-
[cdpg] Controlling Conditional Language Models without Catastrophic ForgettingRL/RL 2024. 12. 22. 08:49
https://arxiv.org/pdf/2112.00791
(Jun 2022 ICML 2022)
Abstract
Machine learning is shifting towards general-purpose pretrained generative models, trained in a self-supervised manner on large amounts of data, which can then be applied to solve a large number of tasks. However, due to their generic training methodology, these models often fail to meet some of the downstream requirements (e.g., hallucinations in abstractive summarization or style violations in code generation). This raises the important question of how to adapt pre-trained generative models to meet all requirements without destroying their general capabilities (“catastrophic forgetting”). Recent work has proposed to solve this problem by representing task-specific requirements through energy-based models (EBMs) and approximating these EBMs using distributional policy gradients (DPG). Despite its effectiveness, this approach is however limited to unconditional distributions. In this paper, we extend DPG to conditional tasks by proposing Conditional DPG (CDPG). We evaluate CDPG on four different control objectives across three tasks (translation, summarization and code generation) and two pretrained models (T5 and GPT-Neo). Our results show that finetuning using CDPG robustly moves these pretrained models closer towards meeting control objectives and — in contrast with baseline approaches — does not result in catastrophic forgetting.
1. Introduction
Pretrained generative models are shifting the landscape of machine learning research and practice. General purpose models such as the GPT family (Radford et al., 2019; Brown et al., 2020; Black et al., 2021), T5 (Raffel et al., 2020), CLIP (Radford et al., 2021) and Codex (Chen et al., 2021) are trained in a self-supervised manner on large amounts of uncurated data and can then be adapted to specific downstream tasks (e.g. generating Python code) or control objectives (e.g. controlling the style of generated code). Frequently, control objectives are motivated by the desire to address the shortcomings of certain pretrained models. These can be due to the uncurated nature of the original training data (e.g. a large portion of Python source code on the Internet violates PEP8 (van Rossum et al., 2001), the Python Style Guide) or the difficulty of learning a desired behaviour by purely self-supervised training (e.g. there is not enough training signal to ensure that a model trained on source code always generates compilable code or that a summarization model always produces factually correct summaries).
The practice of adapting and controlling pretrained generative models poses two open problems. The first is that control objectives frequently lack ground truth data that could be used for supervised fine-tuning; in general, we are only given an indicator b(x) of whether a given sample x from the model satisfies a given control objective. Thus, this restriction calls for approaches that can employ this signal such as reinforcement learning (RL) (Pasunuru & Bansal, 2018; Ziegler et al., 2019), weighted decoding (Ghazvininejad et al., 2017; Holtzman et al., 2018; See et al., 2019) or decoding with perturbed activations (Dathathri et al., 2020).
The second problem is catastrophic forgetting: most approaches to enforcing a control objective result in a dramatic loss of capabilities of the original model beyond the scope of the control objective. Notably, there exists one approach largely avoiding both of these problems (Parshakova et al., 2019a; Khalifa et al., 2021): representing the control objective as an energy-based models (EBM) and approximating that EBM using distributional policy gradients (DPG). Although this approach shows great improvements in controlling pretrained language models while avoiding catastrophic forgetting (Khalifa et al., 2021), it is limited to unconditional generation tasks and cannot finetune conditional models that are behind the most impactful NLP tasks such as machine translation, summarization or dialogue systems.
In this paper, we present Conditional DPG (CDPG), an extension of DPG that can approximate conditional EBMs. A conditional EBM P defines an unnormalized distribution for each context c (e.g. a source document). Extending the approach of Khalifa et al. (2021) such a conditional EBM represents the ideal behaviour of a generative model, given context c, as the distribution that incorporates the control objectives while remaining as close as possible to the original distribution to prevent catastrophic forgetting. This corresponds to defining multiple distributions pc indexed by c, where each is the normalization of an unconditional EBM Pc following Khalifa et al. (2021). We then define the training objective for the conditional model based on minimizing the average divergence for each pc.
We demonstrate the effectiveness of CDPG in addressing shortcomings of pretrained generative models by considering three tasks: translation, summarization and code generation; and two corresponding pretrained generative models: T5 (Raffel et al., 2020) and GPT-Neo (Black et al., 2021).
We start by demonstrating the effectiveness of CDPG on a toy control objective for translation: ensuring that numeral nouns (e.g. “two”) are translated as digits (e.g. “1”) while other aspects of translation are unchanged. This problem is an simple instance of broader challenge of incorporating prior information in neural translation models. CDPG is able to make samples satisfying the constraint 116 times more likely.
For summarization, a similar big, unsolved problem is ensuring that summaries are factually faithful to source documents given that summarization models are prone to hallucinating named entities never mentioned in the source (Maynez et al., 2020). We show that a preference for factually faithful summaries (operationalized as entity-level factual consistency (Nan et al., 2021)) can be represented by a conditional EBM. Then, we show that using CDPG to finetune T5 to approximate this EBM increases the number of correct and relevant named entities in summaries and improves T5’s Rouge score. In contrast with RL approaches, CDPG does not degrade the diversity and quality of summaries.
For code generation, we consider the task of generating a Python function given its signature (name and arguments). While general-purpose language models can generate idiomatic Python functions (Chen et al., 2021; Austin et al., 2021), they may still struggle to learn some desirable properties of generated code. For instance, a Python function generated by GPT-Neo will compile only 40% of the time and will contain on average 4 violations of PEP8. We show that using CDPG to approximate a conditional EBM expressing corresponding constraints improves both compilability and PEP8-compliance without hurting the diversity of generated Python code or leading to degeneration (Holtzman et al., 2020).
The contributions of this paper are as follows:
1. We introduce a formal framework for representing control objectives for conditional generative models as conditional EBMs while alleviating catastrophic forgetting,
2. We design CDPG, an extension of DPG suitable for approximating conditional EBMs,
3. We evaluate CDPG on three control objectives across three tasks: machine translation with number format constraints, summarization constrained to be factually correct, code generation constrained to generate compilable Python functions and code generation constrained to respect PEP8.

2. Method






3. Experiments
We evaluate CDPG as well as three baselines on four control objectives across three tasks: translation, summarization and code generation. Each task is associated with C_train, a set of contexts c used for prompting the model: these are English source sentences for translation, Python function signatures in case of code generation and source documents in case of summarization. When computing evaluation metrics, we sample contexts from a held out set C_test not used for training. In addition to that, for each experiment, we measure Ec∼τ(c)DKL(pc, πθ), the expected forward KL divergence from the optimal distribution pc, as well as Ec∼τ(c)DKL(πθ, a), the expected reverse KL divergence from the original pretrained model.3 .
3.1. Baselines
DPG-like ablation
We compare our algorithm with an ablation (labeled as “DPG” on all figures) that sets Zc in the denominator of (9) to a constant Z which is the running mean of Pc(x) across x’s and c’s. This ablation resembles the original DPG algorithm for unconditional EBMs developed by (Parshakova et al., 2019a) and extended by (Khalifa et al., 2021). While the partition function is constant for unconditional EBMs, in conditional EBMs Zc varies with c. Therefore, the DPG-like ablation performs gradient updates using biased gradient estimates.
Reinforcement learning
The problem of fine-tuning a pretrained model to satisfy a pointwise constraint b(x, c) can be posed as maximising the expected reward Ec∼τ(c) Ex∼πθ(x|c) R(x, c). We consider two instances of this approach: Reinforce (Williams, 1992) and Ziegler (Ziegler et al., 2019). For Reinforce, we simply define R(x, c) = b(x, c). Ziegler prevents too large departures from a by adding a KL penalty term and defining R(x, c) = b(x, c) − βDKL(πθ, a), where β is a hyperparameter updated using an adaptive schedule.
3.2. Translation
Dataset
For the translation task, τ (c) from Algorithm 1 is a uniform distribution over a fixed set of English sentences. We sampled 5k English sentences containing numeral nouns from the English-French subcorpus of the Europarl dataset, version 7 (Koehn, 2005). Metrics are computed for generated translations of another set of 5k English sentences from the test split of Europarl. Note that neither CDPG nor the baselines utilise ground truth translations (references); we compute b(x, c) based on source documents and generated translations. Ground-truth translations are only used for evaluating the BLEU score of generated translations.
Model
We conduct our experiments on the T5 architecture (Raffel et al., 2020), using the pre-trained model t5-small as πθ. During fine-tuning, we generate translations x conditioned on a source sentence c by pure ancestral sampling from πθ. For evaluation, we follow the setup described by (Raffel et al., 2020) and use beam search decoding with beam size 4.
Metrics
In addition to measuring expected DKL(pc, πθ) and DKL(πθ, a), we evaluate the forgetting of T5’s capabilities in terms of BLEU-4 score (Papineni et al., 2002), a measure of translation quality understood as overlap between generated and ground-truth translation.
Constraint
We implement the constraint scorer as table lookup: b(x, c) = 1 if for every occurrence of a given numeral noun (e.g. “two”) in a source sentence c, a corresponding digit (“2”) occurs in its translation x. Otherwise, b(x, c) = 0.
Results
We present the results of the translation task on Figure 2. Initial constraint satisfaction is very low: 0.006. Intuitively, it’s very unlikely for T5 to translate “two” as “2”, not as “deux”. However, CDPG is able to boost that number to 0.7 and reduce the expected divergence from its target distributions pc almost twofold, outperforming DPG by a wide margin. It also outperforms Reinforce by staying closer to the original distribution a and not suffering from almost any drop in BLEU-4 score. (Note that some drop is necessary for satisfying the constraint, because ground truth translations with respect to which BLEU-4 is computed almost don’t satisfy the constraint themselves.) In contrast, Reinforce improves constraints satisfaction only at the cost of heavy divergence from a: it learns to append all the digits at the end of each translation, thus ensuring constraint satisfaction (see Appendix C.1 for sample translations). This is reflected in a catastrophic drop in BLEU-4 score. Ziegler, on the other hand, fails to improve constraint satisfaction and stays too close to the original distribution a.

3.2. Summarization
Dataset
To conduct our summarization experiments, we use the CNN/DailyMail dataset (Nallapati et al., 2016) and sample 5k source documents from the train and test subsets to use for fine-tuning and evaluation, respectively. We use ground truth summaries only for computing reference-based evaluation metrics such as ROUGE score or recall target. Ground truth summaries are not used in training.
Model
We use the same model as in the translation task (t5-small). For fine-tuning, we generate summaries x conditioned on a source document c by pure ancestral sampling from πθ; for evaluation, we use beam search with beam size 4.
Constraints
Following (Nan et al., 2021), we define an entity-level factual consistency constraint as a product of two constraints: there must be at least four named entities in the summary x and all the named entities x must have occurred in the source c. More formally, let NER(·) denote the set of named entities found in a text and | · | the number of elements of a set. Then, b(x, c) = 1 iff [|NER(x)| ≥ 4] ∧ [NER(x) ⊆ NER(c)] and b(x, c) = 0 otherwise.
Metrics
In addition to measuring expected DKL(pc, πθ) and DKL(πθ, a), we evaluate the quality and factual consistency of generated summaries using the following metrics:
1. Precision-source (Nan et al., 2021), defined as [|NER(x) ∩ NER(x)|]/|NER(x)| is the percentage of named entities in the summary that can be found in the source. Low precision-source indicates severe hallucination,
2. Recall-target (Nan et al., 2021), defined as [|NER(x) ∩ NER(x)|]/|NER(t)|, is the percentage of named entities in the target summary t that can be found in the generated summary x.
3. Distinct-2 (Li et al., 2016), a measure of text diversity in terms of the frequency of bigram repetitions within a single continuation x,
4. ROUGE-L (Lin, 2004), a measure of summarization quality in terms of unigram overlap between the source document and ground truth summary.
See Appendix A.4 for on how scorers b and metrics are computed for summarization experiments.
Results
We present the evolution of our 7 metrics through time on Figure 3. CDPG is the only method stably decreasing expected DKL(pc, πθ) and thus approaching (as opposed to drifting away from) optimal distributions pc. This is reflected in moderate divergence from a and translates into downstream metrics. Summaries generated by the fine-tuned model contain, on average, more named entities. Moreover, name entities in summaries are both more factually consistent with source (an increase in precision-source) and more relevant (an increase in recall-target). The tendency towards mentioning more factually consistent named entities increases the bigram diversity within summaries (Distinct-2) and the overall quality of generated summaries compared to ground truth (ROUGE-L). This last results might seem surprising given that CDPG did not have access to ground truth summaries. A plausible explanation is that the original pretrained model was biased towards mentioning too few factually correct entities, at least compared to ground truth summaries. Satisfying the factual consistency constraint reduced this bias.
Baseline approaches fall short of achieving similar results. The DPG-like ablation, the closest contender, still leaves a significant gap in terms of all metrics and is far less stable than CDPG (e.g. its DKL(pc, πθ) starts to diverge again after around 500 epochs). Ziegler stays extremely close to the original model a, failing to improve its shortcomings. In contrast, Reinforce heavily departs from a pushing it to mention a large number of named entities. This results in artificially inflated recall-target but no increase in precision-source and a decrease in ROUGE-L. The additional named entities frequently are frequently irrelevant (i.e. not mentioned in ground truth summaries) or simply hallucinated. See Tables 8-12 in the Appendix for randomly chosen summaries of documents in the test set.

3.4. Code generation
Dataset
For code generation experiments, we condition a language model on Python function signatures (both of methods and standalone functions) extracted from the Python150 dataset which consists of Python source code obtained from GitHub (Raychev et al., 2016). We use the code provided by (Roziere et al., 2020) for function extraction and randomly choose 5k functions for C_train and 5k for C_test. τ (c) is a uniform distribution over these signatures. Note that neither in fine-tuning nor in evaluation do we use ground truth function bodies.
Model
We conduct experiments using GPT-Neo (Black et al., 2021): an off-the-shelf, freely available autoregressive language model mirroring the GPT-3 architecture (Brown et al., 2020). GPT-Neo’s training set included 85 GiB of source code from GitHub which endowed it with some code completion abilities (Gao et al., 2020). We use the gpt-neo-125 variant available on Huggingface Transformers (Wolf et al., 2019). During both fine-tuning and evaluation we generate function bodies by conditioning on signatures using pure ancestral sampling.
Constraints
For experiments with compilability control condition, we check compilability of a Python function declaration obtained by concatenating [c, x] and trying to execute it. b(x, c) = 1 if the Python interpreter raises an exception and 0 otherwise. See Appendix A.4 for more details.
For experiments with PEP8-compliance control condition, we check whether a function declaration given by [c, x] violates PEP8 (van Rossum et al., 2001), the style guide for Python, by running pycodestyle, an off-the-shelf linter (static code analysis tool).4 b(x, c) = 1 if the number of PEP8 violations found by pycodestyle is 0, otherwise b(x, c) = 0.
https://github.com/PyCQA/pycodestyle
Metrics
We evaluate the quality of generated Python functions using the following metrics:
1. PEP8 error count, the average number of violations of PEP8,
2. Compilability, the fraction of samples [c, x] that compile,
3. The average number of characters in [c, x] (after detokenization),
4. The average number of nodes in an abstract syntax tree (AST) of sequences that compile. Intuitively, this metric indicates the logical (as opposed to surface) complexity of generated programs.
For more details on how scorers b and metrics are implemented, see Appendix A.4.
Results
We present the evolution of metrics through time on Figure 4. CDPG was able to increase the fraction of compilable functions from around 40% to around 65% and decrease the average number of PEP8 violations. Incidentally, the PEP8 control objective also leads to an increase in compilability because many PEP8 violations are also compilation errors. Here we note similarly to the results of previous experiments that, CDPG and its DPG-like ablation are the only methods actually approaching optimal distributions pc and diverging moderately from a. This allows them to maintain the original statistics of a: length and the number of nodes in AST trees of generated functions. In contrast, Reinforce learns to generate shorter functions (having less opportunity for mistakes) and Ziegler produces heavily degenerated samples (Holtzman et al., 2020): syntactically simple functions with severe repetitions. This is reflected in an increase in length and a decrease in AST nodes count. See Tables 13-15 and Tables 16-18 for randomly chosen samples from the compilability and PEP8 experiments, respectively.
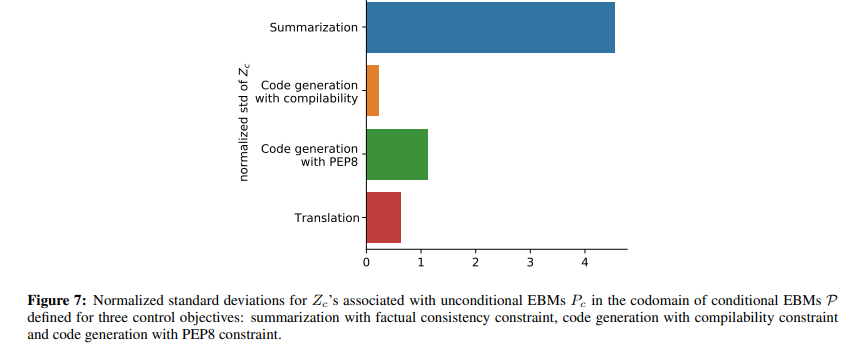
Note that the performance gap between CDPG and its DPG-like ablation is much closer for code generation (especially with compilability control objective) than for summarization. This can be accounted for by the normalized standard deviation of partition functions Zc for EBMs Pc in the range of conditional EBMs P for each control objective. For code generation, this standard deviation is lower meaning that Zc in (9) is better approximated by a constant which can be absorbed into the learning rate α (θ) . For summarization, this variance is higher, therefore ignoring the Zc term incurs higher bias which translates into worse performance. See Appendix A.5 for a comparison.

3.5. Qualitative analysis
In the previous sections, we showed how CDPG is able to fine-tune a pretrained model a to satisfy certain constraints without destroying a’s capabilities. Here we attempt to gain a better understanding of how different fine-tuning approaches affect the distributions of final models. On Figure 5 we present frequencies of errors (for the code generation task) and named entities (for the summarisation task) obtained from fine-tuned models. While errors and named entities differ significantly in their frequency, CDPG consistently decreases frequencies of these errors and consistently increases the frequencies of all kinds of named entities, including the long tail of rare ones.
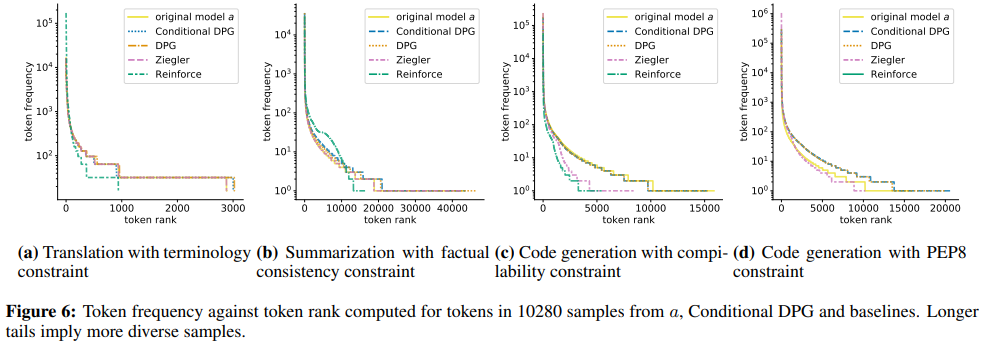
To compare lexical diversity of samples obtained from finetuned models (for all four tasks), we plot the frequency of each token (the number of times it occurs) and its rank (its index in a sorted list of tokens) in Figure 6. CDPG and its DPG-like ablation are able to closely match original token frequencies while Ziegler and Reinforce tend to have shorter tails of rare tokens.

4. Related work
Injecting prior information in machine translation
The “Statistical Machine Translation” paradigm (Koehn, 2010), which was dominant before the deep learning revolution in NLP, heavily exploited log-linear models over predefined features of translation pairs, but without the ability to learn representations typical of neural approaches. Building over such prior work, Zhang et al. (2017) propose to inject a regularization term over a neural translation model which asks for the posterior distribution to be close to a log-linear model using predefined features. This approach is similar to ours in that it allows to incorporate arbitrary features into the posterior distribution. In contrast to our work, the conditional model must be trained jointly with the log-linear one, instead of allowing to control an existing pre-trained model towards directly satisfying constraints. The task here explored is in the spirit of machine translation with terminological constraints (Chatterjee et al., 2017; Hasler et al., 2018; Dinu et al., 2019; ibn Alam et al., 2021). Some approaches to tackle it include constrained decoding (Chatterjee et al., 2017; Hasler et al., 2018), adding the desired terminology as part of the source context (Dinu et al., 2019), among others. Unlike the here-presented approach, these approaches are specific to this task only and will not generalize to arbitrary constraints.
Reducing hallucinations in summarization
Neural abstractive summarization is highly prone to hallucinate content in the summary that is unfaithful to the source document. Maynez et al. (2020) found that hallucinations occur in more than 70% of single-sentence summaries and most of these are extrinsic hallucinations: adding information not directly inferable from the input document. Therefore, a substantial effort was devoted to improving factual consistency of abstractive summarization. Some notable attempts include reranking summaries based on their correctness predicted by entailment classifiers (Falke et al., 2019) or fine-tuning using RL with a reward derived from an entailment classifier (Pasunuru & Bansal, 2018). The notion of entity-level factual consistency – a property such that all named entities in the summary are actually mentioned in the source document – was introduced by Nan et al. (2021) as one way of operationalizing the notion of extrinsic hallucinations.
Controllable code generation
Generating source code is an established application of language models (Nguyen et al., 2013; Raychev et al., 2014; Karpathy et al., 2015; Bielik et al., 2016) that since recently has enjoyed renewed interest (Lu et al., 2021; Chen et al., 2021; Austin et al., 2021). The task is formulated both as unconditional generation (with applications in code completion, e.g. Codex (Lu et al., 2021) or GitHub Copilot5 ) and as conditional generation (e.g. program synthesis or generating a program satisfying a given input-output specification, e.g. (Austin et al., 2021)). Our task of function generation can be seen as a simplified program synthesis with the specification given by function signature (a name of a function and a list of arguments). Previous work found compilability errors to be a signification failure mode of neural code generation (Roziere et al., 2020). Previous attempts at improving compilability of generated code include (Maddison & Tarlow, 2014), who augment neural probabilistic context free grammars with semantic constraints and use them for unconditional generation or (Zhong et al., 2017), who used policy gradients to train a model translating natural language questions to corresponding SQL queries and – in addition for rewarding for query execution results – added a penalty for syntactically invalid queries. Most in line with our work, Korbak et al. (2021) used DPG to improve compilability of unconditional language models for code.
5. Conclusion
We presented CDPG, a principled approach to fine-tuning conditional language models to satisfy arbitrary constraints. In contrast with other methods, CDPG does not require ground truth training data and is able to shift model distribution in a minimally invasive way. In consequence, models fine-tuned with CDPG share desired characteristics, such as improved factual consistency or compilability, with the fluency and diversity of the original model.
Future work could evaluate CDPG on other tasks — such as dialogue — as well as explore other control objectives such as constraining the semantics (as opposed to syntax) of generated Python functions. Another future direction consists in extending CDPG to approximate conditional analogues of the more general, exponential-form (Khalifa et al., 2021) EBMs which can represent distributional constraints, namely, desired expected values for certain features of generated samples.
A. Details of metric and score calculation
A.1. KL divergences


A.2. Translation
We implement the scorer for number normalization as a lookup table mapping a numeral noun (e.g. “one”) to a digit (“1”). Digits range from 1 to 9. A constraint is satisfied if for every occurrence of a given numeral noun in source sentence x, a corresponding digit occurs in its translation x.
To compute BLEU-4 score, we use the SacreBLEU implementation (Post, 2018).
A.3. Summarization
Following (Nan et al., 2021), we implement NER(·) as using a pretrained SpaCy (Honnibal et al., 2020) named entity recognizer. We use the en_core_web_sm model and restrict the named entities we extract to the following categories: PERSON, FAC (buildings, airports, highways, bridges, etc.), GPE (geopolitical entities: countries, cities, etc.), ORG (companies, agencies, institutions, etc.), NORP (nationalities or religious or political groups), LOC (Non-GPE locations: mountain ranges, bodies of water, etc.), EVENT (named hurricanes, battles, wars, sports events, etc.). Also following (Nan et al., 2021), we ignore entities such as date, time and numerals due to large variation in their representation in documents.
A.4. Code generation
Compilability
To check for compilability, we call the compile_command function from the codeop module of Python Standard Library6 with a sequence obtained by string concatenation [c, x] as argument. We then check if compile_command returns a code object. The only postprocessing we apply is removing any characters from x after the end of function declaration (with function end defined in terms of indentation) as we are concerned specifically with function generation. codeop.compile_command is the implementation that Python interactive interpreters use in read-eval-print loop (REPL) to determine whether a string is a valid Python code. The method tries to compile a string of Python code and raise and exception if compilation fails, for instance a SyntaxError for invalid Python syntax and ValueError or OverflowError if there is an invalid literal. Note that our notion of compilability is concerned only with syntactic correctness as Python interpreter does not execute the body of a function at function declaration time.
PEP8
To compute the number of PEP8 violations triggered by a sequence [c, x], we run pycodestyle,7 a Python linter (static code analysis tool) and report the number of violations it reports.
AST
node count Finally, to compute AST node count, the average number of nodes in an abstract syntax trees (ASTs) of generated functions, we consider only samples [c, x] that compile. They are parsed to their corresponding ASTs using the ast module from Python Standard Library.8
A.5. Normalized standard deviations for Zc across tasks

'RL > RL' 카테고리의 다른 글
f-DPG (0) 2024.12.23 Aligning Language Models with Preferences through f-divergence Minimization (0) 2024.12.23 (3/3) GAN, F-Divergence, IPM (0) 2024.12.22 (2/3) GAN, F-Divergence, IPM (0) 2024.12.21 (1/3) GAN, F-Divergence, IPM (0) 2024.12.20