-
How to Successfully Run a LLM Fine-Tuning ProjectResearch/NLP_reference 2024. 9. 7. 11:36
When should you opt for fine-tuning, and when is in-context learning the better choice? How do you kickstart the process, and how do these methods fit into the bigger picture? What techniques are readily available for you to implement?
In this post, we’re diving into the fine-tuning process for pretrained models, explore different fine-tuning methods, and provide a comparison of the latest state-of-the-art techniques.
Table of Contents:
- Getting to the basics of Fine-Tuning
- Fine-Tuning vs. In-Context Learning (Retrieval Augmented Generation)
- State-of-the-Art Training Techniques
- Conclusion
Getting to the basics of Fine-Tuning
The Power of Finetuning
Finetuning is the key to transforming a general-purpose model into a specialized one. For example, it’s what allowed GPT-3 to evolve into the widely recognized ChatGPT, making it behave more like a chatbot.
Below, you’ll find an overview of nine compelling reasons why you should consider finetuning your own Language Model (LLM).
To keep it concise, let’s summarize them into four distinct advantages:
- Privacy: data stay on-premises or in a VPC, prevent leakage and regulatory breaches (e.g., GDPR).
- Reliability: reduce hallucinations, enhance consistency, mitigate bias and filter out unwanted information.
- Cost effective performance: maintain control over uptime, reduce latency, lower the cost per request.
- Transparency: gain greater control and ensure increased transparency in model behavior.

9 Reasons to Train Your own LLM. Source There are several fine-tuning methods to adapt large language models for specific tasks, including:
- In-Context Learning/Retrieval Augemented Generation,
- Instruction Learning,
- Reinforcement Learning from Human Feedback (RLHF).
Data preparation is key to success
Running a fine-tuning project is an iterative process that involves multiple cycles of data preparation, training, and evaluation.

Iterative process of a fine-tuning project. Source While the training and evaluation phases often follow a similar pattern for each iteration, it’s in the data preparation step that you can truly make a difference.
What Kind of Data Do You Need?
To fine-tune your model effectively, the best practices involve using high-quality, diverse, and real data. Research “Less Is More for Alignment” shows that creating a high-quality, low-quantity (~1000 samples) dataset can be sufficient to achieve a well-performing model.

Best pratices when creating your data set. Source There are several ways to create an instruction dataset, including:
- Using an existing dataset and converting it into an instruction dataset, e.g., FLAN
- Use existing LLMs to create synthetically instruction datasets, e.g., Alpaca
- Use Humans to create instructions datasets, e.g., Dolly.
Below is a comparaison of each method, so you can select the right method depends on your project’s unique demands and the trade-offs between ease, cost, time, and data quality.

Comparaison of dataset creation method. Image by author. Another advice is when you start finetuning, narrow down and choose a single task to enhance your model. For example, you can fine-tune a model for coding, text summarization, information extraction, text generation, or answering questions.
Once your task is clear, prepare a instruction dataset of ~ 1000 input and output pairs for that task. Start finetuning a small LLM with this data to test and validate the dataset. This helps you understand its impacts and also you can run the process easily and quicker on a free Google Colab instance.
If you’re satisfied with the results from fine-tuning a smaller LLM, you can confidently scale up. Move on to fine-tuning a larger, more robust Language Model that aligns with the scope and complexity of your task.
Instruction Fine-Tuning vs. In-Context Learning (Retrieval Augmented Generation)
One of the most common questions is about when it’s appropriate to use fine-tuning vs. a different approach to model customization (for example: Retrieval Augmented Generation RAG).
My personal take is choose RAG when you need to prototype quickly or when you simply want the LLM to answer questions about your data, without the need to enhance the LLM’s task abilities. Additionally, RAG is suitable when your data can fit within the context window.
However, if your goal is to enhance the LLM’s capabilities for domain-specific tasks, especially when specific terminologies are unique to your data, such as Finance, Legal etc. RAG might not be the best choice. In such cases, finetuning approach is more suitable. You will have greater control over the model and can further train the model with substantial corpus of data that exceeds the context window’s limitations.
I’ve summarized the main pros and cons into the following table.

Instruction Fine-tuning vs. Retrieval Augmented Generation. Image by author.
Instruction Fine-Tuning
Instruction fine-Tuning is the process of further training a pre-trained model to a domain-specific task with a moderate quantity of tailored dataset.
Pros:
- Relevant Results and Reduced Hallucination: Fine-tuning allows models to produce highly relevant results. It reduces the occurrence of hallucinations or generating unrealistic content.
- No Token Limits: One limitation is that LLMs have a limited context window. As a result, these models may not perform well on tasks that demand a substantial amount of information. Fine-tuned models, on the other hand, is not constrained by token limits, by acquiring such knowledge during the fine-tuning process.
- Full Utilization of Large Training Data: In situations where there is an abundance of training data, fine-tuned models can leverage this wealth of information. Fine-tuning updates the model with real gradients from the task-specific data.
Cons:
- Dependency on Data Quality: The quality of the fine-tuned model is highly dependent on the quality of the dataset used for training. If the dataset is noisy, biased, or lacks diversity, the model may inherit these issues. Therefore, “your model is only as good as your data” holds true in fine-tuning.
- More Complex Approach Requiring Data Science Knowledge: Fine-tuning is a more complex approach that demands a deep understanding of data science. Preparing the data, tuning hyperparameters, and choosing the right architecture are all crucial steps that require expertise.
- Resource-Intensive: Fine-tuning models, especially large-scale ones, can be computationally expensive and time-consuming. Training on substantial datasets and complex tasks requires significant computational resources and time.
- Continual Learning Challenges: Models may require periodic re-fine-tuning to stay effective, which adds a layer of complexity to long-term model maintenance.
Retrieval Augmented Generation
In-Context Learning, or Few Shot Learning, is the process of including task-specific examples in the prompt.
Retrieval Augmented Generation (RAG) is a kind of In-Context Learning. The technique fetchs up-to-date or context-specific data from an external database and pass it as context with the orignal input prompt to an LLM. You can refer to my previous article for a concrete exemple on how to easily implement this technique to chat with your data.
Pros:
- Prototype Simplicity: RAG is relatively simple to prototype, making it accessible for initial development and experimentation.
- Flexibility in Architecture: RAG offers a high degree of flexibility for making changes to the architecture. You can modify the embedding model, vector store, and the Language Model (LLM) independently with minimal to moderate impact on other components, allowing for easy adaptability.
- Auditable Results: RAG can make the LLM’s results auditable by citing the sources it draws from, enhancing transparency and accountability.
- Bridge Knowledge Gap:RAG enables an LLM to answer questions on data it wasn’t specifically trained on by providing context. This helps bridge the gap left by LLMs’ knowledge being frozen at a certain time point.
Cons:
- Challenges in Production: While RAG is easy to prototype, transitioning it to a production-ready state that satisfies customers can be challenging.
- Dependency on Text Chunking and Embedding Retrieval Techniques: The relevance of a RAG powered LLM’s output heavily relies on factors like text chunking methods, embeddings, and retrieval techniques. Inadequate implementation can lead to information loss and suboptimal results.
- Performance Limitations: RAG perform poorly on tasks that require exhaustivity or long-range summarization. For example, tasks like listing all the requirements in an article is impossible because the LLM does not see the entire content and only processes a few chunks at a time.
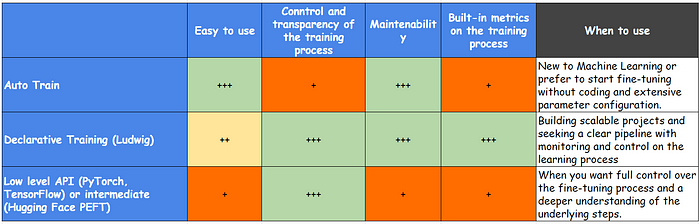
Comparaison of fine-tuning techniques. Image by author.
Running Mistral-7b AI on a Single GPU with Google Colab
How to run your AI efficiently through 4-bit Quantization.
The objective of the article is to show you how to effciently load and run Mistral 7B AI on Google Colab using just a single GPU. The magic ingredient for success? Quantization in 4-bit precision and QLoRA, which will be explained later.
What is Mistral 7B
Mistral-7B-v0.1 is a small, yet powerful Large Language model adaptable to many use-cases. It can perform various natural language processing tasks and has 8k sequence length. For instance, it is optimal for text summarisation, classification, text completion, code completion .
Here's the low-down on Mistral 7B:
- Performance Beyond Compare: Mistral 7B outperforms Llama 2 13B, on all benchmarks.

Performance of Mistral 7B in details - More efficient: Thanks to Grouped-query attention (GQA) and Sliding Window Attention (SWA), Mistral 7B delivers faster inference and handles longer sequences with ease.
- Open for All: Released under the Apache 2.0 license, Mistral 7B can be used without restrictions.
What is quantization and QLoRA?
Mistral 7B might be smaller compared to its peers, it remains a huge challenge to get it run and train in consumer hardware.
In order to run it on a single GPU, we need to run the model in 4-bit precision and use QLoRA to reduce the memory usage.
The QLoRA solution
QLoRA, which stands for Quantized LLMs with Low-Rank Adapters, is an efficient finetuning approach. It uses 4-bit quantization to compress a pretrained language model, without performance tradeoffs compared to standard 16-bit model finetuning.
The abstract of the QLoRA paper:
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. […]
QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and paged optimizers to manage memory spikes. […]
Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA.
Step-by-Step walkthrough
Step1 - Install necessary packages
QLoRA uses bitsandbytes for quantization and is integrated with
Hugging Face's PEFT and transformers libraries.
Step 2 - Define quantization parameters through the BitsandBytesConfig from transformers
Now we’ll configure the QLoRA settings using BitsandBytesConfig from the transformers library.
Here a quick explaination on the arguments that can be tweaked and used:
- load_in_4bit=True: specify that we want to convert and load the model in 4-bit precision.
- bnb_4bit_use_double_quant=True: Use nested quantization for more memory efficient inference and training.
- bnd_4bit_quant_type=”nf4": The 4bit integration comes with 2 different quantization types FP4 and NF4. The NF4 dtype stands for Normal Float 4 and is introduced in the QLoRA paper. By default, the FP4 quantization is used.
- bnb_4bit_compute_dype=torch.bfloat16: The compute dtype is used to change the dtype that will be used during computation. By default, the compute dtype is set to float32 but computation can be set to bf16 for speedups.
Step 3 - Load the Mistral 7B with quantization
Now we specify the model ID and then we load it with our previously defined quantization configuration.
Step 4 - Once loaded, run a generation and give it a try!
Finally we‘re ready to bring Mistral 7B into action.
- Let’s start by testing its text generation abilities. You can use the following template:
PROMPT= """ ### Instruction: Act as a data science expert. ### Question: Explain to me what is Large Language Model. Assume that I am a 5-year-old child. ### Answer: """ encodeds = tokenizer(PROMPT, return_tensors="pt", add_special_tokens=True) model_inputs = encodeds.to(device) generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.eos_token_id) decoded = tokenizer.batch_decode(generated_ids) print(decoded[0])The model has followed our instructions and explained the concept of a Large Language Model quite well!

2. Now let’s test Mistral 7B coding skills.
messages = [ {"role": "user", "content": "write a python function to generate a list of random 1000 numbers between 1 and 10000?"} ] encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt") model_inputs = encodeds.to(device) generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True) decoded = tokenizer.batch_decode(generated_ids) print(decoded[0])Seems the model nails the code perfectly!

Instruction Learning
There are several Finetuning methods to adapt large language models for specific tasks, including:
- In-Context Learning/Retrieval Augemented Generation,
- Instruction Learning,
- Reinforcement Learning from Human Feedback (RLHF).
In this article, we’ll focus on one of these methods — Instruction Learning. If you’re interested in how to use In-Context Learning/Retrieval Augmented Generation (RAG), please refer to my article on “Crafting an AI-Powered Chatbot for Finance using RAG, Langchain, and Streamlit”.
What is Instruction Learing/Tuning, and Why Should You Consider It?
Instruction fine-tuning is a process that tailors large language models to perform specific tasks based on explicit instructions.
It involves using a dataset containing pairs of `{instructions, outputs}` within a given domain. This dataset helps the model learn how to provide the correct response when presented with those types of instructions. During this training process, the model’s underlying weights may be adjusted, or alternative methods can be employed to train it. When executed correctly, this process equips the model to comprehend and execute instructions that it may have struggled with previously.
How Can You Perform Instruction Finetuning?
There are several instruction finetuning methods to choose from:
1. Full Fine-Tuning: This method entails training the entire pre-trained model from scratch on new data. It updates all model layers and parameters. While it can lead to high accuracy, it demands substantial computational resources and time. It is best suited for tasks significantly different from the original pre-training task.
2. Parameter Efficient Fine-Tuning (PEFT), e.g., LoRA: PEFT focuses on updating only a subset of the model’s parameters. It often involves freezing certain layers or parts of the model. This approach can result in faster finetuning with fewer computational resources. Notable methods within PEFT include LoRA, AdaLoRA, and Adaption Prompt (LLaMA Adapter). It is suitable when the new task shares similarities with the original pre-training task. Recent State-of-the-Art PEFT techniques achieve performance comparable to that of full fine-tuning.
3. QLoRA: QLoRA involves reducing the precision of model parameters through quantization. This reduces memory usage and enables faster inference on hardware with reduced precision support. It is particularly useful when deploying models on resource-constrained devices, such as mobile phones or edge devices.
In our demo, we’ll use PEFT LoRA to finetune our Mistral-7B model.
In short, PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.
Step-by-Step walkthrough
Step 1 - Install Necessary Packages
Step 2 - Loading the Model with Quantization
Step 3 - Preparing the Dataset for Instruction Fine-Tuning
Step 4 - Applying LoRA
Step 5 - Running the Training
Step 6 - Evaluating the Model Qualitatively
We’ve seen that PEFT is as an efficient way of tuning large LLMs, saving a lot of compute and storage while delivering comparable performance to full finetuning.
Even with a modest fine-tuning process involving just 100 examples from our dataset, we noted a remarkable improvement in our model’s performance on the designated task.
It also demonstrates that having a high-quality dataset is key in shaping the final performance of your customized model. For instance, research showed you can outperform GPT-3 (DaVinci003) by fine-tuning a LLaMA (v1) model with 65 billion parameters on only 1,000 high-quality samples.
How to Generate Instruction Datasets from Any Documents for LLM Fine-Tuning
Generate high-quality synthetic datasets economically using lightweight libraries
Large Language Models (LLMs) are capable and general-purpose tools, but often they lack domain-specific knowledge, which is frequently stored in enterprise repositories.
Fine-tuning a custom LLM with your own data can bridge this gap, and data preparation is the first step in this process. It is also a crucial step that can significantly influence your fine-tuned model’s performance.
However, manually creating datasets can be an expensive and time-consuming. Another approach is leveraging an LLM to generate synthetic datasets, often using high-performance models such as GPT-4, which can turn out to be very costly.
In this article, I aim to bring to your attention to a cost-efficient alternative for automating the creation of instruction datasets from various documents. This solution involves utilizing a lightweight open-source library called Bonito.
Getting Started with Bonito, the Open-Source Solution
Understanding Instructions
Before we dive into the library bonito and how it works, we need to first understand what even an instruction is.
An instruction is a text or prompt given to a LLM, such as Llama, GPT-4, etc. It directs the model to produce a specific kind of answer. Through instructions, people can guide the discussion, ensuring that the model’s replies are relevant, helpful, and in line with what the user wants. Creating clear and precise instructions is important to achieve the desired outcome.
Introducing Bonito, an Open-Source Model for Conditional Task Generation
Bonito is an open-source model designed for conditional task generation. It can be used to create synthetic instruction tuning datasets to adapt large language models to users’ specialized, private data.

Bonito workflow. Source: Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation The research paper underlying Bonito’s development illustrates how it can be effectively employed to adapt both pre-trained and instruction-tuned models to various tasks without requiring any text annotations.
The model itself is fine-tuned from mistralai/Mistral-7B-v0.1 with a new large-scale dataset containing 1.65M examples.
Bonito also supports a variety of task types, including multiple-choice question answering, yes-no question answering, natural language inference, topic classification etc.
How to Use Bonito
The easiest way to use the Bonito model is through their package built upon the transformers and the vllm libraries.
In the next section, I'll show you how to easily use the Bonito package to create a synthetic dataset from a PDF document.
Step-by-Step Guide to Generating Datasets
In this guide, I’ll show you how to generate a question-answering dataset from a PDF document using the Bonito package.
I’ve selected in this example the Circular 12/552 issued by the CSSF, Luxembourg’s financial regulator, which pertains to bank governance and central administration. The motivation behind this choice stems from the observation that tools like ChatGPT often struggle to grasp domain-specific knowledge, particularly regulatory requirements within specific industries and from smaller countries like Luxembourg.
My aim is to transform this circular into an instructional dataset suitable for fine-tuning a LLM. This tailored LLM will enable me to comprehend the underlying regulatory requirements, respond to inquiries about them, and ultimately extend its utility to broader applications such as risk management, impact assessment, and ongoing monitoring.
Step 1 - Installing the Bonito Package and Other Dependencies
Besides the Bonito package, we’ll also need :
- Datasets and Hugging Face Hub libraries to handle datasets and interact with Hugging Face repository
- PyMuPDF and SpaCy: PyMuPDF is used for reading and extracting text from PDF files, while SpaCy for natural language processing tasks.
Step 2 - Processing the PDF Document
First, we utilize PyMuPDF library to extract text from the document.
Next, we process the extracted text by splitting it into sentences. This step uses SpaCy, a library for advanced natural language processing (NLP).
Finally, we transform the list of sentences into a format that can be utilized by the model Bonito, specifically using the datasets library:
Step 3 - Generating the Synthetic Dataset
Now it’s time to utilize the Bonito library to generate a synthetic dataset tailored for question answering!
In this example, we use Bonito for “question generation” (qg) to create questions for the dataset. But Bonito can handle a wide array of tasks. Here’s a brief overview of the types of tasks Bonito can manage:
- Extractive Question Answering (exqa): Generates answers to questions based on a given text snippet, extracting the answer directly from the text.
- Multiple-Choice Question Answering (mcqa): Provides answers to questions from a set of multiple choices.
- Question Generation (qg): Creates questions based on the content of a provided text.
- Question Answering Without Choices (qa): Answers questions without providing multiple-choice options.
- Yes-No Question Answering (ynqa): Generates yes or no answers to questions.
- Coreference Resolution (coref): Identifies mentions in a text that refer to the same entity.
- Paraphrase Generation (paraphrase): Rewrites sentences or phrases with different wording while retaining the original meaning.
- Paraphrase Identification (paraphrase_id): Determines whether two sentences or phrases convey the same meaning.
- Sentence Completion (sent_comp): Fills in missing parts of a sentence.
- Sentiment Analysis (sentiment): Identifies the sentiment expressed in a text, such as positive, negative, or neutral.
- Summarization: Condenses a longer text into a shorter summary, capturing the main points.
- Text Generation (text_gen): Creates coherent and contextually relevant text based on a prompt.
- Topic Classification (topic_class): Categorizes text into predefined topics.
- Word Sense Disambiguation (wsd): Determines the meaning of a word based on its context.
- Textual Entailment (te): Predicts whether a given text logically follows from another text.
- Natural Language Inference (nli): Determines the relationship between two pieces of text, such as contradiction, entailment, or neutrality.
Step 4 - Saving the Generated Dataset
Now we can save either the generated dataset locally or upload it to the Hugging Face Hub.
To upload and save the dataset on the Hugging Face Hub, log into the Hub.
Then create a repository for the dataset and push it to the hub.
Here is the dataset I’ve created with my document, which of course needs some further cleaning and refinement to ensure its quality and performance, before the finetuning process.

My synthetic dataset generated with Bonito Creating a high-quality instruction dataset is key to achieving a well-performing model, but it can be a time-consuming process.
In this guide, we’ve looked at how to use Bonito, a specially fine-tuned open-source model, to create datasets from any text. This new way offers a good option compared to doing things by hand or using paid models like GPT-4, which can get really expensive.
Bonito is a relatively new approach, released just last month. Since a significant amount of knowledge is in unstructured data scattered across various documents, I’ve employed Bonito to automate the generation of datasets from multiple documents. These datasets are then used to train a local LLM, enabling me to customize my models to comprehend and utilize specific knowledge.
'Research > NLP_reference' 카테고리의 다른 글
Llama 3.1 (0) 2024.09.08 Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA (0) 2024.09.08 RoPE (0) 2024.08.27 Prompt Engineering Guide (2/2) (0) 2024.07.24 Prompt Engineering Guide (1/2) (0) 2024.07.24