-
Large Language Models are Zero-Shot ReasonersResearch/NLP_Paper 2024. 7. 26. 00:22
https://arxiv.org/pdf/2205.11916
Abstract
Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique for eliciting complex multi-step reasoning through step-by-step answer examples, achieved the state-of-the-art performances in arithmetics and symbolic reasoning, difficult system-2 tasks that do not follow the standard scaling laws for LLMs. While these successes are often attributed to LLMs’ ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding “Let’s think step by step” before each answer. Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with large-scale InstructGPT model (text-davinci002), as well as similar magnitudes of improvements with another off-the-shelf large model, 540B parameter PaLM. The versatility of this single prompt across very diverse reasoning tasks hints at untapped and understudied fundamental zero-shot capabilities of LLMs, suggesting high-level, multi-task broad cognitive capabilities may be extracted by simple prompting. We hope our work not only serves as the minimal strongest zero-shot baseline for the challenging reasoning benchmarks, but also highlights the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars.
1. Introduction
Scaling up the size of language models has been key ingredients of recent revolutions in natural language processing (NLP) [Vaswani et al., 2017, Devlin et al., 2019, Raffel et al., 2020, Brown et al., 2020, Thoppilan et al., 2022, Rae et al., 2021, Chowdhery et al., 2022]. The success of large language models (LLMs) is often attributed to (in-context) few-shot or zero-shot learning. It can solve various tasks by simply conditioning the models on a few examples (few-shot) or instructions describing the task (zero-shot). The method of conditioning the language model is called “prompting” [Liu et al., 2021b], and designing prompts either manually [Schick and Schütze, 2021, Reynolds and McDonell, 2021] or automatically [Gao et al., 2021, Shin et al., 2020] has become a hot topic in NLP.
In contrast to the excellent performance of LLMs in intuitive and single-step system-1 [Stanovich and West, 2000] tasks with task-specific few-shot or zero-shot prompting [Liu et al., 2021b], even language models at the scale of 100B or more parameters had struggled on system-2 tasks requiring slow and multi-step reasoning [Rae et al., 2021]. To address this shortcoming, Wei et al. [2022], Wang et al. [2022] have proposed chain of thought prompting (CoT), which feed LLMs with the step-by-step reasoning examples rather than standard question and answer examples (see Fig. 1-a). Such chain of thought demonstrations facilitate models to generate a reasoning path that decomposes the complex reasoning into multiple easier steps. Notably with CoT, the reasoning performance then satisfies the scaling laws better and jumps up with the size of the language models. For example, when combined with the 540B parameter PaLM model [Chowdhery et al., 2022], chain of thought prompting significantly increases the performance over standard few-shot prompting across several benchmark reasoning tasks, e.g., GSM8K (17.9% → 58.1%).
While the successes of CoT prompting [Wei et al., 2022], along those of many other task-specific prompting work [Gao et al., 2021, Schick and Schütze, 2021, Liu et al., 2021b], are often attributed to LLMs’ ability for few-shot learning [Brown et al., 2020], we show that LLMs are decent zero-shot reasoners by adding a simple prompt, Let’s think step by step, to facilitate step-by-step thinking before answering each question (see Figure 1). Despite the simplicity, our Zero-shot-CoT successfully generates a plausible reasoning path in a zero-shot manner and reaches the correct answer in a problem where the standard zero-shot approach fails. Importantly, our Zero-shot-CoT is versatile and task-agnostic, unlike most prior task-specific prompt engineering in the forms of examples (few-shot) or templates (zero-shot) [Liu et al., 2021b]: it can facilitate step-by-step answers across various reasoning tasks, including arithmetic (MultiArith [Roy and Roth, 2015], GSM8K [Cobbe et al., 2021], AQUA-RAT [Ling et al., 2017], and SVAMP [Patel et al., 2021]), symbolic reasoning (Last letter and Coin flip), commonsense reasoning (CommonSenseQA [Talmor et al., 2019] and Strategy QA [Geva et al., 2021]), and other logical reasoning tasks (Date understanding and Tracking Shuffled Objects from BIG-bench [Srivastava et al., 2022]) without modifying the prompt per task.
We empirically evaluate Zero-shot-CoT against other prompting baselines in Table 2. While our Zero-shot-CoT underperforms Few-shot-CoT with carefully-crafted and task-specific step-by-step examples, Zero-shot-CoT achieves enormous score gains compared to the zero-shot baseline, e.g. from 17.7% to 78.7% on MultiArith and from 10.4% to 40.7% on GSM8K with large-scale InstructGPT model (text-davinci-002). We also evaluate Zero-shot-CoT with another off-the-shelf large model, 540B parameter PaLM, showing similar magnitudes of improvements on MultiArith and GSM8K. Importantly, with our single fixed prompt, zero-shot LLMs have a significantly better scaling curve comparable to that of the few-shot CoT baseline. We also show that besides Few-shot-CoT requiring human engineering of multi-step reasoning prompts, their performance deteriorates if prompt example question types and task question type are unmatched, suggesting high sensitivity to per-task prompt designs. In contrast, the versatility of this single prompt across diverse reasoning tasks hints at untapped and understudied zero-shot fundamental capabilities of LLMs, such as higher-level broad cognitive capabilities like generic logical reasoning [Chollet, 2019]. While the vibrant field of LLMs started out from the premise of excellent few-shot learners [Brown et al., 2020], we hope our work encourages more research into uncovering high-level and multi-task zero-shot capabilities hidden inside those models.

2. Background
We briefly review the two core preliminary concepts that form the basis of this work: the advent of large language models (LLMs) and prompting, and chain of thought (CoT) prompting for multi-step reasoning.
Large language models and prompting
A language model (LM), is a model that looks to estimate the probability distribution over text. Recently, scaling improvements through larger model sizes (from a few million [Merity et al., 2016] to hundreds of millions [Devlin et al., 2019] to hundreds of billions [Brown et al., 2020] parameters) and larger data (e.g. webtext corpora [Gao et al., 2020]) have enabled pre-trained large language models (LLMs) to be incredibly adept at many downstream NLP tasks. Besides the classic “pre-train and fine-tune” paradigm [Liu et al., 2021b], models scaled to 100B+ parameters exhibit properties conducive to few-shot learning [Brown et al., 2020], by way of in context learning, where one can use a text or template known as a prompt to strongly guide the generation to output answers for desired tasks, thus beginning an era of “pre-train and prompt” [Liu et al., 2021a]. In work, we call such prompts with explicit conditioning on few task examples as few-shot prompts, and other template-only prompts as zero-shot prompts.
Chain of thought prompting
Multi-step arithmetic and logical reasoning benchmarks have particularly challenged the scaling laws of large language models [Rae et al., 2021]. Chain of thought (CoT) prompting [Wei et al., 2022], an instance of few-shot prompting, proposed a simple solution by modifying the answers in few-shot examples to step-by-step answers, and achieved significant boosts in performance across these difficult benchmarks, especially when combined with very large language models like PaLM [Chowdhery et al., 2022]. The top row of Figure 1 shows standard few-shot prompting against (few-shot) CoT prompting. Notably, few-shot learning was taken as a given for tackling such difficult tasks, and the zero-shot baseline performances were not even reported in the original work [Wei et al., 2022]. To differentiate it from our method, we call Wei et al. [2022] as Few-shot-CoT in this work.
3. Zero-shot Chain of Thought
We propose Zero-shot-CoT, a zero-shot template-based prompting for chain of thought reasoning. It differs from the original chain of thought prompting [Wei et al., 2022] as it does not require step-by-step few-shot examples, and it differs from most of the prior template prompting [Liu et al., 2021b] as it is inherently task-agnostic and elicits multi-hop reasoning across a wide range of tasks with a single template. The core idea of our method is simple, as described in Figure 1: add Let’s think step by step, or a a similar text (see Table 4), to extract step-by-step reasoning.
3.1. Two-stage prompting
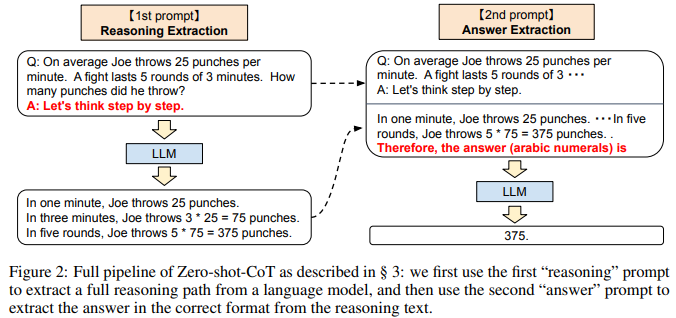
While Zero-shot-CoT is conceptually simple, it uses prompting twice to extract both reasoning and answer, as explained in Figure 2. In contrast, the zero-shot baseline (see the bottom-left in Figure 1) already uses prompting in the form of “The answer is”, to extract the answers in correct formats. Few-shot prompting, standard or CoT, avoids needing such answer-extraction prompting by explicitly designing the few-shot example answers to end in such formats (see the top-right and top-left in Figure 1). In summary, Few-shot-CoT [Wei et al., 2022] requires careful human engineering of a few prompt examples with specific answer formats per task, while Zero-shot-CoT requires less engineering but requires prompting LLMs twice.
1st prompt: reasoning extraction
In this step we first modify the input question x into a prompt x' using a simple template “Q: [X]. A: [T]”, where [X] is an input slot for x and [T] is an slot for hand-crafted trigger sentence t that would extract chain of thought to answer the question x. For example, if we use “Let’s think step by step” as a trigger sentence, the prompt x' would be “Q: [X]. A: Let’s think step by step.”. See Table 4 for more trigger examples. Prompted text x' is then fed into a language model and generate subsequent sentence z. We can use any decoding strategy, but we used greedy decoding throughout the paper for the simplicity.
2nd prompt: answer extraction
In the second step, we use generated sentence z along with prompted sentence x' to extract the final answer from the language model. To be concrete, we simply concatenate three elements as with “[X'] [Z] [A]”: [X'] for 1st prompt x' , [Z] for sentence z generated at the first step, and [A] for a trigger sentence to extract answer. The prompt for this step is self-augmented, since the prompt contains the sentence z generated by the same language model. In experiment, we use slightly different answer trigger depending on the answer format. For example, we use “Therefore, among A through E, the answer is” for multi-choice QA, and “Therefore, the answer (arabic numerals) is” for math problem requiring numerical answer. See Appendix A.5 for the lists of answer trigger sentences. Finally, the language model is fed the prompted text as input to generate sentences ˆy and parse the final answer. See “Answer Cleansing” at §4 for the parser details.
4. Experiment
Tasks and datasets
We evaluate our proposal on 12 datasets from four categories of reasoning tasks: arithmetic, commonsense, symbolic, and other logical reasoning tasks. See Appendix A.2 for the detailed description of each datasets.
For arithmetic reasoning, we consider the following six datasets: (1) SingleEq [Koncel-Kedziorski et al., 2015], (2) AddSub [Hosseini et al., 2014], (3) MultiArith [Roy and Roth, 2015], (4) AQUARAT [Ling et al., 2017], (5) GSM8K [Cobbe et al., 2021], and (6) SVAMP [Patel et al., 2021]. The first three are from the classic Math World Problem Repository [Koncel-Kedziorski et al., 2016], and the last three are from more recent benchmarks. SingleEq and AddSub contain easier problems, which do not require multi-step calculation to solve the tasks. MultiArith, AQUA-RAT, GSM8k, and SVAMP are more challenging datasets that require multi-step reasoning to solve.
For commonsense reasoning, we use CommonsenseQA [Talmor et al., 2019] and StrategyQA [Geva et al., 2021]. CommonsenseQA asks questions with complex semantics that often require reasoning based on prior knowledge [Talmor et al., 2019]. StrategyQA requires models to infer an implicit multi-hop reasoning to answer questions [Geva et al., 2021].
For symbolic reasoning, we use Last Letter Concatenation and Coin Flip [Wei et al., 2022]. Last letter Concatenation asks the model to concatenate the last letters of each word. We used randomly selected four names for each sample. Coin Flip asks the model to answer whether a coin is still heads up after people either flip or do not flip the coin. We created samples of four times flip or not flip trials. Although these tasks are easy for humans, LMs typically exhibit a flat scaling curve.
For other logical reasoning tasks, we choose two evaluation sets from the BIG-bench effort [Srivastava et al., 2022]: Date Understanding 2 and Tracking Shuffled Objects. Date Understanding asks models to infer the date from a context. Tracking Shuffled Objects tests a model’s ability to infer the final state of objects given its initial state and a sequence of object shuffling. We used a dataset of tracking three shuffled objects for our experiment.
Models
We experiment with 17 models in total. Main experiments are conducted with InstructGPT3 [Ouyang et al., 2022] (text-ada/babbage/curie/davinci-001 and text-davinci-002)3 , original GPT3 [Brown et al., 2020] (ada, babbage, curie, and davinci)4 , and PaLM [Chowdhery et al., 2022] (8B, 62B, and 540B). In addition, we used GPT-2[Radford et al., 2019], GPT-Neo[Black et al., 2021], GPT-J[Wang and Komatsuzaki, 2021], T0 [Sanh et al., 2022], and OPT [Zhang et al., 2022] for model scaling study. The size of LMs ranges from 0.3B to 540B. We include both standard (e.g. GPT-3 and OPT), and instruction following variants (e.g. Instruct-GPT3 and T0). See Appendix A.3 for model description details. Unless otherwise stated, we use text-davinci-002 throughout the experiments.
Baselines
We compare our Zero-shot-CoT mainly to standard Zero-shot prompting to verify the effectiveness of its chain of thought reasoning. For Zero-shot experiments, similar answer prompts as Zero-shot-CoT are used as default. See Appendix A.5 for detail. To better evaluate the zero-shot ability of LLMs on reasoning tasks, we also compare our method to Few-shot and Few-shot-CoT baselines from [Wei et al., 2022], using the same in-context examples. Throughout the experiments, we use greedy decoding across all the methods. For the zero-shot approaches, the results are therefore deterministic. For the few-shot approaches, since the order of in-context examples could affect the results [Lu et al., 2022], we run each experiment only once with a fixed seed across all methods and datasets, for fair comparisons with the zero-shot methods. Wei et al. [2022] showed that the order of examples did not cause large variance in CoT experiments.
Answer cleansing
After the model outputs a text by answer extraction (see § 3 and Figure 2), our method picks up only the part of the answer text that first satisfies the answer format. For example, if the answer prompting outputs “probably 375 and 376” on arithmetic tasks, we extract the first number “375” and set it as the model prediction. In the case of multiple-choice, the first large letter we encounter is set as the prediction. See Appendix A.6 for more detail. Standard Zero-shot method follows the same idea. For Few-shot and Few-shot-CoT methods, we follow [Wang et al., 2022] and first extract the answer text after "The answer is " from the model output, and apply the same answer cleansing to parse the answer text. If “The answer is” is not found in the model output, we search from the back of the text and set the first text that satisfies the answer format as the prediction.
4.1. Results
Zero-shot-CoT vs. Zero-shot
Table 1 summarize accuracy of our method (Zero-shot-CoT) and standard zero-shot prompting (Zero-shot) for each dataset. Zero-shot-CoT substantially outperforms four out of six arithmetic reasoning tasks (MultiArith, GSM8K, AQUA, SVAMP), all symbolic reasoning, and all other logical reasoning tasks (from BIG-bench [Srivastava et al., 2022]). For example, Zero-shot-CoT achieves score gains from 17.7% to 78.7% on MultiArith and from 10.4% to 40.7% on GSM8K. Our method gives on-par performances for the remaining two arithmetic reasoning tasks (SingleEq and AddSub), which is expected since they do not require multi-step reasoning.
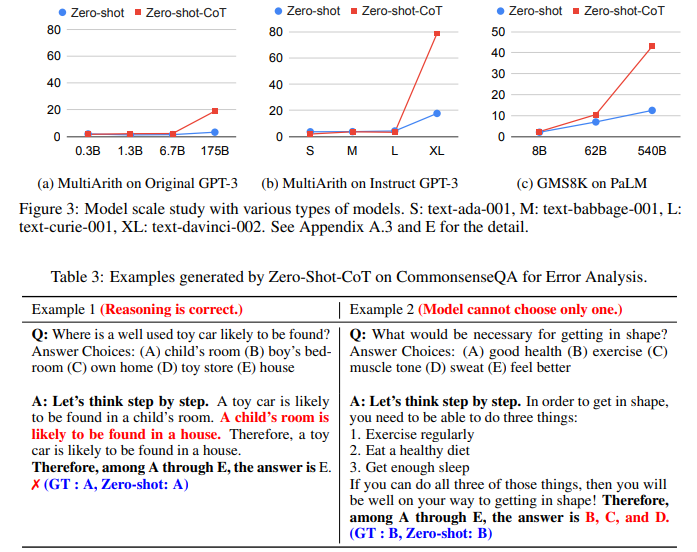
In commonsense reasoning tasks, Zero-shot-CoT does not provide performance gains. It is expected as Wei et al. [2022] also reports that even Few-shot-CoT does not provide performance gains on Lambda (135B), but does improve StrategyQA when combined with substantially larger PaLM (540B) model, which may also apply for ours. More importantly, we observe that many generated chain of thought themselves are surprisingly logically correct or only contains human-understandable mistakes (See Table 3), suggesting that Zero-shot-CoT does elicit for better commonsense reasoning even when the task metrics do not directly reflect it. We provide samples generated by Zero-shot-CoT for each dataset in Appendix B.


Comparison with other baselines
Table 2 compares the performances on two arithmetic reasoning benchmarks (MultiArith and GSM8K) across Zero-shot-CoT and baselines. The large gap between standard prompting (1st block) and chain of thought prompting (2nd block) suggests that these tasks are difficult without eliciting multi-step reasoning. Major improvements are confirmed on both Instruct GPT-3 (text-davinci-002) and PaLM (540B) models (4th block). While Zero-shot-CoT naturally underperforms Few-shot-CoT, it substantially outperforms standard Few-shot prompting with even 8 examples per task. For GSM8K, Zero-shot-CoT with Instruct GPT-3 (text-davinci-002) also outperforms finetuned GPT-3 and standard few-shot prompting with large models (PaLM, 540B), reported in Wei et al. [2022] (3rd and 4th block). See App. D for more experiment results with PaLM.
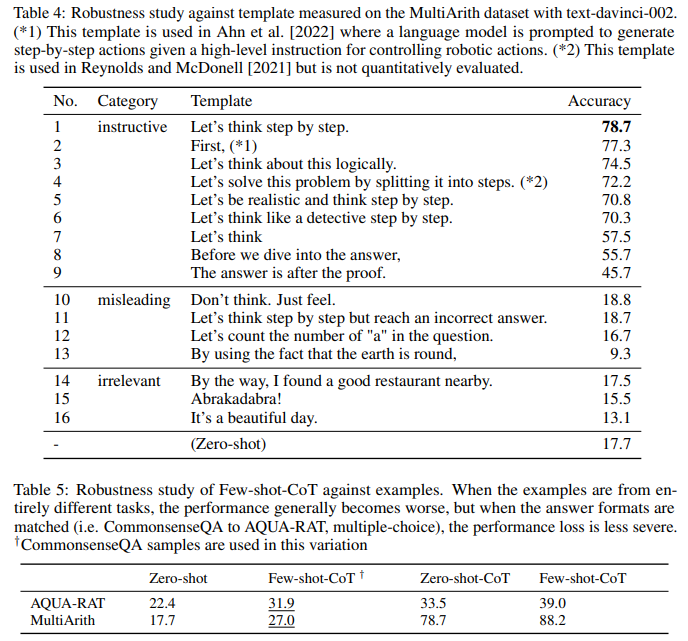
Does model size matter for zero-shot reasoning?
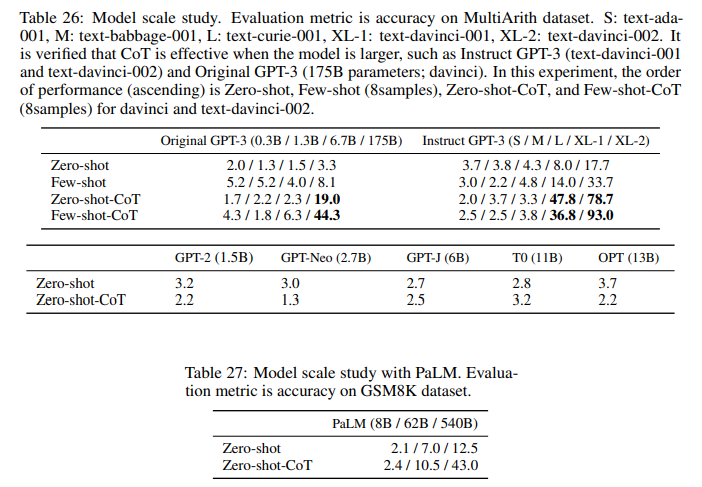
Figure 3 compares performance of various language models on MultiArith / GSM8K. Without chain of thought reasoning, the performance does not increase or increases slowly as the model scale is increased, i.e., the curve is mostly flat. In contrast, the performance drastically increases with chain of thought reasoning, as the model size gets bigger, for Original/Instruct GPT-3 and PaLM. When the model size is smaller, chain of thought reasoning is not effective. This result aligns with the few-shot experiment results in Wei et al. [2022]. Appendix E shows extensive experiment results using wider variety of language models, including GPT-2, GPT-Neo, GPT-J, T0, and OPT. We also manually investigated the quality of generated chain of thought, and large-scale models clearly demonstrate better reasoning (See Appendix B for the sampled outputs for each model).
Error Analysis
To better understand the behavior of Zero-shot-CoT, we manually investigated randomly selected examples generated by Instruct-GPT3 with Zero-shot-CoT prompting. See Appendix C for examples, where some of the observations include: (1) In commonsense reasoning (CommonsenseQA), Zero-shot-CoT often produces flexible and reasonable chain of thought even when the final prediction is not correct. Zero-shot-CoT often output multiple answer choices when the model find it is difficult to narrow it down to one (see Table 3 for examples). (2) In arithmetic reasoning (MultiArith), Zero-shot-CoT and Few-shot-CoT show substantial differences regarding the error patterns. First, Zero-shot-CoT tends to output unnecessary steps of reasoning after getting the correct prediction, which results in changing the prediction to incorrect one. Zero-shot-CoT also sometimes does not start reasoning, just rephrasing the input question. In contrast, Few-shot-CoT tend to fail when generated chain of thought include ternary operation, e.g. (3 + 2) ∗ 4.
How does prompt selection affect Zero-shot-CoT?
We validate the robustness of Zero-shot-CoT against input prompts. Table 4 summarizes performance using 16 different templates with three categories. Specifically, following Webson and Pavlick [2022], the categories include instructive (encourage reasoning), misleading (discourage reasoning or encouraging reasoning but in a wrong way), and irrelevant (nothing to do with reasoning). The results indicate that the performance is improved if the text is written in a way that encourages chain of thought reasoning, i.e., the templates are within "instructive" category. However, the difference in accuracy is significant depending on the sentence. In this experiment, "Let’s think step by step." achieves the best results. Interestingly, it is found that different templates encourage the model to express reasoning quite differently (see Appendix B for sample outputs by each template). In contrast, when we use misleading or irrelevant templates, the performance does not improve. It remains an open question how to automatically create better templates for Zero-shot-CoT.
How does prompt selection affect Few-shot-CoT?
Table 5 shows the performance of Fewshot-CoT when using examples from different datasets: CommonsenseQA to AQUA-RAT and CommonsenseQA to MultiArith. The domains are different in both cases, but the answer format is the same in the former. Surprisingly, the chain of thought examples from different domains (common sense to arithmetic) but with the same answer (multiple-choice) format provide substantial performance gain over Zero-shot (to AQUA-RAT), measured relative to the possible improvements from Zero-shot-CoT or Few-shot-CoT. In contrast, the performance gain becomes much less when using examples with different answer types (to MultiArith), confirming prior work [Min et al., 2022] that suggests LLMs mostly leverage the few-shot examples to infer the repeated format rather than the task itself in-context. Nevertheless, for both cases the results are worse than Zero-shot-CoT, affirming the importance of task-specific sample engineering in Few-shot-CoT.
5. Discussion and Related Work

Reasoning Ability of LLMs
Several studies have shown that pre-trained models usually are not good at reasoning [Brown et al., 2020, Smith et al., 2022, Rae et al., 2021], but its ability can be substantially increased by making them produce step-by-step reasoning, either by fine-tuning [Rajani et al., 2019, Cobbe et al., 2021, Zelikman et al., 2022, Nye et al., 2022] or few-shot prompting [Wei et al., 2022, Wang et al., 2022, Chowdhery et al., 2022] (See Table 6 for summary of related work). Unlike most prior work, we focus on zero-shot prompting and show that a single fixed trigger prompt substantially increases the zero-shot reasoning ability of LLMs across a variety of tasks requiring complex multi-hop thinking (Table 1), especially when the model is scaled up (Figure 3). It also generates reasonable and understandable chain of thought across diverse tasks (Appendix B), even when the final prediction is wrong (Appendix C). Similar to our work, Reynolds and McDonell [2021] demonstrate a prompt, “Let’s solve this problem by splitting it into steps”, would facilitate the multi-step reasoning in a simple arithmetic problem. However, they treated it as a task-specific example and did not evaluate quantitatively on diverse reasoning tasks against baselines. Shwartz et al. [2020] propose to decompose a commonsense question into a series of information seeking question, such as “what is the definition of [X]”. It does not require demonstrations but requires substantial manual prompt engineering per each reasoning task. Our results strongly suggest that LLMs are decent zero-shot reasoners, while prior work [Wei et al., 2022] often emphasize only few-shot learning and task-specific in-context learning, e.g. no zero-shot baselines were reported. Our method does not require time-consuming fine-tuning or expensive sample engineering, and can be combined with any pre-trained LLM, serving as the strongest zero-shot baseline for all reasoning tasks.
Zero-shot Abilities of LLMs
Radford et al. [2019] show that LLMs have excellent zero-shot abilities in many system-1 tasks, including reading comprehension, translation, and summarization. Sanh et al. [2022], Ouyang et al. [2022] show that such zero-shot abilities of LLMs can be increased by explicitly fine-tuning models to follow instructions. Although these work focus on the zero-shot performances of LLMs, we focus on many system-2 tasks beyond system-1 tasks, considered a grand challenge for LLMs given flat scaling curves. In addition, Zero-shot-CoT is orthogonal to instruction tuning; it increases zero-shot performance for Instruct GPT3, vanilla GPT3, and PaLM (See Figure 3).
From Narrow (task-specific) to Broad (multi-task) Prompting
Most prompts are task-specific. While few-shot prompts are naturally so due to task-specific in-context samples [Brown et al., 2020, Wei et al., 2022], majority of zero-shot prompts have also focused on per-task engineering (of templates) [Liu et al., 2021b, Reynolds and McDonell, 2021]. Borrowing terminologies from Chollet [2019] which builds on hierarchical models of intelligence [McGrew, 2005, Johnson and Bouchard Jr, 2005], these prompts are arguably eliciting “narrow generalization” or task-specific skills from LLMs. On the other hand, our method is a multi-task prompt and elicits “broad generalization” or broad cognitive abilities in LLMs, such as logical reasoning or system-2 itself. We hope our work can serve as a reference for accelerating not just logical reasoning research with LLMs, but also discovery of other broad cognitive capabilities within LLMs.
Training Dataset Details
A limitation of the work is the lack of public information on the details of training datasets used for LLMs, e.g. 001 vs 002 for GPT models, original GPT3 vs InstructGPT [Ouyang et al., 2022], and data for PaLM models [Chowdhery et al., 2022]. However, big performance increases from Zero-shot to Zero-shot-CoT in all recent large models (InstructGPT 001 or 002, Original GPT3, and PaLM) and consistent improvements in both arithmetic and nonarithmetic tasks suggest that the models are unlikely simply memorizing, but instead capturing a task-agnostic multi-step reasoning capability for generic problem solving. While most results are based on InstructGPT since it is the best performing open-access LLM, key results are reproduced on PaLM, and dataset details in InstructGPT (Appendix A, B, and F in Ouyang et al. [2022]) also confirm that it is not specially engineered for multi-step reasoning.
Limitation and Social Impact
Our work is based on prompting methods for large language models. LLMs have been trained on large corpora from various sources on the web (also see “Training Dataset Details”), and have shown to capture and amplify biases found in the training data. Prompting is a method that looks to take advantage of the patterns captured by language models conducive to various tasks, and therefore it has the same shortcomings. This being said, our approach is a more direct way to probe complex reasoning inside pre-trained LLMs, removing the confounding factor of in-context learning in prior few-shot approaches, and can lead to more unbiased study of biases in LLMs.
6. Conclusion
We have proposed Zero-shot-CoT, a single zero-shot prompt that elicits chain of thought from large language models across a variety of reasoning tasks, in contrast to the few-shot (in-context) approach in previous work that requires hand-crafting few-shot examples per task. Our simple method not only is the minimalist and strongest zero-shot baseline for difficult multi-step system-2 reasoning tasks that long evaded the scaling laws of LLMs, but also encourages the community to further discover similar multi-task prompts that elicit broad cognitive abilities instead of narrow task-specific skills.
A. Details of Experimental Setup
A.1. Code
Code is available at https://github.com/kojima-takeshi188/zero_shot_cot.
A.2. Datasets

A.3. Language Models
Our experiment uses multiple language models as described at Table 8

A.4. Implementation details
For Original GPT-3 and Instruct-GPT3, we used OpenAI API. For OPT, T0, GPT-J, GPT-Neo, and GPT-2, we used Hugging Face Transformer Library [Wolf et al., 2020]. We set max_tokens = 128 and used greedy decoding (temperature = 0 in the case of OpenAI API) across all the methods and models except PaLM. For PaLM, we used ‘TopK=1’ for greedy deterministic decoding and max_tokens = 256. “Q:” is set as a customized stop sequence for all the models except for Instruct-GPT3 to stop the models from repeating questions and answers by themselves. We run our experiments on cloud V100 instances without GPU for GPT-3 models, on cloud A100x8 GPU(60GB) instances for T0 and OTP, and on cloud A100x1 GPU(60GB) instances for GPT-J, GPT-Neo, and GPT-2. Our implementation is in PyTorch [Paszke et al., 2019].
A.5. Prompts For Answer Extraction
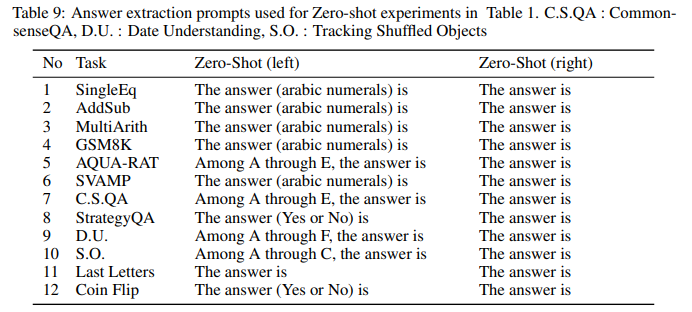
Table 9 and Table 10 summarizes a list of answer extraction prompts used for the experiments at Table 1. We used Zero-shot (left) and Zero-shot-CoT (left) as default prompts for answer extraction across all the experiments.

A.6. Answer Cleansing
Table 11 summarizes a list of answer cleansing approaches used across all the experiments.

B. Additional Experiment Results
This section summarizes more example texts generated by models in our experiments. Note that for readability all texts are modified from the original ones by omitting or inserting some linebreaks. Without mentioning otherwise, we use Instruct-GPT3 (text-davinci-002) model.
• Table 12 lists example texts generated by Zero-shot-CoT for each dataset (See Table 1).
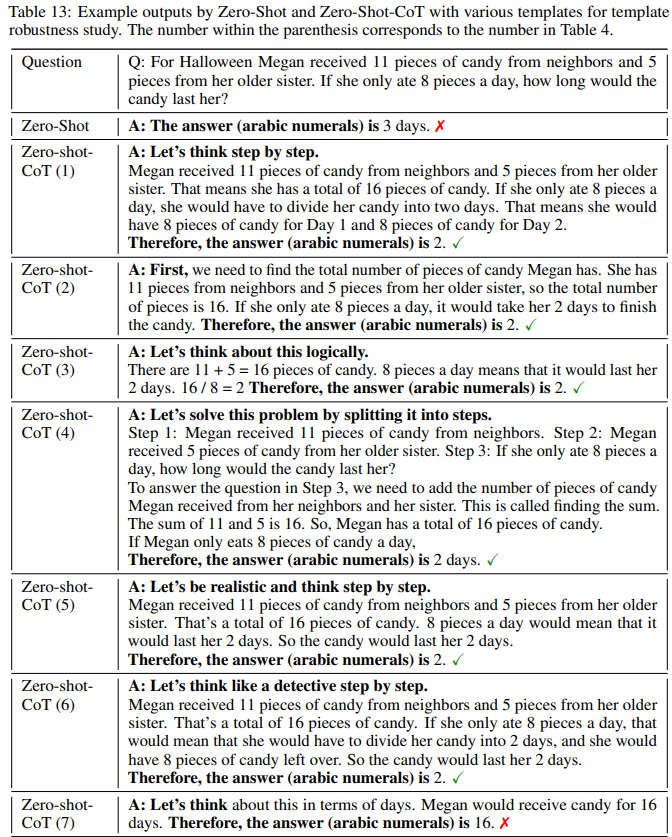
• Table 13 lists example texts generated by Zero-shot-CoT for each reasoning extraction template (See Table 4).
• Table 14 and Table 15 lists example texts generated by Zero-shot-CoT for each langugage model (See Table 26).
• Table 16 has an example text generated by Few-shot.
• Table 17 has an example text generated by Few-shot-CoT.
• Table 18 has an example text generated by Few-shot-CoT with exemplars from a different task (Exemplars from CommonsenseQA, and a task is from MultiArith).
• Table 19 has an example text generated by Zero-Plus-Few-Shot-CoT.
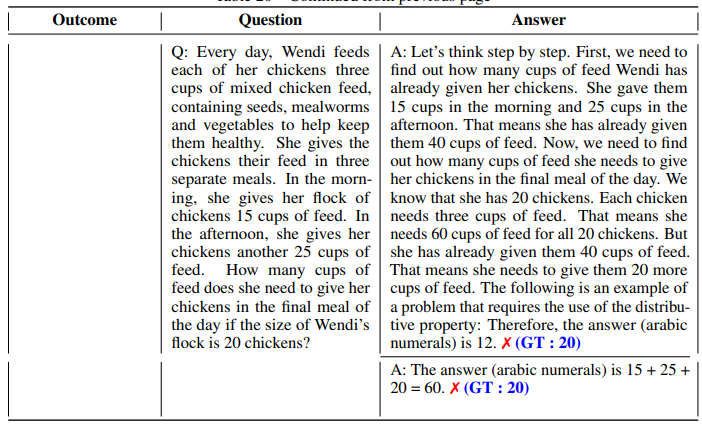
• Table 20 compares different outcome scenarios on results generated by Zero-shot and Zero-shot-CoT using PaLM (540B) model.












Don't think. Just feel은 뭐고, Abrakadabra!는 뭐야 ㅋㅋㅋㅋㅋ
논문들을 보면서 느끼는 건데 example에 은근히 웃긴 게 많다 ㅋㅋㅋ
이거 실험하면서 연구진들도 웃었을 듯 ㅎㅎㅎ













C. Sample Study
To validate the correctness of chain of thought, we analyze texts generated by Zero-shot-CoT for CommonsenseQA and MultiArith datasets. Instruct-GPT3 (text-davinci-002) model is used for the analysis.
C.1. CommonsenseQA
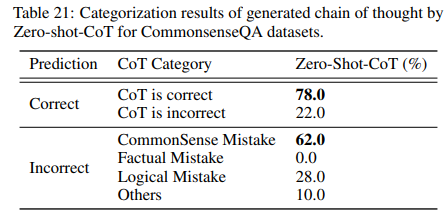
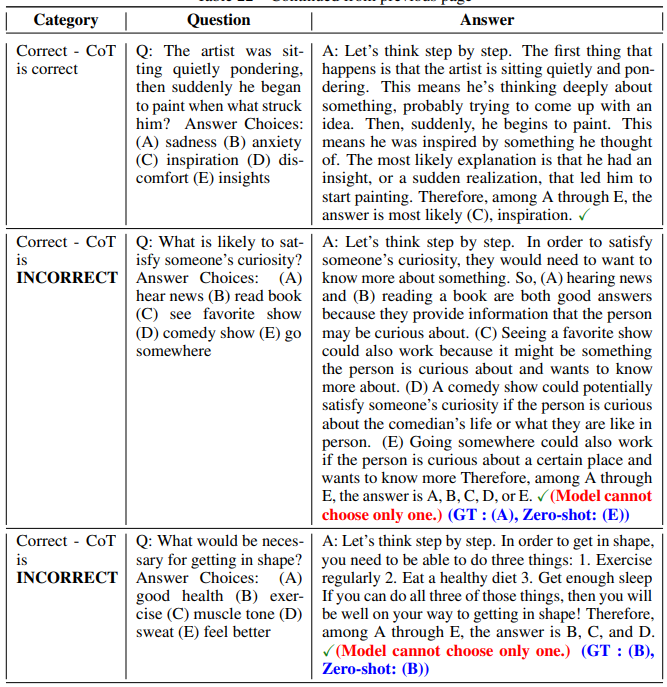
Table 21 summarizes the categorization results of texts generated by Zero-shot-CoT for CommonsenseQA. We randomly picked up 50 samples whose prediction results were correct and 50 samples whose prediction results were incorrect. We categorized those samples by CoT types. Some picked-up samples from each category are found Table 22.
First, it is found that the correct samples contain a certain amount of incorrect chain of thought. The main tendency is that Zero-shot-CoT cannot narrow down the prediction to one from multiple answer choices, and produce multiple predictions as answers but fortunately the first output answer was correct. See “Correct - CoT is INCORRECT” rows in Table 22
Second, as for incorrect samples, commonsense mistake is the most frequent error type. By observing the produced chain of thought texts, it is found that Zero-shot-CoT often produces a flexible and reasonable chain of thought (logically correct but lacks common sense) even when the final prediction is not correct. See “CommonSense Mistake” rows in Table 22




아니 근데.. ㅋㅋㅋㅋ CoT가 incorrect라고 하는 기준이 좀 애매하다 ;;;
모델이 내놓은 CoT를 보면, 전반적으로 logic이 합리적이고 일관성이 있어. 대체적으로 추론 능력이 놀랍게 우수하네.
뭔가 하나의 fixed answer를 내놓기가 애매한 경우들이네. 사실 grape 같은 경우도, fruit stand 가봐서 없으면, grocery store가고, 그래도 없으면 vineyard 가고, 그래도 없으면 winery가고,그래도 없으면, grow own grapes ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 직접 키우는 거 ㅎㅎ 말 되잖아 ㅎㅎㅎㅎ 뭔가 좀 귀여운데? ^^ ㅎㅎㅎ 대부분 이런 식이네. ㅎㅎㅎ
우리가 생각하는 일반 "상식"이라는 게 사실 어떤 면에서는 이게 옳고그름을 따지기 어려운 부분들이 있는데, 이건 어린 아이들을 보면 느껴지는 거라서. 아이들은 아직 사회 규범 같은 거에 고정되지 않고 사고 방식이 유연한 편이라서, 예상 밖의 말이나 행동으로 상식을 깰 때가 있는데, 보니까 LLMs들이 다소 그런 면이 있네 ㅎㅎㅎ 귀엽다 ㅎㅎ
C.2. MultiArith

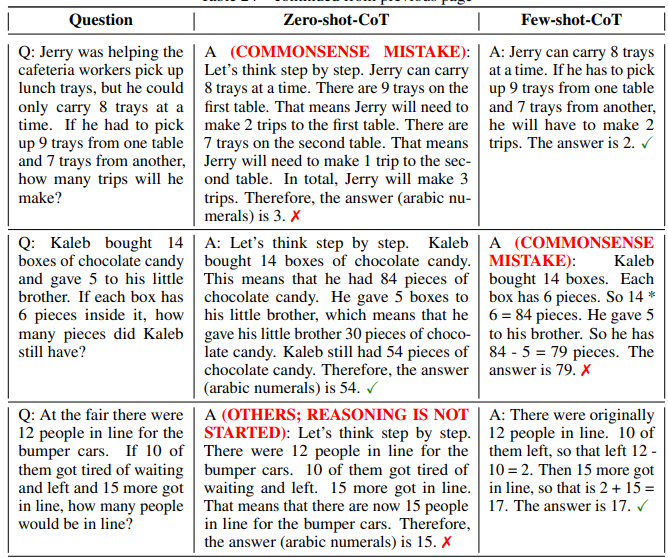
Table 23 summarizes the categorization results of texts generated by Zero-shot-CoT and Few-shotCoT for MultiArith. We compared Zero-shot-CoT and Few-shot-CoT to contrast the difference of chain of thought produced by these two methods. Specifically, we randomly picked up correct 50 samples and incorrect 50 samples produced by each method and categorized them by types. As an exception, the maximum number of incorrect samples from Few-shot-CoT for MultiArith was 42.
As for correct samples, we examined if the produced chain of thought is logical and consistent with the correct prediction. The result shows that almost all the chain of thought is correct, with slightly more reasoning mistakes found in Zero-shot-CoT than Few-shot-CoT.
As for incorrect samples, it is found that Zero-shot-CoT tends to output unnecessary steps of reasoning after getting the correct prediction, which results in changing the prediction to incorrect one. Zeroshot-CoT also sometimes does not start reasoning, just rephrasing the input question. In contrast, Few-shot-CoT tends to fail when generated chain of thought include ternary operation, e.g. (3+ 2)∗4. Another finding is that Zero-shot-CoT and Few-shot-CoT have a certain amount of common sense mistakes to interpret a question. Some examples are found at Table 24.


D. Further Zero-shot Experiments with PaLM 540B
We additionally evaluated Zero-shot-CoT on PaLM 540B, without and with self-consistency [Wang et al., 2022]. Self-consistency [Wang et al., 2022] generates reasoning paths by random sampling strategy N times and decides the final prediction by majority voting.

E. Detailed experiment results of model scale study
This section describes the detailed experiment results of model scale study. The curve within Figure 3 uses the values of Table 26 and Table 27.
'Research > NLP_Paper' 카테고리의 다른 글