-
Learned latent queries 의 정체Research/Multimodal 2024. 9. 26. 17:06
LLM이 어떻게 이미지를 이해하고, 이미지에 대해 말할 수 있게 할 것인가? 문제에 대해서
Flamingo는 기존의 Pretrained LLM과 image encoder를 십분 활용하면서,
perceiver resampler로 image feature vector (CLIP (혹은 NFNet) encoder에서 추출한 visual representation)을 사용 가능한 형태로 가져오고,
gated cross attention을 통해, 수도꼭지 틀 듯이 LLM에 image 정보를 inject해준다.
이것은, LLM이 난생 처음 보는 image feature vector에 화들짝 놀라서 catastrophic하게 자신이 기존에 가지고 있던 정교한
language에 대한 understanding을 모두 잃어버리는 현상을 방지하면서 안정적으로 image를 이해할 수 있게 한다.
아 신박하도다.
기존의 contrastive learning이 image-text pair에 대해 학습해서 alignment를 하는 것과 다르게,
Flamingo는 LLM의 강력한 힘을 십분 활용해서, web상에 존재하는 어떠한 image와 text가 interweave된 data에 대해서도 학습이 가능하다.
그렇게 학습된 Flamingo는 LLM의 in-context learning 능력을 image input에 대해서도 보여주게 된다.
이렇게 visual language model for few shot learning "Flamingo"가 탄생하게 된다.
한 가지 풀리지 않던 의문이었던 "learned latent queries"의 정체를 BLIP-2 paper에서 찾았다!
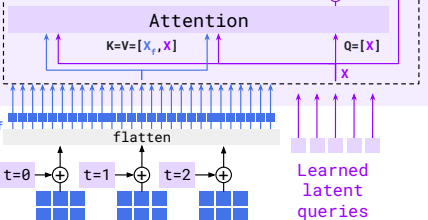
BLIP-2 는 catastrophic forgetting issue를 피하면서 기존 모델을 활용한 효율성을 위해, Q-Former를 제안한다.
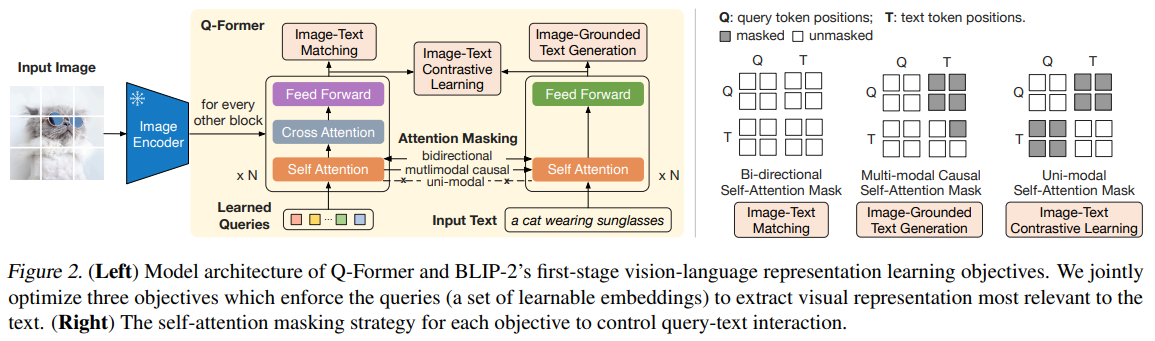
여기서도 역시 image와 text 간의 직접적인 대면은 피하고 있다. Flamingo에서 gated cross attention을 통해 LLM에 조심스럽게 이미지에 정보를 주입해주었듯이
BLIP-2 에서도 learned queries가 self attention과 cross attention을 반복적으로 수행하면서 image에서 text에 align할 정보를 extract해오고 text에 넘겨주는 bridge 역할을 한다!!
즉 Flamingo에서 그러하였듯이, 여기서도 learned queries가 매개자 역할을 하는 것이다!!Flamingo에서는 perceiver resampler를 통해 매개자가 정보를 추출해 오고, gated cross attention을 통해 LLM에 넣어주었다면
BLIP-2에서는 learned queries가 self attention block과 cross attention block에 모두 들어가서, 매개자 역할을 수행한다.(Learned queries interact with both the image and text to extract key information.)
(Flamingo에서 perceiver resampler에서 K, V에 Q가 concat된 후 attention을 수행하였던 것과 동일하다!)
그림은 이해가 쉬운데 말로 썼더니 의미 전달이 좀 혼돈이 될 것 같다.< BLIP2 논문에서 언급하는 Learned Queries 핵심 포인트 >
1) Query vector의 정체
"The queries interact with each other through self-attention layers, and interact with frozen image features through cross-attention layers (inserted every other transformer block). The queries can additionally interact with the text through the same self-attention layers."
2) Bootstrapping phase에서 query vectors는 뭘 하는가
"We aim to train the Q-Former such that the queries can learn to extract visual representation that is most informative of the text."
3) query vectors가 어떻게 text와 image 간 information을 열결시키는가
"Since the architecture of Q-Former does not allow direct interactions between the frozen image encoder and the text tokens, the information required for generating the text must be first extracted by the queries, and then passed to the text tokens via self-attention layers. Therefore, the queries are forced to extract visual features that capture all the information about the text."'Research > Multimodal' 카테고리의 다른 글
Grokking self-supervised (representation) learning: how it works in computer vision and why (0) 2024.09.28 SimCLR (0) 2024.09.26 CLIP - Creating strong image and language representations for general machine learning tasks. (0) 2024.09.26 Visual Question Answering with Frozen Large Language Models (0) 2024.09.25 Perceiver 과 Flamingo에서의 Perceiver Resampler의 미묘한 차이 (0) 2024.09.24