-
[Lecture 12] (2/2) Deep Reinforcement LearningRL/RL_DeepMind 2024. 8. 9. 16:18
https://www.youtube.com/watch?v=cVzvNZOBaJ4&list=PLqYmG7hTraZDVH599EItlEWsUOsJbAodm&index=12

In this section, I want to give you some insight in what happens when ideas from reinforcement learing are combined with deep learning, both in terms of how known RL issues manifest when using deep learning for function approximation and also in terms of how we can control these issues by keeping in mind the effect on function approximation of our reinforcement learning choices.
Let's start with the simple online deep Q-learning algorithm. What are potential issues with this algorithm? To start, we know from deep learning literature that, stochastic gradient descent assumes gradients are sampled iid, and this is definitely not the case if we update parameters using gradients that are computed on consecutive transitions in MDP. Because what you observe on one step is strongly correlated with what you observed and the decisions that you made in the previous steps.
On the other side, we also know that, in deep learning, typically mini-batches, instead of using single samples, is better in terms of finding a good bias-variance trade-off. And again this doesn't quite seem to fit the online deep Q-learning algorithm, because there we perform an update on every new step. So every time we are in a state and execute an action, get a reward, a discount and another observation. We would compute in updates to our parameters theta.

So how can we make RL more deep learning friendly? If we look back, it's quite clear that certain algorithms may better reflect deep learning's assumptions than others. So, it's good to keep deep learning in mind when choosing what to do on the RL side. So we discussed Dyna-Q and Experience Replay where we mixed online updates with updates computed on data that was sampled from a learned model of the environment in the case of Dyna-Q or from a buffer of past experience when we're doing Experience Replay.
And both might address very directly the two concerns that we highlighted in the vanilla deep Q-learning agent, because by sampling state action pairs or entire transitions from a memory buffer, we effectively reduce correlations between consecutive updates to the parameters and also we get for free support for mini-batches. Instead of doing a loop where we apply n planning updates, we could batch them together and do a mini-batch gradient ascent instead of vanilla SGD.

Similarly, if we are using deep learning for function approximation, there are many things we can do to help learning to be stable and effective. So we could use alternative online RL algorithm such as eligibility traces that integrate, in each update to the parameters theta, informations that comes from multiple steps and multiple interactions with the environment without requiring explicit planning or explicit replay like in Dyna-Q or Experience Replay.
Alternatively, we could also think about certain optimizers from the deep learning literature that might address and alleviate the issues that come from online deep reinforcement learning by integrating information across multiple updates for in a different way by using momentum or the Adam update.
Finally in some cases, if we keep in mind the properties of deep learning, we might even be able or willing to change the problem itself to make it more amenable. For instance, we could think of having multiple copies of the agent that interact with parallel environments and then mix this diverse data that comes from multiple instances of the environment in each single update to the parameters.
If we use Dyna-Q or experience replay, we can address certain issues and better fit certain assumptions of deep learning.
At the same time, if you think about Dyna-Q and DQN, and what happens when we use these algorithms in combination of function approximation? Then, we are combining fuction approximation but also bootstrapping, because we are using Q-learning as model-free algorithm and Off-policy learning because by replaying past data, the data is sampled from a mixture of past policies rather than just from the latest one. And the combination of exactly these three things is the deadly triad.
When you combine these three things, there is a possibility of divergence. At the same time, you will find that many successful agents do combine these three ingredients. So there is a tension here how is this possible?
A partial resolution is that, the dealy triad says that divergence is possible when combining these, but not that is certain and not even that it's likely. So if we understand and keep in mind the properties that underlie both RL and deep learning algorithms, there's much we can do to ensure the stability and reliability of the deep RL agents even when they are combining all the elements of the deadly triad.
I want to help you develop an understanding and an intuition about how and when the deadly triad manifests when combining reinforcement learning with the use of neural networks for function approximation.
The two issues, batching and correlation by understanding and keeping in mind the properties underlying RL and deep learning would this will already go long way towards being able to design the parallel algorithms that are quite robust.

Let's start with the larger empirical study where we looked at the emergence of divergence due to the deadly triad across a large number of variants of deep Q-learning agents and across many domains.
What we found is that, empirically unbounded divergence is very rare. So parameters don't tend to go to infinity even if you're combining all the elements of the deadly triad. What is more common is a different phenomenon that we call soft-divergence. And this is shown where we show the distribution of value estimates across many agents and many environments and for different networks.
What you see is that, the values explode initially. So they grow to orders of magnitudes larger than it's reasonable to expect in any of the environments that we're considering, because the max true values were at most 100.
But what we see is that, these values that are initially diverging don't go to infinity. So over time, the estimates recover and go back down to reasonable values. You may wonder, if soft divergence mostly resolves itself when doing the parallel in pratice, is it even a concern? Should we even be discussing how to minimize this initial instability?
And I think, the answer it that yes, I think it's worth discussing these things. Because even if it doesn't diverge fully to infinity, having many hundreads of, thousands of, millions of interaction with the environment where values are wildly incorrect does affect the behavior of the agent and the speed of convergence to the correct solution.
Let's then discuss what we can do about it. How do different reinforcement learning ideas help us to ensure that the learning dynamics when using deep networks for function approximation is stable and effective.

The first approach I want to tell you about was introduced by the DQN algorithm. And is known as target networks. The idea is to hold fixed parameters that are used to compute the bootstrap targets.
So in Q-learning, this would be the parameters that are used to estimate the max Q on the next step and then only update these parameters periodically, maybe every few hundreds or even thousands of updates.
By doing so, we interfere the feedback loop that is at the heart of the deadly triad. The core issue that deadly triad is that, when you update a state, you also inadvertently possibly update the next state that you are going to bootstrap on and this can create certain feedback loops. But if the parameters that you use to bootstrap are frozen, at least for a while, then this feedback loop is broken.

We know that Q-learning by itself, even in a tabular setting has an overestimation bias. And this can result in unreasonable high value estimates at least in an initial phase. So it's possible that this could interact with the deadly triad and increment the likelihood of observing these explosions in the value estimates. If this was the case, then we could use double Q-learning to reduce the overestimation of the update. And this would also help us make the algorithms more stable with respect to the deadly triad.In double Q-learning, we use separate networks to choose which action to bootstrap on, and the evaluation of such action. And neatly this combines really well with the target networks idea. Because then, we can use the frozen parameters the ones of the target network as one of the two networks.

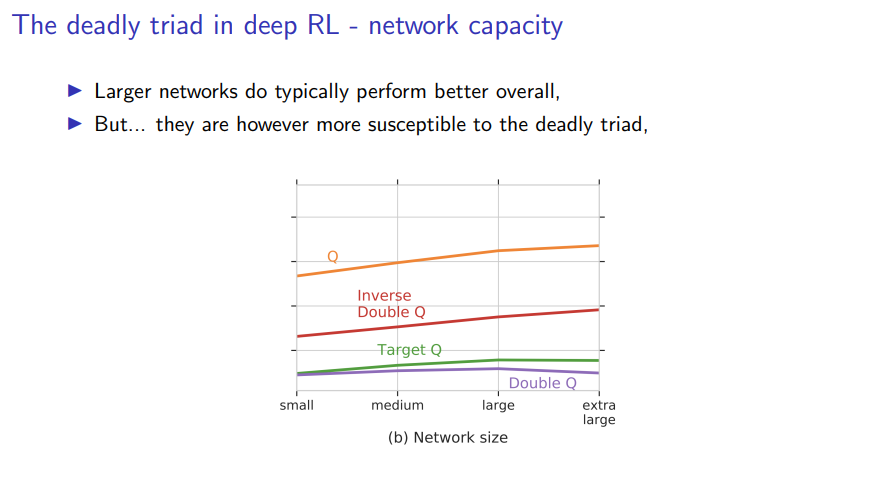
In this plot, you can see and compare the effects of both using target networks using only double Q, inverse double Q and doing both. So double Q learning typically uses both the separation of the evaluation from the selection of the bootstrap action, but also use the target network for the target estimation.
What we see is that, both these idea have a strong stabilizing effect. So just using target networks dropped the likelihood of observing soft divergence across the many agent instances and environments from 61 percent of the experiments to just 14 percent. And if we can consider the full double Q that combines both the idea of the de-coupling action selection and evaluation and the target networks idea, then the likelihood of observing soft divergence dropped to only 10 percent.
In general, I find it quite insightful to see these things and see how different choices on the reinforcement learning side interact with the dealy triad that is triggered by the combination of bootstrapping and Off-policy with function approximation. And it's quite interesting to see that this is not just about target networks or double Q learning.
Throughout our design choices that we make in our agents, each design choices can interact with function approximation and the learning dynamics of our deep networks.












'RL > RL_DeepMind' 카테고리의 다른 글
MuZero: Mastering Go, chess, shogi and Atari without rules (0) 2025.11.12 PPO & RLHF & DPO (0) 2024.08.11 [Lecture 12] (1/2) Deep Reinforcement Learning (0) 2024.08.09 [Lecture 11] (2/2) Off-Policy and Multi-Step Learning (0) 2024.08.09 [Lecture 11] (1/2) Off-Policy and Multi-Step Learning (0) 2024.08.08