-
[6/6] Policy Gradient MethodsResearch/RL_DeepMind 2024. 8. 10. 17:23
https://www.youtube.com/watch?v=e20EY4tFC_Q&list=PLzvYlJMoZ02Dxtwe-MmH4nOB5jYlMGBjr&index=6


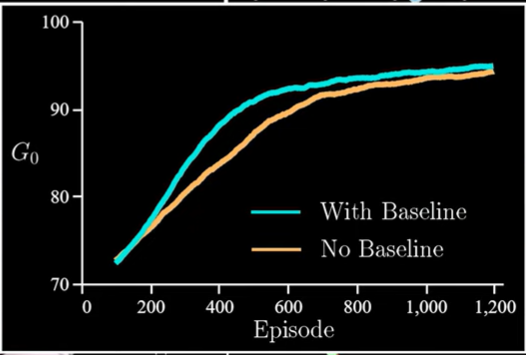
Policy gradient methods take a more direct approach to the problem statement of RL and as a result, many of the most effective models are from this category. For example, Proxmal Policy Optimization is a type of policy gradient method, and that's OpenAI's go to RL algorithm. In fact, that's what they use to incorporate human feedback into ChatGPT's training. Considering how much that product has grown, it's pretty clear, these techniques have serious real world value.










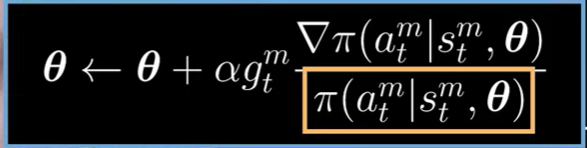










'Research > RL_DeepMind' 카테고리의 다른 글
PPO & RLHF & DPO (0) 2024.08.11 [5/6] Function Approximation (0) 2024.08.10 [4/6] Temporal Difference Learning (0) 2024.08.10 [3/6] Monte Carlo and Off-Policy Methods (0) 2024.08.10 [2/6] Bellman Equations, Dynamic Programming, Generalized Policy Iteration (0) 2024.08.09