-
Perceiver 과 Flamingo에서의 Perceiver Resampler의 미묘한 차이Multimodal 2024. 9. 24. 09:50
분명 작동 방식은 동일한데, 뭔가 미묘한 차이를 발견.
Cross Attention이 내포하고 있는 의미가 살짝 다르다.
Perceiver 코드 구현체 가져다가 실행하였을 때, 분명 latent를 임의로 초기화하고 시작했거든. (논문에서 제시한대로)

그러고 나서 iterative하게 cross-attention을 수행하니까, image feature (byte array)가 latent에 projection되는 결과를 낳았는데..
Flamingo에서는 미묘하게 다르다!

그니까..여기에서는..
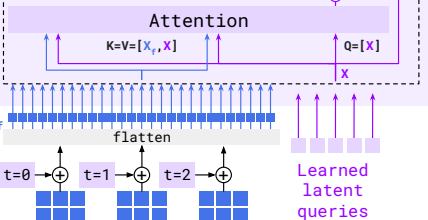
이미 학습된 query vector를 가져오고,
cross-attention 시에도, Key, Value vector에 query vector가 concat된 후 attention을 한다.
왜 이렇게 할까 처음에 좀 이해가 안되었는데,
이건 마치.. 자기 자신이 기존에 가지고 있던 정보를 잃지 않으면서, 이미지 feature의 정보를 추가적으로 embed하는 것과 같다.
그러니까 말하자면.. Perceiver 원 논문에서는 주체가 byte array (image feature vector)였는데 (latent array는 빈 깡통으로 출발. 단지 그 size에 맞추어 byte array의 정보를 압축 (low-dimension으로 보내줌)해주는 역할),
여기서는 주체가 Learned latent vector고, 여기에 image feature vector의 정보를 latent vector의 관점에서 filtering해서 가져오는 것과 같다.
(내가 이해한 바임. not validated!!!! ㅎㅎㅎㅎ)
즉, 원 논문에서는 제목 그대로 perceive하는 기능이었다면, 여기서는 perceiver "Resampler!" - 정보를 filtering out 하는 게 point!.
그래서 이름이 perceiver Resampler 인가보다.
그렇다면.. learned latent는 어디서 왔는교..?
기존의 CLIP과 같은 powerful한 모델이 만들어놓은 feature representation을 가져온건가..??
논문에 쓰여있는데 내가 못찾았나..? 확인 필요!

'Multimodal' 카테고리의 다른 글
CLIP - Creating strong image and language representations for general machine learning tasks. (0) 2024.09.26 Visual Question Answering with Frozen Large Language Models (0) 2024.09.25 [Flamingo] The architecture behind modern visual language modeling (0) 2024.09.24 Perceiver / Perceiver IO (0) 2024.09.23 Understanding VQ-VAE (DALL-E Explained Pt. 1) (0) 2024.08.19