-
[VQ-VAE] Neural Discrete Representation LearningResearch/Generative Model 2024. 4. 7. 15:13
※ https://arxiv.org/pdf/1711.00937.pdf
Abstract
Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static.
In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of “posterior collapse” -— where the latents are ignored when they are paired with a powerful autoregressive decoder -— typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.
1. Introduction
Recent advances in generative modelling of images [38, 12, 13, 22, 10], audio [37, 26] and videos [20, 11] have yielded impressive samples and applications [24, 18]. At the same time, challenging tasks such as few-shot learning [34], domain adaptation [17], or reinforcement learning [35] heavily rely on learnt representations from raw data, but the usefulness of generic representations trained in an unsupervised fashion is still far from being the dominant approach.
Maximum likelihood and reconstruction error are two common objectives used to train unsupervised models in the pixel domain, however their usefulness depends on the particular application the features are used in. Our goal is to achieve a model that conserves the important features of the data in its latent space while optimising for maximum likelihood. As the work in [7] suggests, the best generative models (as measured by log-likelihood) will be those without latents but a powerful decoder (such as PixelCNN). However, in this paper, we argue for learning discrete and useful latent variables, which we demonstrate on a variety of domains.
Learning representations with continuous features have been the focus of many previous work [16, 39, 6, 9] however we concentrate on discrete representations [27, 33, 8, 28] which are potentially a more natural fit for many of the modalities we are interested in. Language is inherently discrete, similarly speech is typically represented as a sequence of symbols. Images can often be described concisely by language [40]. Furthermore, discrete representations are a natural fit for complex reasoning, planning and predictive learning (e.g., if it rains, I will use an umbrella). While using discrete latent variables in deep learning has proven challenging, powerful autoregressive models have been developed for modelling distributions over discrete variables [37].
In our work, we introduce a new family of generative models succesfully combining the variational autoencoder (VAE) framework with discrete latent representations through a novel parameterisation of the posterior distribution of (discrete) latents given an observation. Our model, which relies on vector quantization (VQ), is simple to train, does not suffer from large variance, and avoids the “posterior collapse” issue which has been problematic with many VAE models that have a powerful decoder, often caused by latents being ignored. Additionally, it is the first discrete latent VAE model that get similar performance as its continuous counterparts, while offering the flexibility of discrete distributions. We term our model the VQ-VAE.
Since VQ-VAE can make effective use of the latent space, it can successfully model important features that usually span many dimensions in data space (for example objects span many pixels in images, phonemes in speech, the message in a text fragment, etc.) as opposed to focusing or spending capacity on noise and imperceptible details which are often local.
Lastly, once a good discrete latent structure of a modality is discovered by the VQ-VAE, we train a powerful prior over these discrete random variables, yielding interesting samples and useful applications. For instance, when trained on speech we discover the latent structure of language without any supervision or prior knowledge about phonemes or words. Furthermore, we can equip our decoder with the speaker identity, which allows for speaker conversion, i.e., transferring the voice from one speaker to another without changing the contents. We also show promising results on learning long term structure of environments for RL.
Our contributions can thus be summarised as:
- Introducing the VQ-VAE model, which is simple, uses discrete latent, does not suffer from "posterior collapse" and has no variance issues.
- We show that a discrete latent model (VQ-VAE) perform as well as its continuous model counterparts in log-likelihood.
- When paired with a powerful prior, our samples are coherent and high quality on a wide variety of applications such as speech and video generation.
- We show evidence of learning language through raw speech, without any supervision, and show applications of unsupervised speaker conversion.
3. VQ-VAE
Perhaps the work most related to our approach are VAEs. VAEs consist of the following parts: an encoder network which parameterises a posterior distribution q(z|x) of discrete latent random variables z given the input data x, a prior distribution p(z), and a decoder with a distribution p(x|z) over input data.
Typically, the posteriors and priors in VAEs are assumed normally distributed with diagonal covariance, which allows for the Gaussian reparametrisation trick to be used [32, 23]. Extensions include autoregressive prior and posterior models [14], normalising flows [31, 10], and inverse autoregressive posteriors [22].
In this work we introduce the VQ-VAE where we use discrete latent variables with a new way of training, inspired by vector quantisation (VQ). The posterior and prior distributions are categorical, and the samples drawn from these distributions index an embedding table. These embeddings are then used as input into the decoder network.
3.1 Discrete Latent variables

We define a latent embedding space e ∈ R^K×D where K is the size of the discrete latent space (i.e., a K-way categorical), and D is the dimensionality of each latent embedding vector ei . Note that there are K embedding vectors ei ∈ R^D, i ∈ 1, 2, ..., K.
As shown in Figure 1, the model takes an input x, that is passed through an encoder producing output z_e(x). The discrete latent variables z are then calculated by a nearest neighbour look-up using the shared embedding space e as shown in equation 1. The input to the decoder is the corresponding embedding vector ek as given in equation 2.
One can see this forward computation pipeline as a regular autoencoder with a particular non-linearity that maps the latents to 1-of-K embedding vectors. The complete set of parameters for the model are union of parameters of the encoder, decoder, and the embedding space e.
For sake of simplicity we use a single random variable z to represent the discrete latent variables in this Section, however for speech, image and videos we actually extract a 1D, 2D and 3D latent feature spaces respectively.
The posterior categorical distribution q(z|x) probabilities are defined as one-hot as follows:

where z_e(x) is the output of the encoder network. We view this model as a VAE in which we can bound log p(x) with the ELBO. Our proposal distribution q(z = k|x) is deterministic, and by defining a simple uniform prior over z we obtain a KL divergence constant and equal to log K.
The representation z_e(x) is passed through the discretisation bottleneck followed by mapping onto the nearest element of embedding e as given in equations 1 and 2.

3.2 Learning
Note that there is no real gradient defined for equation 2, however we approximate the gradient similar to the straight-through estimator [3] and just copy gradients from decoder input z_q(x) to encoder output z_e(x). One could also use the subgradient through the quantisation operation, but this simple estimator worked well for the initial experiments in this paper.
During forward computation the nearest embedding z_q(x) (equation 2) is passed to the decoder, and during the backwards pass the gradient ∇zL is passed unaltered to the encoder. Since the output representation of the encoder and the input to the decoder share the same D dimensional space, the gradients contain useful information for how the encoder has to change its output to lower the reconstruction loss.

As seen on Figure 1 (right), the gradient can push the encoder’s output to be discretised differently in the next forward pass, because the assignment in equation 1 will be different.
Equation 3 specifies the overall loss function. It is has three components that are used to train different parts of VQ-VAE. The first term is the reconstruction loss (or the data term) which optimizes the decoder and the encoder (through the estimator explained above). Due to the straight-through gradient estimation of mapping from z_e(x) to z_q(x), the embeddings ei receive no gradients from the reconstruction loss log p(x|z_q(x)). Therefore, in order to learn the embedding space, we use one of the simplest dictionary learning algorithms, Vector Quantisation (VQ). The VQ objective uses the l2 error to move the embedding vectors ei towards the encoder outputs z_e(x) as shown in the second term of equation 3. Because this loss term is only used for updating the dictionary, one can alternatively also update the dictionary items as function of moving averages of z_e(x) (not used for the experiments in this work, Appendix A.1.).
Finally, since the volume of the embedding space is dimensionless, it can grow arbitrarily if the embeddings ei do not train as fast as the encoder parameters. To make sure the encoder commits to an embedding and its output does not grow, we add a commitment loss, the third term in equation 3. Thus, the total training objective becomes:

where sg stands for the stopgradient operator that is defined as identity at forward computation time and has zero partial derivatives, thus effectively constraining its operand to be a non-updated constant. The decoder optimises the first loss term only, the encoder optimises the first and the last loss terms, and the embeddings are optimised by the middle loss term. We found the resulting algorithm to be quite robust to β, as the results did not vary for values of β ranging from 0.1 to 2.0. We use β = 0.25 in all our experiments, although in general this would depend on the scale of reconstruction loss. Since we assume a uniform prior for z, the KL term that usually appears in the ELBO is constant w.r.t. the encoder parameters and can thus be ignored for training.
In our experiments we define N discrete latents (e.g., we use a field of 32 x 32 latents for ImageNet, or 8 x 8 x 10 for CIFAR10). The resulting loss L is identical, except that we get an average over N terms for k-means and commitment loss – one for each latent.
The log-likelihood of the complete model log p(x) can be evaluated as follows:
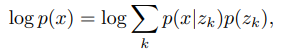
Because the decoder p(x|z) is trained with z = z_q(x) from MAP-inference, the decoder should not allocate any probability mass to p(x|z) for z ≠ z_q(x) once it has fully converged. Thus, we can write

We empirically evaluate this approximation in section 4. From Jensen’s inequality, we also can write

3.3 Prior
The prior distribution over the discrete latents p(z) is a categorical distribution, and can be made autoregressive by depending on other z in the feature map. Whilst training the VQ-VAE, the prior is kept constant and uniform. After training, we fit an autoregressive distribution over z, p(z), so that we can generate x via ancestral sampling. We use a PixelCNN over the discrete latents for images, and a WaveNet for raw audio. Training the prior and the VQ-VAE jointly, which could strengthen our results, is left as future research.
4. Experiments
4.1 Comparison with continuous variables
As a first experiment we compare VQ-VAE with normal VAEs (with continuous variables), as well as VIMCO [28] with independent Gaussian or categorical priors. We train these models using the same standard VAE architecture on CIFAR10, while varying the latent capacity (number of continuous or discrete latent variables, as well as the dimensionality of the discrete space K). The encoder consists of 2 strided convolutional layers with stride 2 and window size 4 × 4, followed by two residual 3 × 3 blocks (implemented as ReLU, 3x3 conv, ReLU, 1x1 conv), all having 256 hidden units. The decoder similarly has two residual 3 × 3 blocks, followed by two transposed convolutions with stride 2 and window size 4 × 4. We use the ADAM optimiser [21] with learning rate 2e-4 and evaluate the performance after 250,000 steps with batch-size 128. For VIMCO we use 50 samples in the multi-sample training objective.
The VAE, VQ-VAE and VIMCO models obtain 4.51 bits/dim, 4.67 bits/dim and 5.14 respectively. All reported likelihoods are lower bounds. Our numbers for the continuous VAE are comparable to those reported for a Deep convolutional VAE: 4.54 bits/dim [13] on this dataset.
Our model is the first among those using discrete latent variables which challenges the performance of continuous VAEs. Thus, we get very good reconstructions like regular VAEs provide, with the compressed representation that symbolic representations provide. A few interesting characteristics, implications and applications of the VQ-VAEs that we train is shown in the next subsections.
4.2 Images
Images contain a lot of redundant information as most of the pixels are correlated and noisy, therefore learning models at the pixel level could be wasteful.
In this experiment we show that we can model x = 128×128×3 images by compressing them to a z = 32×32×1 discrete space (with K=512) via a purely deconvolutional p(x|z). So a reduction of (128×128×3×8) / (32×32×9) ≈ 42.6 in bits. We model images by learning a powerful prior (PixelCNN) over z. This allows to not only greatly speed up training and sampling, but also to use the PixelCNNs capacity to capture the global structure instead of the low-level statistics of images.

Reconstructions from the 32x32x1 space with discrete latents are shown in Figure 2. Even considering that we greatly reduce the dimensionality with discrete encoding, the reconstructions look only slightly blurrier than the originals. It would be possible to use a more perceptual loss function than MSE over pixels here (e.g., a GAN [12]), but we leave that as future work.
Next, we train a PixelCNN prior on the discretised 32x32x1 latent space. As we only have 1 channel (not 3 as with colours), we only have to use spatial masking in the PixelCNN. The capacity of the PixelCNN we used was similar to those used by the authors of the PixelCNN paper [38].

Samples drawn from the PixelCNN were mapped to pixel-space with the decoder of the VQ-VAE and can be seen in Figure 3.

We also repeat the same experiment for 84x84x3 frames drawn from the DeepMind Lab environment [2]. The reconstructions looked nearly identical to their originals. Samples drawn from the PixelCNN prior trained on the 21x21x1 latent space and decoded to the pixel space using a deconvolutional model decoder can be seen in Figure 4.

Finally, we train a second VQ-VAE with a PixelCNN decoder on top of the 21x21x1 latent space from the first VQ-VAE on DM-LAB frames. This setup typically breaks VAEs as they suffer from "posterior collapse", i.e., the latents are ignored as the decoder is powerful enough to model x perfectly. Our model however does not suffer from this, and the latents are meaningfully used. We use only three latent variables (each with K=512 and their own embedding space e) at the second stage for modelling the whole image and as such the model cannot reconstruct the image perfectly – which is consequence of compressing the image onto 3 x 9 bits, i.e. less than a float32. Reconstructions sampled from the discretised global code can be seen in Figure 5.
5. Conclusion
In this work we have introduced VQ-VAE, a new family of models that combine VAEs with vector quantisation to obtain a discrete latent representation. We have shown that VQ-VAEs are capable of modelling very long term dependencies through their compressed discrete latent space which we have demonstrated by generating 128 × 128 colour images, sampling action conditional video sequences and finally using audio where even an unconditional model can generate surprisingly meaningful chunks of speech and doing speaker conversion. All these experiments demonstrated that the discrete latent space learnt by VQ-VAEs capture important features of the data in a completely unsupervised manner. Moreover, VQ-VAEs achieve likelihoods that are almost as good as their continuous latent variable counterparts on CIFAR10 data. We believe that this is the first discrete latent variable model that can successfully model long range sequences and fully unsupervisedly learn high-level speech descriptors that are closely related to phonemes.
VQ-VAE dictionary updates with Exponential Moving Averages

'Research > Generative Model' 카테고리의 다른 글
[SA-VAE] Semi-Amortized Variational Autoencoders (0) 2024.04.08 [IWAE] Importance Weighted Autoencoders (0) 2024.04.07 Lagging Inference Networks and Posterior Collapse in Variational Autoencoders (0) 2024.04.06 [HFVAE] Structured Disentangled Representations (0) 2024.04.05 [Factor VAE] Disentangling by Factorising (0) 2024.04.05