-
[FLAN] Finetuned Language Models Are Zero-shot LearnersResearch/NLP_Paper 2024. 7. 25. 10:49
https://arxiv.org/pdf/2109.01652
Abstract
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning—finetuning language models on a collection of datasets described via instructions—substantially improves zeroshot performance on unseen tasks.
We take a 137B parameter pretrained language model and instruction tune it on over 60 NLP datasets verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 20 of 25 datasets that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of finetuning datasets, model scale, and natural language instructions are key to the success of instruction tuning.

1. Introduction
Language models (LMs) at scale, such as GPT-3 (Brown et al., 2020), have been shown to perform few-shot learning remarkably well. They are less successful at zero-shot learning, however. For example, GPT-3’s zero-shot performance is much worse than few-shot performance on tasks such as reading comprehension, question answering, and natural language inference. One potential reason is that, without few-shot exemplars, it is harder for models to perform well on prompts that are not similar to the format of the pretraining data.
In this paper, we explore a simple method to improve the zero-shot performance of large language models, which would expand their reach to a broader audience. We leverage the intuition that NLP tasks can be described via natural language instructions, such as “Is the sentiment of this movie review positive or negative?” or “Translate ‘how are you’ into Chinese.” We take a pretrained language model of 137B parameters and perform instruction tuning—finetuning the model on a mixture of more than 60 NLP datasets expressed via natural language instructions. We refer to this resulting model as FLAN, for Finetuned Language Net.
To evaluate the zero-shot performance of FLAN on unseen tasks, we group NLP datasets into clusters based on their task types and hold out each cluster for evaluation while instruction tuning FLAN on all other clusters. For example, as shown in Figure 1, to evaluate FLAN’s ability to perform natural language inference, we instruction tune the model on a range of other NLP tasks such as commonsense reasoning, translation, and sentiment analysis. As this setup ensures that FLAN has not seen any natural language inference tasks in instruction tuning, we then evaluate its ability to perform zero-shot natural language inference.
Our evaluations show that FLAN substantially improves the zero-shot performance of the base 137B-parameter model. FLAN’s zero-shot also outperforms 175B-parameter GPT-3’s zero-shot on 20 of 25 datasets that we evaluate, and even outperforms GPT-3’s few-shot by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. In ablation studies, we find that increasing the number of task clusters in instruction tuning improves performance on unseen tasks and that the benefits of instruction tuning emerge only with sufficient model scale.
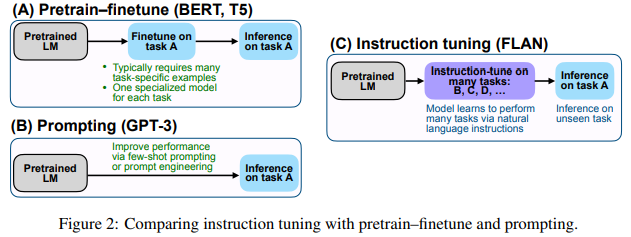
Instruction tuning is a simple method that, as depicted in Figure 2, combines appealing aspects of both the pretrain–finetune and prompting paradigms by using supervision via finetuning to improve language model’s responses to inference-time text interactions. Our empirical results demonstrate promising abilities of language models to perform tasks described purely via instructions. Source code for loading the instruction tuning dataset used for FLAN is publicly available at https://github.com/google-research/flan.
2. FLAN: Instruction Tuning Improves Zero-shot Learning
The motivation of instruction tuning is to improve the ability of language models to respond to NLP instructions. The idea is that by using supervision to teach an LM to perform tasks described via instructions, the LM will learn to follow instructions and do so even for unseen tasks. To evaluate performance on unseen tasks, we group datasets into clusters by task type and hold out each task cluster for evaluation while instruction tuning on all remaining clusters.
2.1. Tasks & Templates
As creating an instruction tuning dataset with many tasks from scratch would be resource-intensive, we transform existing datasets from the research community into an instructional format. We aggregate 62 text datasets that are publicly available on Tensorflow Datasets, including both language understanding and language generation tasks, into a single mixture. Figure 3 shows these datasets— each dataset is categorized into one of twelve task clusters, for which datasets in a given cluster are of the same task type. Descriptions, sizes, and examples of each dataset are shown in Appendix G.

For each dataset, we manually compose ten unique templates that use natural language instructions to describe the task for that dataset. While most of the ten templates describe the original task, to increase diversity, for each dataset we also include up to three templates that “turned the task around,” (e.g., for sentiment classification we include templates asking to generate a movie review). We then instruction tune a pretrained language model on the mixture of all datasets, with examples in each dataset formatted via a randomly selected instruction template for that dataset. Figure 4 shows multiple instruction templates for a natural language inference dataset.

2.2. Evaluation Splits
We are interested in how FLAN performs on tasks not seen in instruction tuning, and so it is crucial to define what counts as an unseen task. Whereas some prior work defines unseen tasks by disallowing the same dataset to appear in training, we use a more conservative definition that leverages the task clusters from Figure 3. In this work, we only consider dataset D unseen at evaluation time if no datasets from any task clusters that D belongs to were seen during instruction tuning. For instance, if D is an entailment task, then no entailment datasets appeared in instruction tuning, and we instruction-tuned on all other clusters.1 Hence, to evaluate zero-shot FLAN on c task clusters, we instruction tune c models, where each model holds out a different task cluster for evaluation.
2.3. Classification with Options
The output space for a given task is either one of several classes (classification) or free text (generation). As FLAN is an instruction-tuned version of a decoder-only language model, it naturally responds in free text, and so no further modifications are needed for generation tasks.
For classification tasks, prior work (Brown et al., 2020) used a rank classification approach where, for example, only two outputs (“yes” and “no”) are considered and the higher probability one is taken as the model’s prediction. Though this procedure is logically sound, it is imperfect in that the probability mass for answers may have an undesired distribution among ways of saying each answer (e.g., a large number of alternative ways of saying “yes” may lower the probability mass assigned to “yes”). Therefore, we include an options suffix, in which we append the token OPTIONS to the end of a classification task along with a list of the output classes for that task. This makes the model aware of which choices are desired when responding to classification tasks. Example use of options is shown in the NLI and commonsense examples in Figure 1.
2.4. Training Details
Model architecture and pretraining.
In our experiments, we use LaMDA-PT, a dense left-to-right, decoder-only transformer language model of 137B parameters (Thoppilan et al., 2022). This model is pretrained on a collection of web documents (including those with computer code), dialog data, and Wikipedia, tokenized into 2.49T BPE tokens with a 32k vocabulary using the SentencePiece library (Kudo & Richardson, 2018). Around 10% of the pretraining data was non-English. Note that LaMDA-PT only has language model pretraining (c.f. LaMDA, which was finetuned for dialog).
Instruction tuning procedure.
FLAN is the instruction-tuned version of LaMDA-PT. Our instruction tuning pipeline mixes all datasets and randomly samples from each dataset. To balance the different sizes of datasets, we limit the number of training examples per dataset to 30k and follow the examples-proportional mixing scheme (Raffel et al., 2020) with a mixing rate maximum of 3k.2 We finetune all models for 30k gradient steps with a batch size of 8,192 tokens using the Adafactor Optimizer (Shazeer & Stern, 2018) with a learning rate of 3e-5. The input and target sequence lengths used in finetuning are 1024 and 256, respectively. We use packing (Raffel et al., 2020) to combine multiple training examples into a single sequence, separating inputs from targets using a special EOS token. This instruction tuning takes around 60 hours on a TPUv3 with 128 cores. For all evaluations, we report results on the final checkpoint trained for 30k steps.
3. Results
We evaluate FLAN on natural language inference, reading comprehension, closed-book QA, translation, commonsense reasoning, coreference resolution, and struct-to-text. As described in §2.2, we evaluate on unseen tasks by grouping datasets into task clusters and holding out each cluster for evaluation while instruction tuning on all remaining clusters (i.e., each evaluation task cluster uses a different checkpoint). For each dataset, we evaluate the mean of performance on all templates, which proxies the expected performance given a typical natural language instruction. As a dev set is sometimes available for manual prompt engineering (Brown et al., 2020), for each dataset we also obtain the test set performance using the template with the best dev set performance.
For comparison, we report zero and few-shot results for LaMDA-PT using the same prompts as GPT-3 (as LaMDA-PT is not suitable for natural instructions without instruction tuning). This baseline provides the most direct ablation of how much instruction tuning helps. Instruction tuning significantly improves LaMDA-PT on most datasets.
We also show the zero-shot performances of GPT-3 175B (Brown et al., 2020) and GLaM 64B/64E (Du et al., 2021), as reported in their respective papers. With the best dev template, zero-shot FLAN outperforms zero-shot GPT-3 on 20 of 25 datasets and even surpasses GPT-3’s few-shot performance on 10 datasets. With the best dev-template, zero-shot FLAN outperforms zero-shot GLaM on 13 of 19 available datasets and one-shot GLaM on 11 of 19 datasets.
Overall, we observe that instruction tuning is very effective on tasks naturally verbalized as instructions (e.g., NLI, QA, translation, struct-to-text) and is less effective on tasks directly formulated as language modeling, where instructions would be largely redundant (e.g., commonsense reasoning and coreference resolution tasks that are formatted as finishing an incomplete sentence or paragraph). Results on natural language inference, reading comprehension, closed-book QA, and translation are summarized in Figure 5 and described below.

Natural language inference (NLI).
On five NLI datasets, where a model must determine whether a hypothesis is true given some premise, FLAN outperforms all baselines by a large margin. As noted by Brown et al. (2020), perhaps one reason why GPT-3 struggles with NLI is that NLI examples are unlikely to have appeared naturally in an unsupervised training set and are thus awkwardly phrased as a continuation of a sentence. For FLAN, we phrase NLI as the more natural question “Does <premise> mean that <hypothesis>?”, achieving much higher performance.
Reading comprehension.
On reading comprehension, where models are asked to answer a question about a provided passage, FLAN outperforms baselines for MultiRC (Khashabi et al., 2018) and OBQA (Mihaylov et al., 2018). On BoolQ (Clark et al., 2019a), FLAN outperforms GPT-3 by a large margin, though LaMDA-PT already achieves high performance on BoolQ.
Closed-book QA.
For closed-book QA, which asks models to answer questions about the world without access to specific information containing the answer, FLAN outperforms GPT-3 on all four datasets. Compared to GLaM, FLAN has better performance on ARC-e and ARC-c (Clark et al., 2018), and slightly lower performance on NQ (Lee et al., 2019; Kwiatkowski et al., 2019) and TQA (Joshi et al., 2017).
Translation.
Similar to GPT-3, the training data for LaMDA-PT is around 90% English and includes some text in other languages that was not specifically used to train the model to perform machine translation. We also evaluate FLAN’s performance on machine translation for the three datasets evaluated in the GPT-3 paper: French–English from WMT’14 (Bojar et al., 2014), and German– English and Romanian–English from WMT’16 (Bojar et al., 2016). Compared with GPT-3, FLAN outperforms zero-shot GPT-3 for all six evaluations, though it underperforms few-shot GPT-3 in most cases. Similar to GPT-3, FLAN shows strong results for translating into English and compares favorably against supervised translation baselines. Translating from English into other languages, however, was relatively weaker, as might be expected given that FLAN uses an English sentencepiece tokenizer and that the majority of pretraining data is English.
Additional tasks.
Although we see strong results for the above task clusters, one limitation with instruction tuning is that it does not improve performance for many language modeling tasks (e.g., commonsense reasoning or coreference resolution tasks formulated as sentence completions). For seven commonsense reasoning and coreference resolution tasks (see Table 2 in the Appendix), FLAN only outperforms LaMDA-PT on three of the seven tasks. This negative result indicates that when the downstream task is the same as the original language modeling pre-training objective (i.e., in cases where instructions are largely redundant), instruction tuning is not useful. Finally, we report results for sentiment analysis, paraphrase detection, and struct-to-text, as well as additional datasets for which GPT-3 results are not available, in Table 2 and Table 1 in the Appendix. Generally, zero-shot FLAN outperforms zero-shot LaMDA-PT and is comparable with or better than few-shot LaMDA-PT.
4. Ablation Studies & Further Analysis
4.1. Number of Instruction Tuning Clusters
As the core question of our paper asks how instruction tuning improves a model’s zero-shot performance on unseen tasks, in this first ablation we examine how performance is affected by the number of clusters and tasks used in instruction tuning. For this setup, we hold out NLI, closed-book QA, and commonsense reasoning as evaluation clusters, and use the seven remaining clusters for instruction tuning.3 We show results for one to seven instruction tuning clusters, where clusters are added in decreasing order of number of tasks per cluster.
Figure 6 shows these results. As expected, we observe that average performance across the three held-out clusters improves as we add additional clusters and tasks to instruction tuning (with the exception of the sentiment analysis cluster), confirming the benefits of our proposed instruction tuning approach on zero-shot performance on novel tasks. It is further interesting to see that, for the seven clusters we test, the performance does not appear to saturate, implying that performance may further improve with even more clusters added to instruction tuning. Of note, this ablation does not allow us to draw conclusions about which instruction tuning cluster contributes the most to each evaluation cluster, although we see minimal added value from the sentiment analysis cluster.

4.2. Scaling Laws
As Brown et al. (2020) shows that zero and few-shot capabilities of language models substantially improve for larger models, we next explore how the benefits of instruction tuning are affected by model scale. Using the same cluster split as in the previous ablation study, we evaluate the effect of instruction tuning on models of size 422M, 2B, 8B, 68B, and 137B parameters.
Figure 7 shows these results. We see that for the two models on the order of 100B parameters, instruction tuning substantially improves performance on held-out tasks, as is expected given the prior results in our paper. The behavior on held-out tasks for the 8B and smaller models, however, is thoughtprovoking—instruction tuning actually hurts performance on held-out tasks. One potential explanation for this result could be that for small-scale models, learning the ∼40 tasks used during instruction tuning fills the entire model capacity, causing these models to perform worse on new tasks. Under this potential explanation, for the larger scale models, instruction tuning fills up some model capacity but also teaches these models how to follow instructions, allowing them to generalize to new tasks with the remaining capacity.

4.3. Role of Instructions
In a final ablation study, we explore the role of instructions during finetuning, as one possibility is that performance gains come entirely from multi-task finetuning and the model could perform just as well without instructions. We hence consider two finetuning setups without instructions. In a no template setup, only inputs and outputs were given to the model (e.g., for translation the input would be “The dog runs.” and the output would be “Le chien court.”). In a dataset name setup, each input is prepended with the name of the task and dataset (e.g., for translation to French, the input would be “[Translation: WMT’14 to French] The dog runs.”).
We compare these two ablations to FLAN’s finetuning procedure, which used natural instructions (e.g., “Please translate this sentence to French: ‘The dog runs.’”). We perform evaluations for four held-out clusters from Figure 5. For the no template setup, we used the FLAN instructions during zero-shot inference (because if we used no template, the model would not know what task to perform). For models finetuned on dataset name only, we report zero-shot performance for FLAN instructions as well as using the dataset name. Figure 8 shows the results—both ablation configurations performed substantially worse than FLAN, indicating that training with instructions is crucial for zero-shot performance on unseen tasks.

4.4. Instructions with Few-shot Exemplars
So far, we have focused on instruction tuning in the zero-shot setting. Here, we study how instruction tuning can be used when few-shot exemplars are available at inference time. The format for the few-shot setting builds on the zero-shot format. For some input x and output y, let instruct(x) denote the zero-shot instructions. Then, given k few-shot exemplars (xi , yi) k i=1 and a new input x, the instruction format for the few-shot setting is “instruct(x1) ⊕ y1 ⊕ instruct(x2) ⊕ y2 ⊕ . . . ⊕ instruct(xk)⊕yk ⊕instruct(x)”, where ⊕ denotes string concatenation with a delimiter token inserted in between. At both training and inference time, exemplars are randomly drawn from the training set, and the number of exemplars is capped at 16 and such that the total sequence length is less than 960 tokens. Our experiment uses the same task splits and evaluation procedure as §3, such that few-shot exemplars for an unseen task are only used at inference time.
As shown in Figure 9, few-shot exemplars improve the performance on all task clusters, compared with zero-shot FLAN. Exemplars are especially effective for tasks with large/complex output spaces, such as struct to text, translation, and closed-book QA, potentially because exemplars help the model better understand the output format. In addition, for all task clusters, standard deviation among templates is lower for few-shot FLAN, indicating reduced sensitivity to prompt engineering.

4.5. Instruction Tuning Facilitates Prompt Tuning
As we’ve seen that instruction tuning improves the ability of a model to respond to instructions, it follows that, if FLAN is indeed more amenable to performing NLP tasks, then it should also achieve better performance when performing inference using soft prompts, represented by prepended continuous variables optimized via prompt tuning (Li & Liang, 2021; Lester et al., 2021). As further analysis, we train continuous prompts for each of the SuperGLUE (Wang et al., 2019a) tasks in accordance with the cluster splits from §2.2 such that when prompt-tuning on task T , no tasks in the same cluster as T were seen during instruction tuning. Our prompt tuning setup follows the procedure of Lester et al. (2021) except that we use a prompt length of 10, weight decay of 1e-4, and did not use dropout on the attention scores; we found in preliminary experiments that these changes improved the performance of LaMDA-PT.
Figure 10 shows the results of these prompt tuning experiments for both using a fully-supervised training set and in a low-resource setting with only 32 training examples. We see that in all scenarios, prompt tuning works better with FLAN than LaMDA-PT. In many cases, especially for the low-resource setting, prompt tuning on FLAN even achieves more than 10% improvement over prompt tuning on the LaMDA-PT. This result exemplifies in another way how instruction tuning can result in a checkpoint that is more desirable for performing NLP tasks.

5. Related Work
Our work relates to several broad research areas including zero-shot learning, prompting, multi-task learning, and language models for NLP applications (Radford et al., 2019; Raffel et al., 2020; Brown et al., 2020; Efrat & Levy, 2020; Aghajanyan et al., 2021; Li & Liang, 2021, inter alia). We describe prior work for these broad areas in an extended related work section (Appendix D), and here we describe two subareas narrower in scope that perhaps relate most closely to our work.
The way we ask a model to respond to instructions is similar to QA-based task formulation (Kumar et al., 2016; McCann et al., 2018), which aims to unify NLP tasks by casting them as QA over a context. Though these methods are very similar to ours, they mostly focus on multi-task learning instead of zero-shot learning, and—as noted by Liu et al. (2021)—they are generally not motivated by using existing knowledge in pretrained LMs. Moreover, our work supercedes recent work such as Chai et al. (2020) and Zhong et al. (2021) in terms of both model scale and scope of tasks.
The success of language models has led to nascent research on the ability of models to follow instructions. Most recently, Mishra et al. (2021) finetune 140M parameter BART on instructions with few-shot exemplars, and evaluate its few-shot abilities on unseen tasks—this is similar to our few-shot instruction tuning result from §4.4. This promising result (as well as one from Ye et al. (2021), which does not emphasize instructions as much) suggests that finetuning on a collection of tasks improves few-shot performance on unseen tasks, even at a smaller model scale. Sanh et al. (2021) finetune T5 in a setup similar to ours, finding that zero-shot learning can be improved in a model of 11B parameters. At a model scale similar to ours, OpenAI’s InstructGPT models are trained via both finetuning and reinforcement learning to produce outputs that are more preferred by human raters (Ouyang et al., 2022).
6. Discussion
Our paper has explored a simple question in zero-shot prompting: does finetuning a model on a collection of tasks phrased as instructions improve its performance on unseen tasks? We operationalize this question via instruction tuning, a simple method that combines appealing aspects of both the pretrain–finetune and prompting paradigms. Our instruction-tuned model, FLAN, improves performance against an untuned model and surpasses zero-shot GPT-3 on the majority of tasks that we evaluate on. Ablation studies reveal that performance on unseen tasks improves with the number of instruction tuning task clusters, and, interestingly, that performance improvements from instruction tuning emerge only with sufficient model scale. Moreover, instruction tuning can be combined with other prompting methods such as few-shot prompting and prompt tuning.
The diverse capabilities of language models at scale have drawn attention to the tradeoffs between specialist models (one model per task) and generalist models (one model for many tasks; Arivazhagan et al., 2019; Pratap et al., 2020), for which our study has potential implications. Although one might expect labeled data to have the most natural role in improving specialist models, instruction tuning demonstrates how labeled data can be used to help large language models perform many, unseen tasks. In other words, the positive effect of instruction tuning on cross-task generalization shows that task-specific training is complementary to general language modeling and motivates further research on generalist models.
As for limitations of our study, there is a degree of subjectivity in assigning tasks to clusters (though we try to use accepted categorizations in the literature), and we only explore the use of relatively short instructions of typically a single sentence (c.f. detailed instructions given to crowd-workers). A limitation for our evaluation is that individual examples might have appeared in the models’ pretraining data, which includes web documents, though in post-hoc analysis (Appendix C) we do not find any evidence that data overlap substantially impacted the results. Finally, the scale of FLAN 137B makes it costly to serve. Future work on instruction tuning could include gathering/generating even more task clusters for finetuning, cross-lingual experiments, using FLAN to generate data for training downstream classifiers, and using finetuning to improve model behavior with respect to bias and fairness (Solaiman & Dennison, 2021).
7. Conclusions
This paper has explored a simple method for improving the ability of language models at scale to perform zero-shot tasks based purely on instructions. Our instruction-tuned model, FLAN, compares favorably against GPT-3 and signals the potential ability for language models at scale to follow instructions. We hope that our paper will spur further research on instructions-based NLP, zero-shot learning, and using labeled data to improve large language models.
D. Extended Related Work
D.1. Language Models and Multi-task Learning
Our work is broadly inspired by a long line of prior work on language models for NLP applications (Dai & Le, 2015; Peters et al., 2018; Howard & Ruder, 2018; Radford et al., 2018; 2019, inter alia). Instruction tuning can be seen as a formulation of multitask learning (MTL), which is an established area within deep learning (Collobert et al., 2011; Luong et al., 2016; Ruder, 2017; Velay & Daniel, 2018; Clark et al., 2019b; Liu et al., 2019b, inter alia)—see Worsham & Kalita (2020) for a recent survey on MTL for NLP. Differing from prior MTL work which focuses on performance improvements across training tasks (Raffel et al., 2020; Aghajanyan et al., 2021) or to new domains (Axelrod et al., 2011), our work is motivated by improving zero-shot generalization to tasks that were not seen in training.
D.2. Zero-shot Learning and Meta-learning
Our work also falls in the well-established category of zero-shot learning, which has historically been used to refer to classifying instances among a set of unseen categories (Lampert et al., 2009; Romera-Paredes & Torr, 2015; Srivastava et al., 2018; Yin et al., 2019, inter alia). In NLP, zero-shot learning work also includes translating between unseen language pairs (Johnson et al., 2017; Pham et al., 2019), language modeling on unseen languages (Lauscher et al., 2020), as well as various NLP applications (Liu et al., 2019a; Corazza et al., 2020; Wang et al., 2021). Most recently, the emergent ability of language models (Brown et al., 2020) has led to increased interest in how models generalize to unseen tasks, the definition of zero-shot learning used in our paper. In addition, meta-learning (Finn et al., 2017; Vanschoren, 2018, inter alia) also broadly tries to train models that adapt quickly to unseen tasks, typically based on a few examples.
D.3. Prompting
Instruction tuning leverages the intuition that language models at scale contain substantial world knowledge and can perform a range of NLP tasks (Brown et al., 2020, see also Bommasani et al. (2021)). Another line of work that shares this goal prompts models with continuous inputs optimized via backpropagation to substantially improve performance (Li & Liang, 2021; Lester et al., 2021; Qin & Eisner, 2021), as well as work that prompts models to produce specialized outputs (Wei et al., 2022). Although the success of these approaches depends heavily on model scale (Lester et al., 2021), for which large models can be costly to serve, the ability of a single large model to perform many tasks slightly eases this burden. As shown by our experiments in §4.5, prompt tuning is an orthogonal method for which instruction tuning can additionally improve performance. Reif et al. (2021) is similar to our work in that they also use related tasks to improve zero-shot learning, though they differ by only using related tasks in the context (and not finetuning), and focus on the application of text style transfer.
Our work shares similar motivations with prompting in that we use inference-time text interactions to prompt a single model, without creating separate checkpoints for each task. Whereas prompting work such as GPT-3 uses prompt engineering to write prompts that intentionally mimic text that is likely to be seen during pretraining (e.g., for MultiRC GPT-3 tries a prompt that mimics a test with an answer key), we hope that finetuning models to respond to natural language instructions instead of completing a sentence will make such large models more accessible to non-technical users.
D.4. Finetuning Large Language Models
Finetuning pretrained language models is a well-established method in NLP, with much of the work so far occurring on models in the range of 100M to 10B parameters (Dai & Le, 2015; Devlin et al., 2019; Raffel et al., 2020; Lewis et al., 2020, inter alia). For models of O(100B) parameters, recent work has finetuned task-specific models for program synthesis (Austin et al., 2021; Chen et al., 2021), summarization (Wu et al., 2021), as well as improved bias and fairness behavior (Solaiman & Dennison, 2021). In addition to the traditional “dense” models, sparse mixture of experts (MoE) models of up to more than 1T parameters have been trained and finetuned (Lepikhin et al., 2020; Fedus et al., 2021). Compared with this prior work that finetunes and evaluates on the same downstream task, our setup studies the effect of instruction tuning on ability to perform unseen tasks.
D.5. Multi-task Question Answering
The instructions we use for instruction tuning are similar to QA-based task formulation research, which aims to unify NLP tasks by casting them as question-answering over a context. For instance, McCann et al. (2018) cast ten NLP tasks as QA and train a model on a collection of tasks formulated with natural language prompts; they report transfer learning gains on finetuning tasks as well as zero-shot domain adaptation results on SNLI (Bowman et al., 2015) and Amazon/Yelp Reviews (Kotzias et al., 2015). While McCann et al. (2018) does not leverage unsupervised pre-training and only reports zero-shot transfer to unseen domains, our work uses a pretrained LM and focuses on zero-shot performance on unseen task clusters. UnifiedQA (Khashabi et al., 2020) shows similar transfer learning gains as McCann et al. (2018) across 20 datasets and reports good generalization to unseen tasks across four types of QA. Focusing on binary text classification, Zhong et al. (2021) finetune T5-770M on 43 tasks phrased as yes/no questions and study the zero-shot performance on unseen tasks. In comparison, our paper is much larger in scope, empirically demonstrating the idea on a wide range of tasks with a much larger model. Other work has used QA-based task formulation for more-targeted applications including semantic role labeling (He et al., 2015), relation extraction (Levy et al., 2017), coreference resolution (Wu et al., 2020) and named entity recognition (Li et al., 2020) as question answering.
D.6. Instructions-based NLP
Recent improvements in the capabilities of language models have led to increased interest in a nascent area of instructions-based NLP (Goldwasser & Roth, 2014, and see McCarthy (1960)). Schick & Schütze (2021) (also see Gao et al., 2021; Tam et al., 2021) use task descriptions in cloze-style phrases to help language models assign soft labels for few-shot and semi-supervised learning, though this line of work finetunes new checkpoints for each downstream task. Efrat & Levy (2020) evaluated GPT-2 (Radford et al., 2019) on simple tasks ranging from retrieving the nth word of a sentence to generating examples for SQuAD, concluding that GPT-2 performs poorly across all tasks.
In terms of the setup of finetuning on a large number of tasks and evaluating on unseen tasks, two recent papers are similar to ours. Mishra et al. (2021) finetune BART (Lewis et al., 2020) using instructions and few-shot examples for tasks such as question answering, text classification, and text modification, and find that this few-shot finetuning with instructions improves performance on unseen tasks. Ye et al. (2021) introduce a setup for cross-task few-shot learning, finding that multi-task meta-learning using MAML (Finn et al., 2017) improves the few-shot capabilities of BART on unseen downstream tasks. Our work differs from these two papers in that we focus on zero-shot learning, for which we observe the crucial importance of model scale (FLAN is 1,000x larger than BART-base).
Perhaps the papers most related to ours are the recent Sanh et al. (2021) and Min et al. (2021), which were released after our initial preprint. Min et al. (2021) finetunes GPT-2 Large (770M parameters) to be a few-shot learner, which is the same approach as our experiment in Section 4.3. Similar to our conclusions, they also observe that including few-shot exemplars and instruction tuning are complementary ways to improve performance. Sanh et al. (2021) propose to finetune T5-11B to respond to prompts, and they also report performance improvements on zero-shot learning. These two papers and our work all study finetuning with instructions, but, as noted by Min et al. (2021), it is hard to directly compare results, due to differing model sizes, model types (decoder-only vs encoder-decoder), pretraining data, task mixtures, and type of instructions (Sanh et al. (2021) say that their instructions are more diverse).
Finally, OpenAI has a model called InstructGPT (Ouyang et al., 2022). InstructGPT uses human anntations to guide desired model behavior, both via finetuning and reinforcement learning, finding that InstructGPT is preferred by human rathers compared with unmodified GPT-3.
E. Frequently Asked Questions
How do the FLAN instructions differ from GPT-3 or T5 prompts?
GPT-3 prompting is done in a way such that the prompt looks like data that the model has been pretrained on, and the model finishes the continuation. T5 prompts are mostly just a tag for the dataset, which would not work in the zero-shot setting. In contrast, the prompts that we use for FLAN are similar to what would be used to ask a human to perform the task.
For instance, given an input for an NLI task, these would be the prompts.
T5 prompt: cb hypothesis: At my age you will probably have learnt one lesson. premise: It’s not certain how many lessons you’ll learn by your thirties.
GPT-3 prompt: At my age you will probably have learnt one lesson. question: It’s not certain how many lessons you’ll learn by your thirties. true, false, or neither? answer:
FLAN prompt: Premise: At my age you will probably have learnt one lesson. Hypothesis: It’s not certain how many lessons you’ll learn by your thirties. Does the premise entail the hypothesis?
So because FLAN prompts are formulated as responding to an instruction, they do not work well for pretrained language models without finetuning. Performance was near zero for most generation tasks. For instance, given the input “‘The dog runs.’ Translate this sentence to French.”, LaMDA-PT continues with ”The dog runs after the cat” instead of actually translating the sentence. Hence, we used the established GPT-3 prompts for our LaMDA-PT baselines.
What are some limitations/failure cases of FLAN?
While we qualitatively find that FLAN responds well to most tasks, it does fail on some simple tasks. For instance, as shown in Figure 22, FLAN fails at the very simple task of returning the second word in a sentence, and also incorrectly translates a question to Danish when asked to answer the question in Danish. Additional limitations include a context length of only 1024 tokens (which is not enough for most summarization tasks), and that the model was mostly trained on English data.
Can FLAN be used when large amounts of training data are available?
In this work, we focus on cross-task generalization to zero-shot tasks, but we also believe that instruction tuning could result in positive task transfer among seen tasks, depending on the mixture of tasks (though we leave this for future work). In §4.5, where we apply prompt tuning to the FLAN checkpoint, we see promising results that indicate positive task transfer in a supervised setting.
Are the ten unique templates per dataset or per task cluster?
The ten unique templates are for each dataset and not for a task cluster. This is because datasets in the same task cluster often differed slightly (e.g., “is this movie review positive” vs “is this yelp review positive”).
In Figure 7A, why does the untuned LaMDA-PT model see worse performance with more parameters for reading comprehension and sentiment analysis?
For context, Figure 7A is a check of correctness for Figure 7B. Figure 7A confirms that scale improves performance for tasks that were seen during instruction tuning, as expected. The untuned LaMDA-PT model performance in Figure 7A is shown just for completeness.
Nonetheless, the fact that scale does not always improve zero-shot performance of untuned LaMDA-PT is an interesting artifact. Initially, we were surprised, because Brown et al. (2020) shows that scale improves performance across a large number of tasks in aggregate.
It turns out that scale does not improve performance for certain tasks. This is especially true for zero-shot learning, and we think that this happens to be the case for the reading comprehension and sentiment analysis tasks we evaluate. The GPT-3 paper itself similarly reports that zero-shot performance on BoolQ and DROP decreases from 13B to 175B parameters. The GPT-3 paper does not show results on sentiment analysis, but Holtzman et al. (2021) find that zero-shot performance on SST-2 also gets worse from 13B to 175B parameters. Hence, this artifact is consistent across both GPT-3 and the models we use.
This artifact is certainly worth further study, but is outside the scope of instruction tuning. Ideally, we would have performed the Figure 7 ablation with cross-validation instead of a single split, which likely would have smoothed out that artifact.
F. Qualitative Examples
This section shows qualitative examples of FLAN responding to various prompts.







G. Tasks and Datasets
This appendix further details the datasets that we use in this paper. We group datasets into one of the following task clusters:
• Natural language inference
concerns how two sentences relate, typically asking, given a first sentence, whether a second sentence is true, false, or possibly true. We use the following datasets:
1. ANLI (Nie et al., 2020)
2. CB (De Marneffe et al., 2019)
3. MNLI (Williams et al., 2018)
4. QNLI (Rajpurkar et al., 2018)
5. SNLI (Bowman et al., 2015)
6. WNLI (Levesque et al., 2012)
7. RTE (Dagan et al., 2005; Haim et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., 2009)
• Reading comprehension
tests the ability to answer a question when given a passage that contains the answer. We use the following datasets:
1. BoolQ Clark et al. (2019a)
2. DROP (Dua et al., 2019)
3. MultiRC (Khashabi et al., 2018)
4. OBQA (Mihaylov et al., 2018)
5. SQuADv1 (Rajpurkar et al., 2016)
6. SQuADv2 (Rajpurkar et al., 2018)
• Commonsense reasoning
evaluates the ability to perform physical or scientific reasoning with an element of common sense. We use the following datasets:
1. COPA (Roemmele et al., 2011)
2. HellaSwag (Zellers et al., 2019)
3. PiQA (Bisk et al., 2020)
4. StoryCloze (Mostafazadeh et al., 2016)
• Sentiment analysis
is a classic NLP task aims to understand whether a piece of text is positive or negative. We use the following datasets:
1. IMDB (Maas et al., 2011)
2. Sentiment140 (Go et al., 2009)
3. SST-2 (Socher et al., 2013)
4. Yelp (Fast.AI)
• Closed-book QA
asks models to answer questions about the world without specific access to information that contains the answer. We use the following datasets:
1. ARC (Clark et al., 2018)
2. NQ (Lee et al., 2019; Kwiatkowski et al., 2019)
3. TriviaQA Joshi et al. (2017)
• Paraphrase detection
asks a model to determine whether two sentences are semantically equivalent.4 We use the following datasets:
1. MRPC (Dolan & Brockett, 2005)
2. QQP (Wang et al., 2018, see)
3. Paws Wiki (Zhang et al., 2019)
• Coreference resolution
tests the ability to identify expressions of the same entity in some given text. We use the following datasets: 1. DPR (Rahman & Ng, 2012)
2. Winogrande (Sakaguchi et al., 2020)
3. WSC273 (Levesque et al., 2012)
• Reading comprehension with commonsense
combines elements of both reading comprehension with commonsense. We use the following datasets:
1. CosmosQA (Huang et al., 2019)
2. ReCoRD (Zhang et al., 2018)
• Struct to text
tests the ability to describe some structured data using natural language. We use the following datasets:
1. CommonGen (Lin et al., 2020)
2. DART (Nan et al., 2021)
3. E2ENLG (Dušek et al., 2019)
4. WebNLG (Gardent et al., 2017)
• Translation
is the task of translating text from one language into a different language. We use the following datasets:
1. En–Fr from WMT’14 (Bojar et al., 2014)
2. En–De, En–Tr, En–Cs, En–Fi, En–Ro, and En–Ru from WMT’16 (Bojar et al., 2016)
3. En–Es from Paracrawl (Bañón et al., 2020)
• Summarization
asks models to read a piece of text and generate an abbreviated summary of it. We use the following datasets:
1. AESLC (Zhang & Tetreault, 2019)
2. CNN-DM (See et al., 2017)
3. Gigaword (Napoles et al., 2012)
4. MultiNews (Fabbri et al., 2019)
5. Newsroom (Grusky et al., 2018)
6. Samsum (Gliwa et al., 2019)
7. XSum (Narayan et al., 2018)
8. AG News (Zhang et al., 2015)
9. Opinion Abstracts - Rotten Tomatoes (Wang & Ling, 2016)
10. Opinion Abstracts - iDebate (Wang & Ling, 2016)
11. Wiki Lingua English (Ladhak et al., 2020)
• Additional datasets
that we assign to a miscellaneous task cluster include:
1. Conversational question-answering: QuAC (Choi et al., 2018) and CoQA (Reddy et al., 2019)
2. Evaluating context-sentence word meanings: WiC (Pilehvar & Camacho-Collados, 2019)
3. Question classification: TREC (Li & Roth, 2002; Hovy et al., 2001)
4. Linguistic acceptability: CoLA (Warstadt et al., 2019)
5. Math questions (Saxton et al., 2019)
For all tasks, our finetuning and evaluation code uses tensorflow datasets (TFDS) to load and process datasets. Regarding the number of training examples per dataset, we limited the training set size per dataset to 30,000 so that no dataset dominated the finetuning distribution. When a test set with labels was available in TFDS, we used it; otherwise, we used the TFDS validation set as our test set, splitting the training set into a train and dev set.
On the following pages, we show inputs and outputs for evaluation tasks where we compared with GPT-3. See the attached supplementary material for the templates for all other datasets.
G.1. Natural Language Inference



G.2. Reading Comprehension



G.3. Commonsense Reasoning



G.4. Closed-Book QA


G.5. Coreference Resolution

G.6. Reading Comprehension with Commonsense

G.7. Translation (7 Languages)

'Research > NLP_Paper' 카테고리의 다른 글