-
Contrastive LearningResearch/Multimodal 2024. 8. 14. 14:03
https://neurips.cc/media/neurips-2021/Slides/21895.pdf
https://sthalles.github.io/simple-self-supervised-learning/
https://sanghyu.tistory.com/184

What is Self-Supervised Learning?
Self-Supervised Learning (SSL) is a special type of representation learning that enables learning good data representation from unlabelled dataset.
It is motivated by the idea of constructing supervised learning tasks out of unsupervised datasets.
Why?
1. Data labeling is expensive and thus high-quality labeled dataset is limited.
2. Learning good representation makes it easier to trasfer useful information to a variety of downstream tasks.
- e.g. A downstream task has only a few examples.
- e.g. Zero-shot transfer to new tasks.
Self-supervised learning tasks are also known as pretext tasks.
What's Possible with Self-Supervised Learning?
Despite of not training on supervised labels, the zero-shot CLIP classifier achieve great performance on challenging image-to-text classification tasks.

Methods for Framing Self-Supervised Learning Tasks
Self-prediction
Given an individual data sample, the task is to predict one part of the sample given the other part.
The part to be predicted pretends to be missing.

Contrastive learning
Given multiple data samples, the task is to predict the relationship among them.
The multiple samples can be selected from the dataset based on some known logics (e.g. the order of words / sentences), or fabricated by altering the original version.

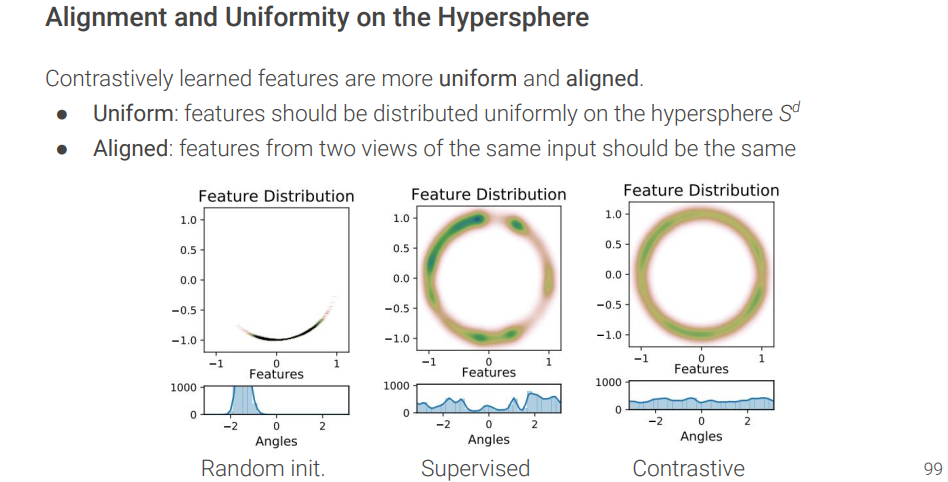
같은 class를 가지는 두 샘플(positive samples) 간의 공통 부분 (identity를 보여주는 부분=중요한 부분)을 학습하고 싶어. 근데 representation collapse라는 치명적 문제가 있음. 따라서 negative sample을 갖는 contrastive learning으로 학습하자.
Self-prediction
self-prediction construct prediction tasks within every individual data sample: to predict a part of the data from the rest while pretending we don't know that part.

1. Autoregressive generation
2. Masked generation
3. Innate relationship prediction
4. Hybrid self-prediction
Self-Prediction: Autoregressive Generation
The autoregressive model predicts future behavior based on past behavior. Any data that comes with an innate sequential order can be modeled with regression.

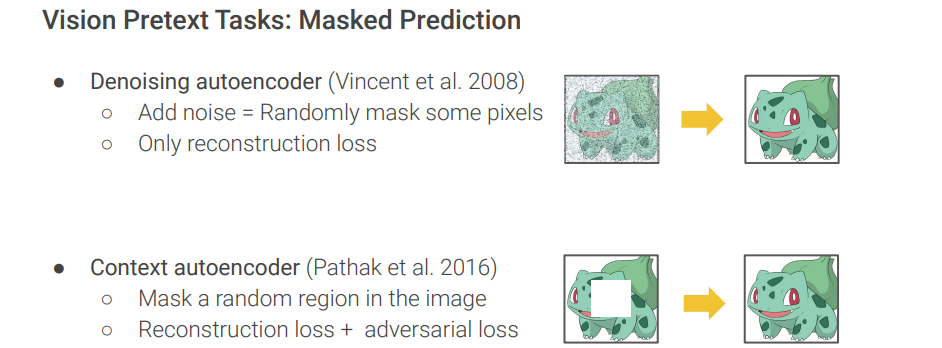
Self-Prediction: Masked Generation
We mask a random portion of information and pretend it is missing, irrespective of the natural sequence. The model learns to predict the missing portion given other unmasked information.

Self-Prediction: Innate Relationship Prediction
Some transformation (e.g. segmentation, rotation) of one data sample should maintain the original information or follow the desired innate logic.

Self-Prediction: Hybrid Self-Prediction Models

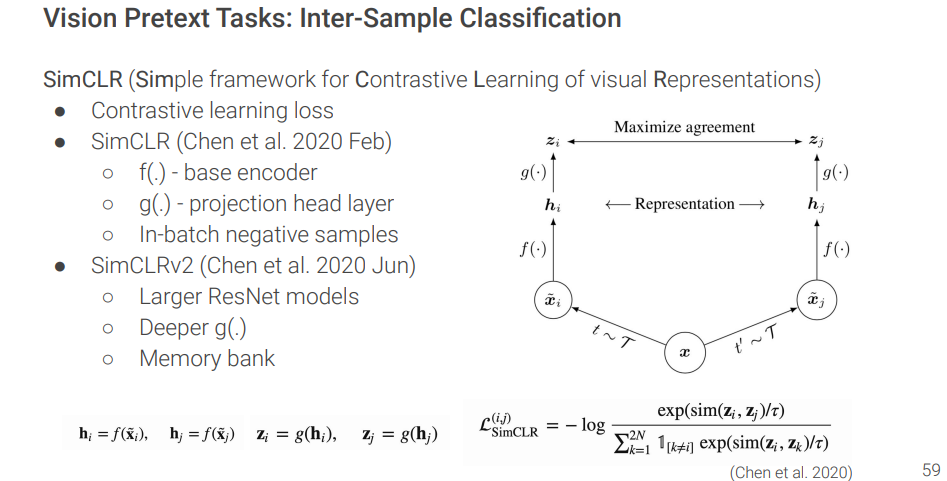
Contrastive Learning
The goal of contrastive representation learning is to learn such an embedding space in which similar sample pairs stay close to each other while dissimilar ones are far apart.

1. Inter-sample classification
2. Feature clustering
3. Multiview coding
Inter-Sample Classification
Given both similar ("positive") and dissimilar ("negative") candidates, to identify which ones are similar to the anchor data point is a classification task.
There are creative ways to construct a set of data point candidates:
1. The original input and its distorted version
2. Data that captures the same target from different views.
Contrastive loss
Works with labelled dataset.
Encodes data into an embedding vector such that examples from the same class have similar embeddings and samples from different classes have different ones.

Triplet loss
Learns to minimize the distance between the anchor x and positive x+ and maximize the distance between the anchor x and negative x- at the same time.

N-pair loss
Generalizes triplet loss to include comparison with multiple negative samples.

Noise Contrastive Estimation (NCE)
Runs logistic regression to tell apart the target data from noise.

InfoNCE
Uses categorical cross-entropy loss to identify the positive sample amongst a set of unrelated noise samples.
Given a context vector c, the positive sample should be drawn from the conditional distribution p(x|c), while N-1 negative samples are drawn from the proposal distribution p(x), independent from the context c.















'Research > Multimodal' 카테고리의 다른 글
Perceiver / Perceiver IO (0) 2024.09.23 Understanding VQ-VAE (DALL-E Explained Pt. 1) (0) 2024.08.19 Understanding DeepMind's Flamingo Visual Language Models (0) 2024.08.15 [Flamingo] Tackling multiple tasks with a single visual language model (0) 2024.08.15 [CLIP] Connecting text and images (0) 2024.08.13