-
Visual Question Answering with Frozen Large Language ModelsResearch/Multimodal 2024. 9. 25. 23:18
Talking with LLMs about images, without training LLMs on images.
In this article we’ll use a Q-Former, a technique for bridging computer vision and natural language models, to create a visual question answering system. We’ll go over the necessary theory, following the BLIP-2 paper, then implement a system which can be used to talk with a large language model about an image.

What we’ll be building A Brief Chronology of Visual Language Modeling
Visual language modeling really started up in 2016 with the paper VQA: Visual Question Answering, which formally posed the following class of problem:
Given an image and a natural language question about the image, the task is to provide an accurate natural language answer — VQA: Visual Question Answering
In 2016, when VQA was popularized, a typical approach looked something like this:
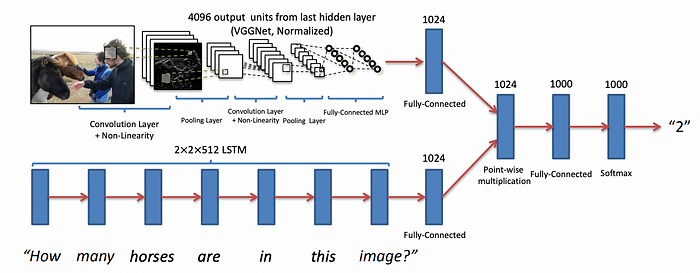
A VQA model from 2016 using an LSTM to embed the question into a vector, an existing computer vision network to embed the image as a vector, then a dense layer which considers the two in the correct choice of output. From VQA: Visual Question Answering . In the early days of VQA it was appropriate to train the vision and language components from scratch, pass the outputs to a dense network, and pick one of n possible outputs as a response.
As vision and language models became more powerful, Visual Question Answering gave way to Visual Language Modeling (VLM), which can generally be considered as an expansion on visual question answering. Instead of simple questions like “is there a car in this image”, modern Visual Language Models allow you to ask what type of car is in an image, then ask about how the car drives, the most popular movie that car was in, etc.

An example of Visual Language Modeling in action. This particular example is from the BLIP-2 paper , which we will be using as a reference in this post. This shift from VQA to VLM was largely the result of incorporating large language models into visual systems, providing complex reasoning abilities and encyclopedic knowledge out of the box.
The difficulty of visual language modeling is, and always has been, multi-modality. You have to be good at images, natural language, and you have to be good at getting them to play nicely together. As vision and language models have gotten larger, systems for combining them for visual language modeling have gotten more complex.
This poses a practical problem. Large language models are massive, so updating their parameters to learn some new task is exorbitantly expensive (like, thousands to millions of dollars expensive). Also, when training a model on a completely new mode of data it’s common for that model to catastrophically forget; a term for when models forget key information when being tuned to a new use case. If you slap an image encoder and a large language model together willy-nilly, you might get a model that’s bad at understanding both images and text.
The BLIP-2 paper proposes the Q-Former to address both the catastrophic forgetting issue, as well as being economical by leveraging existing models.
The Q-Former in a nutshell
If you wanted to make a VQA system from scratch in a weekend, you might consider the following approach:
- Pass the image you want to talk about through a caption generator
- Combine the question asked by the user and the generated caption into a prompt for an LLM using some template
- Pass that prompt to the LLM, which would return the final output
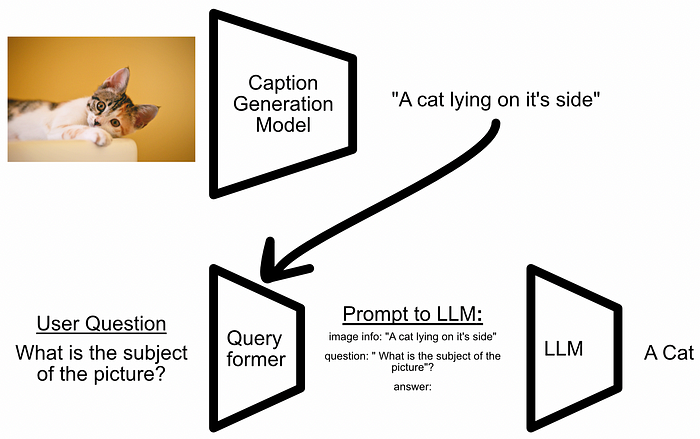
The flow diagram of a naive approach being successful. The user asked a question which happens to be answerable from the generated caption. That approach might work if you’re asking simple questions about the subject of an image, but if you have more obscure questions you might be out of luck.
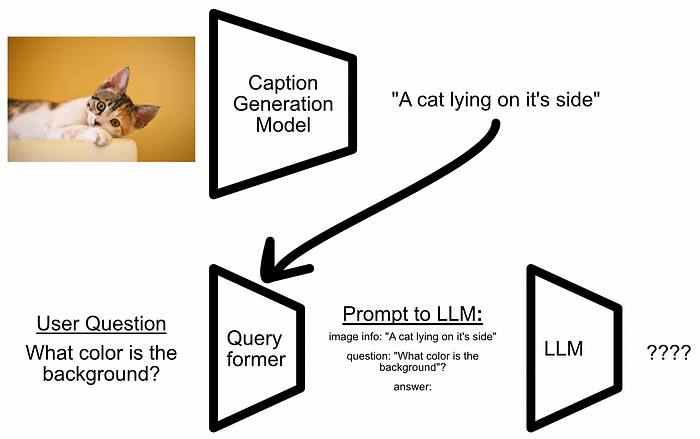
The flow diagram of a naive approach not being successful. The user asked a question which is not answerable from the generated caption. The Q-former is used as a querying transformer (hence the name) which can transform a users query based on the image. The idea is to be able to extract the correct information from the image, based on the users prompt, and provide it to the LLM.
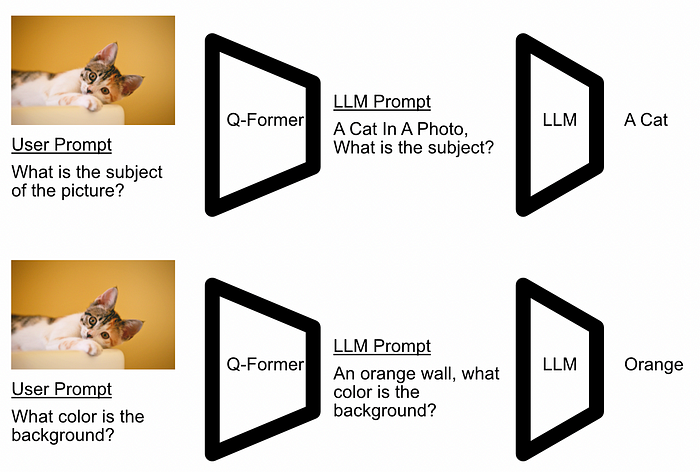
A conceptual diagram of what the Q-Former does. It uses both the prompt and the image to constuct the input to the LLM. In reality the Q-Former doesn’t actually generate text, it generates a high dimensional embedding, but this is the conceptual essence.
The BLIP-2 Architecture
Before we really dive into it, let’s get a high level understanding.
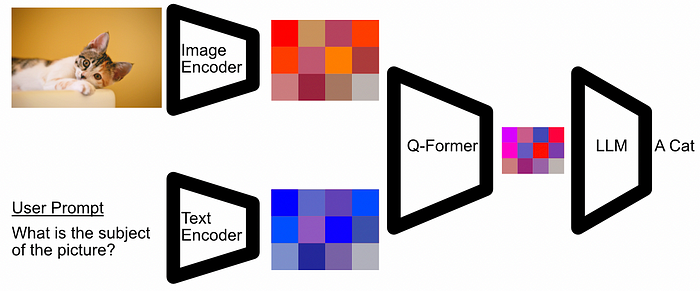
A Slightly more accurate depiction of the Q-Former, and the components around it. The image encoder embeds an Image into its most important parts, the text encoder does the same for the users prompt, and the Q-Former combines them to create an input for the LLM. The BLIP-2 Architecture, which the Q-Former exists within, has the following components:
- An Image Encoder: A pretrained model which embeds images into an abstract representation which makes tasks like image classification easier. In essence, you can think of this as extracting an images important content. A popular example of this is CLIP.
- A Text Encoder: A pretrained model which embeds text into an abstract representation. These typically treat words like points in a high dimensional space, where similar words will be in similar points in that space. A popular example of this is Word2Vect.
- An LLM: A large language model trained to perform general language tasks. Kind of like chat GPT.
- The Q-Former: A transformer model which combines the embedded image and the embedded prompt into a format compatible for the LLM. The Q-Formers main job is to properly contextualize both inputs and provide them to the LLM in a way that’s conducive with text generation.
Because of the Q-Formers flexibility, different encoders and LLMs can be used within BLIP-2.
The Q-Former, in a Nutshell
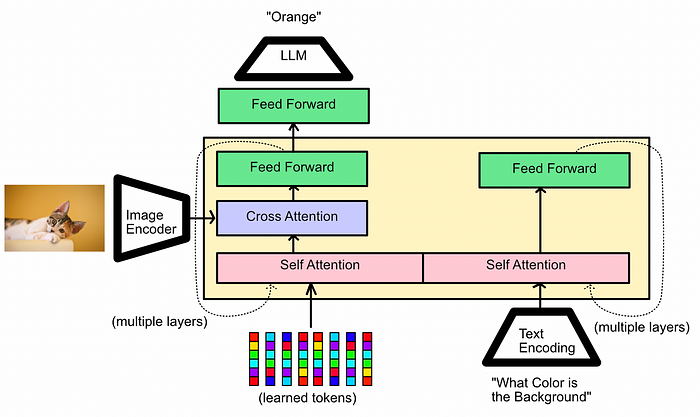
A High level conceptual diagram of the Q-Former First of all, a general understanding of attention is required as it makes up the bulk of the Q-Former architecture. Basically, attention makes modified copies of its inputs, then mixes the copies together.
If we passed the text input “What Color is the Background” through a self-attention mechanism then the vector for each word in the sentence would be combined with the vector for every other word. This would result in an abstract matrix that contains contextualized information about all the words in the input.

Multi Headed self attention, in a nutshell. The mechanism mathematically combines the vectors for different inputs (in this example, words), creating a matrix which encodes a deeper meaning of the entire input. What might not be so obvious, even if you are familiar with attention, is why the self attention block is divided down the middle. In reality the two self attention blocks within the Q-Former are actually one. The input on the left of the self attention mechanism can fully interact with the input on the right of the self attention mechanism, and vice versa. The division isn’t based on how the model works, but rather how the model is trained.
Because of the way the Q-former is trained, the self-attention block is good at manipulating just the image, just the text, and the two simultaneously. Hence why it’s somewhat like two attention blocks, but it’s really one big attention block.
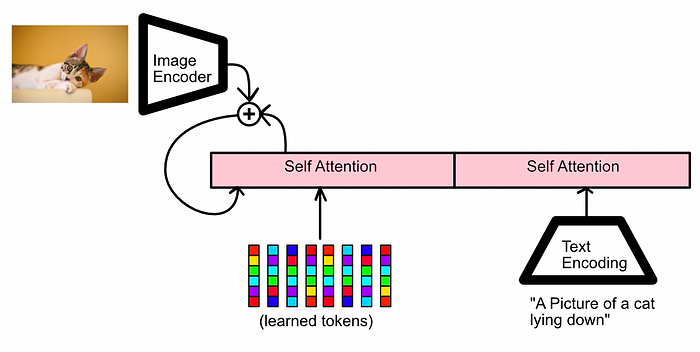
A conceptual diagram of how the self attention mechanism in the Q-Former both isolates text and image representations, and aids in their interaction. This is done in the bootstrapping phase of training, which we’ll discuss in the next section. The learned tokens on the bottom left of the diagram are essentially learned constants which are used by the model in the first self attention block. Briefly, I like to think of them two ways:
- If you think about them in terms of self attention with the text, they’re dictating how the text is initially introduced to the image.
- If you think of them in terms of interacting with the image, they’re serving as an initialization which gets modified by the image, ultimately becoming the prompt to the model.
Also, as you can see in the first image in this section, there are dotted recursive connections connecting the output of the two feedforward networks back into the input. the entire region depicted in yellow is a Q-Former block. Multiple of these blocks are stacked on top of each other to create the complete Q-Former.
That’s all the components, which might be surprising. Based on just looking at the components it’s not obvious why the Q-Former would be especially good at bridging images and text. To understand that, you need to understand how the Q-Former is trained.
How the Q-Former Is Trained
The Training of the Q-Former can be divided into two phases: Bootstrapping and Generative Learning Pre-Training. The bootstrapping phase can be further divided into three sub phases. We’ll go over all of them step by step.
The naming of these training phases might be a bit confusing. What is “bootstrapping”? Why is there a pre-training step but not a “training step”? I think the naming of these phases is the result of the following definitions:
- Bootstrapping is the general process of using data which may or may not be perfectly suited for the final use case in order to get the model up from random initialization to some state which performs well at related tasks.
- Pre-Training is the general process of using large amounts of data to get the model into a generally good state for the final task.
- Fine-Tuning is the process of taking a pre-trained model and presenting it a small amount of task specific data to optimize it for the final modeling task.
One of the core advantages of BLIP-2 is Zero-Shot Performance. BLIP-2 promises to be good at tasks like visual question answering without being fine tuned on VQA datasets. It uses datasets with captioned images (captions which explain the content of an image) to do bootstrapping and pre-training, but never actually does fine-tuning on VQA.
Bootstrapping
The bootstrapping phase is designed to encourage the model to be good at a variety of tasks which require understanding of both text and images. Kind of like my self-supervision post, you can think of this as a sort of “game”, which the model learns to prepare for the final task of visual question answering.
The bootstrapping phase has three sub-phases.
- Image-Text Contrastive Learning: The model learns how to group image-caption pairs which belong together, and separate image-caption pairs which don’t belong together through contrastive learning.
- Image-Grounded Text Generation: Divide the caption into two sections, the hidden and not hidden part, and attempt to guess the hidden part based on both the not hidden part and the image.
- Image-Text Matching: Pass the output of the Q-Former into a sacrificial dense network, which converts the output into a binary classification, then use this binary classification to decide if a caption does, or does not, belong to an image.
Image-Text Contrastive Learning
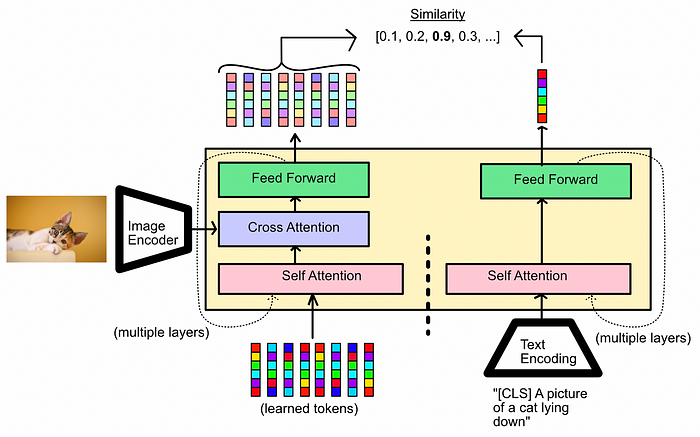
Image-Text Contrastive Learning in action. All of the vectors on the image side (which would be the input to the LLM) are compared with the class token from the text side. In this example the similarity is high, because the image and text match. We would hope, if the image and text didn’t match, the maximum similarity score would be low. In this mode of bootstrapping, the self attention mechanism in the Q-Former is split in two. This is done via a mask applied to the attention layer called the “Uni-modal Self-Attention Mask”. This is a complicated phrase for a simple concept:
within the self attention mechanism, any time the text side interacts with the image side, just set the value to zero.
This, in effect, blocks all communication between the image side of the Q-Former and the text side of the Q-Former.
This training method also employs a special token, called the “class” token. This idea was inspired by BERT. Basically, you have some arbitrary token that lets the model know “hey, we’re doing Image-text contrastive learning now”. You then disregard any other output on the text side besides the class token, and use that to calculate loss. As a result, the model knows that the “class” token, when present, is special and will try to learn how to manipulate both the vision on the left, and the text on the right, to maximize performance in terms of contrastive loss.
Contrastive loss, essentially, is the task of trying to get matching pairs close together, and not-matching pairs far apart. In essence, contrastive loss looks at a bunch of images and their captions and tries to get the model to learn which images belongs to which captions. In our case, this is done by calculating the similarity of the vectors on either side, and finding the maximum similarity value. matching pairs of text and images should have a large similarity score, and not matching pairs should have a small similarity score.
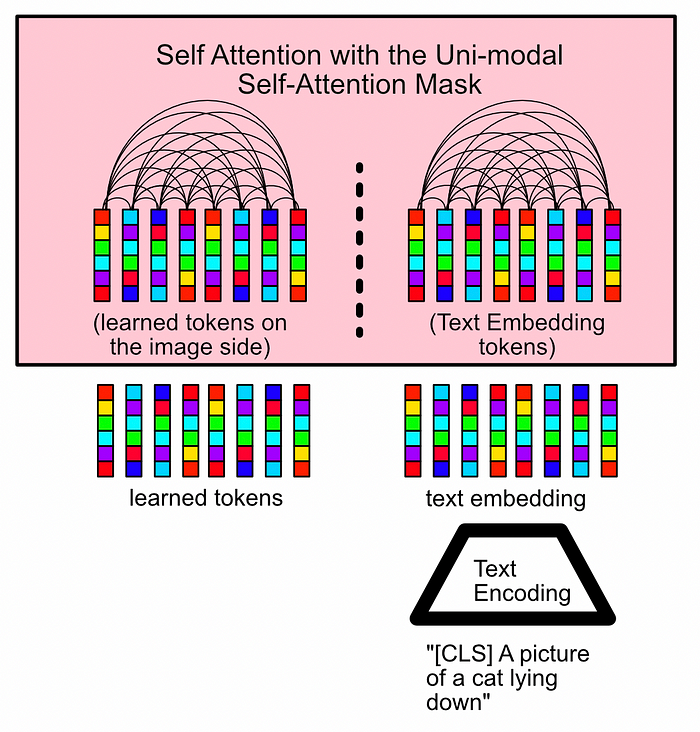
A conceptual diagram of uni-modal self attention, the masking strategy used in this phase of training. Note how there is full attention on the image side, and full attention on the text side, but no attention between the two. Image-Grounded Text Generation
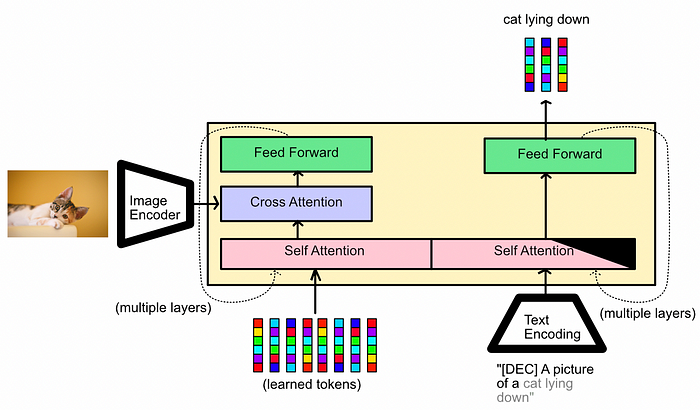
A conceptual diagram of the “Image-Grounded Text Generation” pre-training step in action. A section of the input text is hidden from the Q-Former, and the Q-Former is tasked with trying to fill in the hidden text. In this bootstrapping mode, we ask the Q-Former to complete a partially hidden caption. We apply a “Multi-modal Causal Self-Attention Mask”, which allows the text side of the Q-Former to interact with the image side, but hides a part of the caption which is to be predicted by the Q-Former. We also swap out the “class” token for a “decoder” token to let the model know what task it’s supposed to be doing.
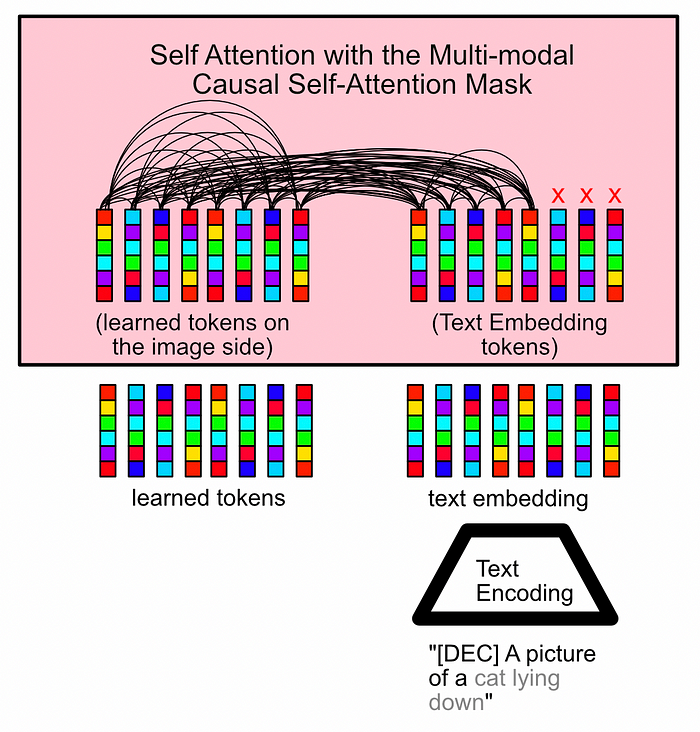
A conceptual diagram of multi-modal causal self-attention; the masking strategy used in this phase of training. Not how full attention is permitted across all tokens save those which are supposed to be output by the model. Image-Text Matching
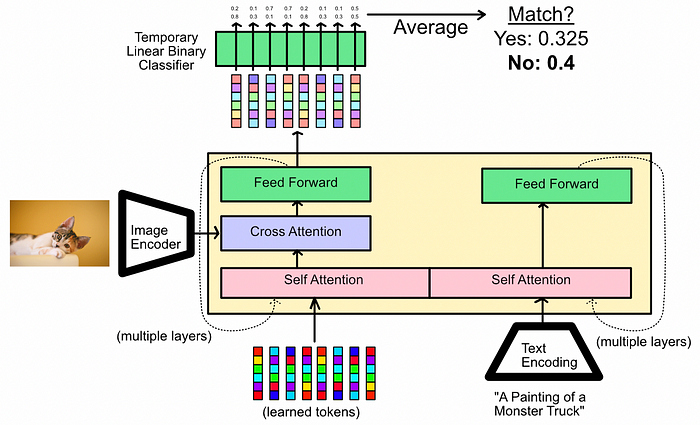
A conceptual diagram of the “Image-Text Matching” pre-training step in action. No mask is used in this phase, allowing all text and image tokens to interact within the self attention mechanism. Note how the output is false because the image is not compatible with the text “A Painting of a Monster Truck”. In this pre-training mode, we create a temporary linear classifier (a dense network) and feed all of the output tokens of the Q-Former into it. This linear classifier projects the tokens into “true” or “false” predictions, which are used to train the model to predict whether input text matches the input image. Different pairs, both with matching and not matching combinations, are fed into the model.
I talk about the concept behind using a dense network to project the output of a model for certain pre-training tasks in this post. In essence, a linear classifier that gets used to train, but is thrown out at inference time, is useful for allowing the model to learn general representations about text and images, but helps to keep the model from being too specialized in the task; so specialized that it’s less good at doing its actual job of feeding tokens to an LLM.
You can think of the Q-Former as the “understanding text and images” part, and the temporary linear classifier as the “turn that understanding into a yes or no answer” part. After this step we throw out the “turn that understanding into a yes or no answer” part, keeping the general text and image understanding.
What We Get Out of Bootstrapping
In the last section we talked about the three phases of bootstrapping; Image-Text Contrastive Learning, Image-Grounded Text Generation, and Image-Text Matching. Through the process of optimizing the Q-Former for these various tasks, the Q-Former is encouraged to build strong representations of both image and text, and a strong system for inter-relating the two.
A Note on the Learned Tokens
As previously mentioned, the learned tokens (referred to in the BLIP-2 paper as the “query vectors”) interact with both the image and text to extract key information. To flesh out that idea a bit further, I wanted to share the following quotes from the BLIP-2 paper related to the query vectors:
On the query vectors generally:
The queries interact with each other through self-attention layers, and interact with frozen image features through cross-attention layers (inserted every other transformer block). The queries can additionally interact with the text through the same self-attention layers.
On how the bootstrapping phase relates to the query vectors:
We aim to train the Q-Former such that the queries can learn to extract visual representation that is most informative of the text.
On how the query vectors relate text and image information:
Since the architecture of Q-Former does not allow direct interactions between the frozen image encoder and the text tokens, the information required for generating the text must be first extracted by the queries, and then passed to the text tokens via self-attention layers. Therefore, the queries are forced to extract visual features that capture all the information about the text.
Pre-Training
Now that we have a Q-Former which has good internal representations of both text and images, we can hook it up to an LLM and use it to train the Q-Former.

Generative pre-training diagram from BLIP-2 We can divide the caption of the image into two parts, a prefix and a sufix. We can pass the prefix through the entire BLIP-2 architecture, and modify the weights of the Q-Former to encourage the output of the LLM to output the suffix. Conceptually, this alligns the image and text representations within the Q-Former with the needs of the specific LLM model it’s being used with.
Theory Conclusion
Great, so now we understand the BLIP-2 architecture; the components, how the Q-Former (its core component) works, and how it’s trained. In the next section we’ll use a pre-trained version of BLIP-2 to do image captioning, VQA, and even have a small image grounded conversation.
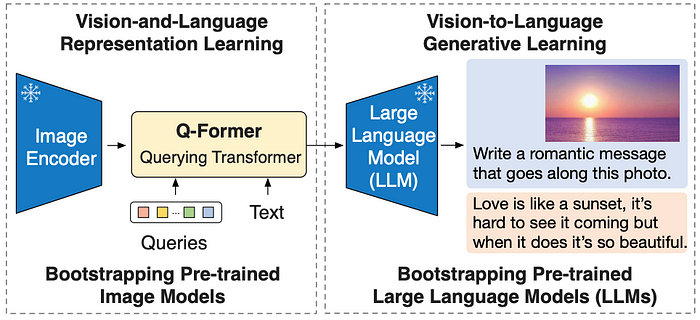
The entire BLIP-2 architecture 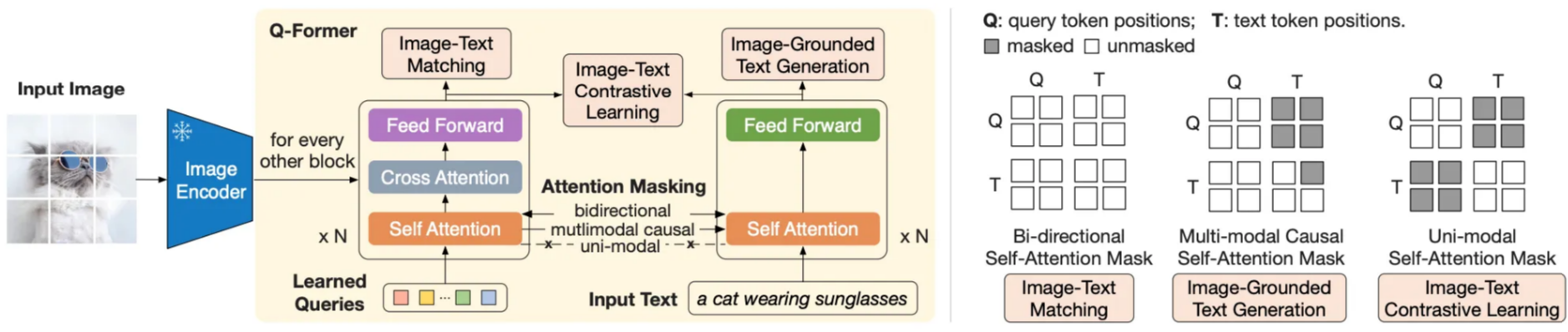
The BLIP-2 architecture in relation to the Q-Former, as defined in the BLIP-2 paper . Here we can see the inputs of the Q-Former, the learned queries, the three training bootstrapping strategies, and the three masks used to support those strategies. One subtle note: the BLIP-2 exposes the image to the Q-former every other block. I invite you to think of the rational for this on your own. For me, this feels like a residual connection which encourages repeated and increasingly more complex analysis of the image. The blocks without access to the image are allowed to form complex relations, which are then compared with the image in the subsequent block.
VQA using Q-Formers from Hugging Face
Let’s experiment with Q-Formers using a pre-built solution.
The full notebook can be viewed here:
Graciously LAVIS, a machine learning team within SalesForce (the group which published the BLIP-2 paper) provide an end-to-end pre-trained solution on Hugging face:
"""Downloading the BLIP-2 Architecture loading as an 8 bit integer to save on GPU memory. This may have some impact on performance. """ from transformers import AutoProcessor, Blip2ForConditionalGeneration import torch processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b") model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", device_map="auto", load_in_8bit=True) # load in int8As you can see BLIP-2 comes with two parts; a processor and a model. First let's explore the processor.
The Processor
In the example provided by HuggingFace, the processor is used to pre-process the inputs (both the text and image) before passing them to BLIP-2. Let’s load up an image, generate some text, and pass it to the processor to see what we get.
"""Loading and displaying a sample image """ import requests from PIL import Image url = 'https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Images/pexels-thuany-marcante-1805053.jpg?raw=true' image = Image.open(requests.get(url, stream=True).raw).convert('RGB') print(f'Image dimensions: {image.width}px X {image.height}px') dsfact = 15 display(image.resize((int(image.width/dsfact), int(image.height/dsfact))))
A sample image we’ll be using for this example Passing this image along with some sample text through the processor, we can see we get a dictionary from the processor:
"""Exploring the outputs of the processor """ processor_result = processor(image, text='a prompt from the user about the image', return_tensors="pt").to("cpu", torch.float16) processor_result.keys()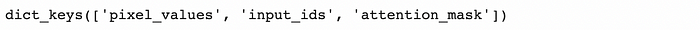
The pixel_values from the processor are a transformation of the image down to 224 x 224, with the color values normalized to a convenient range for modeling.
"""Understanding resolution and plotting one of the color channels """ import matplotlib.pyplot as plt #printing the processed image shape print(f'processed image shape: {processor_result["pixel_values"].numpy().shape}') #extracting one of the color channels from the processed image print('single color channel:') processed_im_c0 = processor_result['pixel_values'].numpy()[0,0] #rendering plt.imshow(processed_im_c0, interpolation='nearest') plt.show()
"""Understanding the distribution of values allong each color channel, both in the processed image and in the original image """ bins = 100 #extracting all color channels from the processed image processed_im_c1 = processor_result['pixel_values'].numpy()[0,1] processed_im_c2 = processor_result['pixel_values'].numpy()[0,2] #plotting modified pixel value distributions plt.figure() plt.hist([processed_im_c0.flatten(), processed_im_c1.flatten(), processed_im_c2.flatten()], bins, stacked=True, density = True) plt.title('processed image value distribution') plt.show() #plotting original pixel value distributions import numpy as np image_np = np.array(image) plt.figure() plt.hist([image_np[:,:,0].flatten(), image_np[:,:,1].flatten(), image_np[:,:,2].flatten()], bins, stacked=True, density = True) plt.title('raw image value distribution') plt.show()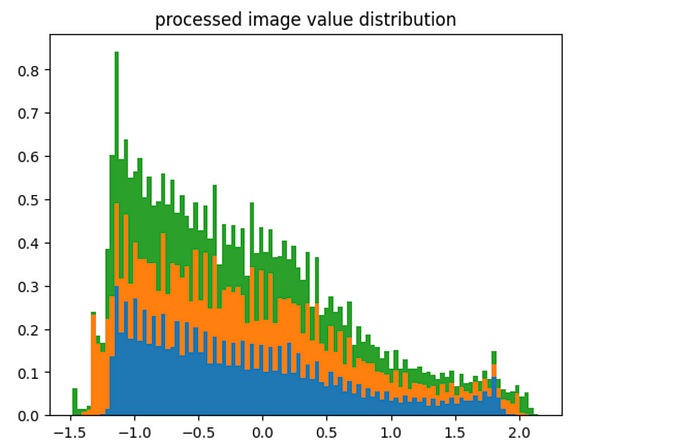
The values for the processed images are reduced within a reasonable range, and they seem to be averaged around zero 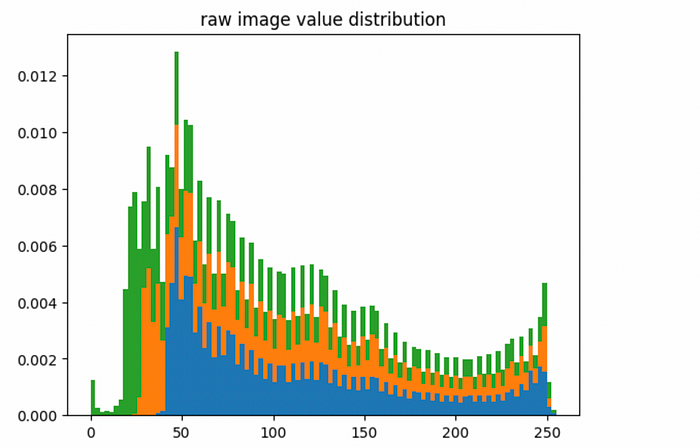
The values for the raw image have a biased distribution which spans a much wider range of values The input_ids from the processor are word piece indexes. Individual parts of a sentence are assigned individual indexes, which are later used in a word to vector embedder, which is then applied to the BLIP-2.
"""Exploring the input_ids from the processor given a variety of prompts """ print('input_ids for "a short prompt":') sampres = processor(image, text='a short prompt', return_tensors="pt").to("cpu", torch.float16) print(sampres['input_ids']) print('input_ids for "a much much much much longer prompt":') sampres = processor(image, text='a much much much much longer prompt', return_tensors="pt").to("cpu", torch.float16) print(sampres['input_ids']) print('input_ids for "alongcompoundword":') sampres = processor(image, text='alongcompoundword', return_tensors="pt").to("cpu", torch.float16) print(sampres['input_ids'])
Because we’re inferencing the model, the mask provided by the processor is simply all 1’s, allowing the model to see all input values.
"""Understanding the mask from the processor """ print('input_ids for "a short prompt":') sampres = processor(image, text='a short prompt', return_tensors="pt").to("cpu", torch.float16) print(sampres['input_ids']) print('mask for "a short prompt":') print(sampres['attention_mask'])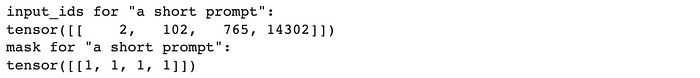
Invoking the Model
Now that we have some idea what the processor does, we can start using it to pass things to BLIP-2, and start generating output.
Image Captioning: BLIP-2 will caption an image if you provide it an image and no text.
"""Getting BLIP-2 to describe the image, unprompted this is done by only passing the image, not the text """ inputs = processor(image, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs, max_new_tokens=20) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)
Prompted Image Captioning: If you provide a prefix to a caption, BLIP-2 will try to complete the caption.
"""Prompted caption example 1 """ prompt = "this is a picture of" inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs, max_new_tokens=20) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)
The result of completing the prompt “this is a picture of” """Prompted caption example 2 """ prompt = "the weather looks" inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs, max_new_tokens=20) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)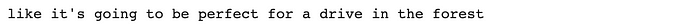
The result of completing the prompt “the weather looks”
Visual Question Answering: By invoking BLIP-2 with a specially formatted query, visual question answering can be achieved without ever having trained on visual question answering data.
prompt = "Question: what season is it? Answer:" inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs, max_new_tokens=20) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)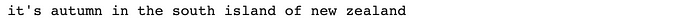
Visually Based Conversations: We can format our prompts into something resembling a conversation, thus allowing us to converse with the model about an image.
"""Visual Conversation conversing about the image """ #imagine these are generated by a person as a response to output, rather than pre-defined. questions = [ "What's in this photo?", "What is vernacular architecture?" ] #defining the state of the conversation as it progresses, to be passed to the model conv_state = '' #asking all questions in order for question in questions: #updating the conversational state with the question conv_state = conv_state+' Question: ' + question + ' Answer: ' #passing the state thus far to the model inputs = processor(image, text=conv_state, return_tensors="pt").to(device, torch.float16) #generating a response generated_ids = model.generate(**inputs, max_new_tokens=40) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() #rendering conversation print('Question: '+question) print('Answer: ' + generated_text) #updating the conversational state with the answer conv_state = conv_state + generated_text + '\n'
Conclusion
In this post we went over the history of multimodal image and language modeling; from it’s humble beginnings in visual question answering to it’s modern stage of using large language models and image encoders. We described a method for exposing images to a large language model, the BLIP-2 architecture, and described the inner workings of it’s most significant component, the Q-Former. We then explored practical applications of BLIP-2 for captioning, visual question answering, and visually based conversations.
'Research > Multimodal' 카테고리의 다른 글
Learned latent queries 의 정체 (0) 2024.09.26 CLIP - Creating strong image and language representations for general machine learning tasks. (0) 2024.09.26 Perceiver 과 Flamingo에서의 Perceiver Resampler의 미묘한 차이 (0) 2024.09.24 [Flamingo] The architecture behind modern visual language modeling (0) 2024.09.24 Perceiver / Perceiver IO (0) 2024.09.23