-
[Chronos] Learning the Language of Time Series*Paper Writing 1/Related_Work 2024. 10. 30. 23:38
https://arxiv.org/pdf/2403.07815
https://github.com/amazon-science/chronos-forecasting
Abstract
We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
1. Introduction
Time series forecasting is an essential component of decision-making across various domains, including retail, energy, finance, healthcare, climate science, among others. Traditionally, forecasting has been dominated by statistical models such as ARIMA and ETS. These have served as reliable tools, at least until the recent shift towards deep learning techniques (Hyndman & Athanasopoulos, 2018; Benidis et al., 2022). This shift can be attributed to the availability of large and diverse time series data sources, and the emergence of operational forecasting problems (Kolassa & Januschowski, 2019) that play to the strengths of deep forecasters, i.e., the ability to extract patterns out of a large collection of time series. Despite their impressive performance, deep forecasters still operate in the standard regime of training and prediction on the same dataset. While there have been works dedicated to transfer learning (Ye & Dai, 2018) and domain adaptation (Jin et al., 2022) for forecasting, the field has yet to converge on a unified, general-purpose forecasting model, a goal that remains a beacon for time series researchers.
The emergence of large language models (LLMs) with zero-shot learning capabilities has ignited interest in developing “foundation models” for time series. In the context of LLMs, this interest has been pursued through two main avenues: directly prompting pretrained LLMs in natural language (Gruver et al., 2023; Xue & Salim, 2023) and fine-tuning LLMs for time series tasks (Zhou et al., 2023a; Jin et al., 2024). However, these methods face significant limitations, notably the need for prompt engineering or fine-tuning for each new task, or reliance on large-scale models (GPT-3 (Brown et al., 2020), Llama 2 (Touvron et al., 2023), etc.) that demand substantial computational resources and time for inference. Recent concurrent work (Dooley et al., 2023; Das et al., 2023; Rasul et al., 2023; Woo et al., 2024) also explores pretraining transformer-based models with sophisticated time-series-specific designs on a large corpus of real and (or) synthetic time series data.
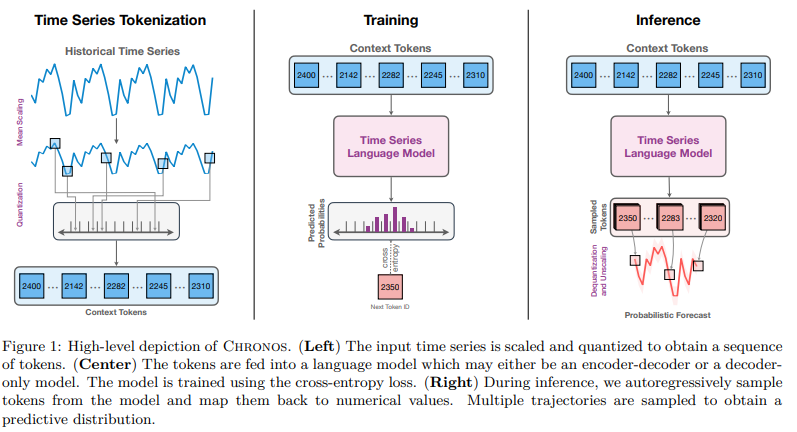
In this work, we take a step back and ask: what are the fundamental differences between a language model that predicts the next token, and a time series forecasting model that predicts the next values? Despite the apparent distinction — tokens from a finite dictionary versus values from an unbounded, usually continuous domain — both endeavors fundamentally aim to model the sequential structure of the data to predict future patterns. Shouldn’t good language models “just work” on time series? This naive question prompts us to challenge the necessity of time-series-specific modifications, and answering it led us to develop Chronos, a language modeling framework minimally adapted for time series forecasting. Chronos tokenizes time series into discrete bins through simple scaling and quantization of real values. In this way, we can train off-the-shelf language models on this “language of time series,” with no changes to the model architecture (see Figure 1 for a high-level depiction of Chronos). Remarkably, this straightforward approach proves to be effective and efficient, underscoring the potential for language model architectures to address a broad range of time series problems with minimal modifications.
For the development of a useful general-purpose time series forecasting model, the scarcity of publicly available time series datasets, both in quantity and quality, is arguably more critical than the modeling framework. In addition to the comprehensive collection of public datasets we used to train Chronos, a central aspect of our approach is the integration of data augmentation strategies, including TSMixup and KernelSynth. TSMixup randomly samples a set of base time series from different training datasets, and generates new time series based on a convex combination of them; KernelSynth uses Gaussian processes to generate synthetic time series by randomly composing kernel functions. These techniques address the inherent limitations of small training datasets in time series forecasting, enhancing model robustness and generalization.
Our comprehensive evaluation across 42 datasets establishes Chronos as a benchmark for both in-domain and zero-shot forecasting, surpassing both traditional models and task-specific deep learning approaches. Notably, Chronos achieves impressive zero-shot forecasting performance out of the box, without necessitating task-specific adjustments. Its accuracy, coupled with its relatively modest model size, positions it as a preferable alternative to larger, more computationally demanding models for zero-shot forecasting applications. By its very nature as a language model operating over a fixed vocabulary, Chronos can seamlessly integrate with future advancements in LLMs, making it an ideal candidate for further development as a generalist time series model.
The rest of the paper is organized as follows. Section 2 introduces the background on time series forecasting and language models, and discusses related work. In Section 3, we describe Chronos, our proposed language modeling framework for time series. Section 4 discusses our data augmentation technique and synthetic time series generation process. In Section 5, we present our main results and a rigorous analysis of different design choices. We discuss future directions in Section 6, and conclude the paper in Section 7. Additional material is presented in the appendices.
2. Background and Related Work
Time series forecasting
concerns using historical data from a quantity of interest (typically real-valued) to predict their future values. Formally, given a uniformly-spaced time series x1:C = [x1, . . . , xC ], we are interested in predicting the joint distribution of the next H steps, p(xC+1:C+H|x1:C ). In this work, we focus on univariate forecasting, where the observations are scalars, i.e., xi ∈ R for all i.
Time series forecasting can be addressed with a variety of different methods which can be broadly categorized into classical forecasting methods and deep learning methods. Classical forecasting methods such as ETS, ARIMA (Hyndman et al., 2008), Theta (Assimakopoulos & Nikolopoulos, 2000) fit a separate model to each time series independently (hence referred to as local models). In contrast, deep learning forecasting models learn across time series in a given dataset (and are called global models). These methods leverage advances in deep learning, such as RNNs which are used by DeepState (Rangapuram et al., 2018), DeepFactor (Wang et al., 2019), DeepAR (Salinas et al., 2020), TimeGrad (Rasul et al., 2021), and transformers which are used by TFT (Lim et al., 2021) and PatchTST (Nie et al., 2023). Apart from the choice of architecture, these approaches differ in the way they model the target, with some modeling the density function while others directly predicting a set of quantiles (Wen et al., 2017; Gasthaus et al., 2019; Park et al., 2022). Nevertheless, not all models produce probabilistic forecasts: notably, models such as Informer (Zhou et al., 2021) and DLinear (Zeng et al., 2023) only produce point forecasts.
Large language models (LLMs)
have demonstrated impressive performance on various natural language processing tasks (Brown et al., 2020; Chung et al., 2022; Touvron et al., 2023). Given a sequence of input tokens, w1:k = [w1, . . . , wk], language models aim to predict the next token, wk+1, by modeling the conditional distribution, p(wk+1|w1:k). The tokens belong to a vocabulary, V, and may be characters, subwords (Sennrich et al., 2015), or words, depending on the tokenization scheme used.
Most modern LLMs (Brown et al., 2020; Chung et al., 2022; Touvron et al., 2023) are based on the transformer architecture (Vaswani et al., 2017). The original transformer architecture is an encoder-decoder model designed for machine translation. The encoder maps an input sentence of some language to a continuous representation, and the decoder generates the translation token-by-token using the input representation and previously decoded tokens. Many popular language models, such as BART (Lewis et al., 2019) and T5 (Raffel et al., 2020; Chung et al., 2022), belong to this family. Another popular architecture for LLMs is decoder-only, used in GPT-3 (Brown et al., 2020) and Llama 2 (Touvron et al., 2023), where the model only attends to tokens up to the current token. LLMs are typically trained on a very large corpus of text with their number of parameters ranging from millions (Raffel et al., 2020) to hundreds of billions (Chowdhery et al., 2023). We refer the reader to Zhao et al. (2023) for a recent survey on this area of research.
LLM-based forecasters.
Inspired by the success of pretrained LLMs, recent work has shown that LLMs are general pattern recognizers (Mirchandani et al., 2023) and several methods adapting LLMs to the time series domain have been developed. One line of work treats numerical time series data as raw text and directly uses the pretrained LLMs with minimal or no fine tuning to forecast unseen time series. PromptCast (Xue & Salim, 2023) leverages pretrained LLMs for forecasting by transforming the time series data into text-based input and output pairs and reformulating the forecasting problem as a question answering task. However, PromptCast requires dataset-specific templates for converting numerical data to text prompts. Perhaps the most straightforward LLM-based forecasting model is LLMTime (Gruver et al., 2023), which shows clear evidence for zero-shot forecasting ability of pretrained LLMs on a variety of benchmark time series datasets. LLMTime proposes a new tokenization scheme that encodes real-valued data as a string of digits after fixing the numerical precision and scaling the data appropriately. Once encoded as strings, forecasts are obtained in a zero-shot setting from pretrained LLMs such as GPT-3 (Brown et al., 2020) and Llama 2 (Touvron et al., 2023). Nevertheless, the use of such compute-hungry models hampers the scalability and practical utility of LLMTime.
Zhou et al. (2023a) propose a unified one-fits-all model (GPT4TS) for different time series analysis tasks by using a pretrained GPT-2 model (Radford et al., 2019) as a backbone and only fine-tune the positional embeddings and the parameters of the layer normalization for each individual task. Instead of using tokenized input, they directly feed the model with patch embeddings, similar to PatchTST (Nie et al., 2023). Recent concurrent work, Time-LLM (Jin et al., 2024), repurposes LLMs for time series forecasting by aligning embeddings of time series patches with text prototypes, and prompting the (frozen) LLM with these aligned embeddings and a natural language prefix describing the task. Unlike Chronos, both GPT4TS and TimeLLM require in-domain training or fine-tuning, i.e., they are fine-tuned and tested on each dataset separately. Furthermore, the aforementioned methods are based on prompting or fine-tuning pretrained LLMs. In contrast, Chronos trains language models from scratch on a large collection of time series, tokenized via scaling and quantization.
Zero-shot forecasting.
Zero-shot forecasting is the ability of models to generate forecasts for time series from unseen datasets. Some early work (Orozco & Roberts, 2020; Oreshkin et al., 2021; Jin et al., 2022) in zero-shot forecasting considers training on a single time series dataset and testing on a different dataset. ForecastPFN (Dooley et al., 2023) tackles the problem of zero-shot forecasting by training a transformer-based model purely on synthetic data generated according to predefined trend, seasonalities (daily, monthly, yearly). The trained transformer model is then used to forecast real-world time series in a zero-shot setting. In this work, we also propose a method to generate synthetic time series data from Gaussian processes (Section 4.2); however, we use the synthetic data in combination with real data to train Chronos models, which improves the overall zero-shot performance. Furthermore, Chronos models are probabilistic, whereas ForecastPFN can only generate point forecasts.
Recent concurrent works (Rasul et al., 2023; Goswami et al., 2024; Das et al., 2023; Woo et al., 2024) also develop zero-shot forecasting models by pretraining transformer-based architectures on a large corpus of time series data. These works operate on the real values of the time series and include time-series-specific designs such as time features, lags, patching, and real-valued distribution heads, among others. In contrast, Chronos follows a minimalist approach by tokenizing time series values into a fixed vocabulary and training existing language model architectures on these tokens without any time-series-specific design or features. That is, Chronos uses a categorical distribution to model the observations, performing regression via classification.
Other time series tasks.
Similar to Zhou et al. (2023a), recent works have studied general purpose models applicable across time series tasks including imputation, forecasting, classification and anomaly detection. Wu et al. (2023) develop a task-generic backbone based on the Inception model (Szegedy et al., 2015). In order to use the CNN-based Inception model, one dimensional time series is transformed into a two dimensional image-like representation by essentially segmenting the time series based on the periodicity and stacking the segments. SimMTM (Dong et al., 2023) is a masked pretraining framework for time series which learns general time series representations that are then used for forecasting and classification via fine-tuning. Although we focus on univariate time series forecasting in this work, based on its excellent performance on unseen time series datasets, we hypothesize that Chronos learns general representations that can potentially be deployed for tasks beyond forecasting.
3. Chronos: A Language Modeling Framework for Time Series
In this section we introduce Chronos, a framework adapting existing language model architectures and training procedures to probabilistic time series forecasting. While both language and time series are sequential in nature, they differ in terms of their representation — natural language consists of words from a finite vocabulary, while time series are real-valued. This distinction necessitates specific modifications to existing language modeling frameworks, especially concerning tokenization, to make them applicable to time series data. Nevertheless, since existing transformer models have excelled on language tasks, our design philosophy involves making minimal changes to the model architectures and training procedure.
3.1. Time Series Tokenization
Consider a time series x1:C+H = [x1, . . . , xC+H], where the first C time steps constitute the historical context, and the remaining H represent the forecast horizon. Language models operate on tokens from a finite vocabulary, so using them for time series data requires mapping the observations xi ∈ R to a finite set of tokens. To this end, we first scale and then quantize observations into a fixed number of bins.
Scaling.
The scale of time series can differ significantly even within a single dataset. This poses optimization challenges for deep learning models. Therefore, individual time series are normalized to facilitate better optimization. In the case of Chronos, the goal of normalization is to map the time series values into a suitable range for quantization. A common normalization technique involves applying an affine transformation to the time series, i.e., x˜i = (xi − m)/s. Several popular normalization schemes, such as mean scaling, standard scaling and min-max scaling, can be obtained by appropriately choosing m and s. We opt for mean scaling, a method that has proven effective in deep learning models commonly used for practical time series applications (Salinas et al., 2020), but other approaches are viable and only require minimal changes. Mean scaling normalizes individual entries of the time series by the mean of the absolute values in the historical context. Specifically, this involves setting m = 0 and s = 1 / C Summation i=1 C |xi |.

respectively. The positioning of bin centers and edges can either be data-dependent or uniform (Rabanser et al., 2020). Quantile binning, a type of data-dependent binning, exploits the cumulative distribution function (CDF) of the training datapoints to construct bins such that approximately equal number of datapoints are assigned to each bin. In contrast, uniform binning selects bin centers uniformly within some interval [l, r]. Since the distribution of values for unseen downstream datasets can differ significantly from the training distribution, we opt for uniform binning in our experiments, but other quantization techniques can be used. We refer the reader to Rabanser et al. (2020) for a detailed discussion on quantization schemes for time series. A potential limitation of this approach is that the prediction range is restricted between [c1, cB], making it theoretically infeasible to model time series with a strong trend. We explore this further in a practical setting in Section 5.7.
Apart from the time series tokens {1, 2, . . . , B}, we include two special tokens, commonly used in language models, into the time series vocabulary, Vts: PAD and EOS. The PAD token is used to pad time series of different lengths to a fixed length for batch construction and to replace missing values. The EOS token is appended to the quantized and padded time series to denote the end of the sequence. While the use of an EOS token is not strictly necessary in the case of time series, it makes training and inference using popular language modeling libraries convenient. The sequences of tokens from Vts can readily be processed by language models (both encoder-decoder and decoder only models), to train them as usual. A common approach in time series modeling is to incorporate time and frequency information, through features such as day-of-week, weekof-year, and so on. Perhaps counter-intuitively, in Chronos, we ignore time and frequency information, treating the “time series” simply as a sequence.
We primarily focus on the variants of the encoder-decoder T5 model (Raffel et al., 2020). Additionally, we conduct an experiment with the GPT-2 (Radford et al., 2019) model to demonstrate that our approach can be straightforwardly extended to decoder-only models. No modifications are required to the language model architecture, except adjusting the vocabulary size to |Vts|, which depends on the number of bins used for quantization and may be different from the vocabulary size of the original language model. Concretely, adjusting the vocabulary size entails truncating (or extending) the input and output embedding layers of the language model.
3.2. Objective Function

Note that the categorical cross entropy loss (Eq. 2) is not a distance-aware objective function, i.e., it does not explicitly recognize that bin i is closer to bin i + 1 than to i + 2. Instead, the model is expected to associate nearby bins together, based on the distribution of bin indices in the training dataset. In other words, Chronos performs regression via classification (Torgo & Gama, 1997). This is unlike typical probabilistic time series forecasting models, which either use parametric continuous distributions such as Gaussian and Student’s-t (Salinas et al., 2020) or perform quantile regression (Wen et al., 2017; Lim et al., 2021).
Opting for a categorical output distribution offers two key advantages. Firstly, it requires no modification to the language model architecture or training objective, enabling the use of popular language modeling libraries and the utilities they provide out of the box (Wolf et al., 2020). Secondly, it imposes no restrictions on the structure of the output distribution, allowing the model to learn arbitrary distributions, including multimodal ones. This flexibility proves especially valuable for a pretrained model, as time series datasets from diverse domains may follow distinct output distribution patterns.
3.3. Forecasting
Chronos models are probabilistic by design and multiple realizations of the future can be obtained by autoregressively sampling from the predicted distribution, pθ(zC+h+1|z1:C+h), for h ∈ {1, 2, . . . , H}. These sample paths come in the form of token IDs that need to be mapped back to real values and then unscaled to obtain the actual forecast. The dequantization function d from Eq. (1) maps the predicted tokens to real values: these are then unscaled by applying the inverse scaling transformation, which in the case of mean scaling involves multiplying the values by the scale s.
4. Data Augmentation
The quality and quantity of public time series data pales in comparison to the natural language processing (NLP) domain, which benefits from ample high-quality text datasets such as WikiText-103 (Merity et al., 2016), C4 (Raffel et al., 2020), and The Pile (Gao et al., 2020). This poses challenges for training models intended for zero-shot forecasting, which rely on large-scale time series data with diverse patterns. To address this issue, we propose enhancing the diversity of training data by generating mixup augmentations from real datasets and supplementing training with synthetic data.
4.1. TSMixup: Time Series Mixup
Mixup (Zhang et al., 2017) is a data augmentation scheme proposed in the context of image classification. It generates convex combinations of random image pairs and their labels from the training dataset, which alleviates issues such as memorization and overfitting in deep learning models. Existing works (Carmona et al., 2021; Zhou et al., 2023b) have extended Mixup to the time series domain. Building upon these works, we propose TSMixup, which generalizes the idea of Mixup to more than two datapoints. Concretely, TSMixup randomly samples k ∼ U {1, K} time series of a specific length, l ∼ U {lmin, lmax}, from the training datasets, scales them, and takes their convex combination,

where x˜ (i) 1:l denotes the i-th scaled time series. The combination weights, [λ1, . . . , λk], are sampled from a symmetric Dirichlet distribution, Dir(α). The complete pseudocode of TSMixup can be found in Algorithm 1 in Appendix A. Intuitively, TSMixup enhances the diversity of data by combining patterns from different time series. Figure 2 shows example augmentations generated by TSMixup and illustrates how different patterns are mixed.

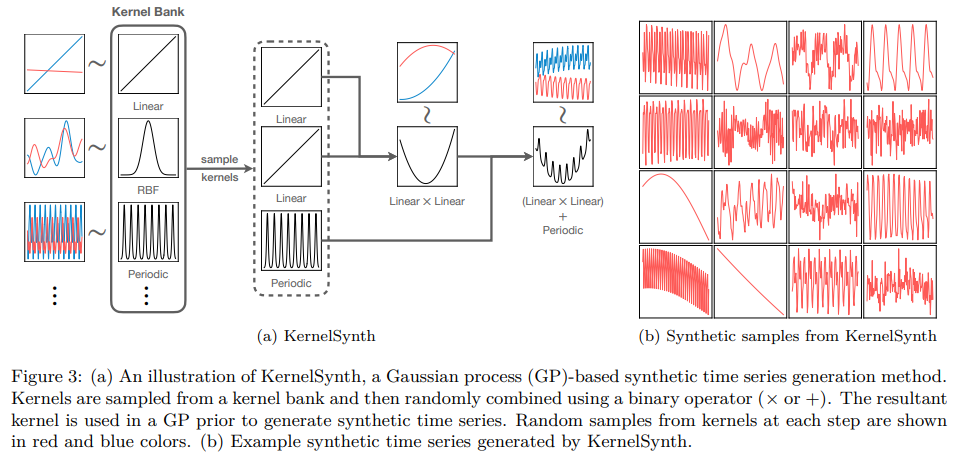
4.2. KernelSynth: Synthetic Data Generation using Gaussian Processes
While TSMixup improves pattern diversity, it may still prove insufficient for training a generalist time series model, especially when real data is limited. To further supplement the training dataset, we propose KernelSynth, a method to generate synthetic time series using Gaussian processes (GPs). KernelSynth is inspired by the Automatic Statistician (Duvenaud et al., 2013), where a compositional search over a space of GP kernels is performed to explain the structure of a time series. We use the inverse of this process — randomly compose GP kernels to generate new time series.
GPs are distributions over functions defined by the mean function, m(t), and the positive definite kernel, κ(t, t′ ), where t ∈ R is the domain. The kernel specifies a covariance function which defines the joint variability of the function values at an arbitrary pair of points, (t, t′ ), in the input domain. Diverse patterns can be generated by appropriately selecting the kernel. We constructed a kernel bank, K, of basis kernels defining fundamental time series patterns. These include linear kernels for trend, RBF kernels for smooth local variation, and periodic kernels for seasonalities found in typical time series frequencies. The final kernel, κ˜(t, t′ ), is constructed by sampling j ∼ U{1, J} kernels from K with replacement and combining these kernels via random binary operations, + or ×. A synthetic time series is generated by drawing a sample of length lsyn from the GP prior, GP(m(t) = 0, κ˜(t, t′ )); see Algorithm 2 in Appendix A for details. Figure 3 depicts this generative process used in KernelSynth, illustrating how time series with intricate patterns can arise from the composition of simple basis kernels.
5. Experiments
In this section, we present empirical results on commonly used benchmark datasets. First, we give an overview of the datasets, training strategy, baselines, and evaluation metrics (Section 5.1-5.4). Table 1 provides a high-level summary of the datasets and baselines used in our experiments. We then (a) evaluate the performance of Chronos models in the in-domain and zero-shot settings against local models and task-specific deep learning models (Section 5.5); (b) analyze the effect of various design choices such as model size, initialization, synthetic data proportion, context length, and vocabulary size on the performance of Chronos models (Section 5.6); and (c) analyze the qualitative performance of Chronos models and highlight their limitations (Section 5.7). We discuss our key findings in this section and relegate specific experiment details to the appendices.

5.1. Datasets
To train and evaluate Chronos models, we collected a wide variety of publicly available datasets spanning various application domains including energy, transport, healthcare, retail, web, weather, finance, and with sampling frequencies ranging from 5 minutes up to yearly. The complete list of datasets, together with their respective sources and additional details, is given in Appendix B. In total, our dataset collection comprises 55 datasets from multiple sources, including the Monash Time Series Forecasting Repository (Godahewa et al., 2021), the M-competitions (Makridakis et al., 1979; Makridakis & Hibon, 2000; Makridakis et al., 2020; 2022), and public domain datasets from Kaggle.
We categorize this collection into three subsets, based on how we use them for training and evaluating Chronos models: (a) datasets exclusively used for training (13 datasets); (b) Benchmark I datasets, employed for both training and evaluation, representing an in-domain evaluation (15 datasets); and (c) Benchmark II datasets, used solely for evaluation, constituting a zero-shot evaluation (27 datasets). In categorizing the datasets in this way, we tried to find a good balance between keeping as many datasets as possible for the zero-shot evaluation of Chronos models, among the ones most commonly used in the literature, while still having enough variety of domains and sampling frequencies in the training data. Overall, we used 28 datasets for training Chronos models, consisting of about 890K univariate time series with approximately 84B observations (tokens) in total. For both in-domain (I) and zero-shot (II) benchmark datasets, we used the last H ∈ N + observations of each time series as a held-out test set: all models are judged by the accuracy of their forecast on such held-out set, which no model had access to for training purposes. The prediction length H is task-specific (see Table 2 in Appendix B), where we define a task as a dataset and prediction length pair. Tasks in both benchmarks exhibit diverse properties, in terms of the dataset size, frequency, history length, and prediction length, making them rich benchmarks reflective of real world scenarios.
5.2. Training Corpus and Protocols
We selected T5 (Raffel et al., 2020) as the main architecture for Chronos in our experiments, since it is available in a variety of sizes, ranging from 16M (Tiny) to 11B (XXL) parameters (Tay et al., 2021). We also conducted experiments with the decoder-only GPT-2 model to demonstrate the applicability of the Chronos framework to decoder-only models. In the following, we discuss the training configurations used for our main results (Section 5.5) and explore alternatives for some of the hyperparameters in Section 5.6.
We trained T5 models of 4 sizes,1 namely, Mini (20M), Small (46M), Base (200M) and Large (710M), and the GPT-2 base model (90M), on 10M TSMixup augmentations (see Section 4.1) generated from the 28 training datasets, with K = 3 in Algorithm 1, and 1M synthetic time series generated using Gaussian processes (see Section 4.2). Note that with this setup, original time series are adequately represented since they are included in the TSMixup augmentations with probability 1/3. We sampled time series from the augmentations and synthetic data in the ratio 9:1 during training. Each model is trained with an effective batch size of 256 sequences, using distributed data parallelism and gradient accumulation, whenever necessary. These sequences are constructed by slicing random windows from the time series, and then scaling and quantizing them into equal-sized bins within the interval [l= − 15, r=15], as described in Section 3.1. The context length of the sequences was set to 512, the default for T5 models, and the prediction length is set to 64, a value greater than the prediction lengths of all tasks we consider in our evaluation.
The models were optimized for 200K steps using the AdamW optimizer with a weight decay of 0.01. The learning rate was annealed linearly from its initial value of 0.001 to 0 over the training steps. The other model and training hyperparameters were set to their defaults used in the transformers library (Wolf et al., 2020). We used an AWS EC2 instance with 8 A100 (40GB) GPUs to train all Chronos models, and we employed faster floating point formats (TF32) and model compilation to speed up training. Table 5 in Appendix E reports the training time and the approximate cost of training Chronos models of different sizes.
5.3. Baselines
We assessed the performance of Chronos models against a variety of time series forecasting baselines. From statistical forecasting literature (Hyndman & Athanasopoulos, 2018), we included Naive, Seasonal Naive, AutoETS, AutoARIMA (Hyndman et al., 2008) and AutoTheta (Assimakopoulos & Nikolopoulos, 2000). Additionally, we compared against several neural forecasting baselines, including WaveNet (Oord et al., 2016), DeepAR (Salinas et al., 2020), N-BEATS (Oreshkin et al., 2020), TFT (Lim et al., 2021), DLinear (Zeng et al., 2023), PatchTST (Nie et al., 2023), N-HiTS (Challu et al., 2023), and GPT4TS (Zhou et al., 2023a). Furthermore, from the recently proposed pretrained time series models, we included the ones with publicly available weights: Lag-Llama (Rasul et al., 2023) and Moirai-1.0-R (Woo et al., 2024). On Benchmark II (i.e., zero-shot datasets for Chronos models), we also evaluated against two zero-shot methods: ForecastPFN (Dooley et al., 2023) which is a transformer model pretrained only on synthetic time series data and LLMTime (Gruver et al., 2023) which uses LLMs for zero-shot forecasting.
We categorize Chronos models and the baselines into three groups: local models that estimate parameters for each time series individually; task-specific models trained or fine-tuned for each task separately; and pretrained models which do not perform task-specific training, instead using a single model across all tasks. Further details on the implementation and training of these baselines can be found in Appendix C.
5.4. Evaluation Metrics
Whenever possible,2 we evaluated models both in terms of their probabilistic and point forecast performance. We used the weighted quantile loss (WQL) to assess the quality of the probabilistic forecasts: the WQL is related to the continuous ranked probability score (CRPS, Gneiting & Raftery (2007))3 and is commonly used to evaluate probabilistic forecasts (Gasthaus et al., 2019; Shchur et al., 2023). The WQL measures the compatibility between the predictive distribution and the ground-truth observation at a uniformlyspaced grid of quantile levels; we compute the WQL on 9 uniformly-spaced quantile levels {0.1, 0.2, . . . , 0.9}. Quantile forecasters such as TFT were directly trained on these quantile levels. For methods requiring sampling, we estimated the quantiles using 20 sample forecast paths. We used the mean absolute scaled error (MASE, Hyndman & Koehler (2006)) to evaluate the point forecast performance. The MASE is defined as the absolute error of the forecast scaled by the historical seasonal error of the time series, and was selected due to its favorable properties over other point forecasting metrics (Hyndman & Koehler, 2006). We used the median forecast (0.5-quantile) for computing the MASE for the probabilistic forecasters. See Appendix D for a detailed discussion on the evaluation metrics.
Since the magnitude of the evaluation metrics can vary across datasets, we adopt a different approach to aggregate scores than naive averaging. For each dataset, we compute the relative score of each model as the model’s score divided by the score of a baseline model (here, Seasonal Naive). The relative scores are aggregated across all datasets using the geometric mean. The choice of the geometric mean is deliberate — Fleming & Wallace (1986) show that the arithmetic mean can yield misleading conclusions in this context, and the geometric mean is provably the only meaningful way to aggregate such relative scores. Furthermore, the geometric mean is also not sensitive to the choice of the baseline, and the model ordering stays intact if another baseline is selected instead. We used Seasonal Naive due to its simplicity and popularity as a forecasting baseline. For models that failed or could not finish evaluation within the allotted time on certain datasets, we use a relative score of 1, i.e., the baseline relative score, when aggregating the results. We assign equal weights to all tasks during aggregation, reflecting real-world scenarios where datasets may have different numbers of time series, frequencies, history and prediction lengths.
5.5. Main Resutls
In this section, we present our main results on 42 datasets, which comprise Benchmark I (15 datasets) and Benchmark II (27 datasets). Chronos models surpass classical statistical baselines, task-specific deep learning models, and other pretrained models on the in-domain datasets (Benchmark I; see Section 5.5.1). On the zero-shot datasets (Benchmark II; Section 5.5.2), Chronos models comfortably outperform statistical baselines and other pretrained models, while performing on par with the best deep learning models trained on these tasks. With an inexpensive fine-tuning regimen, our Chronos-T5 (Small) model achieves the top spot on Benchmark II, significantly outperforming all baselines.
5.5.1. Benchmark 1: in-domain Results
Benchmark I comprises 15 datasets that were also part of the training data of Chronos models, i.e., this benchmark evaluates the in-domain performance of Chronos models (see Table 2). Figure 4 summarizes the probabilistic and point forecasting performance for all models on the held-out test windows, in terms of their aggregated relative scores, computed as described in Section 5.4. The bigger Chronos-T5 models (Base and Large) significantly outperform baseline models, obtaining the best aggregated relative scores and average ranks (Figure 18 in Appendix E). These models not only perform better than local models (e.g., AutoETS and AutoARIMA), but they also perform better than task-specific deep learning models trained or fine-tuned for each dataset (e.g., PatchTST and DeepAR) and other pretrained models (e.g., Lag-Llama and Moirai-1.0-R).
The smaller Chronos-T5 models (Mini and Small) and Chronos-GPT2 also perform better than the majority of baselines, with the exception of PatchTST. Between the two baseline pretrained models studied in this experiment, Moirai-1.0-R clearly outperforms Lag-Llama. Notably, the best Moirai-1.0-R model (Large, 311M) is still outperformed by the smallest Chronos-T5 model (Mini, 20M) even though Moirai1.0-R models were trained on a significantly larger corpus of time series data. Task-specific deep learning models, trained across multiple time series for a specific task, perform better than local statistical models that fit parameters for each time series. Interestingly, the Seasonal Naive baseline performs competitively against other local models on this benchmark, suggesting that the datasets in this benchmark exhibit strong seasonal patterns. This is unsurprising since a majority of these datasets belong to domains such as energy and transport that tend to be highly seasonal in nature. The raw WQL and MASE values for individual datasets summarized in Figure 4 can be found in Tables 6 and 7 in Appendix E.
These results demonstrate the benefit of using models that are trained only once across multiple datasets, over task-specific models trained individually for each task. Such models could streamline production forecasting systems, where forecasts from different time series tasks are required, by obviating the need for training separate models for each task.

5.5.2. Benchmark 2: Zero-shot Results
Benchmark II consists of 27 datasets that were not used during Chronos models’ training (see Table 2 in appendix B), i.e., this benchmark evaluates the zero-shot performance of these models. These datasets belong to diverse domains and frequencies, some of which are not even part of the training data, making this a challenging benchmark for Chronos. 4 Figure 5 summarizes the results on Benchmark II in terms of the aggregated relative scores. This benchmark is clearly more challenging than Benchmark I (Figure 4), as the best models tend to offer lower improvements relative to the baseline.
Nevertheless, despite never having seen these datasets during training, Chronos models significantly outperform local statistical models. On probabilistic forecasting (aggregate relative WQL), Chronos models achieve the 2nd and 3rd spots, performing better than most task-specific models that have been trained on these tasks. Chronos-T5 (Large) places 3rd in terms of the point forecasting performance, narrowly losing the 2nd spot to N-HiTS. Chronos models also significantly outperform other pretrained models such as Moirai-1.0-R, Lag-Llama, LLMTime, and ForecastPFN, and even GPT4TS, which fine-tunes a pretrained GPT-2 model on each dataset. Moirai-1.0-R obtains the best performance after Chronos although the evaluation setup may have been advantageous for Moirai-1.0-R as many datasets in Benchmark II were part of its pretraining corpus. The raw WQL and MASE values for individual datasets summarized in Figure 5 can be found in Tables 8 and 9 in Appendix E.
The results on this benchmark highlight the promise of Chronos as a generalist time series forecaster — it performs significantly better than local models that are commonly used in a zero-shot setting, and it performs on par with the best task-specific deep learning models.

Fine tuning.
Motivated by the remarkable zero-shot performance of Chronos models, we conducted a preliminary investigation into fine-tuning Chronos models individually on datasets from Benchmark II.
We selected the Chronos-T5 (Small) model for this experiment due to its good zero-shot performance with a relatively low training cost. We fine-tuned the model in a dataset-agnostic fashion with an initial learning rate of 0.001, annealed linearly to 0 over 1000 steps. Figure 6 shows that fine-tuning significantly improves the aggregate performance of the model on Benchmark II. The fine-tuned Chronos-T5 (Small) model now takes the top spot on Benchmark II overall, overtaking both larger (zero shot) Chronos models and the best task-specific models. Notably, Chronos-T5 (Small) is not even the most accurate variant of Chronos on Benchmark II in the zero shot setting, suggesting that further improvements may be obtained by fine-tuning larger Chronos-T5 variants.

5.6. Analysis of Hyperparameters
Here, we explore the effect of different design choices on the downstream model performance, beginning with a comparison of different model sizes and initializations. We then analyze the effect of training steps, synthetic data proportion, context length, and vocabulary size, on the performance of Chronos-T5 (Small). We only vary the parameter of interest, keeping everything else fixed to the value used in the main results.
Model size.
We experimented with four model sizes ranging from 20M to 710M parameters.5 Unsurprisingly, the training loss improves with the model capacity, as shown in Figure 7a. We also observe this trend in the downstream model performance — it improves with the model size for both in-domain and zero-shot benchmarks, as shown in Figure 7b. These trends suggest that even larger models may improve performance further. However, we did not explore larger models due to slow inference times which would render them impractical for real-world applications.

Initialization.
We investigated whether initializing Chronos models to the corresponding T5 language models pretrained by Tay et al. (2021) on the C4 dataset (Raffel et al., 2020) has any impact on the training dynamics or the downstream performance. Figure 8 shows the training loss curve for models initialized randomly and those initialized with language model weights. Notably, models initialized randomly tend to converge to a lower training loss compared to their counterparts initialized with language model weights. For the larger models (Base and Large), models initialized with language model weights initially exhibit a faster decrease in training loss, but they ultimately converge to a higher final loss.
Overall, these observations suggest that language model weights are not particularly remarkable in the context of time series forecasting and offer no improvement over random initialization. These conclusions are further reinforced by Figure 9 which shows the downstream performance of models initialized with language model weights against three randomly-initialized models of each size. Across all model sizes, the performance of models initialized with language model weights either overlaps with or slightly underperforms compared to randomly initialized models. These results suggest that LLM initialization offers relatively little advantage in the context of time series forecasting, and instead random initialization may be the preferable choice.


TSMixup augmentations.
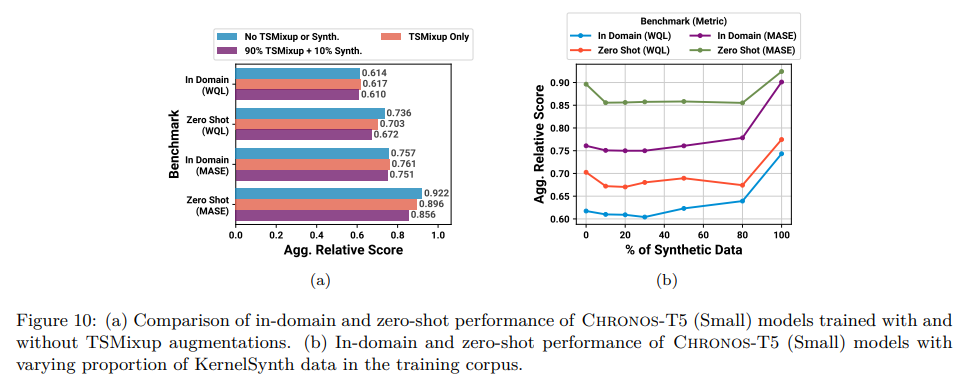
As described in Section 5.2, we trained Chronos models on TSMixup augmentations rather than directly on the original time series. In this experiment, we investigate whether using TSMixup augmentations is advantageous for downstream performance. Figure 10a compares the performance of Chronos-T5 (Small, 46M) models trained with and without TSMixup augmentations. The model trained on TSMixup augmentations obtains similar in-domain performance to the model trained without augmentations. However, the zero-shot performance improves when using TSMixup augmentations. This suggests that TSMixup enchances the diversity of training data which leads to improved performance on unseen datasets. Figure 10a also shows that the zero-shot performance obtains an additional boost with the inclusion of synthetic data. We investigate this further in the next experiment.
Synthetic data proportion.
We systematically explored the impact of KernelSynth on downstream model performance. We trained Chronos-T5 (Small, 46M) models with time series sampled from TSMixup augmentations and KernelSynth data in different ratios, ranging from 0% (i.e., trained solely on TSMixup augmentations) to 100% synthetic data.
Figure 10b shows the performance of models trained with different proportions of synthetic data. Both in-domain and zero-shot metrics improve with the incorporation of synthetic data in training. The most consistent improvement is observed around the 10% synthetic data proportion. Further increasing the proportion of synthetic data tends to worsen performance. This is unsurprising since the synthetic data generated using Gaussian processes is not representative of all real-world time series.
While the model trained only on synthetic data performs worse relative to models with real data in their training corpus, it performs reasonably well in terms of its absolute performance. Figure 20 (Appendix E) shows that it performs significantly better than ForecastPFN (Dooley et al., 2023), another model that is trained solely on synthetic data (generated differently from KernelSynth). Surprisingly, it also outperforms several other baselines in our benchmarks,6 despite never having seen real data during training. These results attest the quality of our synthetic data, and they open up directions for future work to close the performance gap further.
Training steps.
We trained a Chronos-T5 (Small, 46M) for 1M training steps to study the effect of longer training on model performance. Figure 11a shows that the downstream model performance improves over the course of training, both on in-domain and zero-shot benchmarks. This suggests that performance of the larger models (Base and Large) can potentially be improved by training them for longer.
Context length.
We studied the effect of the context length on downstream performance by training Chronos-T5 (Small, 46M) models with four distinct context lengths. Figure 11b shows how the performance varies with increasing context length. We observe improvements on both in-domain and zero-shot metrics as context length increases, showing that a longer context helps the models to forecast better. However, this analysis may be limited due to our zero-shot evaluation setup, wherein the majority of datasets in the benchmark have low frequencies and time series shorter than 1000 steps. Hence, further evaluation is required to conclusively study the impact of longer context lengths. We posit that high-frequency datasets may benefit from a longer context, which may be necessary to correctly capture the long-term seasonal patterns.
Vocabulary size.
The vocabulary size governs the precision with which the model can process the scaled time series. To explore its impact on performance, we trained Chronos-T5 (Small, 46M) models with varying vocabulary sizes. Figure 11c shows consistent improvements in the point forecasting metric (MASE) as the vocabulary size increases. In contrast, the WQL initially improves but deteriorates for larger vocabulary sizes. We hypothesize that this behavior is an artifact of the chosen metrics. The MASE, which is invariant to the scale of individual series, is closely aligned to our training loss, which is also invariant to scale. Hence, MASE exhibits an improvement with increased precision, just as one expects for the training loss. Conversely, WQL, a scale-dependent metric, does not correlate closely with the training loss and behaves less predictably as precision increases. See Appendix D for a discussion on the properties of these metrics.

5.7. Qualitative Analysis and Limitations
In this section, we analyze forecasts generated by Chronos models qualitatively, and we also highlight some limitations of our tokenization technique. We primarily focus on synthetically generated time series for a controlled analysis of different types of time series patterns. For example forecasts from real datasets, see Figures 22 to 24 in Appendix E.


I.I.D. Noise.
We generated time series comprised purely of Gaussian observations, N (0, 1) and N (100, 10), and used Chronos-T5 (Base) to forecast these. Figure 12a shows that Chronos generates plausible forecasts for such time series and the predicted 80% interval coincides with the ground truth 80% interval shown by the dashed blue lines.
Trend and seasonality.
We generated time series following linear and exponential trends: Chronos-T5 (Base) predicts the linear trend accurately but struggles with the exponential trend, as shown in Figure 12b. This may be due to a limited representation of exponential trends in the training data. A potential resolution for generating better forecasts for time series with exponential trends is to perform logarithmic scaling before feeding the time series into Chronos models. We also observed that Chronos models tend to underestimate the trend when the context is not sufficiently long. This phenomenon is depicted in Figure 13 where the model forecasts the pattern correctly but underpredicts the trend when a short context is provided. However, with a longer context, the model picks up the correct pattern and trend. In our analysis, we observed that Chronos models recognize seasonal patterns in time series particularly well. We generated purely seasonal time series using sinusoids with different frequencies. As shown in Figure 12c, Chronos-T5 (Base) precisely forecasts both time series. When fundamental patterns such as trend and seasonality are combined, either additively or multiplicatively, Chronos forecasts them accurately. This is demonstrated in Figure 12d on time series generated via addition and multiplication of a linear function with a sinusoid.
Autoregressive processes.
An autoregressive (AR) process of order p is defined as

where εt ∼ N (0, 1) and φ1, . . . , φp are the parameters of the model. We generated time series from stationary AR processes of different orders ranging from 1 to 4, and we compared the forecasts generated by ChronosT5 (Base) against those generated by three models: (a) the ground truth AR model that was used to generate the time series; (b) an AR model with the correct order (p) fitted to the time series; and (c) an AutoARIMA model fitted to the time series. Figure 14 shows the results for the AR(1) and AR(4) processes, and Figure 21 (Appendix E) shows the results for AR(2) and AR(3). We observe that Chronos-T5 (Base) generates plausible forecasts across all four AR processes. The simpler AR(1) and AR(2) processes are easier for the correctly-specified AR model and AutoARIMA model to fit, resulting in a better MSE than Chronos-T5 (Base). However, with increasing complexity in AR(3) and AR(4) processes, Chronos-T5 (Base) not only outperforms the AutoARIMA model (which belongs the same family as the ground truth model) but also performs slightly better than the fitted AR model with correct order. These results highlight that Chronos models can recognize fundamental patterns present in time series data.

Flexible predictive distributions.
Using a categorical distribution to encode predictions gives Chronos flexibility in producing predictive distributions of different shapes. This is shown in Figure 15, illustrating kernel density estimate (KDE) plots of token IDs sampled from a Chronos model, for the first five time steps in the forecast horizon, across three datasets. Despite the fact that cross-entropy is not distanceaware, Chronos outputs predictive distributions over a contiguous set of tokens, and with different shapes, including multi-modal ones.

Overflow and loss of precision.
One limitation of Chronos comes from the proposed tokenization approach (see Section 3.1). Specifically, the tokens we select represent values in the range [−15s, 15s], where s is the scale of the data (mean absolute value). If s is very small compared to the range of values in the series, then some observations will fall out of the representable range. An example of this behaviour is with sparse series, and as shown in Figure 16a. On the other hand, very large values of s compared to the variance result in loss of precision: in the original space, tokens are spaced 30s/(B − 1) from each other, where B is the number of bins (we used B = 4094 in our experiments); values closer than that to each other may be mapped to the same token, with an apparent loss of precision. An example of this behaviour is given in Figure 16b. Improving the tokenization to overcome these edge cases is subject for future work, but the results from Section 5.5 suggest that the Chronos models performs well on real-world data despite the limitations.

6. Discussion
Chronos represents one of the first endeavours in practical pretrained time series forecasting models, with remarkable zero-shot performance on a comprehensive collection of test datasets. This work opens up various research avenues, some of which we discuss below.
6.1. Beyond Zero-shot Univariate Forecasting
In our experiments, we evaluated Chronos in a zero-shot manner for most datasets. Such a setup highlights the competitiveness of zero-shot Chronos models against task-specific baselines. We expect that both in-domain and zero-shot results could be enhanced further through fine-tuning, an avenue we briefly explored in Section 5.5.2. This can be done using any parameter-efficient fine-tuning methods such as those based on low-rank adapters (LoRA) (Hu et al., 2021; Zhang et al., 2023). Alternatively, Chronos can be calibrated for a specific task with conformal methods (Romano et al., 2019; Stankeviciute et al., 2021; Xu & Xie, 2021). Chronos is especially attractive in the context of conformal prediction since it requires no training set, so all available data can be used for calibration.
In this work, we have focused on univariate time series forecasting since it constitutes the most common of real-world time series use-cases. Nevertheless, practical forecasting tasks often involve additional information that must be taken into account. One example involves covariates, that can be either time-independent (e.g., color of the product) or time-varying (e.g., on which days the product is on sale). Another closely related problem is multivariate forecasting, where historic values of one time series (e.g., interest rates) can influence the forecast for another time series (e.g., housing prices). The number of covariates or multivariate dimensions can vary greatly across tasks, which makes it challenging to train a single model that can handle all possible combinations. A possible solution may involve training task-specific adaptors that inject the covariates into the pretrained forecasting model (Rahman et al., 2020). As another option, we can build stacking ensembles (Ting & Witten, 1997) of Chronos and other light-weight models that excel at handling covariates such as LightGBM (Ke et al., 2017).
Thus far, our exploration has centered on the problem of time series forecasting. However, several other time series analysis tasks, such as classification, clustering, and anomaly detection (Dau et al., 2018; Wu & Keogh, 2021; Ismail Fawaz et al., 2019; Goswami et al., 2024), could potentially benefit from a pretrained model like Chronos. We hypothesize that the representations learned by the encoders of Chronos-T5 models are universal and can be used for these tasks. An exploration of Chronos-T5 representations for various downstream tasks would constitute interesting future work.
6.2. Inference
A potential limitation of the larger Chronos models is their inference speed compared to task-specific deep learning models. Figure 17 illustrates the inference time of generating forecasts for a single time series, averaged across datasets. The inference speed of the larger Chronos models is comparable to some statistical local models. Moreover, while Chronos models are slower than task-specific models, they are not too large to be prohibitively slow. Furthermore, task-specific models need to be trained for each task individually, which requires additional time and compute. In contrast, Chronos models can be deployed for datasets with diverse history lengths, frequencies, prediction horizons, and context lengths. This makes model deployment significantly easier and drastically simplifies forecasting pipelines, obviating the need for task-specific training.
By leveraging a language modeling framework for time series, we make developments in the NLP community immediately transferable to Chronos models. For instance, inference speed can be improved by using CUDA kernels optimized for modern Ampere GPUs, quantization (Dettmers et al., 2022), and faster decoding techniques, including speculative (Leviathan et al., 2023) and lookahead (Fu et al., 2023) decoding. Developments in long-context language models (Sun et al., 2022; Dao, 2023) may help improve Chronos models’ applicability to high-frequency datasets that require longer contexts to capture seasonal patterns. Other techniques popularly used for text language models, such as temperature tuning, beam search (Freitag & Al-Onaizan, 2017), Top-K sampling (Fan et al., 2018), nucleus sampling (Holtzman et al., 2019), could enhance the quality of forecasts. These may particularly be helpful in improving the speed and quality of point forecasts, which currently require aggregation over multiple samples.

6.3. Data
Our findings underscore that training larger models on a large corpus of time series data yields excellent in-domain and zero-shot performance. Nevertheless, in contrast to NLP, high-quality public time series data remains limited. This poses a dilemma when training models on a large corpus of diverse datasets — selecting more datasets for training leaves fewer for zero-shot evaluation. The time series community would benefit greatly from the availability of larger time series datasets that could be used to develop and improve pretrained model such as Chronos. There have been some recent efforts on building large-scale time series datasets for specific domains (Emami et al., 2023; Liu et al., 2023) and cross-domain (Borchert et al., 2022), albeit further investment is needed.
Another direction to address the problem of limited data involves developing better methods for generating synthetic time series. Our work has made significant strides in this direction by clearly demonstrating the utility of synthetic data generated using Gaussian processes, improving model performance when incorporated into the training data. Even models trained solely on synthetic data exhibit reasonable forecasting performance. Future research could delve into the failure modes of these models, proposing enhancements to bridge the gap between real and synthetic data.
7. Conclusion
In this work, we approach the problem of developing generalist pretrained forecasting models from the lens of a minimalist. We adapt existing language model architectures and training procedures for time series forecasting, challenging the notion that time-series-specific features or architectures are necessary for forecasting. This results in Chronos, a language modeling framework for time series that is, paradoxically, agnostic to time. The defining characteristic of Chronos is its compatibility with any language model architecture, only requiring minimal modifications — tokenization though scaling and quantization. Our pretrained models significantly outperform existing local models and task-specific deep learning baselines in terms of their in-domain performance. More remarkably, Chronos models obtain excellent results on unseen datasets (zero-shot performance), performing competitively with the best deep-learning baselines trained on these datasets, while showing promising evidence of further improvements through fine-tuning.
Our contributions are significant in two key aspects. First, we show that existing language model architectures are capable of performing forecasting without time-series-specific customizations. This paves the way for accelerated progress by leveraging developments in the area of LLMs and through better data strategies. Second, on a practical level, the strong performance of Chronos models suggests that large (by forecasting standards) pretrained language models can greatly simplify forecasting pipelines without sacrificing accuracy, offering an inference-only alternative to the conventional approach involving training and tuning a model on individual tasks.
'*Paper Writing 1 > Related_Work' 카테고리의 다른 글