-
Perceiver / Perceiver IOResearch/Multimodal 2024. 9. 23. 22:55

단순하고 직관적인 아이디어로 소기의 성과를 이루는 극강의 가성비템.
코드도 매우 깔끔하다.
1) 역시나 embedding space의 힘을 보여주는 architecture. (VQ-VAE 작동 방식과 상통하는 부분)
- 저차원의 Latent array에 projection 한 후 기존 attention 연산을 수행하는 방식 (내가 이해한 바임. not validated!)
2) 단일 구조로 다양한 modality의 input을 처리할 수 있는 획기적인 성과.
- 기존 CNN의 inductive bias 배제, 기존의 transformer의 연산량으로 인한 길이 제약 감소
3) 마치 RNN처럼 weight가 sharing되는 것이 특이하게 느껴졌다.
- 추측으로는, RNN에서 input의 정보가 hidden에 누적되는 것처럼 여러번의 참조를 통해 중요한 정보를 반영하는 걸로 이해했다. (이 또한 내가 이해한 바임. not validated!! ㅎㅎ)
4) 그런데 마지막에 output 단에 가서는 단순한 classifier로 classification task만 처리하도록 구성이 되어 있어서,
살짝 흠짓 했다. (용두사미 느낌)
- 그러나 역시 Perceiver 논문이 나온 후 얼마 지나지 않아서 Perceiver IO 후속 논문을 발표해 주는 센스!

Perceiver IO에서는 output에도 유연성을 부여하여 다양한 structured output, task가 가능하다.
input 단에서 일어났던 cross-attention과 유사한 방식이지만, 이번에는 자유로운 output 형태에 맞추어 output query array를 만들고, 여기에 representation (latent) array를 value, key로 cross-attention하였다는 차이가 있다.
https://www.youtube.com/watch?v=wTZ3o36lXoQ&list=PLj-lDqBAM8UfwEIQ3iOexjeEBs2O47uo-&index=23&t=1948s
뭐니뭐니 해도 저자 직강이 최고. 영상 본 후에 업데이트 예정.
(영상 시청 후 기록은 아래 ↓)




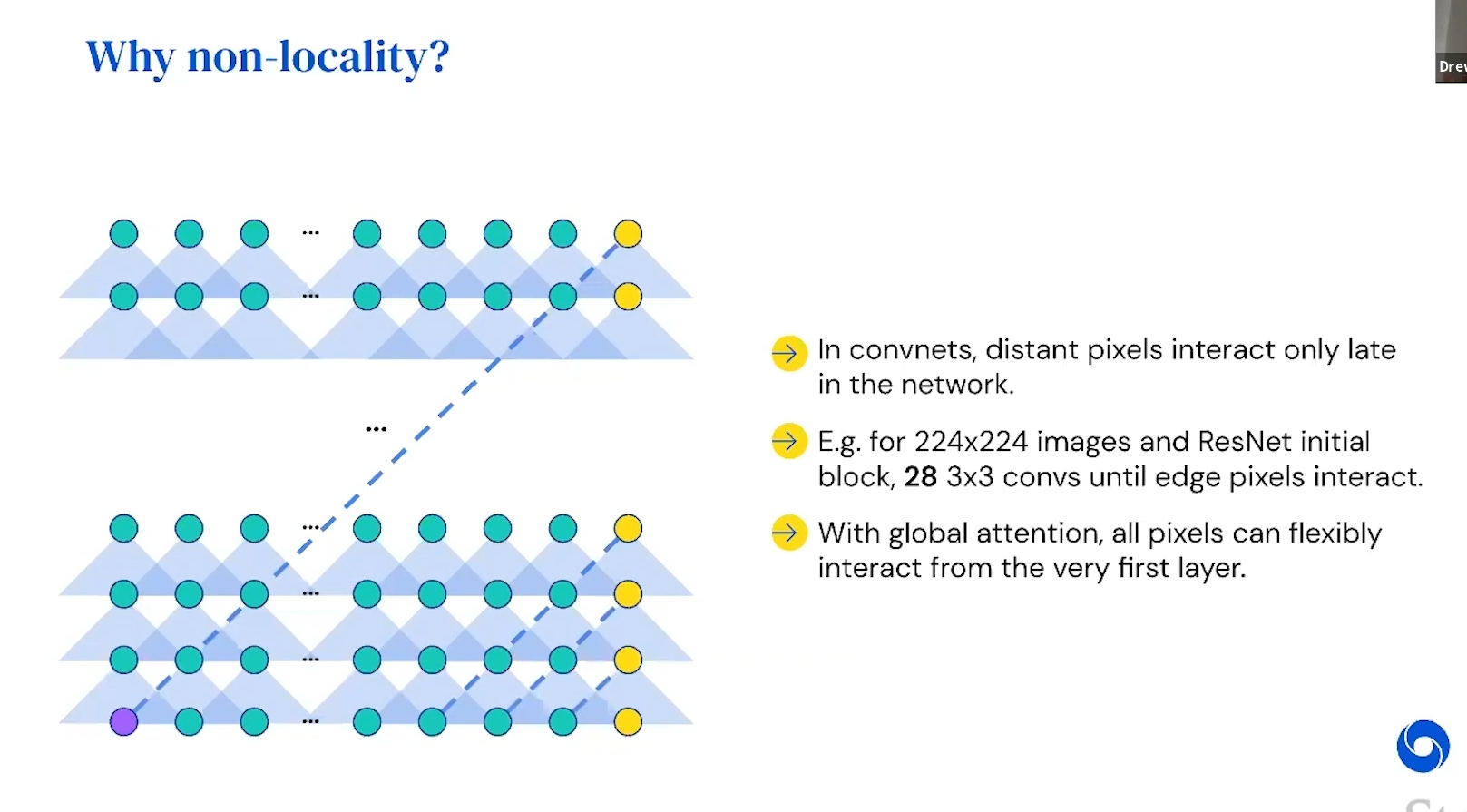





< Query의 차원이 줄어든 것에 대한 설명 >
One way to think about this, about what's happening here is that, instead of -- so in a normal self-attention transformer, by comparing all to all, we're sort of saying, OK, I know what the feature is at this point and I want it to attend to similar features. Here what we're saying is, we're learning a bunch of supplementary points that should be sort of maximally similar to some subset of the inputs.

< weight sharing에 대한 설명 - RNN처럼 iterative하게 attention을 수행한 것의 effect 설명 >
So once we're in the space, we can then build an architecture by using a standard transformer but phrased in the latent space rather than in the input space. And this is going to allow us to basically end up, because we sort of distilled the input down to the smaller space. We can still flexibly allow all of these points to interact. So this should be still as nearly as expressive as a normal transformer is. And then each of the modules here now is quadratic in the latent size rather than the input size. So this is something that we can control quite a lot.
So in the original version of the procedure, we found it was very helpful to have additional cross attentions. So this is certainly something that you could do. And the reason-- the intuition behind this is that, this bottleneck is quite severe. We can't maintain all of the information from the input, and so we want these queries, which are now sort of conditioned on the past to be able to look back at the input point.
And so this is something that we found to be quite helpful when tuning for the first paper.
The other thing that we found quite helpful in the context of datasets that have a limited amount of data, which for these architectures includes ImageNet, is to allow weight sharing in depth. And so this basically just amounts to tying the weights for the different cross attention and different self-attention layers as they're repeated. So this ends up looking like an RNN that's unrolled in depth.
At a high level, this gives us an architecture that we can apply to images. But it doesn't make any assumptions about image structure. So it's one that you can use elsewhere.










※ 여담..
논문 3.2. Position encodings 절에서 갑자기 임마누엘 칸트 등장 ^^;;;;
But permutation invariance means that the Perceiver’s architecture cannot in and of itself exploit spatial relationships in the input data. Spatial relationships are essential for sensory reasoning (Kant, 1781) and this limitation is clearly unsatisfying. In the attention literature, position information is typically injected by tagging position encodings onto the input features (Vaswani et al., 2017); we pursue this strategy here as well. While position information is typically used to encode sequence position in the context of language, it can also be used to encode spatial, temporal, and modality identity.
ㅋㅋㅋ 논문 저자 중에 철학에 조예가 깊은 분이 계셨을까..?
나 이거 잠시 생각했잖아... 뭔가 심오한 뜻이 있는건가..? 하고... ㅎㅎㅎㅎ
'Research > Multimodal' 카테고리의 다른 글
Perceiver 과 Flamingo에서의 Perceiver Resampler의 미묘한 차이 (0) 2024.09.24 [Flamingo] The architecture behind modern visual language modeling (0) 2024.09.24 Understanding VQ-VAE (DALL-E Explained Pt. 1) (0) 2024.08.19 Understanding DeepMind's Flamingo Visual Language Models (0) 2024.08.15 [Flamingo] Tackling multiple tasks with a single visual language model (0) 2024.08.15