-
[Beta-VAE] Learning Basic Visual Concepts with a Constrained Variational Framework*Generative Model/Generative Model 2024. 4. 4. 21:03
※ https://lilianweng.github.io/posts/2018-08-12-vae/
if each variable in the inferred latent representation z is only sensitive to one single generative factor and relatively invariant to other factors, we will say this representation is disentangled or factorized. One benefit that often comes with disentangled representation is good interpretability and easy generalization to a variety of tasks.
For example, a model trained on photos of human faces might capture the gentle, skin color, hair color, hair length, emotion, whether wearing a pair of glasses and many other relatively independent factors in separate dimensions. Such a disentangled representation is very beneficial to facial image generation.
β-VAE (Higgins et al., 2017) is a modification of Variational Autoencoder with a special emphasis to discover disentangled latent factors. Following the same incentive in VAE, we want to maximize the probability of generating real data, while keeping the distance between the real and estimated posterior distributions small:

We can rewrite it as a Lagrangian with a Lagrangian multiplier β under the KKT condition. The above optimization problem with only one inequality constraint is equivalent to maximizing the following equation:

The loss function of β-VAE is defined as:

where the Lagrangian multiplier β is considered as a hyperparameter.

When β =1, it is same as VAE. When β >1, it applies a stronger constraint on the latent bottleneck and limits the representation capacity of z. For some conditionally independent generative factors, keeping them disentangled is the most efficient representation. Therefore a higher β encourages more efficient latent encoding and further encourages the disentanglement. Meanwhile, a higher β may create a trade-off between reconstruction quality and the extent of disentanglement.
Burgess, et al. (2017) discussed the distentangling in β-VAE in depth with an inspiration by the information bottleneck theory and further proposed a modification to β-VAE to better control the encoding representation capacity.
※ https://openreview.net/pdf?id=Sy2fzU9gl
Abstract
Learning an interpretable factorised representation of the independent data generative factors of the world without supervision is an important precursor for the development of artificial intelligence that is able to learn and reason in the same way that humans do. We introduce β-VAE, a new state-of-the-art framework for automated discovery of interpretable factorised latent representations from raw image data in a completely unsupervised manner. Our approach is a modification of the variational autoencoder (VAE) framework. We introduce an adjustable hyperparameter β that balances latent channel capacity and independence constraints with reconstruction accuracy. We demonstrate that β-VAE with appropriately tuned β > 1 qualitatively outperforms VAE (β = 1), as well as state of the art unsupervised (InfoGAN) and semi-supervised (DC-IGN) approaches to disentangled factor learning on a variety of datasets (celebA, faces and chairs). Furthermore, we devise a protocol to quantitatively compare the degree of disentanglement learnt by different models, and show that our approach also significantly outperforms all baselines quantitatively. Unlike InfoGAN, β-VAE is stable to train, makes few assumptions about the data and relies on tuning a single hyperparameter β, which can be directly optimised through a hyperparameter search using weakly labelled data or through heuristic visual inspection for purely unsupervised data.
1. Introduction
The difficulty of learning a task for a given machine learning approach can vary significantly depending on the choice of the data representation. Having a representation that is well suited to the particular task and data domain can significantly improve the learning success and robustness of the chosen model (Bengio et al., 2013). It has been suggested that learning a disentangled representation of the generative factors in the data can be useful for a large variety of tasks and domains (Bengio et al., 2013; Ridgeway, 2016). A disentangled representation can be defined as one where single latent units are sensitive to changes in single generative factors, while being relatively invariant to changes in other factors (Bengio et al., 2013). For example, a model trained on a dataset of 3D objects might learn independent latent units sensitive to single independent data generative factors, such as object identity, position, scale, lighting or colour, thus acting as an inverse graphics model (Kulkarni et al., 2015). In a disentangled representation, knowledge about one factor can generalise to novel configurations of other factors. According to Lake et al. (2016), disentangled representations could boost the performance of state-of-the-art AI approaches in situations where they still struggle but where humans excel. Such scenarios include those which require knowledge transfer, where faster learning is achieved by reusing learnt representations for numerous tasks; zero-shot inference, where reasoning about new data is enabled by recombining previously learnt factors; or novelty detection.
Unsupervised learning of a disentangled posterior distribution over the underlying generative factors of sensory data is a major challenge in AI research (Bengio et al., 2013; Lake et al., 2016). Most previous attempts required a priori knowledge of the number and/or nature of the data generative factors (Hinton et al., 2011; Rippel & Adams, 2013; Reed et al., 2014; Zhu et al., 2014; Yang et al., 2015; Goroshin et al., 2015; Kulkarni et al., 2015; Cheung et al., 2015; Whitney et al., 2016; Karaletsos et al., 2016). This is not always feasible in the real world, where the newly initialised learner may be exposed to complex data where no a priori knowledge of the generative factors exists, and little to no supervision for discovering the factors is available. Until recently purely unsupervised approaches to disentangled factor learning have not scaled well (Schmidhuber, 1992; Desjardins et al., 2012; Tang et al., 2013; Cohen & Welling, 2014; 2015).
Recently a scalable unsupervised for disentangled factor learning has been developed, called InfoGAN (Chen et al., 2016). InfoGAN extends the generative adversarial network (GAN) (Goodfellow et al., 2014) framework to additionally maximise the mutual information between a subset of the generating noise variables and the output of a recognition network. It has been reported to be capable of discovering at least a subset of data generative factors and of learning a disentangled representation of these factors. The reliance of InfoGAN on the GAN framework, however, comes at the cost of training instability and reduced sample diversity. Furthermore, InfoGAN requires some a priori knowledge of the data, since its performance is sensitive to the choice of the prior distribution and the number of the regularised noise variables. InfoGAN also lacks a principled inference network (although the recognition network can be used as one). The ability to infer the posterior latent distribution from sensory input is important when using the unsupervised model in transfer learning or zero-shot inference scenarios. Hence, while InfoGAN is an important step in the right direction, we believe that further improvements are necessary to achieve a principled way of using unsupervised learning for developing more human-like learning and reasoning in algorithms as described by Lake et al. (2016).
Finally, there is currently no general method for quantifying the degree of learnt disentanglement. Therefore there is no way to quantitatively compare the degree of disentanglement achieved by different models or when optimising the hyperparameters of a single model.
In this paper we attempt to address these issues. We propose β-VAE, a deep unsupervised generative approach for disentangled factor learning that can automatically discover the independent latent factors of variation in unsupervised data. Our approach is based on the variational autoencoder (VAE) framework (Kingma & Welling, 2014; Rezende et al., 2014), which brings scalability and training stability. While the original VAE work has been shown to achieve limited disentangling performance on simple datasets, such as FreyFaces or MNIST (Kingma & Welling, 2014), disentangling performance does not scale to more complex datasets (e.g. Aubry et al., 2014; Paysan et al., 2009; Liu et al., 2015), prompting the development of more elaborate semi-supervised VAE-based approaches for learning disentangled factors (e.g. Kulkarni et al., 2015; Karaletsos et al., 2016).
We propose augmenting the original VAE framework with a single hyperparameter β that modulates the learning constraints applied to the model. These constraints impose a limit on the capacity of the latent information channel and control the emphasis on learning statistically independent latent factors. β-VAE with β = 1 corresponds to the original VAE framework (Kingma & Welling, 2014; Rezende et al., 2014). With β > 1 the model is pushed to learn a more efficient latent representation of the data, which is disentangled if the data contains at least some underlying factors of variation that are independent. We show that this simple modification allows β-VAE to significantly improve the degree of disentanglement in learnt latent representations compared to the unmodified VAE framework (Kingma & Welling, 2014; Rezende et al., 2014). Furthermore, we show that β-VAE achieves state of the art disentangling performance against both the best unsupervised (InfoGAN: Chen et al., 2016) and semi-supervised (DC-IGN: Kulkarni et al., 2015) approaches for disentangled factor learning on a number of benchmark datasets, such as CelebA (Liu et al., 2015), chairs (Aubry et al., 2014) and faces (Paysan et al., 2009) using qualitative evaluation. Finally, to help quantify the differences, we develop a new measure of disentanglement and show that β-VAE significantly outperforms all our baselines on this measure (ICA, PCA, VAE Kingma & Ba (2014), DC-IGN Kulkarni et al. (2015), and InfoGAN Chen et al. (2016)).
Our main contributions are the following: 1) we propose β-VAE, a new unsupervised approach for learning disentangled representations of independent visual data generative factors; 2) we devise a protocol to quantitatively compare the degree of disentanglement learnt by different models; 3) we demonstrate both qualitatively and quantitatively that our β-VAE approach achieves state-of-the-art disentanglement performance compared to various baselines on a variety of complex datasets.
2. β-VAE framework derivation




3. Disentanglement metric
It is important to be able to quantify the level of disentanglement achieved by different models. Designing a metric for this, however, is not straightforward. We begin by defining the properties that we expect a disentangled representation to have. Then we describe our proposed solution for quantifying the presence of such properties in a learnt representation.
As stated above, we assume that the data is generated by a ground truth simulation process which uses a number of data generative factors, some of which are conditionally independent, and we also assume that they are interpretable. For example, the simulator might sample independent factors corresponding to object shape, colour and size to generate an image of a small green apple. Because of the independence property, the simulator can also generate small red apples or big green apples. A representation of the data that is disentangled with respect to these generative factors, i.e. which encodes them in separate latents, would enable robust classification even using very simple linear classifiers (hence providing interpretability). For example, a classifier that learns a decision boundary that relies on object shape would perform as well when other data generative factors, such as size or colour, are varied.
Note that a representation consisting of independent latents is not necessarily disentangled, according to our desiderata. Independence can readily be achieved by a variety of approaches (such as PCA or ICA) that learn to project the data onto independent bases. Representations learnt by such approaches do not in general align with the data generative factors and hence may lack interpretability. For this reason, a simple cross-correlation calculation between the inferred latents would not suffice as a disentanglement metric.
Our proposed disentangling metric, therefore, measures both the independence and interpretability (due to the use of a simple classifier) of the inferred latents. To apply our metric, we run inference on a number of images that are generated by fixing the value of one data generative factor while randomly sampling all others. If the independence and interpretability properties hold for the inferred representations, there will be less variance in the inferred latents that correspond to the fixed generative factor. We use a low capacity linear classifier to identify this factor and report the accuracy value as the final disentanglement metric score. Smaller variance in the latents corresponding to the target factor will make the job of this classifier easier, resulting in a higher score under the metric. See Fig. 5 for a representation of the full process.

More formally, we start from a dataset D = {X, V, W} as described in Sec. 2, assumed to contain a balanced distribution of ground truth factors (v, w), where images data points are obtained using a ground truth simulator process x ∼ Sim(v, w). We also assume we are given labels identifying a subset of the independent data generative factors v ∈ V for at least some instances. We then construct a batch of B vectors z b diff, to be fed as inputs to a linear classifier as follows:
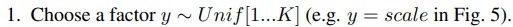

The classifier's goal is to predict the index y of the generative factor that was kept fixed for a given z b diff. The accuracy of this classifier over multiple batches is used as our disentanglement metric score. We choose a linear classifier with low VC-dimension in order to ensure it has no capacity to perform nonlinear disentangling by itself. We take differences of two inferred latent vectors to reduce the variance in the inputs to the classifier, and to reduce the conditional dependence on the inputs x. This ensures that on average z b diff y < z b diff {\y} . See Equations 5 in Appendix A.4 for more details of the process.
4. Experiments
In this section we first qualitatively demonstrate that our proposed β-VAE framework consistently discovers more latent factors and disentangles them in a cleaner fashion that either unmodified VAE (Kingma & Welling, 2014) or state of the art unsupervised (InfoGAN: Chen et al., 2016) and semisupervised (DC-IGN: Kulkarni et al., 2015) solutions for disentangled factor learning on a variety of benchmarks. We then quantify and characterise the differences in disentangled factor learning between our β-VAE framework and a variety of benchmarks using our proposed new disentangling metric.
4.1 Qualitative Benchmarks




4.2 Quantitative Benchmarks
5. Conclusion
In this paper we have reformulated the standard VAE framework (Kingma & Welling, 2014; Rezende et al., 2014) as a constrained optimisation problem with strong latent capacity constraint and independence prior pressures. By augmenting the lower bound formulation with the β coefficient that regulates the strength of such pressures and, as a consequence, the qualitative nature of the representations learnt by the model, we have achieved state of the art results for learning disentangled representations of data generative factors. We have shown that our proposed β-VAE framework significantly outperforms both qualitatively and quantitatively the original VAE (Kingma & Welling, 2014), as well as state-of-the-art unsupervised (InfoGAN: Chen et al., 2016) and semi-supervised (DC-IGN: Kulkarni et al., 2015) approaches to disentangled factor learning. Furthermore, we have shown that β-VAE consistently and robustly discovers more factors of variation in the data, and it learns a representation that covers a wider range of factor values and is disentangled more cleanly than other benchmarks, all in a completely unsupervised manner. Unlike InfoGAN and DC-IGN, our approach does not depend on any a priori knowledge about the number or the nature of data generative factors. Our preliminary investigations suggest that the performance of the β-VAE framework may depend on the sampling density of the data generative factors within a training dataset (see Appendix A.8 for more details). It appears that having more densely sampled data generative factors results in better disentangling performance of β-VAE, however we leave a more principled investigation of this effect to future work.
β-VAE is robust with respect to different architectures, optimisation parameters and datasets, hence requiring few design decisions. Our approach relies on the optimisation of a single hyperparameter β, which can be found directly through a hyperparameter search if weakly labelled data is available to calculate our new proposed disentangling metric. Alternatively the optimal β can be estimated heuristically in purely unsupervised scenarios. Learning an interpretable factorised representation of the independent data generative factors in a completely unsupervised manner is an important precursor for the development of artificial intelligence that understands the world in the same way that humans do (Lake et al., 2016). We believe that using our approach as an unsupervised pretraining stage for supervised or reinforcement learning will produce significant improvements for scenarios such as transfer or fast learning.
'*Generative Model > Generative Model' 카테고리의 다른 글
[HFVAE] Structured Disentangled Representations (0) 2024.04.05 [Factor VAE] Disentangling by Factorising (0) 2024.04.05 Semi-supervised Learning with Variational Autoencoders (0) 2024.04.04 [CVAE 2] Semi-supervised Learning with Deep Generative Models (0) 2024.04.03 [CVAE 1] Learning Structured Output Representation using Deep Conditional Generative Models (0) 2024.04.03