-
DiffusionAD: Norm-guided One-step Denoising Diffusion for Anomaly Detection*Generative Model/Generative Model 2024. 4. 16. 12:48
https://arxiv.org/pdf/2303.08730.pdf
Abstract
Anomaly detection has garnered extensive applications in real industrial manufacturing due to its remarkable effectiveness and efficiency. However, previous generative-based models have been limited by suboptimal reconstruction quality, hampering their overall performance. We introduce DiffusionAD, a novel anomaly detection pipeline comprising a reconstruction sub-network and a segmentation sub-network. A fundamental enhancement lies in our reformulation of the reconstruction process using a diffusion model into a noise-to-norm paradigm. Here, anomalous regions are perturbed with Gaussian noise and reconstructed as normal, overcoming the limitations of previous models by facilitating anomaly-free restoration. Additionally, we propose a rapid one-step denoising paradigm, significantly faster than the traditional iterative denoising in diffusion models. Furthermore, the introduction of the norm-guided paradigm elevates the accuracy and fidelity of reconstructions. The segmentation sub-network predicts pixel-level anomaly scores using the input image and its anomaly-free restoration. Comprehensive evaluations on four standard and challenging benchmarks reveal that DiffusionAD outperforms current state-of-the-art approaches, demonstrating the effectiveness and broad applicability of the proposed pipeline.
1. Introduction
Similar to how human perception and visual systems work, anomaly detection involves identifying and locating anomalies with little to no prior knowledge about them. Over the past decades, anomaly detection has been a mission-critical task and a spotlight in the computer vision community due to its wide range of applications.
Given its importance, a great number of work has been devoted to anomaly detection (AD). Due to the limited number of anomaly samples and the labor-intensive labeling process, detailed anomaly samples are not available for training. As a result, most recent studies on anomaly detection have been performed without prior information about the anomaly, i.e., unsupervised paradigm. These methods include, but are not limited to, feature embeddings and generative models. Feature embedding-based methods often suffer from degraded performance when the distribution of industrial images differs significantly from the one used for feature extraction, as they rely on pre-trained feature extractors on extra datasets such as ImageNet. Generative model-based methods require no extra data and are widely applicable in various scenarios. These approaches generally use autoencoderbased networks (AEs), based on the assumption that after the encoder has compressed the input image into a lowdimensional representation, the decoder will reconstruct the anomalous region as normal. However, as shown in Fig. 1, the AE-based paradigm has limitations: I) it may result in an invariant reconstruction of abnormal regions as the low-dimensional representation compressed from the original image still contains anomalous information, leading to false negative detection. II) AEs may perform a coarse reconstruction of normal regions due to limited restoration capability and introduce many false positives, especially on datasets with complex structures or textures.

To address the aforementioned issues, we propose a novel generative model-based framework consisting of a reconstruction sub-network and a segmentation sub-network for anomaly detection named DiffusionAD.
Firstly, we reframe the reconstruction process as a noise-to-norm paradigm by introducing Gaussian noise to perturb the input image, followed by a denoising model to predict the added noise. We implement noise addition and denoising via the diffusion model due to its excellent density estimation capability and high sampling quality.
The proposed paradigm offers two advantages, as shown in the fifth column of Fig. 1: I) The anomalous regions are treated as noise after losing their distinguishable features, which enables a anomaly-free reconstruction of the anomalous regions instead of an invariant one. II) It aims to cover the whole distribution of normal appearance, which enables fine-grained reconstruction instead of a coarse reconstruction.
After that, the segmentation sub-network predicts the pixel-wise anomaly score by exploiting the inconsistencies and commonalities between the input image and its reconstruction.
Equipped with the noise-to-norm paradigm, DiffusionAD reconstructs more satisfactory results and thus improves the performance of anomaly detection. However, as a class of likelihood-based models, diffusion models generally require a large number of denoising iterations (typically about 50 to 1000 steps) to obtain optimal reconstructions from randomly sampled Gaussian noise, which is much slower than the real-time requirements in practical AD scenarios as shown in Fig. 2. To address this issue, we introduce a one-step denoising paradigm for anomaly detection that employs a diffusion model to predict the noise once and then directly predict the reconstruction result. This paradigm achieves hundreds of times faster inference speed than the conventional iterative denoising paradigm while maintaining comparable recovery quality.

Nonetheless, anomaly detection consistently poses a nontrivial challenge, mainly due to the inherent diversity in the representation of anomalies. These variants encompass subtle anomalies as well as more conspicuous ones, which are characterized by larger anomaly regions or semantic alterations. We observe that different types of anomalies require different noise scales for efficient recovery, especially within the one-step denoising paradigm. Specifically, when anomalies are relatively minor, a one-step prediction stemming from a smaller noise scale proves more advantageous, yielding superior pixel-level restoration quality. For more pronounced anomalies, the strategic application of a larger noise scale to perturb them followed by a one-step reconstruction results in enhanced semantic-level restoration quality. Therefore, we further introduce a norm-guided paradigm that leverages direct predictions from larger noise scales to guide the reconstruction of smaller noise scales, leading to superior reconstruction outcomes. Ultimately, DiffusionAD achieves SOTA anomaly detection performance and fast inference speed compared to other diffusion-free paradigms, as demonstrated in Fig. 2. This truly fulfills the effectiveness and efficiency requirements of real-world application scenarios.
The main contributions of this paper are summarized in the following:
- We propose DiffusionAD, a novel pipeline that reconstructs the input image to an anomaly-free restoration via the noise-to-norm paradigm and further predicts pixel-wise anomaly scores by exploiting inconsistencies and commonalities between them.
- We propose a one-step denoising paradigm to significantly speed up the denoising process. Moreover, we propose the norm-guided paradigm to achieve superior reconstruction results.
- We conduct comprehensive experiments on four datasets to demonstrate that DiffusionAD significantly outperforms the previous SOTA by a large margin in terms of anomaly detection and localization.
2. Related Work
Anomaly Detection.
Modern methods for anomaly detection encompass two main paradigms: feature embedding-based approaches and generative model-based approaches.
Methods based on feature embeddings typically extract features of normal samples through a model pre-trained on ImageNet and then perform anomaly estimation. Built on top of extracted features, knowledge distillation estimate anomalies by comparing the differences in anomaly region features between teacher and student networks. There are also extensive studies estimating anomalies by measuring the distance between an anomalous sample and the feature space of normal samples.
On the other hand, generative model-based methods do not require additional data. The core idea of generative model-based approaches is to implicitly or explicitly learn the feature distribution of the anomaly-free training data. Generative models based on VAE introduce a multidimensional normal distribution in the latent space for normal samples and then estimate the anomaly by the negative log-likelihood of the established distribution. GAN-based generative models estimate anomalies through a discriminative network that compares the query image with randomly sampled samples from the latent space of the generative network. Besides, several works introduce proxy tasks based on the generative paradigm, such as image inpainting and attribute prediction. Normalizing Flow-based methods combine deep feature embeddings and generative models. These methods estimate accurate data likelihoods in the latent space by learning bijective transformations between normal sample distributions and specified densities.
Diffusion Model.
Diffusion models, a class of generative models inspired by non-equilibrium thermodynamics, define a paradigm in which the forward process slowly adds random noise to the data, and the reverse constructs the desired data samples from the noise. Recently, a wide range of diffusion-based perception applications has emerged, such as image generation, image segmentation, object detection, etc. AnoDDPM tentatively explores the application of diffusion models to reconstruct medical lesions in the brain. However, it measures unhealthy outliers by squared error, leading to a high false positive rate. In addition, the iterative denoising approach employed in AnoDDPM leads to a notably slow inference speed and substantial computational cost.
3. Preliminaries
Denoising diffusion models.
A family of generative models called denoising diffusion models are inspired by equilibrium thermodynamics. In particular, a diffusion probabilistic model specifies a forward diffusion phase in which the input data are progressively perturbed by adding Gaussian noise over several steps and then learns to reverse the diffusion process to recover the desired noise-free data from the noisy data. The forward noise process is defined as:

which transforms a data sample x0 into a noisy sample xt. Here, t is randomly sampled from {0, 1, ..., T},
α¯t =

and βi ∈ (0, 1) represents the noise variance schedule. This can be defined as a small linear schedule from β1 = 10^−4 to βT = 10^−2 . During training, a U-Net-like architectures ϵθ(x_t, t) is trained to predict ϵ by minimizing the training objective:

At inference stage, x_t−1 is reconstructed from noise x_t with the model ϵθ(x_t, t) according to:

where z ∼ N (0, I) and β˜ t = (1−α¯t−1) / (1−α¯t) * β_t. x_0 is reconstructed from x_t in an iterative way, i.e., xt → xt−1 → . . . → x0.
Classifier guidance and image guidance.
To improve the quality and diversity of generated samples, guided diffusion uses a pre-trained classifier pϕ(y|xt) to guide the diffusion sampling process, where y is the class label. The guiding process is defined as modifying the noise prediction by a guidance scale w:

Thus, the impact of class y on the generated results can be controlled by adjusting the parameter w.
To achieve a more diverse form of control, SDG utilizes the reference image r to guide the sampling process and reformulates Eq. (4) as follows:

where rt is obtained from Eq. (1) by perturbing r and sim(·, ·) is a measure of the similarity or correlation between two images.
4. Methodology
4.1 Architecture
Our proposed novel generative model-based framework consists of two components: a reconstruction sub-network and a segmentation sub-network, as shown in Fig. 3. With the proposed anomaly generation strategies (Sec. 4.4), We define x0 as the input image that is either normal (y = 0) or anomalous (y = 1).

Reconstruction sub-network.
We implement the reconstruction sub-network via a diffusion model, which reformulates the reconstruction process as a noise-to-norm paradigm. First, we use the diffusion forward process to corrupt the input image x0 at a random time step t to obtain xt via Eq. (1). The input image x0 gradually loses its discriminative features and approaches an isotropic Gaussian distribution as the time step increases. Then ϵθ (xt, t) is a function approximator intended to predict noise ϵ from xt and t, which is implemented with a U-Net-like architecture based on PixelCNN, ResNet, and Transformer. It is worth noting that after being perturbed by Gaussian noise, the anomalous pixels lose their distinctive features and tend to be treated by the model as injected noise. Consequently, the anomaly-free reconstruction xˆ0 can be obtained from Eq. (3) in an iterative manner.
Segmentation sub-network.
The segmentation subnetwork employs a U-Net-like architecture consisting of an encoder, a decoder, and skip connections. The input to the segmentation sub-network is a channel-wise concatenation of x0 and xˆ0. The segmentation sub-network learns to identify anomalies by exploiting the inconsistencies and commonalities between the input image x0 and its anomaly-free approximation xˆ0 to predict the pixel-wise anomaly score without post-processing. Remarkably, the learned inconsistency reduces false positives caused by slight pixel-wise differences between the normal region and its reconstruction and highlights significantly different regions.
4.2. Norm-guided One-step Denoising
Each iteration of the denoising process in the diffusion model corresponds to a round of network inference, requiring substantial computational resources and time. This presents a significant challenge for real-time inference.
One-step Denoising.
To this end, we employ a direct reconstruction method, which we refer to as one-step denoising, as an alternative to the iterative approach. More specifically, at any time step t, after the diffusion model predicts the noise ϵθ (xt, t) of xt by a single inference (one-step), direct recovery is always valid, as indicated by the following:
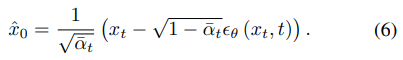
where xˆ0 refers to the anomaly-free reconstruction via onestep denoising. This direct prediction is t times faster than iterative prediction, resulting in significant savings of computational resources and inference time. However, we observe that repairing different types of anomalies requires different scales of noise injection. When the anomaly region is relatively small or absent, direct prediction from xts is more suitable, as shown in Fig. 4 (b). The anomaly-free restoration xˆ0s demonstrates higher pixel quality, preserving finegrained details and closely aligning with the iterative result. Conversely, predicting directly from xtb introduces some distortions, and as the time step t increases, these distortions gradually amplify. In cases where the anomaly region is larger or exhibits semantic changes, predicting from xts leaves some residual anomaly regions, as illustrated in Fig. 4 (b). Therefore, the injection of noise at larger scales becomes necessary to effectively perturb the anomalous regions in order to achieve higher quality, anomaly-free restoration xˆ0b at the semantic level.

Norm-guided Denoising.
In order to harness the advantages of both noise scale regimes, we propose a norm-guided denoising paradigm. We divide the random range of t ∈ {0, 1, ..., T} into two parts using τ , where S = {0, 1, ..., τ} and B = {τ + 1, τ + 2, ..., T}. For an input image x0, we first perturb it using two randomly sampled time steps ts ∈ S and tb ∈ B to obtain xts and xtb through Eq. (1). As the diffusion model defaults to being conditioned on t, we abbreviate ϵθ(xt, t) as ϵθ(xt). Subsequently, we first employ the diffusion model to individually predict the noise of xts and xtb , corresponding to ϵθ(xts ) and ϵθ(xtb ), respectively. We then directly predict xˆ0b using ϵθ(xtb ) by Eq. (6). Although xˆ0b exhibits some distortions and appears low in mass, it consistently presents an anomaly-free appearance despite the diversity of anomalies in x0. Hence, xˆ0b is regarded as xˆ0b ∼ q(x_y=0) and is rewritten as n. After that, n assumes the role of a conditional image to guide the prediction of xˆ0s by Eq. (5). We define sim(x_t, n_t) = − 1/2 * (n_ts − x_ts )^2 to measure the similarity between these two images. n_ts is obtained by perturbing n with the predicted noise ϵθ(x_ts ) instead of random noise in order to make the guidance more dependent on the difference between the image contents themselves. Thus, Eq. (5) is reformulated as follows:

where ϵθ(x_ts , n_ts ) denotes the modified noise with normguidance. Finally, bring x_ts and ϵθ(x_ts , n_ts) into Eq. (6) to directly predict the norm-guided anomaly-free reconstruction as follows:

Equipped with the norm-guided denoising paradigm, DiffusionAD can handle different types of anomalies and predict superior reconstructions.
4.3. Training & Inference
Training stage.
We jointly train the denoising and segmentation sub-networks. The diffusion model learns the entire distribution of normal samples (y = 0) by minimizing the following loss function:

The segmentation sub-network exploits the commonalities and differences between x0 and xˆ0g to predict pixel-wise anomaly scores as close as possible to the ground truth mask. The segmentation loss is defined as:

Where M is the ground truth mask of the input image and Mˆ is the output of the segmentation sub-network. Smooth L1 loss and focal loss are applied simultaneously to reduce over-sensitivity to outliers and accurately segment hard anomalous examples. γ ∈ R+ is a hyperparameter that controls the importance of L_focal. Thus, the total loss used in jointly training DiffusionAD is:

Inference stage.
Unlike other diffusion methods that reconstruct images in an iterative manner, we still perform a one-step norm-guided estimation in the inference stage, which is hundreds of times faster while maintaining comparable sampling quality. The robust decision boundary learned by the segmentation network will also effectively mitigate the effect of such sub-optimal sample quality. Moreover, in the inference phase, t_s and t_b are fixed values. After the segmentation model predicts the pixel-level anomaly score Mˆ , we take the average of the top K anomalous pixels in Mˆ as the image-level anomaly score.
4.4 Anomaly Synthetic Strategy
Since prior information about anomalies is not available for training, we synthesize pseudo-anomalies online for end-to-end training. The idea of our anomaly synthesis strategy is adding visually inconsistent appearances to the normal samples, and these out-of-distribution regions are defined as the synthesized anomalous regions.

Fig. 5 illustrates the overall process of transforming a normal sample (Fig. 5, N) into a synthetic anomalous sample (Fig. 5, S). Random and irregular anomalous regions (Fig. 5, P) are first obtained from the Perlin noise and then multiplied by the object foreground (Fig. 5, F) of the normal sample to obtain the ground truth mask (Fig. 5, M). For textural datasets, the foreground is replaced by a random part of the whole image. The appearance of visual inconsistencies (Fig. 5, A) mainly stems from the self-augmentation of normal samples or Describing Textures Dataset (DTD). The proposed synthetic anomaly (Fig. 5, S) is defined as:

where M¯ is the pixel-wise inverse operation of M, ⊙ is the element-wise multiplication operation, and β serves as an opacity parameter designed to enhance the fusion of anomalous and normal regions.
5. Experiments
5.1. Experimental Details
Datasets.
To assess the efficacy and generalizability of our approach, we conduct experiments on four diverse unsupervised datasets including MVTec, VisA, DAGM, and MPDD. These datasets contain samples of many different types of surface defects, such as scratches, cracks, holes, and depressions.
Evaluation Metrics.
To measure the performance of anomaly detection (image level), we report the Area Under Receiver Operator Characteristic curve (Image AUROC), the most widely used metric. In terms of anomaly localization (pixel level) performance, we report three metrics: Pixel AUROC, PRO, and Pixel AP.
Pixel AUROC may provide an inflated view of the performance, which may pose challenges in measuring the true capabilities of the model when using only this metric. The false positive rate is dominated by the extremely high number of non-anomalous pixels and remains low despite the false positive prediction, which is caused by the fact that anomalous regions typically only occupy a tiny fraction of the entire image.
Thus, to comprehensively evaluate the anomaly localization performance, Per Region Overlap (PRO) and pixel-level Average Precision (AP) also play the role of evaluation metrics. Per Region Overlap (PRO) metric is more capable of assessing the ability of fine-grained anomaly localization, which treats anomaly regions of varying sizes equally and is widely employed by previous works. AP is more appropriate for highly imbalanced classes, especially for industrial anomaly localization, where accuracy is critical.
Implementation Details.
All images in the four datasets are resized to 256 × 256.
For the denoising sub-network, we adopt the UNet architecture for estimating ϵ_θ. This architecture is mainly based on PixelCNN and Wide ResNet, with sinusoidal positional embedding to encode the time step t. T is set to 1000 and is divided by τ = 300 into two parts. The noise schedule is set to linear. We set the base channel to 128, the attention resolutions to 32, 16, 8, and the number of heads to 4. We do not use EMA.
For the segmentation sub-network, we employ a UNet-like architecture consisting of an encoder, a decoder, and skip connections. γ in the segmentation loss L_seg is set to 5.
We train for 3000 epochs with a batch size of 16 consisting of 8 normal samples and 8 anomalous synthetic samples. We use Adam optimizer for optimization, with an initial learning rate 10−4 . The image-level anomaly score is obtained by taking the average of the top 50 anomalous pixels in pixel-wise anomaly score Mˆ. We implement our model and experiments on NVIDIA A100 GPUs.
5.2. Anomaly Detection and Localization Results
We compare the anomaly detection and localization performance of DiffusionAD with four feature embedding-based methods, i.e., PatchCore, RD4AD, RD++, SimpleNet and three generative model-based methods, i.e., DMAD, FastFlow and DRAEM.
Per-class performance on VisA.
The results of anomaly detection (Image AUROC) and anomaly localization (PRO) on the VisA dataset are shown in Tab. 1. Our method achieves the highest image AUROC and the highest PRO in 10 out of 12 classes. The average image AUROC results show that our method outperforms feature embeddingbased SOTA by 2.0% and generative model-based SOTA by 3.3%. Meanwhile, for PRO, our method outperforms feature embedding-based SOTA by 2.6% and generative model-based SOTA by 4.7%. In some hard cases, such as capsules and macaroni2, DiffusionAD outperforms previous generative model-based methods by a large margin.

Quantitative results across the four datasets.
Tab. 2 enumerates the performance of the aforementioned methods across the four datasets. We conduct a comprehensive comparison based on four metrics, which include image AUROC for anomaly detection and pixel AUROC, PRO, and pixel AP for anomaly localization. In addition to its performance on the VisA dataset, DiffusionAD achieves state-of-the-art results on another widely used dataset, MVTec, across four key metrics. Remarkably, DiffusionAD outperforms the previous feature embedding-based SOTA by 15.3% and the previous generative model-based SOTA by 7.7% in terms of average pixel AP metric. Our method also outperforms previous approaches on the DAGM and MPDD datasets, especially in terms of average image AUROC. Finally, we evaluate the generalization ability of the method by measuring its average performance across the four datasets. As shown in Tab. 2, our approach significantly outperforms previous methods and in particular, outperforms previous generative models by a large margin. More details will be provided in Sec. 7.

Qualitatively evaluate on anomaly localization.
According to the results in Fig. 6, we qualitatively assess the performance of DiffusionAD on anomaly detection and localization compared to the previous feature embedding-based method PatchCore and generative model-based method DRAEM. These images are sub-datasets of MVTec and Visa, where the anomalous regions vary in shape, size and number, as shown in the first and second columns of Fig. 6. The third and fourth columns show the reconstruction and anomaly localization results of DiffusionAD, respectively. It can be observed that the reconstruction sub-network successfully repairs various types of anomalies while maintaining high image fidelity. After that, the segmentation subnetwork accurately predicts the pixel-wise anomaly score using the input image and its anomaly-free reconstruction, leading to more accurate anomaly localization than previous methods such as DRAEM and PatchCore.

5.3. Ablation Study
The importance of architecture and denoising paradigm.
Tab. 3 illustrates the impact of different architectures and denoising methods on performance and inference speed. We introduce FPS (Frames Per Second) to evaluate the inference speed. As indicated in the first row of Tab. 3, the performance of anomaly detection and localization is limited due to the unsatisfactory reconstruction results of the Autoencoder (AE.). However, its inference speed is notably fast. When we adopt the proposed noise-to-norm paradigm, as seen in the second row, which utilizes higher-quality reconstructions from the diffusion model (DM.), the performance is significantly enhanced. Nonetheless, each denoising iteration (Ite.) corresponds to one network inference (in this case, 400 iterations in total), which falls significantly short of the real-world requirements for inference speed. In the third row, when we employ the proposed one-step (OS.) denoising, the inference speed is approximately 300 times faster than the iterative approach. Simultaneously, there is an improvement in both anomaly detection and localization performance. We attribute this to the comparable quality of one-step reconstruction results and the consistent training and inference paradigm, where the segmentation sub-network always receives the one-step reconstructions during training. In the fourth row, the norm-guided (NG.) paradigm combines the advantages of both one-step reconstructions from different noise scales, leading to further performance enhancements while maintaining comparable inference speed.

The effect of noise scale.
We investigate how the added noise scale of the input individually affects the reconstruction results and anomaly detection performance. First, Fig. 7 illustrates the effect of the noise scale on the quality of the reconstruction. The second column of Fig. 7 shows the gradual denoising results from t = 400, which can be considered as the ideal recovery. For one-step reconstruction, direct prediction becomes more challenging as the noise scale increases, resulting in lower pixel quality. However, repairing more pronounced anomalies often requires larger noise scales to perturb the anomalies, leading to reconstructions with higher semantic quality. Thus, the norm-guided one-step approach combines the advantages of both scales, resulting in a reconstruction that encompasses both pixel and semantic quality, closely approximating the quality of the iterative one.

Fig. 8 further depicts the effect of different noise scales on the anomaly detection performance. In the iterative approach, the predictions of the segmentation network show little variation, as the reconstruction results are consistent. However, the inference time increases with t. In the one-step denoising approach, the inference time remains constant, but there is a decrease in Image AUROC as t becomes relatively large, mainly due to the reduced reconstruction quality. It is worth noting that the proposed one-step denoising paradigm consistently achieves superior anomaly detection performance compared to the iterative one.

Effects of guidance scale.
As shown in Fig. 9, the influence of conditional information becomes more significant as the guidance scale w increases. In this paper, w is set to 1 as an empirical choice.

6. Conclusion
In this paper, we present DiffusionAD, a novel anomaly detection pipeline consisting of a reconstruction sub-network and a segmentation sub-network. Firstly, we redefine the reconstruction process using a diffusion model, adopting the noise-to-norm paradigm where anomalous regions are perturbed by Gaussian noise and then reconstructed to appear normal. Secondly, we present a one-step denoising paradigm, which is significantly faster than the iterative denoising approach in diffusion models. In addition, we propose the norm-guided paradigm to further enhance the reconstruction quality. Finally, the segmentation sub-network exploits the inconsistencies and commonalities between the input image and its anomaly-free restoration to predict pixel-level anomaly scores. Extensive evaluations across four datasets demonstrate that DiffusionAD outperforms current state-of-the-art methods, highlighting the effectiveness and wide applicability of this novel pipeline.
7. Appendix
Reference
'*Generative Model > Generative Model' 카테고리의 다른 글
[DDPM] Denoising Diffusion Probabilistic Models - Theory to Implementation (0) 2024.04.22 Denoising Diffusion Probabilistic Models 정리 (0) 2024.04.21 Introduction to Diffusion Models (0) 2024.04.15 [SA-VAE] Semi-Amortized Variational Autoencoders (0) 2024.04.08 [IWAE] Importance Weighted Autoencoders (0) 2024.04.07