-
Lagging Inference Networks and Posterior Collapse in Variational Autoencoders*Generative Model/Generative Model 2024. 4. 6. 10:26
※ https://arxiv.org/pdf/1901.05534.pdf
Abstract
The variational autoencoder (VAE) is a popular combination of deep latent variable model and accompanying variational learning technique. By using a neural inference network to approximate the model’s posterior on latent variables, VAEs efficiently parameterize a lower bound on marginal data likelihood that can be optimized directly via gradient methods. In practice, however, VAE training often results in a degenerate local optimum known as “posterior collapse” where the model learns to ignore the latent variable and the approximate posterior mimics the prior. In this paper, we investigate posterior collapse from the perspective of training dynamics. We find that during the initial stages of training the inference network fails to approximate the model’s true posterior, which is a moving target. As a result, the model is encouraged to ignore the latent encoding and posterior collapse occurs. Based on this observation, we propose an extremely simple modification to VAE training to reduce inference lag: depending on the model’s current mutual information between latent variable and observation, we aggressively optimize the inference network before performing each model update. Despite introducing neither new model components nor significant complexity over basic VAE, our approach is able to avoid the problem of collapse that has plagued a large amount of previous work. Empirically, our approach outperforms strong autoregressive baselines on text and image benchmarks in terms of held-out likelihood, and is competitive with more complex techniques for avoiding collapse while being substantially faster.
1. Introduction

Variational autoencoders (VAEs) (Kingma & Welling, 2014) represent a popular combination of a deep latent variable model (shown in Figure 1(a)) and an accompanying variational learning technique. The generative model in VAE defines a marginal distribution on observations, x ∈ X , as:

The model’s generator defines pθ(x|z) and is typically parameterized as a complex neural network. Standard training involves optimizing an evidence lower bound (ELBO) on the intractable marginal data likelihood (Eq.1), where an auxiliary variational distribution qφ(z|x) is introduced to approximate the model posterior distribution pθ(z|x). VAEs make this learning procedure highly scalable to large datasets by sharing parameters in the inference network to amortize inferential cost. This amortized approach contrasts with traditional variational techniques that have separate local variational parameters for every data point (Blei et al., 2003; Hoffman et al., 2013).
While successful on some datasets, prior work has found that VAE training often suffers from “posterior collapse”, in which the model ignores the latent variable z (Bowman et al., 2016; Kingma et al., 2016; Chen et al., 2017). This phenomenon is more common when the generator pθ(x|z) is parametrized with a strong autoregressive neural network, for example, an LSTM (Hochreiter & Schmidhuber, 1997) on text or a PixelCNN (van den Oord et al., 2016) on images.(<= 왜 autoregressive nn에서 posterior collapse가 더 잘 발생할까?)
Posterior collapse is especially evident when modeling discrete data, (<= 왜 discrete data에서 posterior collapse가 더 잘 발생할까?) which hinders the usage of VAEs in important applications like natural language processing. Existing work analyzes this problem from a static optimization perspective, noting that the collapsed solution is often a reasonably good local optimum in terms of ELBO (Chen et al., 2017; Zhao et al., 2017; Alemi et al., 2018). Thus, many proposed solutions to posterior collapse focus on weakening the generator by replacing it with a non-recurrent alternative (Yang et al., 2017; Semeniuta et al., 2017) or modifying the training objective (Zhao et al., 2017; Tolstikhin et al., 2018). In this paper, we analyze the problem from the perspective of training dynamics and propose a novel training procedure for VAEs that addresses posterior collapse. In contrast with other solutions, our proposed procedure optimizes the standard ELBO objective and does not require modification to the VAE model or its parameterization.
Recently, Kim et al. (2018) proposed a new approach to training VAEs by composing the standard inference network with additional mean-field updates. The resulting semi-amortized approach empirically avoided collapse and obtained better ELBO. However, because of the costly instancespecific local inference steps, the new method is more than 10x slower than basic VAE training in practice. It is also unclear why the basic VAE method fails to find better local optima that make use of latents. We consider two questions in this paper: (1) Why does basic VAE training often fall into undesirable collapsed local optima? (2) Is there a simpler way to change the training trajectory to find a non-trivial local optimum?
To this end, we first study the posterior collapse problem from the perspective of training dynamics. We find, empirically, that the posterior approximation often lags far behind the true model posterior in the initial stages of training (Section 3). We then demonstrate how such lagging behavior can drive the generative model towards a collapsed local optimum, and propose a novel training procedure for VAEs that aggressively optimizes the inference network with more updates to mitigate lag (Section 4). Without introducing new modeling components over basic VAEs or additional complexity, our approach is surprisingly simple yet effective in circumventing posterior collapse. As a density estimator, it outperforms neural autoregressive baselines on both text (Yahoo and Yelp) and image (OMNIGLOT) benchmarks, leading to comparable performance with more complicated previous state-of-the-art methods at a fraction of the training cost (Section 6).
2. Background
2.1 Variational Autoencoders
VAEs learn deep generative models defined by a prior p(z) and a conditional distribution pθ(x|z) as shown in Figure 1(a). In most cases the marginal data likelihood is intractable, so VAEs instead optimize a tractable variational lower bound (ELBO) of log pθ(x),

where qφ(z|x) is a variational distribution parameterized by an inference network with parameters φ, and pθ(x|z) denotes the generator network with parameters θ. qφ(z|x) is optimized to approximate the model posterior pθ(z|x). This lower bound is composed of a reconstruction loss term that encourages the inference network to encode information necessary to generate the data and a KL regularizer to push qφ(z|x) towards the prior p(z). Below, we consider p(z) := N (0, I) unless otherwise specified. A key advantage of using inference networks (also called amortized inference) to train deep generative models over traditional locally stochastic variational inference (Hoffman et al., 2013) is that they share parameters over all data samples, amortizing computational cost and allowing for efficient training.
The term VAE is often used both to denote the class of generative models and the amortized inference procedure used in training. In this paper, it is important to distinguish the two and throughout we will refer to the generative model as the VAE model, and the training procedure as VAE training.
2.2 Posterior Collapse
Despite VAE’s appeal as a tool to learn unsupervised representations through the use of latent variables, as mentioned in the introduction, VAE models are often found to ignore latent variables when using flexible generators like LSTMs (Bowman et al., 2016). This problem of “posterior collapse” occurs when the training procedure falls into the trivial local optimum of the ELBO objective in which both the variational posterior and true model posterior collapse to the prior. This is undesirable because an important goal of VAEs is to learn meaningful latent features for inputs. Mathematically, posterior collapse represents a local optimum of VAEs where qφ(z|x) = pθ(z|x) = p(z) for all x. To facilitate our analysis about the causes leading up to collapse, we further define two partial collapse states: model collapse, when pθ(z|x) = p(z), and inference collapse, when qφ(z|x) = p(z) for all x. Note that in this paper we use these two terms to denote the posterior states in the middle of training instead of local optima at the end. These two partial collapse states may not necessarily happen at the same time, which we will discuss later.
2.3 Visualization of Posterior Distribution
Posterior collapse is closely related to the true model posterior pθ(z|x) and the approximate posterior qφ(z|x) as it is defined. Thus, in order to observe how posterior collapse happens, we track the state of pθ(z|x) and qφ(z|x) over the course of training, and analyze the training trajectory in terms of the posterior mean space
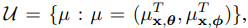
where µx,θ and µx,φ are the means of pθ(z|x) and qφ(z|x), respectively. (µx,θ can be approximated through discretization of the model posterior)
We can then roughly consider µx,θ = 0 as model collapse and µx,φ = 0 as inference collapse as we defined before. Each x will be projected to a point in this space under the current model and inference network parameters. If z is a scalar we can efficiently compute µx,θ and visualize the posterior mean space as shown in Figure 1(b). The diagonal line µx,θ = µx,φ represents parameter settings where qφ(z|x) is equal to pθ(z|x) in terms of mean, indicating a well-trained inference network. The collapsed local optimum is located at the origin, while the data points at a more desirable local optima may be distributed along the diagonal. In this paper we will utilize this posterior mean space multiple times to analyze the posterior dynamics.
3. A Lagging Inference Network Prevents Using Latent Codes
In this section we analyze posterior collapse from a perspective of training dynamics. We will answer the question of why the basic VAE training with strong decoders tends to hit a collapsed local optimum and provide intuition for the simple solution we propose in Section 4.
3.1 Intuitions from ELBO
Since posterior collapse is directly relevant to the approximate posterior qφ(z|x) and true model posterior pθ(z|x), we aim to analyze their training dynamics to study how posterior collapse happens. To this end, it is useful to analyze an alternate form of ELBO:

With this view, the only goal of approximate posterior qφ(z|x) is to match model posterior pθ(z|x), while the optimization of pθ(z|x) is influenced by two forces, one of which is the ideal objective marginal data likelihood, and the other is DKL(qφ(z|x)||pθ(z|x)), which drives pθ(z|x) towards qφ(z|x). Ideally if the approximate posterior is perfect, the second force will vanish, with ∇θDKL(qφ(z|x)|pθ(z|x)) = 0 when qφ(z|x) = pθ(z|x). At the start of training, z and x are nearly independent under both qφ(z|x) and pθ(z|x) as we show in Section 3.2, i.e. all x suffer from model collapse in the beginning. Then the only component in the training objective that possibly causes dependence between z and x under pθ(z|x) is log pθ(x). However, this pressure may be overwhelmed by the KL term when pθ(z|x) and qφ(z|x) start to diverge but z and x remain independent under qφ(z|x). We hypothesize that, in practice, training drives pθ(z|x) and qφ(z|x) to the prior in order to bring them into alignment, while locking into model parameters that capture the distribution of x while ignoring z. Critically, posterior collapse is a local optimum; once a set of parameters that achieves these goals are reached, gradient optimization fails to make further progress, even if better overall models that make use of z to describe x exist.
Next we visualize the posterior mean space by training a basic VAE with a scalar latent variable on a relatively simple synthetic dataset to examine our hypothesis.
3.2 Observations on synthetic data

As a synthetic dataset we use discrete sequence data since posterior collapse has been found the most severe in text modeling tasks. Details on this synthetic dataset and experiment are in Appendix B.1.
We train a basic VAE with a scalar latent variable, LSTM encoder, and LSTM decoder on our synthetic dataset. We sample 500 data points from the validation set and show them on the posterior mean space plots at four different training stages from initialization to convergence in Figure 2. The mean of the approximate posterior distribution µx,φ is from the output of the inference network, and µx,θ can be approximated by discretization of the true model posterior pθ(z|x) (see Appendix A).
As illustrated in Figure 2, all points are located at the origin upon initialization , which means z and x are almost independent in terms of both qφ(z|x) and pθ(z|x) at the beginning of training. In the second stage of basic VAE training, the points start to spread along the µx,θ axis. This phenomenon implies that for some data points pθ(z|x) moves far away from the prior p(z), and confirms that log pθ(x) is able to help move away from model collapse. However, all of these points are still distributed along a horizontal line, which suggests that qφ(z|x) fails to catch up to pθ(z|x) and these points are still in a state of inference collapse. As expected, the dependence between z and x under pθ(z|x) is gradually lost and finally the model converges to the collapsed local optimum.
4. Method
4.1 Aggressive training of the inference network
The problem reflected in Figure 2 implies that the inference network is lagging far behind pθ(z|x), and might suggest more “aggressive” inference network updates are needed. Instead of blaming the poor approximation on the limitation of the inference network’s amortization, we hypothesize that the optimization of the inference and generation networks are imbalanced, and propose to separate the optimization of the two. Specifically, we change the training procedure to:
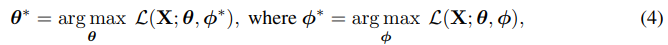
where optimizing the inference network qφ(z|x) is an inner loop in the entire training process as shown in Algorithm 1.

This training procedure shares the same spirit with traditional stochastic variational inference (SVI) (Hoffman et al., 2013) that performs iterative inference for each data point separately and suffers from very lengthy iterative estimation. Compared with recent work that try to combine amortized variational inference and SVI (Hjelm et al., 2016; Krishnan et al., 2018; Kim et al., 2018; Marino et al., 2018) where the inference network is learned to be a component to help perform instance-specific variational inference, our approach keeps variational inference fully amortized, allowing for reverting back to efficient basic VAE training as discussed in Section 4.2. Also, this aggressive inference network optimization algorithm is as simple as basic VAE training without introducing additional SVI steps, yet attains comparable performance to more sophisticated approaches as we will show in Section 6.
4.2 Stopping criterion
Always training with Eq.4 would be inefficient and neglects the benefit of the amortized inference network. Following our previous analysis, the term DKL(qφ(z|x)||pθ(z|x)) tends to pressure qφ(z|x) or pθ(z|x) to p(z) only if at least one of them is close to p(z), and thus we posit that if we can confirm that we haven’t reached this degenerate condition, we can continue with standard VAE training. Since qφ(z|x) is the one lagging behind, we use the mutual information Iq between z and x under qφ(z|x) to control our stopping criterion. In practice, we compute the mutual information on the validation set every epoch, and stop the aggressive updates when Iq stops climbing. In all our experiments in this paper we found that the aggressive algorithm usually reverts back to basic VAE training within 5 epochs. Mutual information, Iq can be computed by (Hoffman & Johnson, 2016):

where pd(x) is the empirical distribution. The aggregated posterior, qφ(z) = Ex∼pd(x) [qφ(z|x)], can be approximated with a Monte Carlo estimate. DKL(qφ(z)||p(z)) is also approximated by Monte Carlo, where samples from qφ(z) can be easily obtained by ancestral sampling (i.e. sample x from dataset and sample z ∼ qφ(z|x)). This estimator for Iq is the same as in (Dieng et al., 2018), which is biased because the estimation for DKL(qφ(z)||p(z)) is biased. More specifically, it is a Monte Carlo estimate of an upper bound of mutual information. The complete algorithm is shown in Algorithm 1.
4.3 Observations on synthetic dataset
By training the VAE model with our approach on synthetic data, we visualize the 500 data samples in the posterior mean space in Figure 2. From this, it is evident that the points move towards µx,θ = µx,φ and are roughly distributed along the diagonal in the end. This is in striking contrast to the basic VAE and confirms our hypothesis that the inference and generator optimization can be rebalanced by simply performing more updates of the inference network. In Figure 3 we show the training trajectory of one single data instance for the first several optimization iterations and observe how the aggressive updates help escape inference collapse.
7. Conclusion
In this paper we study the “posterior collapse” problem that variational autoencoders experience when the model is parameterized by a strong autoregressive neural network. In our synthetic experiment we identify that the problem lies with the lagging inference network in the initial stages of training. To remedy this, we propose a simple yet effective training algorithm that aggressively optimizes the inference network with more updates before reverting back to basic VAE training. Experiments on text and image modeling demonstrate the effectiveness of our approach.
A. Approximation of the mean of the true model posterior
We approximate the mean of true model posterior pθ(z|x) by discretization of the density distribution (Riemann integral):
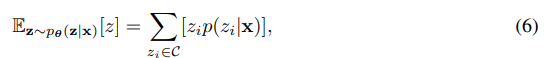
where C is a partition of an interval with small stride and sufficiently large coverage. We assume the density value outside this interval is zero. The model posterior, pθ(z|x), needs to be first approximated on this partition of interval. In practice, for the synthetic data we choose the interval [-20.0, 20.0] and stride equal to 0.01. This interval should have sufficient coverage since we found all samples from true model posterior pθ(z|x) lies within [-5.0, 5.0] by performing MH sampling.
'*Generative Model > Generative Model' 카테고리의 다른 글
[IWAE] Importance Weighted Autoencoders (0) 2024.04.07 [VQ-VAE] Neural Discrete Representation Learning (0) 2024.04.07 [HFVAE] Structured Disentangled Representations (0) 2024.04.05 [Factor VAE] Disentangling by Factorising (0) 2024.04.05 [Beta-VAE] Learning Basic Visual Concepts with a Constrained Variational Framework (0) 2024.04.04