-
Secret of LSTMResearch/NLP_Stanford 2024. 6. 22. 09:22
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=0LixFSa7yts&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=6&t=2101s
Lecture 6 - Simple and LSTM RNNs

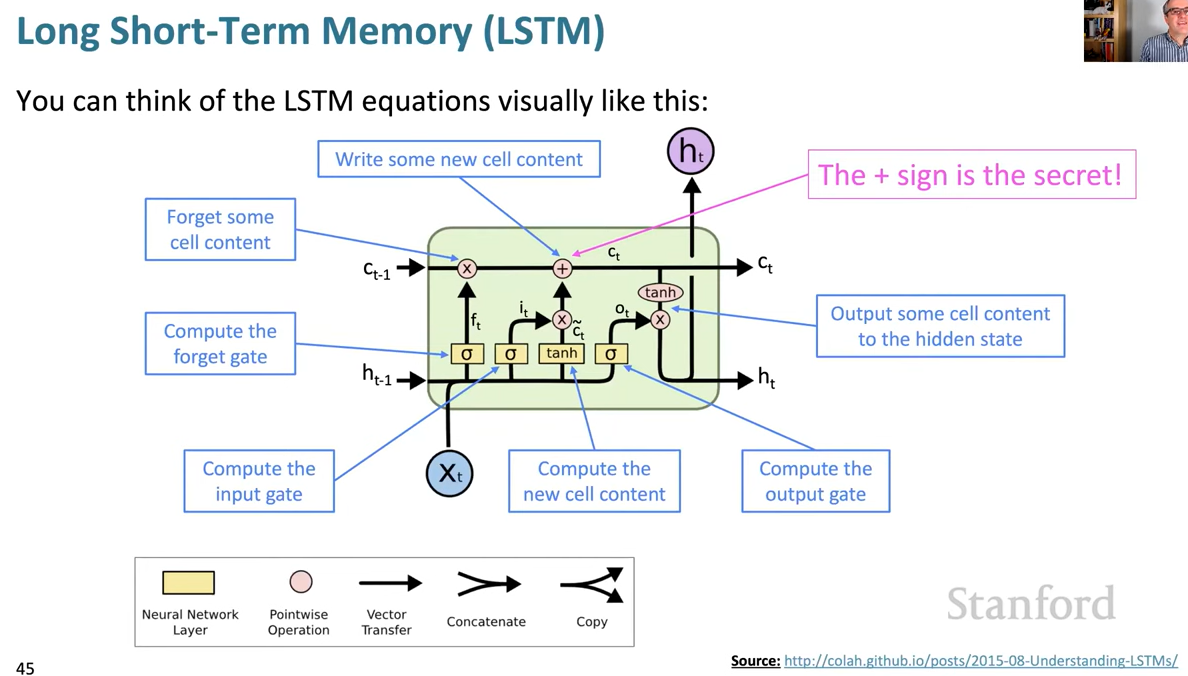
As to understanding why something that's different is happening here, the thing to notice is that the cell state from t-1 is passing right through to be the cell state at time t, without very much happening to it. So some of it is being deleted by the forget gate. And then some new stuff is being written to it, as a result of using candidate new cell content.
But the real secret of the LSTM is that new stuff is just being added to the cell with an addition. So in the simple RNN, at each successive step, you are doing a multiplication. And that makes it incredibly difficult to learn to preserve information in the hidden states, over a long period of time. It's not completely impossible, but it's a very difficult thing to learn. Whereas with LSTM architecture, it's trivial to preserve information in the cell from one timestep to the next. You just don't forget it and it'll carry right through with some new stuff added in to also remember. And so that's the sense in which the cell behaves much more like RAM, in a conventional computer that is storing stuff. Extra stuff can be stored into it, and other stuff can be deleted from it, as you go along.
So the LSTM architecture makes it much easier to preserve information for many timesteps!
GOOD!
'Research > NLP_Stanford' 카테고리의 다른 글
Pretraining (0) 2024.06.23 Self-Attention & Transformers (0) 2024.06.22 Neural Machine Translation (0) 2024.06.22 Sequence-to-Sequence model (0) 2024.06.22 Bidirectional and Multi-layer RNNs (0) 2024.06.22