-
Neural Machine TranslationResearch/NLP_Stanford 2024. 6. 22. 12:50
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=0LixFSa7yts&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=6&t=2101s
Lecture 7 - Translation, Seq2Seq, Attention

Sequence to sequence models is an example of conditional language models.
Previously, the main thing we were doing was just to start at the beginning of the sentence and generate a sentence based on nothing. But here we have something that is going to determine or partially determine that is going to condition what we should produce. So we have a source sentence. And that's going to strongly determine what is a good translation.
So to achieve that, what we're going to do is have some way of transferring information about the source sentence from the encoder to trigger what the decoder should do.
The two standard ways of doing that are you either feed in a hidden state as the initial hidden state to the decoder, or sometimes you will feed something in as the initial input to the decoder.
So in neural machine translation, we are directly calculating this conditional model probability of target language sentence given source language sentence. So at each step, as we break down the word by word generation, that we're conditioning not only on previous words of the target language, but also each time on our source language sentence x.
Because of this, we actually know a ton more about what our sentence that we generate should be. So if you look at the perplexities of these kind of conditional language models, you will find them, almost freakily low perplexities, that you will have models with perplexities that are something like 4 or even less, sometimes 2.5 because you get a lot of information about what words you should be generating.
How to train a neural machine translation system and then how to use it at runtime?
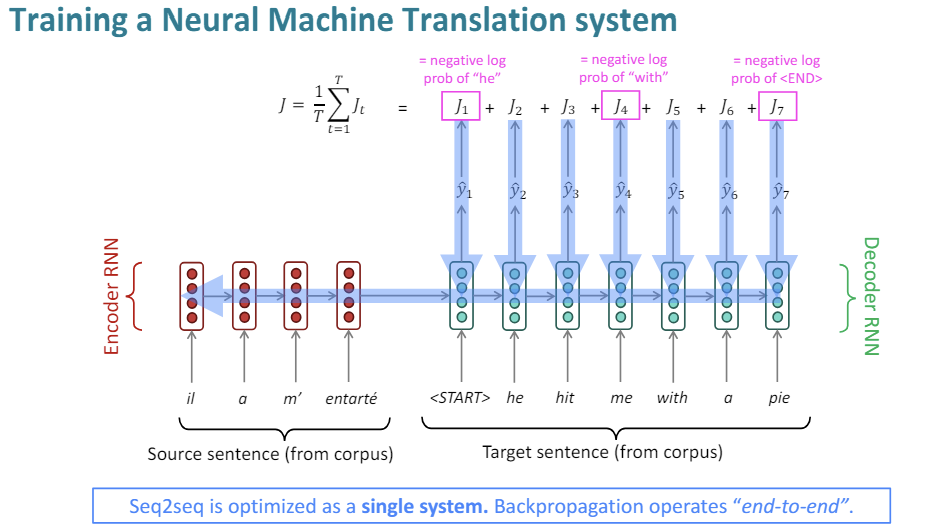
The first step is we get a large parallel corpus. So we run off to the European Union, for example. And we grab a lot of parallel English French data from the European parliament proceedings. So then once we have our parallel sentences, what we're going to do is take batches of source sentences and target sentences.
We'll encode the source sentence with our encoder LSTM. We'll feed its final hidden state into a target LSTM. And this one, we are now then going to train word by word by comparing what it predicts is the most likely word to be produced, versus what the actual first word, and then the actual second word is. And to the extent that we get it wrong, we're going to suffer some loss.
So this is going to be the negative log probability of generating the correct next word "he" and so on along the sentence. And we can work out our overall loss for the sentence doing this teacher forcing style, generate one word at a time, calculate a loss relative to the word that you should have produced.
Loss then gives us information that we can backpropagate through the entire network. The crucial thing about these sequence to seqeunce models that has made them extremely successful in practice is that the entire thing is optimized as a single system end to end. So starting with our final loss, we backpropagate it right through the system. So we not only update all the parameters of the decoder model, but we also update all of the parameters of the encoder model, which in turn will influence what conditioning gets passed over from the encoder to the decoder.

The RNNs that we've looked at so far are already deep on one dimension that unroll horizontally over many time steps. But they've been shallow in that there's just been a single layer of recurrent structure about our sentences.
We can also make them deep in the other dimension by applying multiple RNNs on top of each other. This gives us some multilayer RNN. Often also called a stacked RNN. Having a multilayer RNN allows us the network to compute more complex representations.
So simply put the lower RNNs tend to compute lower level features, and the higher RNNs should compute higher level features. => ???? 이거 레알? need to check! Convolution layer가 deep 해질수록 feature representation 이 more detail로 가는 건 experimentally 확인했는데.. RNN도 그럼???
What would lower level versus higher level features mean in this context???? Typically, what that's meaning is that lower level features are knowing sort of more basic things about words and phrases. So that commonly might be things like what part of speech is this word, or are these words the name of a person, or the name of company? Whereas higher level features refer to things that are at a higher semantic level. So knowing more about the overall structure of a sentence, knowing something about what is means, whether a phrase has positive or negative annotations. What its semantics are when you put together several words into an idiomatic phrase, roughly the higher level kinds of things.
And just like in other neural networks, whether it's feed forward networks, or the kind of networks in vision systems, you get much greater power and success by having a stack on multiple layers of recurrent neural networks.
You might think that, there are two things I could do. I could have a single LSTM with a hidden state of dimension 2000, or I could have four layers of LSTMs with a hidden state of 500 each. And it shouldn't make any difference because I've got the same number of parameters roughly. But that's not true. In practice, it does make a big difference. And multilayer or stacked RNNs are more powerful.
=> Why????

When we build one of these end to end neural machine translation systems, if we want them to work well, single layer LSTM encoder-decoder in neural mahcine translation systems just don't work well.
But you can build something that is no more complex than the model that I've just explained now. That does work pretty well by making it a multi-layer stacked LSTM neural machine translation system.
So we've got this multilayer LSTM that's going through the source sentence. And so now, at each point in time, we calculate a new hidden representation that rather than stopping there, we feed it as the input into another layer of LSTM, and we calculate in the standard way its new hidden representation. And the output of it, we feed into a third layer of LSTM. And so we run that right along. So our representation of the source sentence from encoder is then this stack of three hidden layers. Then we use that to feed in as the initial hidden layer into generating translations, or for training the model of comparing the losses.
So this is what the picture of a LSTM encoder-decoder neural machine translation system really looks like.

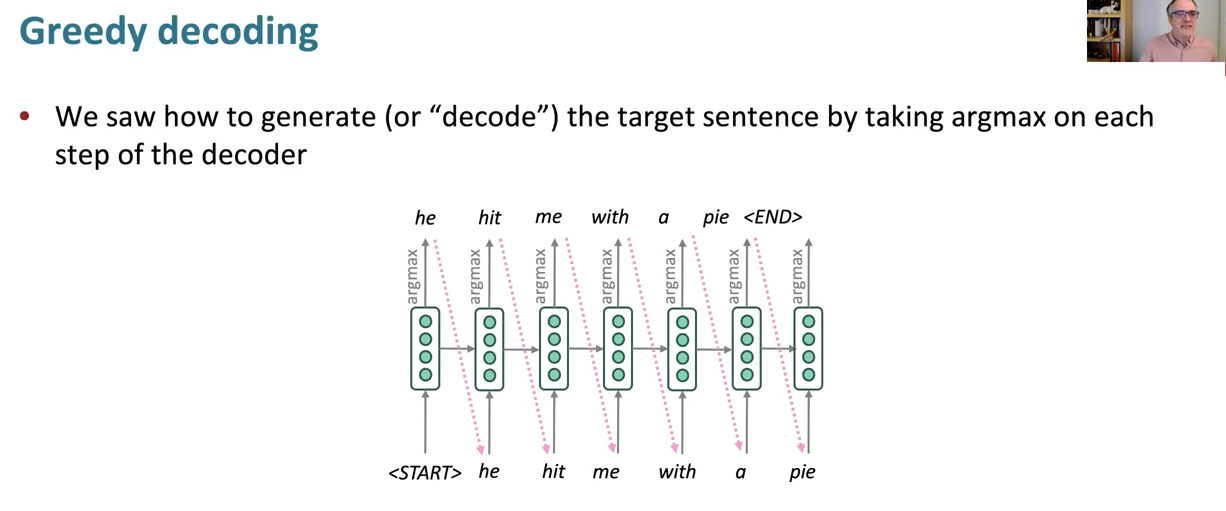

The simplest way to decode is the one that we presented so far. So that we have our LSTM, we start, generate a hidden state. It has a probability distribution over words. And you choose the most probable one the argmax. And you say "he", and you copy it down and you repeat over.
So doing this is referred to as greedy decoding. Taking the most probable word on each step. And it's sort of the obvious thing to do, and doesn't seem like it could be a bad thing to do. But it turns out that it actually can be a fairly problematic thing to do.
The idea of that is, with greedy decoding, you're taking locally what seems the best choice. And then you're stuck with it. You have no way to undo decisions.
Once you've generated it, there's no way to go backwards. And so you just have to keep on going from there and you may not be able to generate the translation you want. So we'd like to be able to explore a bit more in generating our translations.

What could we do? Find translations that maximize the probability of y given x, and at least if we know what the length of that translation is. We can do that as a product of generating a word at a time. And so to have a full model. We also have to have a probability distribution over how long the translation length would be.
Let's generate and score all possible sequences y using this model. And that's where that then requires generating an exponential number of translations. And it's far too expensive.


Neural translation has proven to be much better. I'll show you a couple of statistics and about that in a moment. It has many advantages.
It gives better performance. The translations are better. In particular, they're more fluent because neural language models produce much more fluent sentences. But also, they much better use context because neural language models, including conditional neural language models give us a very good way of conditioning on a lot of contexts. In particular, we can just run a long encoder and condition on the previous sentence, or we can translate words well in context by making use of neural context.
Neural models better understand phrase similarities. And then the technique of optimizing all parameters of the model end to end in a single large neural network has just proved to be a really powerful idea. Previously, a lot of the time, people were building separate components and tuning them individually, which just meant that they weren't actually optimal when put into a much bigger system.
So really a hugely powerful guiding idea in neural network land is if you can build one huge network, and just optimize the entire thing end to end, that will give you much better performance than component-wise systems. We'll come back to the costs of that later in the course.
The models are also actually great in other ways. They actually require much less human effort to build. There's no feature engineering. There's in general, no language specific components. You're using the same method for all language pairs.

Neural machine translation systems also have some disadvantages compared to the older statistical machine translation systems. They're less interpretable. It's harder to see why they're doing what they're doing, where before you could actually look at phrase tables and they were useful. So they're hard to debug.
They also tend to be difficult to control. So compared to anything like writing rules, you can't really give much specification as if you like to say I'd like my translations to be more casual or something like that.
It's hard to know what they'll generate. So there are various safety concerns.

How do we evaluate machine translation?
The most famous method of doing that is BLEU. The way you do BLEU is you have a human translation or several human translations of the source sentence, and you're comparing a mahcine generated translation to those pre-given human written translations. And you score them for similarity by calculating n-gram precisions, i.e., words that overlap between the computer and human reason traslation, bi-grams, tri-grams, and 4-grams. And then working out a geometric average between overlaps of n-grams, plus there's a penalty for too short system translations. BLEU has proven to be a really useful measure.
But it's an imperfect measure. That commonly there are many valid ways to translate a sentence.


Machine translation is solved? No. There are still lots of difficulties which people continue to work on very actively.
There are lots of problems with out of vocabulary words. There are domain mismatches between the training and test data. So it might be trained mainly on news wire data but you want to translate people's Facebook messages. There are still problems of maintaining context over longer text. We'd like to translate languages for which we don't have much data. These methods work by far the best when we have huge amounts of parallel data. Even our best multilayer LSTMs aren't great of capturing sentence meaning. There are particular problems such as interpreting what pronouns refer to, or in languages like Chinese or Japanese, where there's often no pronoun present. For languages that have lots of inflectional forms of nouns, verbs, and adjectives. There systems often get them wrong. So there's still tons of stuff to do.

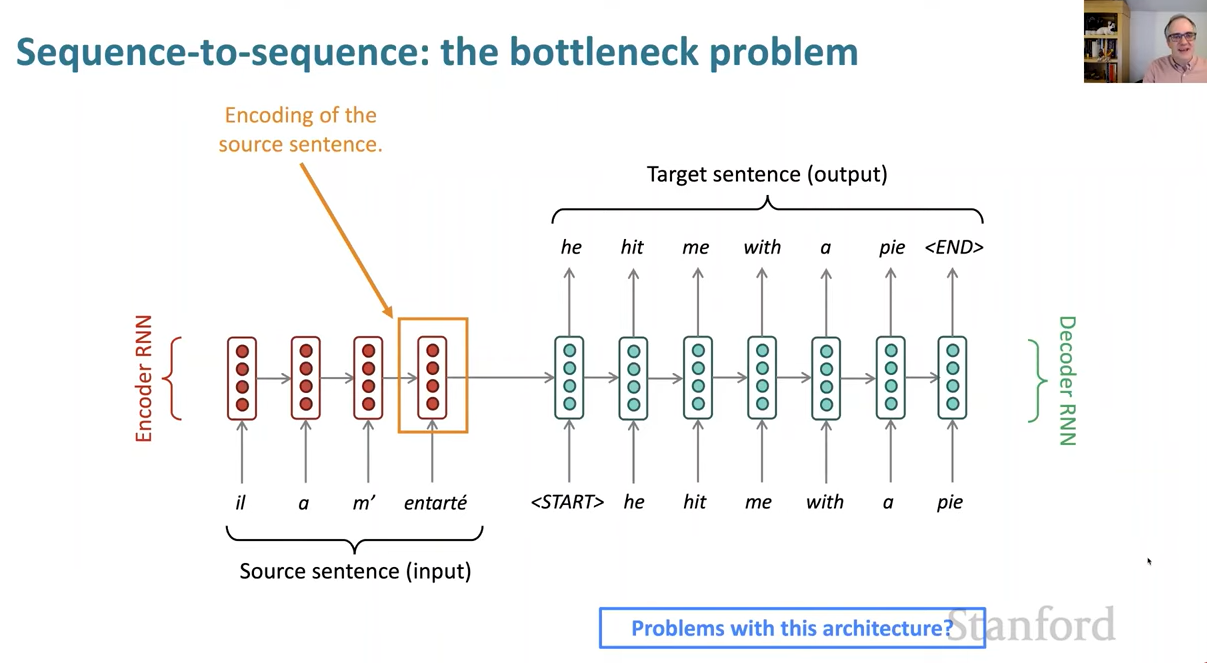
We had this model of doing sequence to sequence models such as for neural machine translation. And the problem with this architecture is that we have one hidden state, which has to encode all the information about the source sentence. So it acts as a kind of information bottleneck. That's all the information that the generation is conditioned on.
I did already mention one idea of how to get more informaiton where you could average all of the vectors of the source to get a sentence representation. But that method turns out to be better for things like sentiment analysis. And not so good for machine translation, where the order of words is very important to preserve. So it seems like we would do better, if somehow, we could get more information from the source sentence while we're generating the translation. And in some sense, this just corresponds to what a human translator does.
If you're a human translator, you read the sentence that you're meant to translate. And you maybe start translating a few words. But then you look back at the source sentence to see what else was in it and translate some more words. So very quickly after the first neural machine translation systems, people came up with the idea of maybe we could build a better neural empty MT that did that. And that's the idea of attention.

So the core idea is on each step of the decoder, we're going to use a direct link between the encoder and the decoder that will allow us to focus on a particular word or words in the source sequence and use it to help us generate what words come next.






We use our encoder just as before and generate our representations, feed in our conditioning as before, and say we're starting our translation. But at this point, we take this hidden representation, and say, I'm going to use this hidden representation to look back at the source to get information directly from it.
So what I will do is I will compare the hidden state of the decoder with the hidden state of the encoder at each position and generate an attention score, which is a kind of similarity score like a product. And then based on those attention scores, I'm going to calculate a probability distribution as to by using a softmax as usual to say which of these encoder states is most like my decoder state.
So we'll be training the model to be saying, probably you should translate the first word of the sentence first, so that's where the attention should be placed. So then based on this attention distribution, which is a probability distribution coming out of the softmax, we're going to generate a new attention output.
And so this attention output is going to be an average of the hidden states of the encoder model. That is going to be a weighted average based on our attention distribution. So we then kind of take that attention output, combind it with the hidden state of the decoder RNN and together, the two of them are then going to be used to predict via a softmax what word to generate first, and we hope to generate he. And then at that point, we chug along and keep doing the same kind of computations at each position.
That's proven to be a very effective way of getting more information from the source sentence more flexibly to allow us to generate a good translation.
'Research > NLP_Stanford' 카테고리의 다른 글
Pretraining (0) 2024.06.23 Self-Attention & Transformers (0) 2024.06.22 Sequence-to-Sequence model (0) 2024.06.22 Bidirectional and Multi-layer RNNs (0) 2024.06.22 Secret of LSTM (0) 2024.06.22