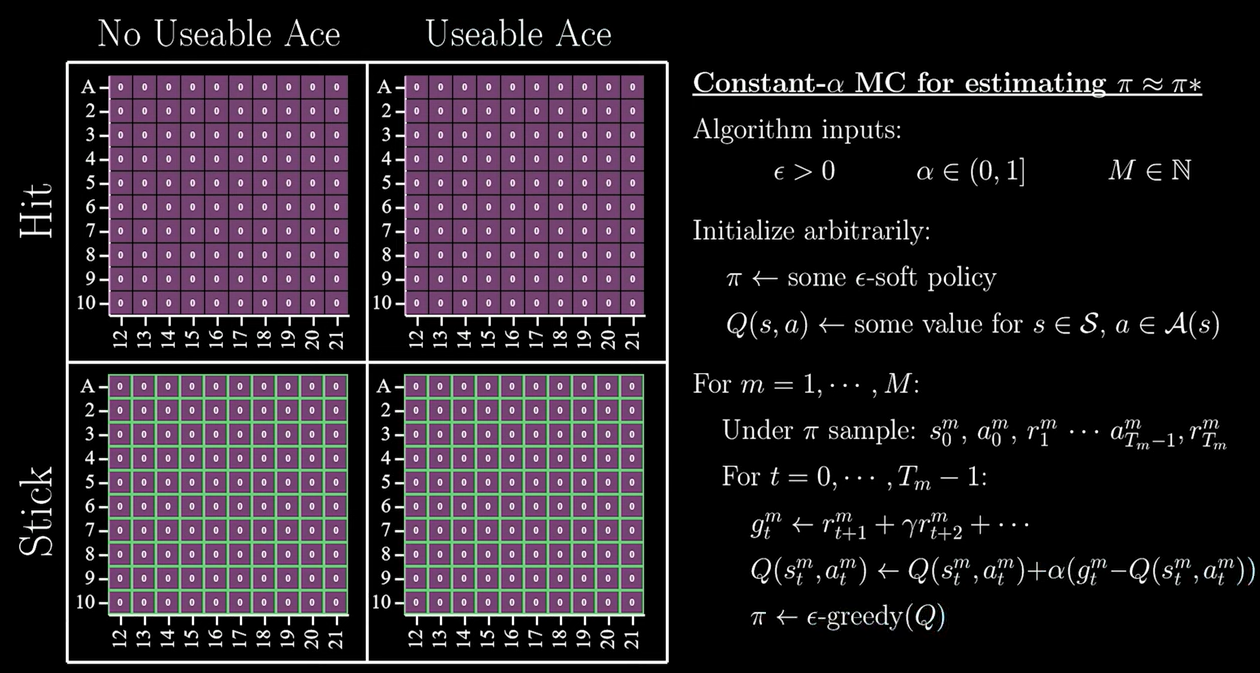
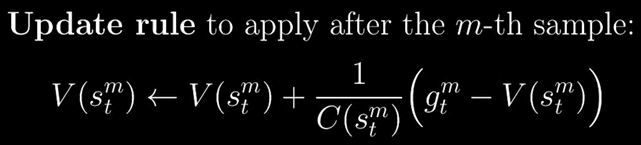-
[3/6] Monte Carlo and Off-Policy MethodsResearch/RL_DeepMind 2024. 8. 10. 02:10
'Research > RL_DeepMind' 카테고리의 다른 글
[5/6] Function Approximation (0) 2024.08.10 [4/6] Temporal Difference Learning (0) 2024.08.10 [2/6] Bellman Equations, Dynamic Programming, Generalized Policy Iteration (0) 2024.08.09 [1/6] Reinforcement Learning, by the Book (0) 2024.08.09 [Lecture 12] (2/2) Deep Reinforcement Learning (0) 2024.08.09