-
Multimodal Few-Shot Learning with Frozen Language ModelsPaper Writing 1/Related_Work 2024. 11. 6. 10:21
https://arxiv.org/pdf/2106.13884
(Jun 2021 NeurIPS 2021)
Abstract
When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples. Here, we present a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language). Using aligned image and caption data, we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption. The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings. We demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.
1. Introduction
Auto-regressive transformers have been shown to be very impressive models of natural language [42]. Large-scale language transformers exhibit several surprising abilities beyond that of standard text generation [4, 31]. Perhaps most notably, they are few-shot learners; they can learn to perform a new task from a few examples without any further gradient updates. Equipped with this ability, these models have been shown to rapidly adapt to new tasks and styles of generation via prompting (e.g. switching from formal to informal language) [4], to retrieve relevant encyclopedic or general knowledge when primed with a relevant context (e.g. answering questions such as ‘When did the French Revolution begin?’) [34, 1, 28] and to use new words in appropriate ways straight after being taught what those words mean (sometimes referred to as ‘fast binding’) [12, 4].
Despite these impressive capabilities, such large scale language models are ‘blind’ to modalities other than text, preventing us from communicating visual tasks, questions or concepts to them. Indeed, philosophers and linguists have questioned whether an un-grounded language model can ever achieve true understanding of the language it processes [5, 2]. Here, we present Frozen, a method for giving a pre-trained language model access to visual information in a way that extends its few-shot learning capabilities to a multimodal setting, without changing its weights. Frozen consists of a neural network trained to encode images into the word embedding space of a large pre-trained language model such that the language model generates captions for those images. The weights of the language model are kept frozen, but gradients are back-propagated through it to train the image encoder from scratch (Figure 2). Although Frozen is trained on single image-text pairs, once trained it can respond effectively to interleaved sequences of multiple images and text. This allows users to ‘prompt’ it with several examples of new multimodal tasks before evaluating its performance, or to ‘teach’ it the name of a new visual category before immediately asking about that category.

By exploiting its pre-trained language model, Frozen exhibits nontrivial zero-shot performance on multimdodal tasks that it was not trained on, such as visual question answering (VQA). More surprisingly, it gets better at these tasks after seeing a handful of examples ‘in-context’ as in [4], and also performs above chance on tests of fast category learning such as miniImageNet [43]. In each case, comparisons with ‘blind’ baselines show that the model is adapting not only to the language distribution of these new tasks, but also to the relationship between language and images. Frozen is therefore a multimodal few-shot learner, bringing the aforementioned language-only capabilities of rapid task adaptation, encyclopedic knowledge and fast category binding to a multimodal setting.
Our goal in developing Frozen was not to maximise performance on any specific task, and in many cases it is far from state-of-the-art. Nonetheless, it performs well above trivial baselines across a wide range of tasks without ever seeing more than a handful of the training examples provided by these benchmarks. Moreover, as illustrated in Figure 1, Frozen is a system for genuinely open-ended and unconstrained linguistic interpretation of images that often produces compelling output.

To summarise, our contributions are as follows:
1. We present Frozen, a modular, scalable and efficient approach to training vision front-ends for large language models. The resulting combined model retains all of the capabilities of large language models, but can also process text and image inputs in any arbitrary sequence.
2. We show that such models transfer their capacity for rapid task adaptation, encyclopedic knowledge and fast category binding from a language-only to a multimodal setting, and verify that prompting them with both visual and language information can be strictly more effective than doing so with language information alone.
3. We quantify these capabilities on a range of existing and new benchmarks, paving the way for future analysis of these capabilities.
2. Related Work
The Frozen method is inspired by lots of recent work. [26] show that the knowledge encoded in transformer language models can be a valuable prior for tasks involving reasoning and memory across discrete sequences, and even classification of images presented as sequences of spatial regions. In that approach, a small subset of the pre-trained language model weights are fine-tuned to the various final applications. In contrast, applying Frozen to different tasks does not involve any weight updates to the transformer whatsoever; the system adapts to and improves at multimodal (vision and language) tasks as activations propagate through the model. The two studies thus reveal different ways in which knowledge acquired from text can transfer to non-linguistic settings.
The effectiveness of prefix tuning [23] or prompt tuning [20] was another important motivation for Frozen. Prefix tuning is a method for prompting a language model to produce output of a particular style using gradient descent to learn a task-specific bias term which functions like the continuous embedding of a text prompt. Using prefix tuning, language models can be adapted to different natural language generation tasks like summarization. Frozen could also be considered a type of image-conditional prefix tuning, in which this continuous prefix is not a bias but an image-conditional activation produced by an external neural network.
Learning to embed image representations into the ‘word’ space of a large pretrained language model was done previously by [16]. This work focused on image-text classification, and uses a BERT-style language model that is fine-tuned (rather than frozen) on multimodal data. [36] extend a similar image embedding+BERT system to create a generative model of text, using a pre-trained object extraction system to embed images into word space. Neither of these studies consider the problem of learning image-text correspondences in a few shots.
A large body of work has applied either text-specific or multimodal representation-learning approaches like BERT [8] to visual question answering (VQA) and captioning (see e.g. [25, 40] and many more). In these approaches, models are first trained with aligned data on task-agnostic cross-modal objectives and then fine-tuned to specific tasks. This approach can yield state-of-the-art performance on a range of classification tasks. Unlike Frozen, the resulting systems are highly specialized to one task, and cannot learn new categories or adapt to new tasks in a few shots.
By contrast, [7] propose text generation as an objective for task-general multimodal models, yielding a system that, like Frozen, produces unconstrained language output. Unlike Frozen, they do not use a pre-trained model trained on text only, and do not consider zero or few-shot learning, instead updating all weights of the system with training data for each task they consider – thus, again, specializing the models to one task at a time. Similarly, [46] and [6] show that a large pre-trained language model as decoder can improve a captioning performance when training data is limited. Unlike Frozen, they use pre-trained frozen visual encoders or object extractors and fine-tune the pre-trained weights in the text decoder on the captioning data. Similarly, they do not consider zero or few-shot adaptation across different multimodal tasks. Past work has also explored alternative approaches for post-hoc combination of models for different modalities using latent variables [41].
Multimodal pre-training has recently been shown to enable strong zero-shot generalization in the discriminative setting using large-scale contrastive learning [29, 14]. Also in a discriminative setting, [45] has observed signs of emergent few-shot-learning from large-scale training. In contrast, our work enables strong generalization to new multimodal tasks both zero-shot or few-shot with completely open-ended generative text output.
3. The Frozen Method
Frozen is a method for grounding a large language model without changing its weights, closely related to prefix tuning [23, 20]. Prefix tuning trains a task-specific continuous bias term to function like the embedding of a constant, static text prompt used for all test-time examples. Frozen extends this approach by making this prefix dynamic, in that it is not a constant bias but an input-conditional activation emitted by a neural network.
3.1. Architecture
Pre-trained Autoregressive Language Models
Our method starts from a pre-trained deep autoregressive language model, based on the Transformer architecture [42, 30], which parametrizes a probability distribution over text y. Text is decomposed into a sequence of discrete tokens y = y1, y2, ..., yL by the SentencePiece tokenizer [18]. We use a vocabulary of size 32,000. The language model makes use of an embedding function gθ which independently transforms each token into a continuous embedding tl := gθ(yl), as well as a transformer neural network fθ whose output is a vector of logits parameterizing a categorical distribution over the vocabulary. The distribution pθ(y) is represented as follows:

The model we start from is pre-trained, i.e. θ has been optimised via the standard maximum-likelihood objective on a large dataset of text from the internet. We use a 7 billion parameter transformer trained on the public dataset C4 [31] – previous work has shown that the multi-billion parameter scale is sufficient to exhibit the key capacities we are interested in studying [30, 34].
Vision Encoder
Our vision encoder is based on NF-ResNet-50 [3]. We define vφ as a function that takes a raw image and emits a continuous sequence to be consumed by the transformer. We use the final output vector of the NF-Resnet after the global pooling layer.
Visual Prefix
One important requirement is to represent images in a form that the transformer already understands: a sequence of continuous embeddings, each having the same dimensionality D as a token embedding tl . We therefore form the visual prefix by linearly mapping the vision encoder’s output to D ∗ k channels, and then reshaping the result as a sequence of k embeddings, each with dimensionality D. We call this sequence a visual prefix since it plays the same functional role in the transformer architecture as (part of) an embedding sequence of prefix tokens. We experimented using different number of tokens k, specifically 1, 2 and 4 and found that 2 performs best, though certainly this would be sensitive to other architectural details. See Appendix for more details on the architecture.
3.2. Training
During training, we update only the parameters φ of the vision encoder using paired image-caption data from the Conceptual Captions dataset [37]. Our experiments show that fine-tuning θ hurts generalization, as much less paired image-caption data is available than the amount of text-only data used to pre-train θ. Training only the parameters φ makes our system modular – it can use an existing language model off the shelf – and also quite simple: we only train a visual encoder and rely on the capabilities of an existing language model.
Following standard captioning systems [22, 13], we treat captioning as conditional generation of caption text y given an image x. We represent x as vφ(x) = i1, i2, ..., in and train φ to maximise the likelihood:
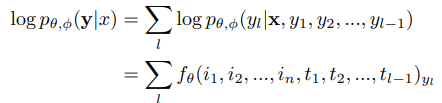
Whilst the parameters θ are frozen, each element ik of the visual prefix receives gradients

enabling the parameters of the visual encoder to be optimised with standard backpropagation and SGD (Figure 2).
As the notation fθ(i1, i2, ..., in, t1, t2, ..., tl−1) suggests, we present the visual prefix during training as if it were a sequence of embeddings occurring earlier in time than the caption (token embeddings) t1, t2, .... We use relative positional encoding [38], which enables the transformer to generalize to prefix sequences where an image is not always in the first absolute positions, and where more than one image may be present. In particular, we use the version of relative attention described in transformerxlDai.We leave improvements of this simple scheme for future work.
3.3. Interface at Inference Time

At inference time, a vanilla language model, conditioned upon an arbitrary text prompt y1, y2, ..., yp, generates text sequences yp+1, yp+2, ... autoregressively. In Frozen it is straightforward to include images in such prompt by placing an image’s embedding i1, i2 as a prefix to a text embedding subsequence t1, t2, ..., tp. Because the transformer fθ is modality-agnostic, we can interleave a sub-sequence of text token embeddings with a sub-sequence of image embeddings in any arbitrary order. In Figure 3, we show how this can support zero-shot visual question-answering (Figure 3a), few-shot visual question-answering (Figure 3b), and few-shot image classification (Figure 3c).
To evaluate these tasks, the model decodes output sequences greedily and these outputs are compared against the ground truth answers of the task following the normalization technique used in [19]. To probe the open-ended capabilities of Frozen, we decided not to use common practice of short-lists of pre-canned answers, even though in some tasks this may hurt its performance in accuracy percentages.
3.4. Few-Shot Learning Definitions
The ability of Frozen to be conditioned on a sequence of interleaved images and text allows it not only to be able to perform different multimodal tasks, but also gives rise to different ways of ‘inducing’ the task to the model in order to improve its performance. We briefly define the terminology used in our settings, common amongst all the different tasks. See Figure 5 in the appendix for a visual illustration of these concepts.
• Task induction Explanatory
text that precedes the sequence of images and text. It is intended to describe the task to the model in natural language, for example ‘Please answer the question.’
• Number of shots
The number of distinct full examples of the task presented to the model prior to the evaluated example. For example, in Visual Question-Answering, a shot is an image along with the question and the answer.
For tasks involving fast category binding (e.g., few-shot image classification), we define further specific terminology. See also Figure 4a and Figure 6 in the appendix.
• Number of ways
The number of object classes in the task (e.g. dog vs cat).
• Number of inner-shots
The number of distinct exemplars from each category that are presented to the model (i.e. number of images of different dogs). In previous work with MiniImagenet, these were known as shots, but we modify the term here to distinguish from the more general usage of the term described above.
• Number of repeats
The number of times each inner-shot is repeated in the context presented to the model. We use this setting as an ablation to explore how the model integrates visual information about a category.
4. Experiments: A Multi-Modal Few-Shot Learner
Our experiments are designed to quantify three capacities that should be characteristic of a MultiModal Few-Shot Learner: rapid adaptation to new tasks, fast access to general knowledge and fast binding of visual and linguistic elements. We train Frozen on Conceptual Captions, a public dataset that consists of around three million image-caption pairs [37]. We do early stopping on the validation set perplexity which usually reaches an optimum just after a single epoch with batch size 128. All experiments used the Adam optimizer with β1 = 0.9 and β2 = 0.95 and a constant learning rate of 3e-4 unless otherwise noted. We operate on 224×224 images at both train and test-time. Images which are not square are first padded with zeroes to square and then resized to 224×224.
4.1. Rapid Task Adaptation
We first examine zero-shot and few-shot generalization from captioning to visual question-answering. This is a type of rapid adaptation from captioning behaviour to question-answering behaviour analogous to transfer from language modelling to open-domain question-answering in the text-only setting [34]. We evaluate on the VQAv2 [10] validation set.
Zero-shot transfer from captioning to VQA
We first observe that a version of our model in which the ability to embed images into a prefix is trained solely with a captioning objective can transfer moderately well to visual question-answering in the zero-shot setting, with no specific training towards that goal. We simply have to provide the system with an image and a textual prompt of the form Question: what colour is the dog sitting on the grass? Answer:, then observe how it completes the prompt. The ability to adapt to input of this form is presumably transferred from the training data of the pretrained language model component of the system.
The strength of the pre-trained language model in the system is a double-edged sword. It powers the generalization abilities of Frozen but also enables the model to perform surprisingly well without considering the visual input at all. To guard against this possibility we also train blind baselines, in which the image presented to the visual encoder is blacked out, but the convnet weights are still trained (see Table 1). This amounts to prefix tuning [23]. We outperform this blind baseline which also inherits the few-shot learning abilities of the language model.
In these experiments we also include two additional and important baselines: Frozen finetuned in which the language model is instead finetuned starting from the pretrained weights and Frozen scratch, wherein the whole system is trained from scratch end-to-end, both using the same dataset as Frozen. These baselines preferred a smaller learning rate of 1e-5. Results in Table 1 show that keeping the language model frozen generalizes substantially better to visual question-answering than finetuning. The model trained from scratch is not able to transfer at all from captioning to VQA; we interpret this to suggest that the tremendous generalization abilities of large language models are reliant upon large-scale training datasets in which the task of predicting the next token mimics the test setting (here question-answering) with non-negligible frequency.
Improving performance with few-shot learning
More importantly, for the present work, we observe that the ability of the model to transfer knowledge from captioning and text-modelling to visual question-answering improves if the model is presented with several examples of VQA data sequentially. We repeat the previous experiments with up to four examples of image-question-answer triples shown to the model as conditioning information in the continuous prefix sequence (using the interface in Figure 3).
These results are presented in Table 1. For contrast, we compare this performance to a condition in which we mix in some data from the VQAv2 training set with the captioning data. As we might expect, few-shot learning on four examples is outperformed by SGD on tens of thousands of examples, but few-shot performance clearly improves with more examples, and goes some way (38.2%) toward closing the gap from zero-shot performance (29.5%) to full SGD training performance (48.4%) There are two important takeaways from the results presented in this section. First, they show that training a visual encoder through a pretrained and frozen language model results in a system capable of strong out-of-distribution (zero-shot) generalization. Second, they confirm that the ability to rapidly adapt to new tasks given appropriate context is inherited from the pretrained language model and transfers directly to multimodal tasks.
4.2. Encyclopedic Knowledge
Here we study the extent to which Frozen can leverage the encyclopedic knowledge in the language model towards visual tasks. The Conceptual Captions dataset is hypernymed (e.g. proper names are replaced with a general word like person). This enables us to rigorously study the transfer of factual knowledge because all knowledge of named entities comes from language model pretraining.
Consequently, when we show the model an image of an airplane and ask “who invented this?” (Figure 1), the visual encoder has determined that the image contains an airplane, and the language model has used this to retrieve the factual knowledge that airplanes were invented by the Wright brothers, a fact which is referenced in the C4 training set through (text-only) articles about airplanes. This is a fascinating chain of deduction. A detailed analysis of this behaviour with more examples is included in the Appendix (e.g. Figure 9, Figure 10, Figure 11).
We bolster this finding quantitatively by evaluating performance on OKVQA [27], a visual questionanswering dataset designed to require outside knowledge in order to answer correctly. The pretrained language model’s command of factual knowledge is of course dependent upon its scale, so we examine the performance of Frozen using pretrained language models of varying sizes: the base model with 7 billion parameters, and a much smaller 400 million parameter language model pretrained on the same dataset. Table 2 shows the results: task performance scales with model size. Again finetuning performs worse than leaving the model frozen in terms of generalization performance. We stress that Frozen is never trained on OKVQA.
4.3. Fast Word-to-Visual-Category Binding

5. Discussion
5.3. Conclusion
We have presented a method for transforming large language models into multimodal few-shot learning systems by extending the soft-prompting philosophy of prefix tuning [23] to ordered sets of images and text while preserving text prompting abilities of the language model. Our experiments confirm that the resulting system, Frozen, is capable both of open-ended interpretation of images and genuinely multimodal few-shot learning even though the system is only trained to do captioning. One corollary of these results is that the knowledge required to quickly bind together or associate different words in language is also pertinent to rapidly binding language to visual elements across an ordered set of inputs. This finding extends the conclusion of [26] – that knowledge in transformer language models can transfer to non-linguistic tasks – to the specific case of knowledge about few-shot learning.
'Paper Writing 1 > Related_Work' 카테고리의 다른 글
[PaliGemma] A versatile 3B VLM for transfer (0) 2024.11.07 [TSMixer] An All-MLP Architecture for Time Series Forecasting (0) 2024.11.04 [GPT4MTS] Prompt-Based Large Language Model for Multimodal Time-Series Forecasting (0) 2024.11.03 [Time-MoE] Billion-Scale Time Series Foundation Models with Mixture of Experts (0) 2024.11.01 [Chronos] Learning the Language of Time Series (0) 2024.10.30