-
[T5] (2/3) Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer*NLP/NLP_Paper 2024. 7. 22. 12:09
https://arxiv.org/pdf/1910.10683
자, 심호흡 하고 시작하자!! ㅎㅎㅎㅎㅎ 갈 길이 어마어마하게 멀다 ㅋㅋㅋㅋㅋ
Google 연구진들이 엄청 심혈을 기울여서 experiments를 진행하고, T5를 완성하셨어 ㅋㅋㅋ
이거 보다가 나 쓰러질지도 몰라.
T5 자세히 봐야겠다 생각한 게 1년이 넘었다 ㅋㅋㅋ
이제 마지막 기회야. 지금 지나면 이제 이렇게 시간을 들여서 볼 기회가 없을 것 같아.
후 =3 후 =3 심호흡!! 할 수 있어!! 완주할 수 있어!! ㅎㅎ

3. Experiments
Recent advances in transfer learning for NLP have come from a wide variety of developments, such as new pre-training objectives, model architectures, unlabeled data sets, and more. In this section, we carry out an empirical survey of these techniques in hopes of teasing apart their contribution and significance. We then combine the insights gained to attain state-of-the-art in many of the tasks we consider. Since transfer learning for NLP is a rapidly growing area of research, it is not feasible for us to cover every possible technique or idea in our empirical study. For a broader literature review, we recommend a recent survey by Ruder et al. (2019).
We systematically study these contributions by taking a reasonable baseline (described in Section 3.1) and altering one aspect of the setup at a time. For example, in Section 3.3 we measure the performance of different unsupervised objectives while keeping the rest of our experimental pipeline fixed. This “coordinate ascent” approach might miss second-order effects (for example, some particular unsupervised objective may work best on a model larger than our baseline setting), but performing a combinatorial exploration of all of the factors in our study would be prohibitively expensive. In future work, we expect it could be fruitful to more thoroughly consider combinations of the approaches we study.
Our goal is to compare a variety of different approaches on a diverse set of tasks while keeping as many factors fixed as possible. In order to satisfy this aim, in some cases we do not exactly replicate existing approaches. For example, “encoder-only” models like BERT (Devlin et al., 2018) are designed to produce a single prediction per input token or a single prediction for an entire input sequence. This makes them applicable for classification or span prediction tasks but not for generative tasks like translation or abstractive summarization. As such, none of the model architectures we consider are identical to BERT or consist of an encoder-only structure. Instead, we test approaches that are similar in spirit—for example, we consider an analogous objective to BERT’s “masked language modeling” objective in Section 3.3 and we consider a model architecture that behaves similarly to BERT on text classification tasks in Section 3.2.
After outlining our baseline experimental setup in the following subsection, we undertake an empirical comparison of model architectures (Section 3.2), unsupervised objectives (Section 3.3), pre-training data sets (Section 3.4), transfer approaches (Section 3.5), and scaling (Section 3.6). At the culmination of this section, we combine insights from our study with scale to obtain state-of-the-art results in many tasks we consider (Section 3.7).
3.1. Baseline
Our goal for our baseline is to reflect typical, modern practice. We pre-train a standard Transformer (described in Section 2.1) using a simple denoising objective and then separately fine-tune on each of our downstream tasks. We describe the details of this experimental setup in the following subsections.
3.1.1. Model
For our model, we use a standard encoder-decoder Transformer as proposed by Vaswani et al. (2017). While many modern approaches to transfer learning for NLP use a Transformer architecture consisting of only a single “stack” (e.g. for language modeling (Radford et al., 2018; Dong et al., 2019) or classification and span prediction (Devlin et al., 2018; Yang et al., 2019)), we found that using a standard encoder-decoder structure achieved good results on both generative and classification tasks. We explore the performance of different model architectures in Section 3.2.
Our baseline model is designed so that the encoder and decoder are each similar in size and configuration to a “BERT_BASE” (Devlin et al., 2018) stack. Specifically, both the encoder and decoder consist of 12 blocks (each block comprising self-attention, optional encoder-decoder attention, and a feed-forward network). The feed-forward networks in each block consist of a dense layer with an output dimensionality of d_ff = 3072 followed by a ReLU nonlinearity and another dense layer. The “key” and “value” matrices of all attention mechanisms have an inner dimensionality of d_kv = 64 and all attention mechanisms have 12 heads. All other sub-layers and embeddings have a dimensionality of d_model = 768. In total, this results in a model with about 220 million parameters. This is roughly twice the number of parameters of BERT_BASE since our baseline model contains two layer stacks instead of one. For regularization, we use a dropout probability of 0.1 everywhere dropout is applied in the model.
3.1.2. Training
As described in Section 2.4, all tasks are formulated as text-to-text tasks. This allows us to always train using standard maximum likelihood, i.e. using teacher forcing (Williams and Zipser, 1989) and a cross-entropy loss. For optimization, we use AdaFactor (Shazeer and Stern, 2018). At test time, we use greedy decoding (i.e. choosing the highest-probability logit at every timestep).
We pre-train each model for 2^19 = 524,288 steps on C4 before fine-tuning. We use a maximum sequence length of 512 and a batch size of 128 sequences. Whenever possible, we “pack” multiple sequences into each entry of the batch10 so that our batches contain roughly 2^16 = 65,536 tokens. In total, this batch size and number of steps corresponds to pre-training on 2^35 ≈ 34B tokens. This is considerably less than BERT (Devlin et al., 2018), which used roughly 137B tokens, or RoBERTa (Liu et al., 2019c), which used roughly 2.2T tokens. Using only 2^35 tokens results in a reasonable computational budget while still providing a sufficient amount of pre-training for acceptable performance. We consider the effect of pre-training for more steps in Sections 3.6 and 3.7. Note that 2^35 tokens only covers a fraction of the entire C4 data set, so we never repeat any data during pre-training.
During pre-training, we use an “inverse square root” learning rate schedule: 1 √ max(n, k) where n is the current training iteration and k is the number of warm-up steps (set to 10^4 in all of our experiments). This sets a constant learning rate of 0.01 for the first 10^4 steps, then exponentially decays the learning rate until pre-training is over. We also experimented with using a triangular learning rate (Howard and Ruder, 2018), which produced slightly better results but requires knowing the total number of training steps ahead of time. Since we will be varying the number of training steps in some of our experiments, we opt for the more generic inverse square root schedule.
Our models are fine-tuned for 2^18 = 262,144 steps on all tasks. This value was chosen as a trade-off between the high-resource tasks (i.e. those with large data sets), which benefit from additional fine-tuning, and low-resource tasks (smaller data sets), which overfit quickly. During fine-tuning, we continue using batches with 128 length-512 sequences (i.e. 2^16 tokens per batch). We use a constant learning rate of 0.001 when fine-tuning. We save a checkpoint every 5,000 steps and report results on the model checkpoint corresponding to the highest validation performance. For models fine-tuned on multiple tasks, we choose the best checkpoint for each task independently. For all of the experiments except those in Section 3.7, we report results in the validation set to avoid performing model selection on the test set.
3.1.3. Vocabulary
We use SentencePiece (Kudo and Richardson, 2018) to encode text as WordPiece tokens (Sennrich et al., 2015; Kudo, 2018). For all experiments, we use a vocabulary of 32,000 wordpieces. Since we ultimately fine-tune our model on English to German, French, and Romanian translation, we also require that our vocabulary covers these non-English languages. To address this, we classified pages from the Common Crawl scrape used in C4 as German, French, and Romanian. Then, we trained our SentencePiece model on a mixture of 10 parts of English C4 data with 1 part each of data classified as German, French or Romanian. This vocabulary was shared across both the input and output of our model. Note that our vocabulary makes it so that our model can only process a predetermined, fixed set of languages.
3.1.4. Unsupervised Objective
Leveraging unlabeled data to pre-train our model necessitates an objective that does not require labels but (loosely speaking) teaches the model generalizable knowledge that will be useful in downstream tasks. Preliminary work that applied the transfer learning paradigm of pre-training and fine-tuning all of the model’s parameters to NLP problems used a causal language modeling objective for pre-training (Dai and Le, 2015; Peters et al., 2018; Radford et al., 2018; Howard and Ruder, 2018). However, it has recently been shown that “denoising” objectives (Devlin et al., 2018; Taylor, 1953) (also called “masked language modeling”) produce better performance and as a result they have quickly become standard. In a denoising objective, the model is trained to predict missing or otherwise corrupted tokens in the input. Inspired by BERT’s “masked language modeling” objective and the “word dropout” regularization technique (Bowman et al., 2015), we design an objective that randomly samples and then drops out 15% of tokens in the input sequence. All consecutive spans of dropped-out tokens are replaced by a single sentinel token. Each sentinel token is assigned a token ID that is unique to the sequence. The sentinel IDs are special tokens which are added to our vocabulary and do not correspond to any wordpiece. The target then corresponds to all of the dropped-out spans of tokens, delimited by the same sentinel tokens used in the input sequence plus a final sentinel token to mark the end of the target sequence. Our choices to mask consecutive spans of tokens and only predict dropped-out tokens were made to reduce the computational cost of pre-training. We perform thorough investigation into pre-training objectives in Section 3.3. An example of the transformation resulting from applying this objective is shown in Figure 2. We empirically compare this objective to many other variants in Section 3.3.

3.1.5. Baseline Performance
In this section, we present results using the baseline experimental procedure described above to get a sense of what kind of performance to expect on our suite of downstream tasks. Ideally, we would repeat every experiment in our study multiple times to get a confidence interval on our results. Unfortunately, this would be prohibitively expensive due to the large number of experiments we run. As a cheaper alternative, we train our baseline model 10 times from scratch (i.e. with different random initializations and data set shuffling) and assume that the variance over these runs of the base model also applies to each experimental variant. We don’t expect most of the changes we make to have a dramatic effect on the inter-run variance, so this should provide a reasonable indication of the significance of different changes. Separately, we also measure the performance of training our model for 2^18 steps (the same number we use for fine-tuning) on all downstream tasks without pre-training. This gives us an idea of how much pre-training benefits our model in the baseline setting.
When reporting results in the main text, we only report a subset of the scores across all the benchmarks to conserve space and ease interpretation. For GLUE and SuperGLUE, we report the average score across all subtasks (as stipulated by the official benchmarks) under the headings “GLUE” and “SGLUE”. For all translation tasks, we report the BLEU score (Papineni et al., 2002) as provided by SacreBLEU v1.3.0 (Post, 2018) with “exp” smoothing and “intl” tokenization. We refer to scores for WMT English to German, English to French, and English to Romanian as EnDe, EnFr, and EnRo, respectively. For CNN/Daily Mail, we find the performance of models on the ROUGE-1-F, ROUGE-2-F, and ROUGE-L-F metrics (Lin, 2004) to be highly correlated so we report the ROUGE-2-F score alone under the heading “CNNDM”. Similarly, for SQuAD we find the performance of the “exact match” and “F1” scores to be highly correlated so we report the “exact match” score alone. We provide every score achieved on every task for all experiments in Table 16, Appendix E.
Our results tables are all formatted so that each row corresponds to a particular experimental configuration with columns giving the scores for each benchmark. We will include the mean performance of the baseline configuration in most tables. Wherever a baseline configuration appears, we will mark it with a ⋆ (as in the first row of Table 1). We also will boldface any score that is within two standard deviations of the maximum (best) in a given experiment.

Our baseline results are shown in Table 1. Overall, our results are comparable to existing models of similar size. For example, BERT_BASE achieved an exact match score of 80.8 on SQuAD and an accuracy of 84.4 on MNLI-matched, whereas we achieve 80.88 and 84.24, respectively (see Table 16). Note that we cannot directly compare our baseline to BERT_BASE because ours is an encoder-decoder model and was pre-trained for roughly 1⁄4 as many steps. Unsurprisingly, we find that pre-training provides significant gains across almost all benchmarks. The only exception is WMT English to French, which is a large enough data set that gains from pre-training tend to be marginal. We include this task in our experiments to test the behavior of transfer learning in the high-resource regime. Since we perform early stopping by selecting the best-performing checkpoint, the large disparity between our baseline and “no pre-training” emphasize how much pre-training improves performance on tasks with limited data. While we do not explicitly measure improvements in data efficiency in this paper, we emphasize that this is one of the primary benefits of the transfer learning paradigm.
As for inter-run variance, we find that for most tasks the standard deviation across runs is smaller than 1% of the task’s baseline score. Exceptions to this rule include CoLA, CB, and COPA, which are all low-resource tasks from the GLUE and SuperGLUE benchmarks. For example, on CB our baseline model had an average F1 score of 91.22 with a standard deviation of 3.237 (see Table 16), which may be partly due to the fact that CB’s validation set contains only 56 examples. Note that the GLUE and SuperGLUE scores are computed as the average of scores across the tasks comprising each benchmark. As a result, we caution that the high inter-run variance of CoLA, CB, and COPA can make it harder to compare models using the GLUE and SuperGLUE scores alone.
3.2. Architecture
While the Transformer was originally introduced with an encoder-decoder architecture, much modern work on transfer learning for NLP uses alternative architectures. In this section, we review and compare these architectural variants.
3.2.1. Model Structures

A major distinguishing factor for different architectures is the “mask” used by different attention mechanisms in the model. Recall that the self-attention operation in a Transformer takes a sequence as input and outputs a new sequence of the same length. Each entry of the output sequence is produced by computing a weighted average of entries of the input sequence. Specifically, let y_i refer to the ith element of the output sequence and x_j refer to the jth entry of the input sequence. y_i is computed as summation_j(w_i,j x_j), where w_i,j is the scalar weight produced by the self-attention mechanism as a function of xi and xj . The attention mask is then used to zero out certain weights in order to constrain which entries of the input can be attended to at a given output timestep. Diagrams of the masks we will consider are shown in Figure 3. For example, the causal mask (Figure 3, middle) sets any w_i,j to zero if j > i.
The first model structure we consider is an an encoder-decoder Transformer, which consists of two layer stacks: The encoder, which is fed an input sequence, and the decoder, which produces a new output sequence. A schematic of this architectural variant is shown in the left panel of Figure 4.

The encoder uses a “fully-visible” attention mask. Fully-visible masking allows a self-attention mechanism to attend to any entry of the input when producing each entry of its output. We visualize this masking pattern in Figure 3, left. This form of masking is appropriate when attending over a “prefix”, i.e. some context provided to the model that is later used when making predictions. BERT (Devlin et al., 2018) also uses a fully-visible masking pattern and appends a special “classification” token to the input. BERT’s output at the timestep corresponding to the classification token is then used to make a prediction for classifying the input sequence.
The self-attention operations in the Transformer’s decoder use a “causal” masking pattern. When producing the ith entry of the output sequence, causal masking prevents the model from attending to the jth entry of the input sequence for j > i. This is used during training so that the model can’t “see into the future” as it produces its output. An attention matrix for this masking pattern is shown in Figure 3, middle.
The decoder in an encoder-decoder Transformer is used to autoregressively produce an output sequence. That is, at each output timestep, a token is sampled from the model’s predicted distribution and the sample is fed back into the model to produce a prediction for the next output timestep, and so on. As such, a Transformer decoder (without an encoder) can be used as a language model (LM), i.e. a model trained solely for next-step prediction (Liu et al., 2018; Radford et al., 2018; Al-Rfou et al., 2019). This constitutes the second model structure we consider. A schematic of this architecture is shown in Figure 4, middle. In fact, early work on transfer learning for NLP used this architecture with a language modeling objective as a pre-training method (Radford et al., 2018).
Language models are typically used for compression or sequence generation (Graves, 2013). However, they can also be used in the text-to-text framework simply by concatenating the inputs and targets. As an example, consider the case of English to German translation: If we have a training datapoint with input sentence “That is good.” and target “Das ist gut.”, we would simply train the model on next-step prediction over the concatenated input sequence “translate English to German: That is good. target: Das ist gut.” If we wanted to obtain the model’s prediction for this example, the model would be fed the prefix“translate English to German: That is good. target:”and would be asked to generate the remainder of the sequence autoregressively. In this way, the model can predict an output sequence given an input, which satisfies the needs of text-to-text tasks. This approach was recently used to show that language models can learn to perform some text-to-text tasks without supervision (Radford et al., 2019).
A fundamental and frequently cited drawback of using a language model in the text-to-text setting is that causal masking forces the model’s representation of the ith entry of the input sequence to only depend on the entries up until i. To see why this is potentially disadvantageous, consider the text-to-text framework where the model is provided with a prefix/context before being asked to make predictions (e.g., the prefix is an English sentence and the model is asked to predict the German translation). With fully causal masking, the model’s representation of a prefix state can only depend on prior entries of the prefix. So, when predicting an entry of the output, the model will attend to a representation of the prefix that is unnecessarily limited. Similar arguments have been made against using a unidirectional recurrent neural network encoder in sequence-to-sequence models (Bahdanau et al., 2015).
This issue can be avoided in a Transformer-based language model simply by changing the masking pattern. Instead of using a causal mask, we use fully-visible masking during the prefix portion of the sequence. This masking pattern and a schematic of the resulting “prefix LM” (the third model structure we consider) are illustrated in the rightmost panels of Figures 3 and 4, respectively. In the English to German translation example mentioned above, fully-visible masking would be applied to the prefix “translate English to German: That is good. target:” and causal masking would be used during training for predicting the target “Das ist gut.” Using a prefix LM in the text-to-text framework was originally proposed by Liu et al. (2018). More recently, Dong et al. (2019) showed that this architecture is effective on a wide variety of text-to-text tasks. This architecture is similar to an encoder-decoder model with parameters shared across the encoder and decoder and with the encoder-decoder attention replaced with full attention across the input and target sequence.
We note that when following our text-to-text framework, the prefix LM architecture closely resembles BERT (Devlin et al., 2018) for classification tasks. To see why, consider an example from the MNLI benchmark where the premise is “I hate pigeons.”, the hypothesis is “My feelings towards pigeons are filled with animosity.” and the correct label is “entailment”. To feed this example into a language model, we would transform it into the sequence “mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. target: entailment”. In this case, the fully-visible prefix would correspond to the entire input sequence up to the word “target:”, which can be seen as being analogous to the “classification” token used in BERT. So, our model would have full visibility over the entire input, and then would be tasked with making a classification by outputting the word “entailment”. It is easy for the model to learn to output one of the valid class labels given the task prefix (“mnli” in this case). As such, the main difference between a prefix LM and the BERT architecture is that the classifier is simply integrated into the output layer of the Transformer decoder in the prefix LM.
3.2.2. Comparing Different Model Structures
In the interest of experimentally comparing these architectural variants, we would like each model we consider to be equivalent in some meaningful way. We might say that two models are equivalent if they either have the same number of parameters or they require roughly the same amount of computation to process a given (input-sequence, target-sequence) pair. Unfortunately, it is not possible to compare an encoder-decoder model to a language model architecture (comprising a single Transformer stack) according to both of these criteria at the same time. To see why, first note an encoder-decoder model with L layers in the encoder and L layers in the decoder has approximately the same number of parameters as a language model with 2L layers. However, the same L + L encoder-decoder model will have approximately the same computational cost as a language model with only L layers. This is a consequence of the fact that the L layers in the language model must be applied to both the input and output sequence, while the encoder is only applied to the input sequence and the decoder is only applied to the output sequence. Note that these equivalences are approximate—there are some extra parameters in the decoder due to the encoder-decoder attention and there are also some computational costs in the attention layers that are quadratic in the sequence lengths. In practice, however, we observed nearly identical step times for L-layer language models versus L + L-layer encoder-decoder models, suggesting a roughly equivalent computational cost. Further, for the model sizes we consider, the number of parameters in the encoder-decoder attention layers is about 10% of the total parameter count, so we make the simplifying assumption that an L + L-layer encoder-decoder model has the same number of parameters as an 2L-layer language model. To provide a reasonable means of comparison, we consider multiple configurations for our encoder-decoder model. We will refer to the number of layers and parameters in a BERT_BASE-sized layer stack as L and P, respectively. We will use M to refer to the number of FLOPs required for an L + L-layer encoder-decoder model or L-layer decoder-only model to process a given input-target pair. In total, we will compare:
• An encoder-decoder model with L layers in the encoder and L layers in the decoder. This model has 2P parameters and a computation cost of M FLOPs.
• An equivalent model, but with parameters shared across the encoder and decoder, resulting in P parameters and an M-FLOP computational cost.
• An encoder-decoder model with L/2 layers each in the encoder and decoder, giving P parameters and an M/2-FLOP cost.
• A decoder-only language model with L layers and P parameters and a resulting computational cost of M FLOPs.
• A decoder-only prefix LM with the same architecture (and thus the same number of parameters and computational cost), but with fully-visible self-attention over the input.
3.2.3. Objectives
As an unsupervised objective, we will consider both a basic language modeling objective as well as our baseline denoising objective described in Section 3.1.4. We include the language modeling objective due to its historic use as a pre-training objective (Dai and Le, 2015; Ramachandran et al., 2016; Howard and Ruder, 2018; Radford et al., 2018; Peters et al., 2018) as well as its natural fit for the language model architectures we consider. For models that ingest a prefix before making predictions (the encoder-decoder model and prefix LM), we sample a span of text from our unlabeled data set and choose a random point to split it into prefix and target portions. For the standard language model, we train the model to predict the entire span from beginning to end. Our unsupervised denoising objective is designed for text-to-text models; to adapt it for use with a language model we concatenate the inputs and targets as described in Section 3.2.1.
3.2.4. Results
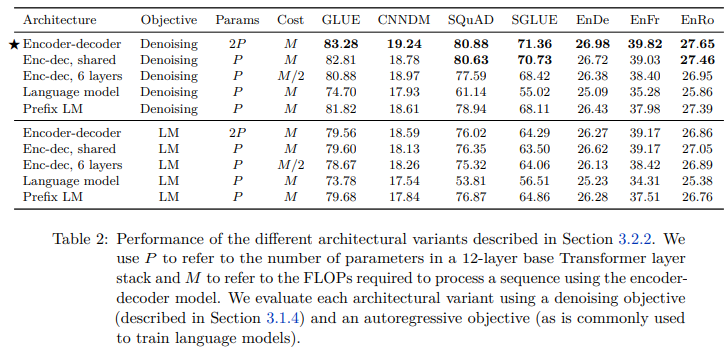
The scores achieved by each of the architectures we compare are shown in Table 2. For all tasks, the encoder-decoder architecture with the denoising objective performed best. This variant has the highest parameter count (2P) but the same computational cost as the P-parameter decoder-only models. Surprisingly, we found that sharing parameters across the encoder and decoder performed nearly as well. In contrast, halving the number of layers in the encoder and decoder stacks significantly hurt performance. Concurrent work (Lan et al., 2019) also found that sharing parameters across Transformer blocks can be an effective means of lowering the total parameter count without sacrificing much performance. XLNet also bears some resemblance to the shared encoder-decoder approach with a denoising objective (Yang et al., 2019). We also note that the shared parameter encoder-decoder outperforms the decoder-only prefix LM, suggesting that the addition of an explicit encoder-decoder attention is beneficial. Finally, we confirm the widely-held conception that using a denoising objective always results in better downstream task performance compared to a language modeling objective. This observation has been previously made by Devlin et al. (2018), Voita et al. (2019), and Lample and Conneau (2019) among others. We undertake a more detailed exploration of unsupervised objectives in the following section.
3.3. Unsupervised Objectives
The choice of unsupervised objective is of central importance as it provides the mechanism through which the model gains general-purpose knowledge to apply to downstream tasks. This has led to the development of a wide variety of pre-training objectives (Dai and Le, 2015; Ramachandran et al., 2016; Radford et al., 2018; Devlin et al., 2018; Yang et al., 2019; Liu et al., 2019b; Wang et al., 2019a; Song et al., 2019; Dong et al., 2019; Joshi et al., 2019). In this section, we perform a procedural exploration of the space of unsupervised objectives. In many cases, we will not replicate an existing objective exactly—some will be modified to fit our text-to-text encoder-decoder framework and, in other cases, we will use objectives that combine concepts from multiple common approaches.
Overall, all of our objectives ingest a sequence of token IDs corresponding to a tokenized span of text from our unlabeled text data set. The token sequence is processed to produce a (corrupted) input sequence and a corresponding target. Then, the model is trained as usual with maximum likelihood to predict the target sequence. We provide illustrative examples of many of the objectives we consider in Table 3.

3.3.1. Disparate High-level Approaches
To begin with, we compare three techniques that are inspired by commonly-used objectives but differ significantly in their approach. First, we include a basic “prefix language modeling” objective as was used in Section 3.2.3. This technique splits a span of text into two components, one to use as inputs to the encoder and the other to use as a target sequence to be predicted by the decoder. Second, we consider an objective inspired by the “masked language modeling” (MLM) objective used in BERT (Devlin et al., 2018). MLM takes a span of text and corrupts 15% of the tokens. 90% of the corrupted tokens are replaced with a special mask token and 10% are replaced with a random token. Since BERT is an encoder-only model, its goal during pre-training is to reconstruct masked tokens at the output of the encoder. In the encoder-decoder case, we simply use the entire uncorrupted sequence as the target. Note that this differs from our baseline objective, which uses only the corrupted tokens as targets; we compare these two approaches in Section 3.3.2. Finally, we also consider a basic deshuffling objective as used e.g. in (Liu et al., 2019a) where it was applied to a denoising sequential autoencoder. This approach takes a sequence of tokens, shuffles it, and then uses the original deshuffled sequence as a target. We provide examples of the inputs and targets for these three methods in the first three rows of Table 3.
The performance of these three objectives is shown in Table 4. Overall, we find that the BERT-style objective performs best, though the prefix language modeling objective attains similar performance on the translation tasks. Indeed, the motivation for the BERT objective was to outperform language model-based pre-training. The deshuffling objective performs considerably worse than both prefix language modeling and the BERT-style objective.

3.3.2. Simplifying the BERT Objective
Based on the results in the prior section, we will now focus on exploring modifications to the BERT-style denoising objective. This objective was originally proposed as a pre-training technique for an encoder-only model trained for classification and span prediction. As such, it may be possible to modify it so that it performs better or is more efficient in our encoder-decoder text-to-text setup.
First, we consider a simple variant of the BERT-style objective where we don’t include the random token swapping step. The resulting objective simply replaces 15% of the tokens in the input with a mask token and the model is trained to reconstruct the original uncorrupted sequence. A similar masking objective was used by Song et al. (2019) where it was referred to as “MASS”, so we call this variant the “MASS-style” objective.
Second, we were interested to see if it was possible to avoid predicting the entire uncorrupted text span since this requires self-attention over long sequences in the decoder. We consider two strategies to achieve this: First, instead of replacing each corrupted token with a mask token, we replace the entirety of each consecutive span of corrupted tokens with a unique mask token. Then, the target sequence becomes the concatenation of the “corrupted” spans, each prefixed by the mask token used to replace it in the input. This is the pre-training objective we use in our baseline, described in Section 3.1.4. Second, we also consider a variant where we simply drop the corrupted tokens from the input sequence completely and task the model with reconstructing the dropped tokens in order. Examples of these approaches are shown in the fifth and sixth rows of Table 3.
An empirical comparison of the original BERT-style objective to these three alternatives is shown in Table 5. We find that in our setting, all of these variants perform similarly. The only exception was that dropping corrupted tokens completely produced a small improvement in the GLUE score thanks to a significantly higher score on CoLA (60.04, compared to our baseline average of 53.84, see Table 16). This may be due to the fact that CoLA involves classifying whether a given sentence is grammatically and syntactically acceptable, and being able to determine when tokens are missing is closely related to detecting acceptability. However, dropping tokens completely performed worse than replacing them with sentinel tokens on SuperGLUE. The two variants that do not require predicting the full original sequence (“replace corrupted spans” and “drop corrupted spans”) are both potentially attractive since they make the target sequences shorter and consequently make training faster. Going forward, we will explore variants where we replace corrupted spans with sentinel tokens and only predict the corrupted tokens (as in our baseline objective).

3.3.3. Varying the Corruption Rate
So far, we have been corrupting 15% of the tokens, the value used in BERT (Devlin et al., 2018). Again, since our text-to-text framework differs from BERT’s, we are interested to see if a different corruption rate works better for us. We compare corruption rates of 10%, 15%, 25%, and 50% in Table 6. Overall, we find that the corruption rate had a limited effect on the model’s performance. The only exception is that the largest corruption rate we consider (50%) results in a significant degradation of performance on GLUE and SQuAD. Using a larger corruption rate also results in longer targets, which can potentially slow down training. Based on these results and the historical precedent set by BERT, we will use a corruption rate of 15% going forward.

3.3.4. Corrupting Spans
We now turn towards the goal of speeding up training by predicting shorter targets. The approach we have used so far makes an i.i.d. decision for each input token as to whether to corrupt it or not. When multiple consecutive tokens have been corrupted, they are treated as a “span” and a single unique mask token is used to replace the entire span. Replacing entire spans with a single token results in unlabeled text data being processed into shorter sequences. Since we are using an i.i.d. corruption strategy, it is not always the case that a significant number of corrupted tokens appear consecutively. As a result, we might obtain additional speedup by specifically corrupting spans of tokens rather than corrupting individual tokens in an i.i.d. manner. Corrupting spans was also previously considered as a pre-training objective for BERT, where it was found to improve performance (Joshi et al., 2019).
To test this idea, we consider an objective that specifically corrupts contiguous, randomly spaced spans of tokens. This objective can be parametrized by the proportion of tokens to be corrupted and the total number of corrupted spans. The span lengths are then chosen randomly to satisfy these specified parameters. For example, if we are processing a sequence of 500 tokens and we have specified that 15% of tokens should be corrupted and that there should be 25 total spans, then the total number of corrupted tokens would be 500×0.15 = 75 and the average span length would be 75/25 = 3. Note that given the original sequence length and corruption rate, we can equivalently parametrize this objective either by the average span length or the total number of spans.
We compare the span-corruption objective to the i.i.d-corruption objective in Table 7. We use a corruption rate of 15% in all cases and compare using average span lengths of 2, 3, 5 and 10. Again, we find a limited difference between these objectives, though the version with an average span length of 10 slightly underperforms the other values in some cases. We also find in particular that using an average span length of 3 slightly (but significantly) outperforms the i.i.d. objective on most non-translation benchmarks. Fortunately, the span-corruption objective also provides some speedup during training compared to the i.i.d. noise approach because span corruption produces shorter sequences on average.

3.3.5. Discussion
Figure 5 shows a flow chart of the choices made during our exploration of unsupervised objectives. Overall, the most significant difference in performance we observed was that denoising objectives outperformed language modeling and deshuffling for pre-training. We did not observe a remarkable difference across the many variants of the denoising objectives we explored. However, different objectives (or parameterizations of objectives) can lead to different sequence lengths and thus different training speeds. This implies that choosing among the denoising objectives we considered here should mainly be done according to their computational cost. Our results also suggest that additional exploration of objectives similar to the ones we consider here may not lead to significant gains for the tasks and model we consider. Instead, it may be fortuitous to explore entirely different ways of leveraging unlabeled data.

3.4. Pre-training Data set
Like the unsupervised objective, the pre-training data set itself is a crucial component of the transfer learning pipeline. However, unlike objectives and benchmarks, new pre-training data sets are usually not treated as significant contributions on their own and are often not released alongside pre-trained models and code. Instead, they are typically introduced in the course of presenting a new method or model. As a result, there has been relatively little comparison of different pre-training data sets as well as a lack of a “standard” data set used for pre-training. Some recent notable exceptions (Baevski et al., 2019; Liu et al., 2019c; Yang et al., 2019) have compared pre-training on a new large (often Common Crawl-sourced) data set to using a smaller preexisting data set (often Wikipedia). To probe more deeply into the impact of the pre-training data set on performance, in this section we compare variants of our C4 data set and other potential sources of pre-training data. We release all of the C4 data set variants we consider as part of TensorFlow Datasets.11
3.4.1. Unlabeled Data sets
In creating C4, we developed various heuristics to filter the web-extracted text from Common Crawl (see Section 2.2 for a description). We are interested in measuring whether this filtering results in improved performance on downstream tasks, in addition to comparing it to other filtering approaches and common pre-training data sets. Towards this end, we compare the performance of our baseline model after pre-training on the following data sets:
C4
As a baseline, we first consider pre-training on our proposed unlabeled data set as described in Section 2.2.
Unfiltered C4
To measure the effect of the heuristic filtering we used in creating C4 (deduplication, removing bad words, only retaining sentences, etc.), we also generate an alternate version of C4 that forgoes this filtering. Note that we still use langdetect to extract English text. As a result, our “unfiltered” variant still includes some filtering because langdetect sometimes assigns a low probability to non-natural English text.
RealNews-like
Recent work has used text data extracted from news websites (Zellers et al., 2019; Baevski et al., 2019). To compare to this approach, we generate another unlabeled data set by additionally filtering C4 to only include content from one of the domains used in the “RealNews” data set (Zellers et al., 2019). Note that for ease of comparison, we retain the heuristic filtering methods used in C4; the only difference is that we have ostensibly omitted any non-news content.
WebText-like
Similarly, the WebText data set (Radford et al., 2019) only uses content from webpages that were submitted to the content aggregation website Reddit and received a “score” of at least 3. The score for a webpage submitted to Reddit is computed based on the proportion of users who endorse (upvote) or oppose (downvote) the webpage. The idea behind using the Reddit score as a quality signal is that users of the site would only upvote high-quality text content. To generate a comparable data set, we first tried removing all content from C4 that did not originate from a URL that appeared in the list prepared by the OpenWebText effort.12 However, this resulted in comparatively little content—only about 2 GB—because most pages never appear on Reddit. Recall that C4 was created based on a single month of Common Crawl data. To avoid using a prohibitively small data set, we therefore downloaded 12 months of data from Common Crawl from August 2018 to July 2019, applied our heuristic filtering for C4, then applied the Reddit filter. This produced a 17 GB WebText-like data set, which is of comparable size to the original 40GB WebText data set (Radford et al., 2019).
Wikipedia
The website Wikipedia consists of millions of encyclopedia articles written collaboratively. The content on the site is subject to strict quality guidelines and therefore has been used as a reliable source of clean and natural text. We use the English Wikipedia text data from TensorFlow Datasets,13 which omits any markup or reference sections from the articles.
Wikipedia + Toronto Books Corpus
A drawback of using pre-training data from Wikipedia is that it represents only one possible domain of natural text (encyclopedia articles). To mitigate this, BERT (Devlin et al., 2018) combined data from Wikipedia with the Toronto Books Corpus (TBC) (Zhu et al., 2015). TBC contains text extracted from eBooks, which represents a different domain of natural language. BERT’s popularity has led to the Wikipedia + TBC combination being used in many subsequent works.
The results achieved after pre-training on each of these data sets is shown in Table 8. A first obvious takeaway is that removing the heuristic filtering from C4 uniformly degrades performance and makes the unfiltered variant perform the worst in every task. Beyond this, we found that in some cases a pre-training data set with a more constrained domain outperformed the diverse C4 data set. For example, using the Wikipedia + TBC corpus produced a SuperGLUE score of 73.24, beating our baseline’s score (using C4) of 71.36. This is almost entirely attributable to a boost in performance from 25.78 (baseline, C4) to 50.93 (Wikipedia + TBC) on the Exact Match score for MultiRC (see Table 16). MultiRC is a reading comprehension data set whose largest source of data comes from fiction books, which is exactly the domain covered by TBC. Similarly, using the RealNews-like data set for pre-training conferred an increase from 68.16 to 73.72 on the Exact Match score for ReCoRD, a data set that measures reading comprehension on news articles. As a final example, using data from Wikipedia produced significant (but less dramatic) gains on SQuAD, which is a question-answering data set with passages sourced from Wikipedia. Similar observations have been made in prior work, e.g. Beltagy et al. (2019) found that pre-training BERT on text from research papers improved its performance on scientific tasks. The main lesson behind these findings is that pre-training on in-domain unlabeled data can improve performance on downstream tasks. This is unsurprising but also unsatisfying if our goal is to pre-train a model that can rapidly adapt to language tasks from arbitrary domains. Liu et al. (2019c) also observed that pre-training on a more diverse data set yielded improvements on downstream tasks. This observation also motivates the parallel line of research on domain adaptation for natural language processing; for surveys of this field see e.g. Ruder (2019); Li (2012).
A drawback to only pre-training on a single domain is that the resulting data sets are often substantially smaller. Similarly, while the WebText-like variant performed as well or better than the C4 data set in our baseline setting, the Reddit-based filtering produced a data set that was about 40× smaller than C4 despite being based on 12× more data from Common Crawl. Note, however, that in our baseline setup we only pre-train on 2^35 ≈ 34B tokens, which is only about 8 times larger than the smallest pre-training data set we consider. We investigate at what point using a smaller pre-training data sets poses an issue in the following section.

3.4.2. Pre-training Data set Size
The pipeline we use to create C4 was designed to be able to create extremely large pretraining data sets. The access to so much data allows us to pre-train our models without repeating examples. It is not clear whether repeating examples during pre-training would be helpful or harmful to downstream performance because our pre-training objective is itself stochastic and can help prevent the model from seeing the same exact data multiple times.
To test the effect of limited unlabeled data set sizes, we pre-trained our baseline model on artificially truncated versions of C4. Recall that we pre-train our baseline model on 2^35 ≈ 34B tokens (a small fraction of the total size of C4). We consider training on truncated variants of C4 consisting of 2^29 , 2^27 , 2^25 and 2^23 tokens. These sizes correspond to repeating the data set 64, 256, 1,024, and 4,096 times respectively over the course of pre-training.
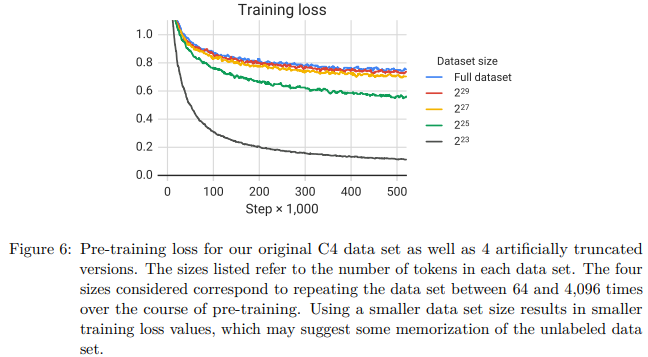
The resulting downstream performance is shown in Table 9. As expected, performance degrades as the data set size shrinks. We suspect this may be due to the fact that the model begins to memorize the pre-training data set. To measure if this is true, we plot the training loss for each of these data set sizes in Figure 6. Indeed, the model attains significantly smaller training losses as the size of the pre-training data set shrinks, suggesting possible memorization. Baevski et al. (2019) similarly observed that truncating the pre-training data set size can degrade downstream task performance.
We note that these effects are limited when the pre-training data set is repeated only 64 times. This suggests that some amount of repetition of pre-training data might not be harmful. However, given that additional pre-training can be beneficial (as we will show in Section 3.6) and that obtaining additional unlabeled data is cheap and easy, we suggest using large pre-training data sets whenever possible. We also note that this effect may be more pronounced for larger model sizes, i.e. a bigger model may be more prone to overfitting to a smaller pre-training data set.

3.5. Training Strategy
So far we have considered the setting where all parameters of a model are pre-trained on an unsupervised task before being fine-tuned on individual supervised tasks. While this approach is straightforward, various alternative methods for training the model on downstream/supervised tasks have been proposed. In this section, we compare different schemes for fine-tuning the model in addition to the approach of training the model simultaneously on multiple tasks.
3.5.1. Fine-tuning Methods
It has been argued that fine-tuning all of the model’s parameters can lead to suboptimal results, particularly on low-resource tasks (Peters et al., 2019). Early results on transfer learning for text classification tasks advocated fine-tuning only the parameters of a small classifier that was fed sentence embeddings produced by a fixed pre-trained model (Subramanian et al., 2018; Kiros et al., 2015; Logeswaran and Lee, 2018; Hill et al., 2016; Conneau et al., 2017). This approach is less applicable to our encoder-decoder model because the entire decoder must be trained to output the target sequences for a given task. Instead, we focus on two alternative fine-tuning approaches that update only a subset of the parameters of our encoder-decoder model.
The first, “adapter layers” (Houlsby et al., 2019; Bapna et al., 2019), is motivated by the goal of keeping most of the original model fixed while fine-tuning. Adapter layers are additional dense-ReLU-dense blocks that are added after each of the preexisting feed-forward networks in each block of the Transformer. These new feed-forward networks are designed so that their output dimensionality matches their input. This allows them to be inserted into the network with no additional changes to the structure or parameters. When finetuning, only the adapter layer and layer normalization parameters are updated. The main hyperparameter of this approach is the inner dimensionality d of the feed-forward network, which changes the number of new parameters added to the model. We experiment with various values for d.
The second alternative fine-tuning method we consider is “gradual unfreezing” (Howard and Ruder, 2018). In gradual unfreezing, more and more of the model’s parameters are finetuned over time. Gradual unfreezing was originally applied to a language model architecture consisting of a single stack of layers. In this setting, at the start of fine-tuning only the parameters of the final layer are updated, then after training for a certain number of updates the parameters of the second-to-last layer are also included, and so on until the entire network’s parameters are being fine-tuned. To adapt this approach to our encoder-decoder model, we gradually unfreeze layers in the encoder and decoder in parallel, starting from the top in both cases. Since the parameters of our input embedding matrix and output classification matrix are shared, we update them throughout fine-tuning. Recall that our baseline model consists of 12 layers each in the encoder and decoder and is fine-tuned for 2^18 steps. As such, we subdivide the fine-tuning process into 12 episodes of 2^18/12 steps each and train from layers 12 − n to 12 in the nth episode. We note that Howard and Ruder (2018) suggested fine-tuning an additional layer after each epoch of training. However, since our supervised data sets vary so much in size and since some of our downstream tasks are actually mixtures of many tasks (GLUE and SuperGLUE), we instead adopt the simpler strategy of fine-tuning an additional layer after every 2^18/12 steps.
A comparison of the performance of these fine-tuning approaches is shown in Table 10. For adapter layers, we report the performance using an inner dimensionality d of 32, 128, 512, 2048. Pursuant with past results (Houlsby et al., 2019; Bapna et al., 2019) we find that lower-resource tasks like SQuAD work well with a small value of d whereas higher resource tasks require a large dimensionality to achieve reasonable performance. This suggests that adapter layers could be a promising technique for fine-tuning on fewer parameters as long as the dimensionality is scaled appropriately to the task size. Note that in our case we treat GLUE and SuperGLUE each as a single “task” by concatenating their constituent data sets, so although they comprise some low-resource data sets the combined data set is large enough that it necessitates a large value of d. We found that gradual unfreezing caused a minor degradation in performance across all tasks, though it did provide some speedup during fine-tuning. Better results may be attainable by more carefully tuning the unfreezing schedule.

3.5.2. Multi-Task Learning
So far, we have been pre-training our model on a single unsupervised learning task before fine-tuning it individually on each downstream task. An alternative approach, called “multitask learning” (Ruder, 2017; Caruana, 1997), is to train the model on multiple tasks at a time. This approach typically has the goal of training a single model that can simultaneously perform many tasks at once, i.e. the model and most of its parameters are shared across all tasks. We relax this goal somewhat and instead investigate methods for training on multiple tasks at once in order to eventually produce separate parameter settings that perform well on each individual task. For example, we might train a single model on many tasks, but when reporting performance we are allowed to select a different checkpoint for each task. This loosens the multi-task learning framework and puts it on more even footing compared to the pre-train-then-fine-tune approach we have considered so far. We also note that in our unified text-to-text framework, “multi-task learning” simply corresponds to mixing data sets together. It follows that we can still train on unlabeled data when using multi-task learning by treating the unsupervised task as one of the tasks being mixed together. In contrast, most applications of multi-task learning to NLP add task-specific classification networks or use different loss functions for each task (Liu et al., 2019b).
As pointed out by Arivazhagan et al. (2019), an extremely important factor in multi-task learning is how much data from each task the model should be trained on. Our goal is to not under- or over-train the model—that is, we want the model to see enough data from a given task that it can perform the task well, but not to see so much data that it memorizes the training set. How exactly to set the proportion of data coming from each task can depend on various factors including data set sizes, the “difficulty” of learning the task (i.e. how much data the model must see before being able to perform the task effectively), regularization, etc. An additional issue is the potential for “task interference” or “negative transfer”, where achieving good performance on one task can hinder performance on another. Given these concerns, we begin by exploring various strategies for setting the proportion of data coming from each task. A similar exploration was performed by Wang et al. (2019a).
Examples-proportional mixing
A major factor in how quickly a model will overfit to a given task is the task’s data set size. As such, a natural way to set the mixing proportions is to sample in proportion to the size of each task’s data set. This is equivalent to concatenating the data sets for all tasks and randomly sampling examples from the combined data set. Note, however, that we are including our unsupervised denoising task, which uses a data set that is orders of magnitude larger than every other task’s. It follows that if we simply sample in proportion to each data set’s size, the vast majority of the data the model sees will be unlabeled, and it will undertrain on all of the supervised tasks. Even without the unsupervised task, some tasks (e.g. WMT English to French) are so large that they would similarly crowd out most of the batches. To get around this issue, we set an artificial “limit” on the data set sizes before computing the proportions. Specifically, if the number of examples in each of our N task’s data sets is e_n, n ∈ {1, . . . , N} then we set probability of sampling an example from the mth task during training to r_m = min(e_m, K)/ Sum min(e_n, K) where K is the artificial data set size limit.
Temperature-scaled mixing
An alternative way of mitigating the huge disparity between data set sizes is to adjust the “temperature” of the mixing rates. This approach was used by multilingual BERT to ensure that the model was sufficiently trained on lowresource languages.14 To implement temperature scaling with temperature T, we raise each task’s mixing rate rm to the power of 1⁄T and renormalize the rates so that they sum to 1. When T = 1, this approach is equivalent to examples-proportional mixing and as T increases the proportions become closer to equal mixing. We retain the data set size limit K (applied to obtain r_m before temperature scaling) but set it to a large value of K = 2^21. We use a large value of K because increasing the temperature will decrease the mixing rate of the largest data sets.
Equal mixing
In this case, we sample examples from each task with equal probability. Specifically, each example in each batch is sampled uniformly at random from one of the data sets we train on. This is most likely a suboptimal strategy, as the model will overfit quickly on low-resource tasks and underfit on high-resource tasks. We mainly include it as a point of reference of what might go wrong when the proportions are set suboptimally.
To compare these mixing strategies on equal footing with our baseline pre-train-then-fine-tune results, we train multi-task models for the same total number of steps: 2 19 + 218 = 786,432. The results are shown in Table 11.
In general, we find that multi-task training underperforms pre-training followed by fine-tuning on most tasks. The “equal” mixing strategy in particular results in dramatically degraded performance, which may be because the low-resource tasks have overfit, the highresource tasks have not seen enough data, or the model has not seen enough unlabeled data to learn general-purpose language capabilities. For examples-proportional mixing, we find that for most tasks there is a “sweet spot” for K where the model obtains the best performance, and larger or smaller values of K tend to result in worse performance. The exception (for the range of K values we considered) was WMT English to French translation, which is such a high-resource task that it always benefits from a higher mixing proportion. Finally, we note that temperature-scaled mixing also provides a means of obtaining reasonable performance from most tasks, with T = 2 performing the best in most cases. The finding that a multi-task model is outperformed by separate models trained on each individual task has previously been observed e.g. by Arivazhagan et al. (2019) and McCann et al. (2018), though it has been shown that the multi-task setup can confer benefits across very similar tasks Liu et al. (2019b); Ratner et al. (2018). In the following section, we explore ways to close the gap between multi-task training and the pre-train-then-fine-tune approach.

3.5.3. Combining Multi-Task Learning with Fine-Tuning
Recall that we are studying a relaxed version of multi-task learning where we train a single model on a mixture of tasks but are allowed to evaluate performance using different parameter settings (checkpoints) for the model. We can extend this approach by considering the case where the model is pre-trained on all tasks at once but is then fine-tuned on the individual supervised tasks. This is the method used by the “MT-DNN” (Liu et al., 2015, 2019b), which achieved state-of-the-art performance on GLUE and other benchmarks when it was introduced. We consider three variants of this approach: In the first, we simply pre-train the model on an examples-proportional mixture with an artificial data set size limit of K = 2^19 before fine-tuning it on each individual downstream task. This helps us measure whether including the supervised tasks alongside the unsupervised objective during pre-training gives the model some beneficial early exposure to the downstream tasks. We might also hope that mixing in many sources of supervision could help the pre-trained model obtain a more general set of “skills” (loosely speaking) before it is adapted to an individual task.
To measure this directly, we consider a second variant where we pre-train the model on the same examples-proportional mixture (with K = 2^19) except that we omit one of the downstream tasks from this pre-training mixture. Then, we fine-tune the model on the task that was left out during pre-training. We repeat this for each of the downstream tasks we consider. We call this approach “leave-one-out” multi-task training. This simulates the real-world setting where a pre-trained model is fine-tuned on a task it had not seen during pre-training. Note that multi-task pre-training provides a diverse mixture of supervised tasks. Since other fields (e.g. computer vision (Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014)) use a supervised data set for pre-training, we were interested to see whether omitting the unsupervised task from the multi-task pre-training mixture still produced good results.
For our third variant we therefore pre-train on an examples-proportional mixture of all of the supervised tasks we consider with K = 2^19. In all of these variants, we follow our standard procedure of pre-training for 2^19 steps before fine-tuning for 2^18 steps.
We compare the results of these approaches in Table 12. For comparison, we also include results for our baseline (pre-train then fine-tune) and for standard multi-task learning (without fine-tuning) on an examples-proportional mixture with K = 2^19. We find that fine-tuning after multi-task pre-training results in comparable performance to our baseline. This suggests that using fine-tuning after multi-task learning can help mitigate some of the trade-offs between different mixing rates described in Section 3.5.2. Interestingly, the performance of “leave-one-out” training was only slightly worse, suggesting that a model that was trained on a variety of tasks can still adapt to new tasks (i.e. multi-task pretraining might not result in a dramatic task interference). Finally, supervised multi-task pre-training performed significantly worse in every case except for the translation tasks. This could suggest that the translation tasks benefit less from (English) pre-training, whereas unsupervised pre-training is an important factor in the other tasks.

3.6. Scaling
The “bitter lesson” of machine learning research argues that general methods that can leverage additional computation ultimately win out against methods that rely on human expertise (Sutton, 2019; Hestness et al., 2017; Shazeer et al., 2017; Jozefowicz et al., 2016; Mahajan et al., 2018; Shazeer et al., 2018, 2017; Huang et al., 2018b; Keskar et al., 2019a). Recent results suggest that this may hold true for transfer learning in NLP (Liu et al., 2019c; Radford et al., 2019; Yang et al., 2019; Lan et al., 2019), i.e. it has repeatedly been shown that scaling up produces improved performance compared to more carefully-engineered methods. However, there are a variety of possible ways to scale, including using a bigger model, training the model for more steps, and ensembling. In this section, we compare these different approaches by addressing the following premise: “You were just given 4× more compute. How should you use it?”
We start with our baseline model, which has 220M parameters and is pre-trained and fine-tuned for 2^19 and 2^18 steps respectively. The encoder and decoder are both sized similarly to “BERT_BASE”. To experiment with increased model size, we follow the guidelines of “BERT_LARGE” Devlin et al. (2018) and use d_ff = 4096, d_model = 1024, d_kv = 64 and 16-head attention mechanisms. We then generate two variants with 16 and 32 layers each in the encoder and decoder, producing models with 2× and 4× as many parameters as our original model. These two variants also have a roughly 2× and 4× the computational cost. Using our baseline and these two larger models, we consider three ways of using 4× as much computation: Training for 4× as many steps, training for 2× as many steps with the 2× bigger model, and training the 4× bigger model for the “baseline” number of training steps. When we increase the training steps, we scale both the pre-train and fine-tune steps for simplicity. Note that when increasing the number of pre-training steps, we are effectively including more pre-training data as C4 is so large that we do not complete one pass over the data even when training for 2^23 steps.
An alternative way for the model to see 4× as much data is to increase the batch size by a factor of 4. This can potentially result in faster training due to more efficient parallelization. However, training with a 4× larger batch size can yield a different outcome than training for 4× as many steps (Shallue et al., 2018). We include an additional experiment where we train our baseline model with a 4× larger batch size to compare these two cases.
It is common practice on many of the benchmarks we consider to eke out additional performance by training and evaluating using an ensemble of models. This provides an orthogonal way of using additional computation. To compare other scaling methods to ensembling, we also measure the performance of an ensemble of 4 separately pre-trained and fine-tuned models. We average the logits across the ensemble before feeding them into the output softmax nonlinearity to obtain an aggregate prediction. Instead of pre-training 4 separate models, a cheaper alternative is to take a single pre-trained model and produce 4 separate fine-tuned versions. While this does not use our entire 4× computational budget, we also include this method to see if it produces competitive performance to the other scaling methods.

The performance achieved after applying these various scaling methods is shown in Table 13. Unsurprisingly, increasing the training time and/or model size consistently improves the baseline. There was no clear winner between training for 4× as many steps or using a 4× larger batch size, though both were beneficial. In general, increasing the model size resulted in an additional bump in performance compared to solely increasing the training time or batch size. We did not observe a large difference between training a 2× bigger model for 2× as long and training a 4× bigger model on any of the tasks we studied. This suggests that increasing the training time and increasing the model size can be complementary means of improving performance. Our results also suggest that ensembling provides an orthogonal and effective means of improving performance through scale. In some tasks (CNN/DM, WMT English to German, and WMT English to Romanian), ensembling 4 completely separately trained models significantly outperformed every other scaling approach. Ensembling models that were pre-trained together but fine-tuned separately also gave a substantial performance increase over the baseline, which suggests a cheaper means of improving performance. The only exception was SuperGLUE, where neither ensembling approach significantly improved over the baseline.
We note that different scaling methods have different trade-offs that are separate from their performance. For example, using a larger model can make downstream fine-tuning and inference more expensive. In contrast, the cost of pre-training a small model for longer is effectively amortized if it is applied to many downstream tasks. Separately, we note that ensembling N separate models has a similar cost to using a model that has an N× higher computational cost. As a result, some consideration for the eventual use of the model is important when choosing between scaling methods.
'*NLP > NLP_Paper' 카테고리의 다른 글