의 단어 집합을 참고로 하여 'low'와 'est'를 찾아냅니다. 즉, 'lowest'를 기계는 'low'와 'est' 두 단어로 인코딩합니다. 그리고 이 두 단어는 둘 다 단어 집합에 있는 단어이므로 OOV가 아닙니다.



3) OOV에 대처하기

WordPiece Tokenizer
WordPiece Tokenizer은 BPE의 변형 알고리즘입니다. 해당 알고리즘은 BPE가 빈도수에 기반하여 가장 많이 등장한 쌍을 병합하는 것과는 달리, 병합되었을 때 코퍼스의 우도(Likelihood)를 가장 높이는 쌍을 병합합니다. 2016년의 위 논문에서 구글은 구글 번역기에서 WordPiece Tokenizer가 수행된 결과에 대해서 기술하였습니다.
수행하기 이전의 문장: Jet makers feud over seat width with big orders at stake
WordPiece Tokenizer를 수행한 결과(wordpieces): _J et _makers _fe ud _over _seat _width _with _big _orders _at _stakeJet는 J와 et로 나누어졌으며, feud는 fe와 ud로 나누어진 것을 볼 수 있습니다. WordPiece Tokenizer는 모든 단어의 맨 앞에 _를 붙이고, 단어는 서브 워드(subword)로 통계에 기반하여 띄어쓰기로 분리합니다. 여기서 언더바 _는 문장 복원을 위한 장치입니다.
예컨대, WordPiece Tokenizer의 결과로 나온 문장을 보면, Jet → _J et와 같이 기존에 없던 띄어쓰기가 추가되어 서브 워드(subwords)들을 구분하는 구분자 역할을 하고 있습니다. 그렇다면 기존에 있던 띄어쓰기와 구분자 역할의 띄어쓰기는 어떻게 구별할까요? 이 역할을 수행하는 것이 단어들 앞에 붙은 언더바 _입니다. WordPiece Tokenizer이 수행된 결과로부터 다시 수행 전의 결과로 돌리는 방법은 현재 있는 모든 띄어쓰기를 전부 제거하고, 언더바를 띄어쓰기로 바꾸면 됩니다.
이 알고리즘은 유명 딥 러닝 모델 BERT를 훈련하기 위해서 사용되기도 하였습니다.
2. 센텐스피스(SentencePiece)
내부 단어 분리를 위한 유용한 패키지로 구글의 센텐스피스(Sentencepiece)가 있습니다. 구글은 BPE 알고리즘과 Unigram Language Model Tokenizer를 구현한 센텐스피스를 깃허브에 공개하였습니다.
내부 단어 분리 알고리즘을 사용하기 위해서, 데이터에 단어 토큰화를 먼저 진행한 상태여야 한다면 이 단어 분리 알고리즘을 모든 언어에 사용하는 것은 쉽지 않습니다. 영어와 달리 한국어와 같은 언어는 단어 토큰화부터가 쉽지 않기 때문입니다. 그런데, 이런 사전 토큰화 작업(pretokenization)없이 전처리를 하지 않은 데이터(raw data)에 바로 단어 분리 토크나이저를 사용할 수 있다면, 이 토크나이저는 그 어떤 언어에도 적용할 수 있는 토크나이저가 될 것입니다. 센텐스피스는 이 이점을 살려서 구현되었습니다. 센텐스피스는 사전 토큰화 작업없이 단어 분리 토큰화를 수행하므로 언어에 종속되지 않습니다.
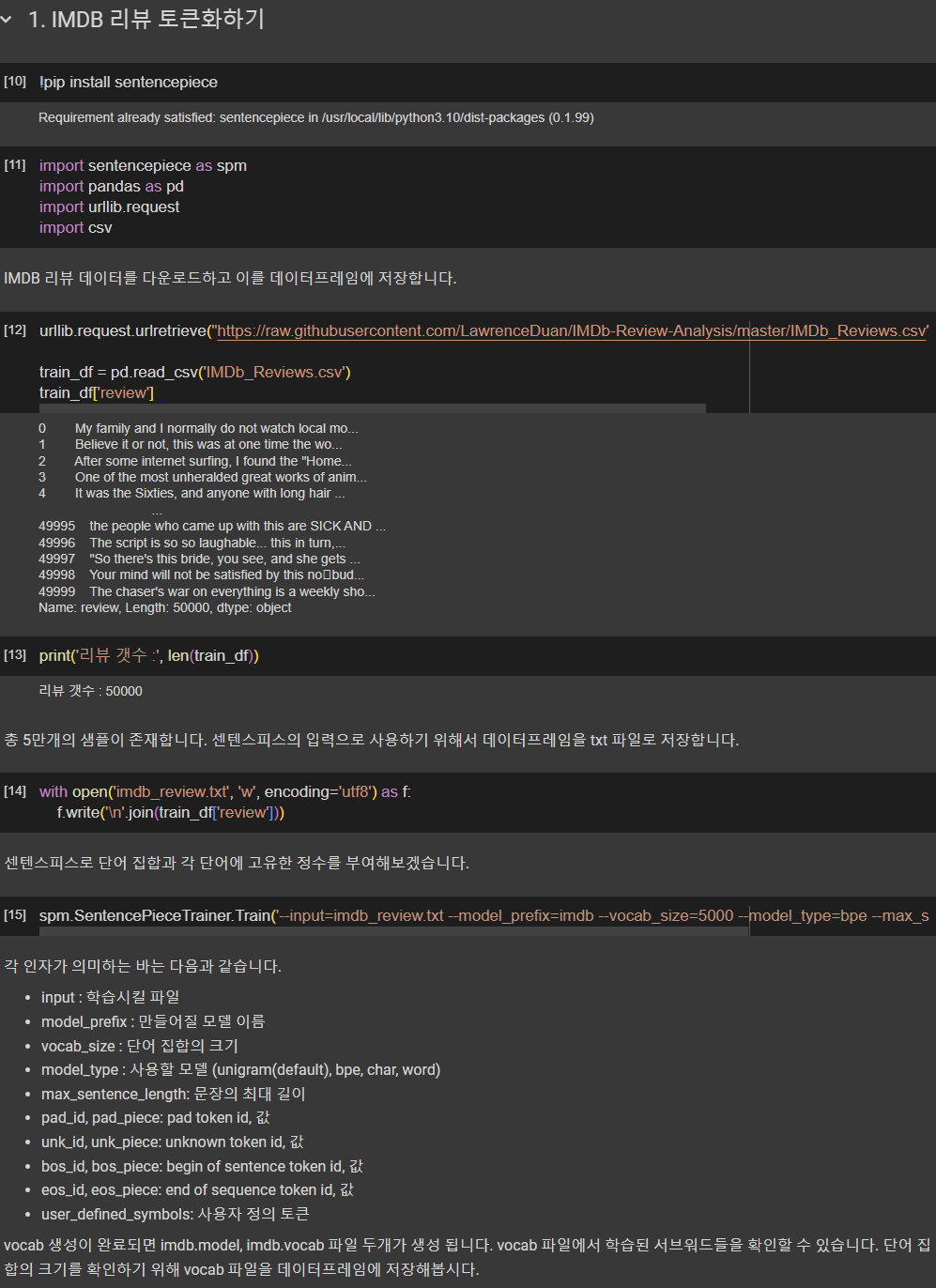




3. 서브워드텍스트인코더(SubwordTextEncoder)
SubwordTextEncoder는 텐서플로우를 통해 사용할 수 있는 서브워드 토크나이저입니다. BPE와 유사한 알고리즘인 Wordpiece Model을 채택하였으며, 패키지를 통해 쉽게 단어들을 서브워드들로 분리할 수 있습니다. SubwordTextEncoder를 통해서 IMDB 영화 리뷰 데이터와 네이버 영화 리뷰 데이터에 대해서 토큰화 작업을 수행해봅시다.




4. 허깅페이스 토크나이저(Huggingface Tokenizer)
자연어 처리 스타트업 허깅페이스가 개발한 패키지 tokenizers는 자주 등장하는 서브워드들을 하나의 토큰으로 취급하는 다양한 서브워드 토크나이저를 제공합니다. 이번 실습에서는 이 중에서 WordPiece Tokenizer를 실습해보겠습니다.
BERT의 워드피스 토크나이저(BertWordPieceTokenizer)
구글이 공개한 딥 러닝 모델 BERT에는 WordPiece Tokenizer가 사용되었습니다. 허깅페이스는 해당 토크나이저를 직접 구현하여 tokenizers라는 패키지를 통해 버트워드피스토크나이저(BertWordPieceTokenizer)를 제공합니다.
여기서는 네이버 영화 리뷰 데이터를 해당 토크나이저에 학습시키고, 이로부터 서브워드의 단어 집합(Vocabulary)을 얻습니다. 그리고 임의의 문장에 대해서 학습된 토크나이저를 사용하여 토큰화를 진행합니다.


'NLP > NLP_reference' 카테고리의 다른 글
Prompt Engineering Guide (2/2) (0) 2024.07.24 Prompt Engineering Guide (1/2) (0) 2024.07.24 Word Embedding (1) 2024.04.10 Vector Similarity (벡터의 유사도) (0) 2024.04.10 카운트 기반의 단어 표현(Count based word Representation) (0) 2024.04.10