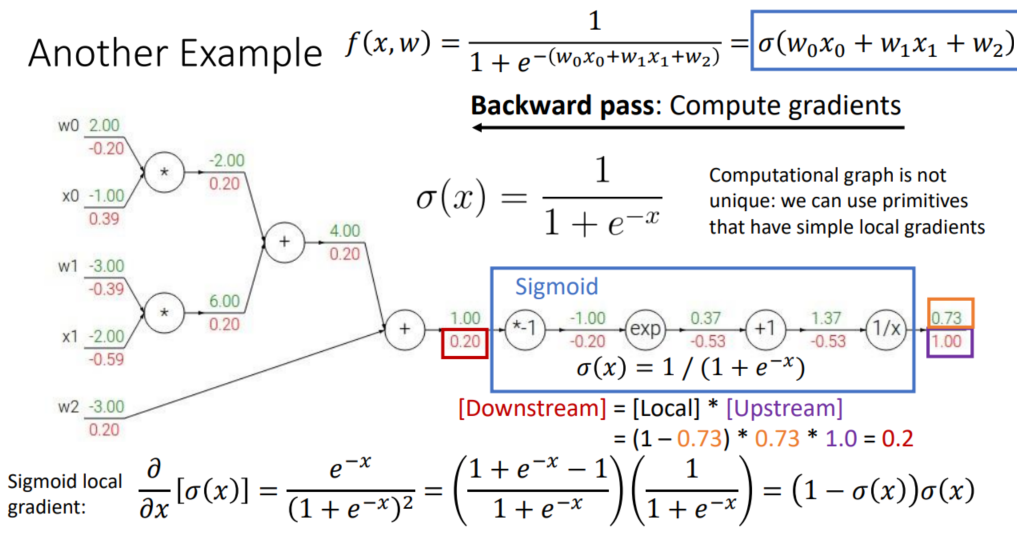
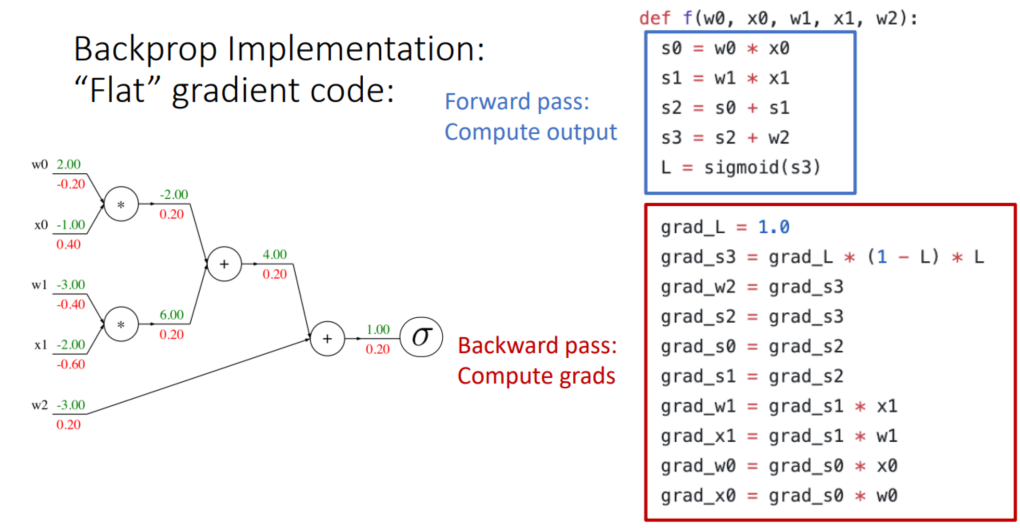
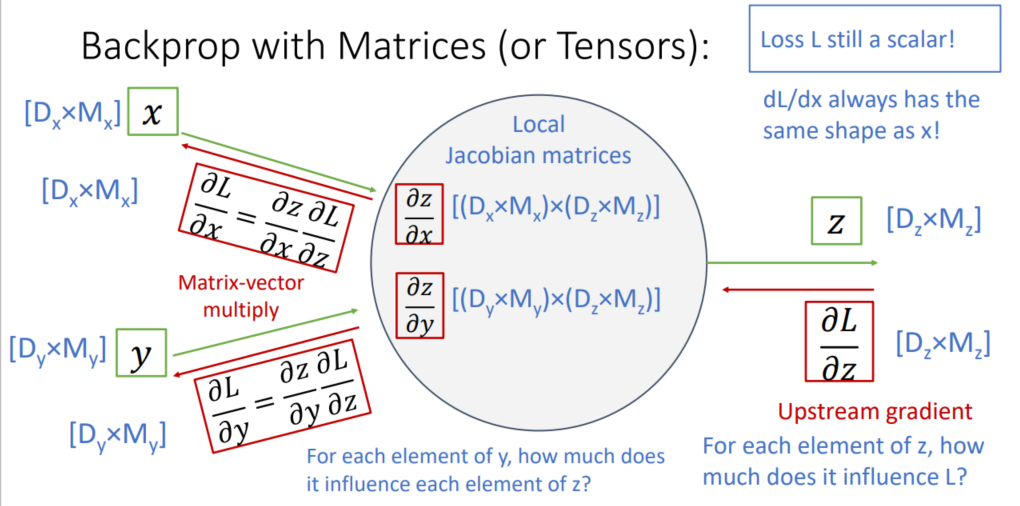
-
Cheat sheet for examCampus Life 2025. 4. 19. 07:22
이 아이들을 A4 1장에 어떻게 잘 우겨 넣을 것인가.. 돋보기 챙겨가야 하는 거 아냐..? -_-









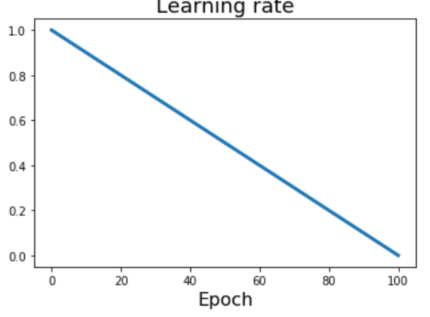
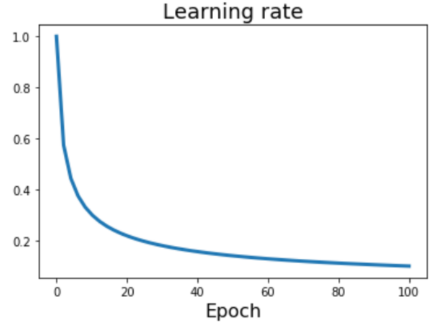
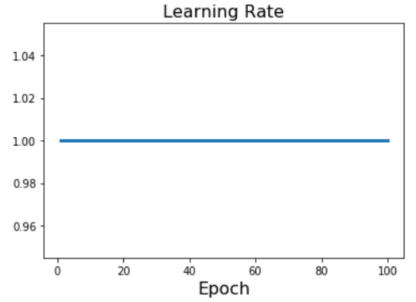




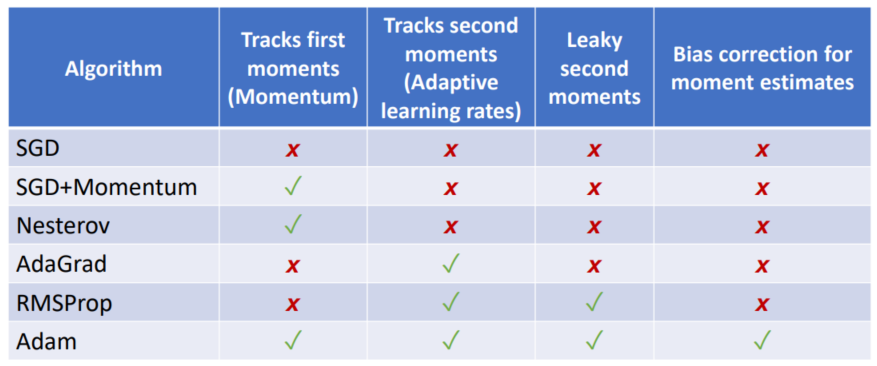




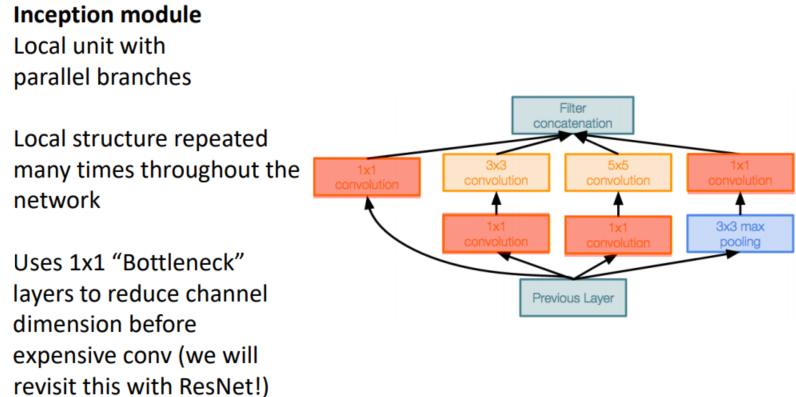
* Linear classifier: One template per class
* Neural net: first layer is bank of templates; Second layer recombines templates
- Can use different templates to cover multiple modes of a class!- “Distributed representation”: Most templates not interpretable!



First-layer conv filters: local image templates (Often learns oriented edges, opposing colors)
For convolution with kernel size K, each element in the output depends on a K x K receptive field in the input
Each successive convolution adds K – 1 to the receptive field size. With L layers the receptive field size is 1 + L * (K – 1)
Input volume: 3 x 32 x 32
10 5x5 filters with stride 1, pad 2
Output volume size: 10 x 32 x 32
Number of learnable parameters: 760
Number of multiply-add operations: 768,000
10*32*32 = 10,240 outputs; each output is the inner product
of two 3x5x5 tensors (75 elems); total = 75*10240 = 768K






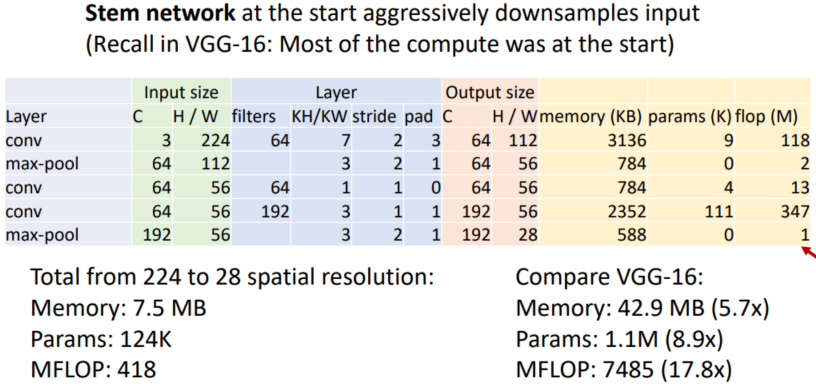
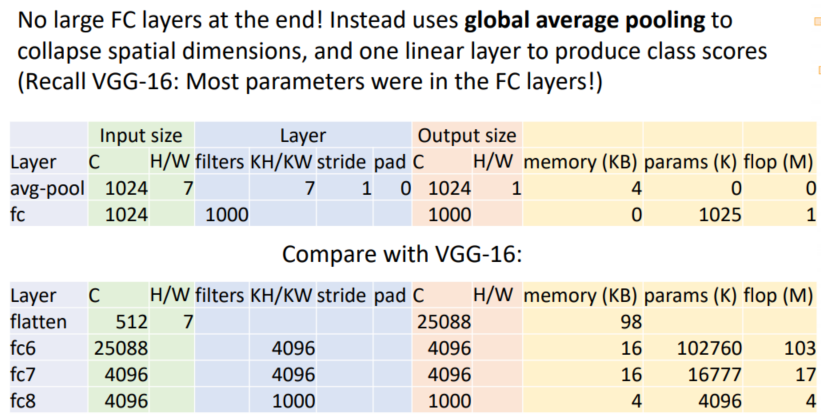
Most of the memory usage is in the early convolution layers
Nearly all parameters are in the fully-connected layers
Most floating-point ops occur in the convolution layers

























'Campus Life' 카테고리의 다른 글
과한 욕심은 화를 부른다 (0) 2025.04.20 질문 잘 하는 귀여운 친구들 (0) 2025.04.19 희망고문 (0) 2025.04.15 assignment 3 completed (0) 2025.04.05 진짜 멘붕이다 (0) 2025.04.04