-
Sequence-to-Sequence model*NLP/NLP_Stanford 2024. 6. 22. 12:26
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=0LixFSa7yts&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=6&t=2101s
Lecture 7 - Translation, Seq2Seq, Attention
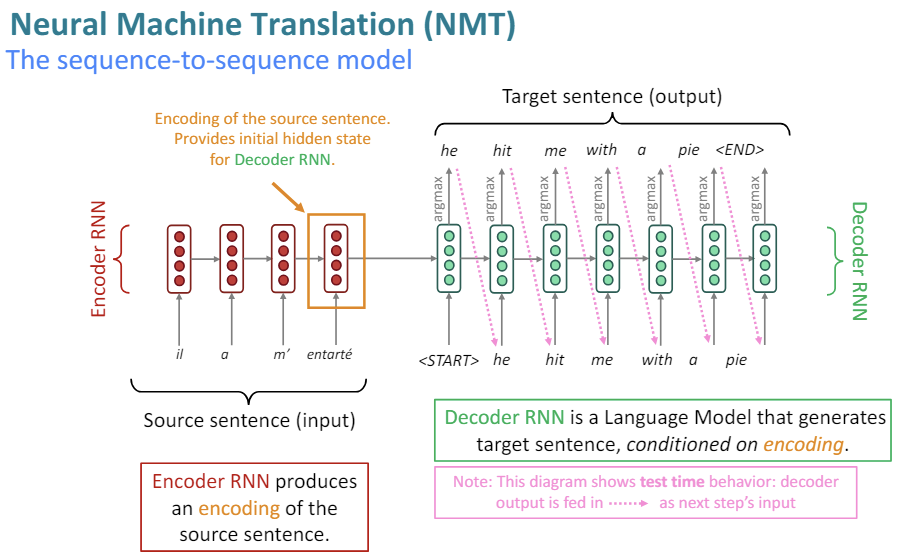
Neural machine translation means you're using a neural network to do machine translation. But in practice, it's meant slightly more than that. It has meant that we're going to build one very large neural network, which completely does translation end to end.
So we're going to have a large neural network, we're going to feed in the source sentence into the input. And what's going to come out of the output of the neural network is the translation of the sentence.
We're going to train that model end to end parallel sentences. And it's the entire system rather than being lots of separate components as in an old fashioned machine translation system.
So these neural network architectures are called sequence to sequence models (seq2seq), and they involve two neural networks, here it says two RNNs. But more generally, they involve two neural networks.
There's one neural network that is going to encode the source sentence. So if we have a source sentence here, we are going to encode that sentence. Using the kind of LSTMs, we can start at the beginning and go through a sentence and update the hidden state each time. And that will give use a representation of the content of the source sentence. So that's the first sequence model, which encodes the source sentence.
And we'll use the idea that the final hidden state of the encoder RNN is going to for instance, represent the source sentence. And we're going to feed it in directly as the initial hidden state for the decoder, or RNN. So then we have our decoder RNN. And it's a language model that's going to generate a target sentence conditioned on the final hidden state of the encoder RNN.
So we're going to start with the input of start symbol. We're going to feed in the hidden state from the encoder RNN. And now this second RNN has completely separate parameters. But we do the same kind of LSTM computations and generate a first word of the sentence, "he." And so then doing LSTM generation, we copy that down as the next input. We run the next step of the LSTM, generate another word, copy it down, and chug along. And we've translated the sentence. This is showing the test time behavior when we're generating the next sentence.
For the training time behavior, when we have parallel sentences, we're still using the same kind of sequence to sequence model. But we're doing it with the decoder part just like training a langauge model, where we're wanting to do teacher forcing and predict each word that's actually found in the source language sentence.
Sequence to sequence models have been an incredibly powerful, widely used work force in neural networks for NLP. So although historically, machine translation was the first big use of them, and it's sort of the canonical use, they're used everywhere else as well. So you can do many other NLP tasks for them.
So you can do summarization. You can think of text summarization as translating a long text into a short text.
but you can use them for other things that are in no way a translation whatsoever.
'*NLP > NLP_Stanford' 카테고리의 다른 글
Pretraining (0) 2024.06.23 Self-Attention & Transformers (0) 2024.06.22 Neural Machine Translation (0) 2024.06.22 Bidirectional and Multi-layer RNNs (0) 2024.06.22 Secret of LSTM (0) 2024.06.22