-
Pixel Recurrent Neural NetworksResearch/Generative Model 2024. 5. 14. 11:53
https://www.youtube.com/watch?v=-FFveGrG46w


1. Variational autoencoders use a latent vector z to encode and decode the images so VAE's are good at efficient inference which just means they generate images quickly and efficiently. Unfortunately the generated samples end up being blurrier than other models.
2. Generative adversarial networks use an adversarial loss to train their models. Gans generates sharper images than VAEs and they don't need any kind of approximation which is good but they're hard to optimize because they're unstable dynamics created by the adversarial nature.
3. Autoregressive models which pixel CNN and pixel RNN is one of those autoregressive model, directly model the distribution of pixels so this makes it simple and has a stable training process and this also gives the best test set results on log likelihood. Unfortunately it makes it relatively inefficient when doing generation it takes a long time to generate an image.
PixelRNN

PixelRNN treats an image as a sequence of pixels going row by row. So each pixel is dependent on the previous pixels that have been generated already.
They represent the probability of an image X as the product of conditional probabilities for each pixel where the probability of pixel Xi is represented as the probability conditioned on all the previous pixels.
Image Generation
How an image is generated using pixelRNN.
First sample the first pixel X1. Send it through the RNN as input and this will generate (predict) the next pixel2. Then send pixel2 back through the generator to generate pixel 3 and keep doing this until generate the whole image.
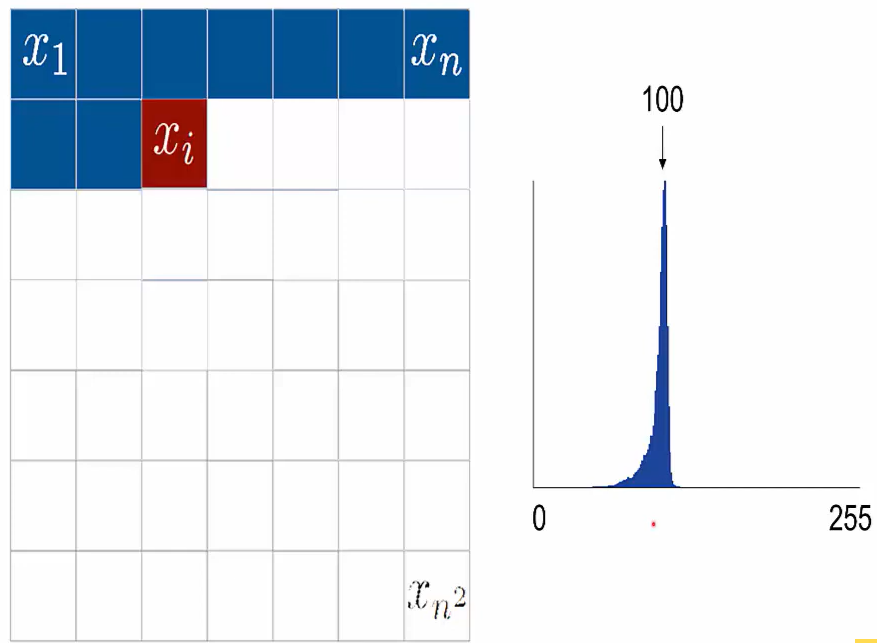
PixelRNN does this by having a softmax layer as its last layer. The softmax layer has 256 units, each one representing one of the possible values that a pixel can have 0 to 255 so what each value represents is the probability of generating that pixel intensity.
In this example we see that it's very likely to output a pixel of intensity about 100 so what the model does is chooses the maximum of this distribution and uses that value as the pixel intensity for this pixel.

We have to do this for all three channels each one of them in order one at a time. So we start off with the Red channel.
PixelRNN basis its decision on all the previously generated pixels for all three channels so it looks at all of them and generates a softmax distribution, takes the maximum and creates the first pixel.

Now we go on to Green and generate it's pixel. It bases on all previously generated pixels including the one we just generated from Red and we do this because we want Green to be dependent on the Red pixel what it's just generated. We want that dependency there. So it generates a sofmax distribution and creates its pixel.
Then we do the same thing for Blue. It's base on all of the previously generated pixels and Red and Green.
Typical Architecture
Typical architecture used for all the models paper presents.

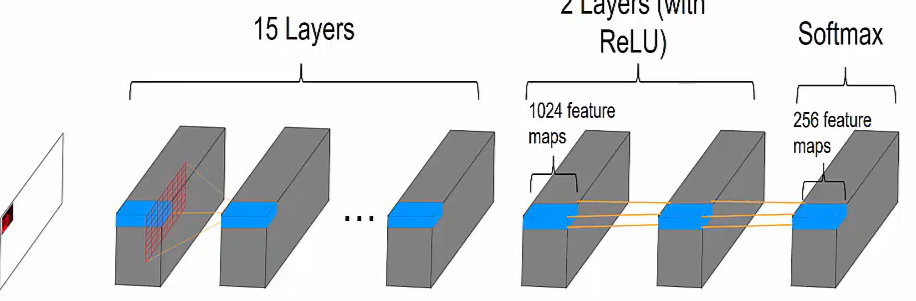
Start off with an image with height, width and three color channels. It goes through a 7 x 7 convolutional layer followed by several residual blocks which can be convolutional layers or LSTM layers based on what we're doing. Then we have two 1 x 1 convolutional layers. And then finally a softmax layer the output of the softmax layer is an image of the same size as an input but it has 256 values for each pixel which represents the probabilities of those intensity values.
PixelCNN (Generation Process)
How PixelCNN generates an image.

Start off with blank image with one for each channel. The output of the model is a softmax distribution for each channel.
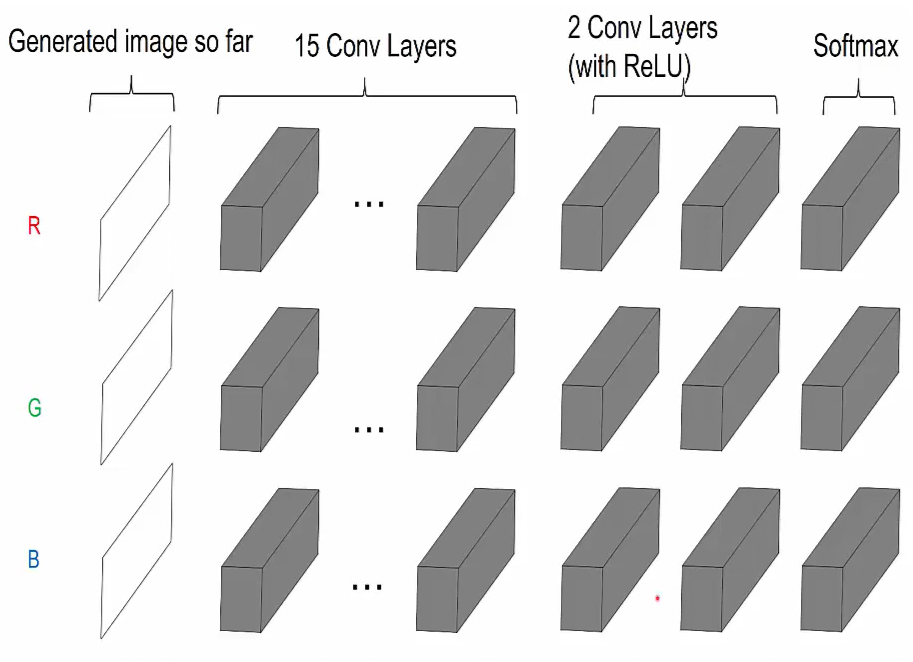
And in between we have several convolutional layers.
How the system works is it generates a pixel of one at a time for each channel one at a time as well.

Zoom in on the first on the Red channel to see how it generates its first pixel. First we just do a 7 x 7 convolution and this generates features for the first pixel for the first layer and this is of size 128.

Then we do the same thing for the next convolution layer.

And we're only doing this for one pixel at a time.

Then we do a 1 x 1 convolution for two more layers.

And then finally a softmax layer, so these 256 values make up a vector and we get the maximum and we use that value to fill in the first pixel for Red.

We go onto the first pixel Green and we do the same thing 7 x 7 convolution but it's also dependent on the pixel that was just generated for Red. So it's dependent on both of these pixels.

So we Generate these features for this pixel and then generate the Green pixel.
Then we move onto Blue and it's the same but it's dependent on all three.


Now that we've finished the first pixel, we can move onto the second pixel of Red. So it generates the features for Red and we keep doing this until we finish completing the image.

And we just consolidate all three channels to make one image.
This is really slow to do image generation. And this is because we have to wait to create pixel2 it's dependent on pixel1. It has to wait until pixel one has been generated. So it has to go one at a time that makes it really slow.
PixelCNN (Training)

For training, it's very similar but we start with the whole image at the beginning.
When we try to generate pixel2, we don't need to wait for pixel1 to be generated. We already have it because it's in training, we have it. So it doesn't need to wait for pixel1 to generate itself.
And pixel3 similar, it doen't need to wait for pixel 1 & 2 to be generated. It already has the information, so we can use that information to compute features for them all in parallel. We do them all at the same time which makes it much faster trained.
Kernel mask

When we training, we don't want to look at future pixels because we can see them but we shouldn't use them.
Because in the generation process, it won't have access to those future pixels they wouldn't have generated them yet.
So we uses a mask over our convolutional kernel. It zeros out those future pixels so we don't look at them in training.

As an example, if we're generating this image, and we want to generate Xi, then we apply a convolution and also apply this mask to it, so that we don't look at these zero pixels which are in the future, and we only use these ones that are in the past and we can apply the same mask during training so that it prevents you from looking at future pixels. so this is for the spatial layout.

We need to do the same thing for each color channel. Because each color channel should be dependent on only the previously generated color channels that were generated.
Red is dependent on only the previous pixels, not any of the other color channels for the current pixel.
Green is dependent all the previous pixels and the Red pixel that was just generated.
Blue is dependent on context and Red and Green.
PixelCNN Advantages / Disadvantages

An advantage of pixelCNN is it's very simple. It's just a bunch of convolutions.
And it's also the fastest to train because we can compute features all at the same time in parallel for the entire image.
Disadvantage is that it has the smallest receptive field which means it only looks at the pixels right around the current pixel. It doesn't look at the ones farther away.
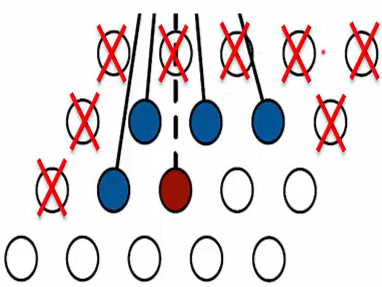
So it doesn't use all the available context. It ignores these even though these pixels have already been generated.
RNN Models

It's good with sequences of data. In our case, our sequence is a sequence of pixels that makes up the image.
Each of these X's is a pixel
We'll input a pixel into here goes through the RNN and outputs a hidden state vector.
We then use that hidden state vector to generate our prediction for the pixel.
So what the hidden state represents, it represents all pixels that come before it. So h2 represents pixel X2, X1 and X0. So it encodes all of them into this one vector and then hT represents all of the pixels in the image.
RNN for Image Generation
How does an RNN generate an image.

First we sample the first pixel. We send it through the RNN which generates a hidden state.
From the hidden state, we add an softmax layer of 256 and then it predicts(generates) pixel2.
We send pixel2 back through the RNN to generate pixel3.
We keep doing this until we've generated the entire image and we just reshape those pixels to make up the image.
LSTM Equations

Input gate, forget gate, output gate and candidate state, all four of these are gates which just control how much information that we allow to flow to the next time step of the LSTM.
All four of these have a similar structure. They all include Xi which represents the raw pixel values for the i-th timestep. They also have hidden state for the previous timestep which is shown by h_i-1.
Each of these are multiplied by a parameter matrix U and the parameter matrix W. These are summed up and then sigmoid or tanh.
c and h are States, they hold information about all the timesteps up to timestep i.

What this paper does is like a convolutionalLSTM, it replaces the fully connected layers with a convolutional layer.
Consolidate all four of these equations into one equation. So has these four outputs, one for each gate.
Instead of having a fully connected layer, we have a convolutional kernel that's convolved with the input X and convolutional kernel convolved with the hidden state h_i-1.

The peper keeps the states the same.
Row LSTM
Each state in Row LSTM represents an entire row.
When we compute the next state, we're computing the state for an entire row and that row is dependent on the previous rows (state).
We generate an entire row at a time but we don't do this with a fully connected layer, we do a sliding convolution from the previous row to generate the current pixel.

There are two components in gates equation.
The one dependent on the input and one dependent on the previous hidden state.
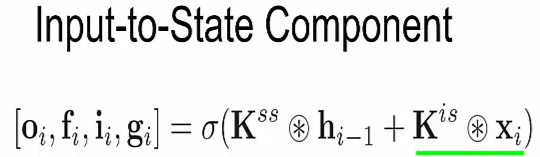
So this first one we call the Input-to-State component, they calculate this by doing a convolution with the input.

We want to generate this row of states, the third row, so we look at the same row in the image we do a convolution a 3 x 1 convolution from the image to generate each of these states. That's how you generate that row.

For the other component, the State-to-State component, we're looking at the hidden state but the previous row so we're looking at the second row and we do a 3 x 1 convolution to compute each of these states.

Now we can combine those two states according to the equation. We add them and then do a sigmoid. That's how we get our final state.

Advantages and Disadvantages
Advantage of this approach is we can compute the state for an entire row at one time and the reason we can do this is because we're not depending on pixels in the same row, so we don't have to wait for them to be generated. We already have the entire previous row generated so it can compute the entire row at once and that's good it makes training a lot faster but not as fast as pixelCNN. PixelCNN can compute all of the pixels at once not just one row.

Disadvantage is that it has a triangular receptive field which means when we're trying to compute this pixel, then it's dependent on a triangle above it.

This is bad because it doesn't use all the available context. It's ignoring these off to the side which have been generated but it's not using it.
It should be dependent on all those pixels so the way they fix this is introducing a new model called dianonal bi-LSTM.
Diagonal BiLSTM
Each state represents a diagonal of the image so we use the previous diagonal to generate the next diagonal and we generate entire diagonal at a time but again we use a convolution to generate those.


This current pixel is dependent on the pixels above it and the left of it to generate the current one.
It's called a Bi-directional LSTM because we do it from both directions from the left and from the right. So we generate diagonals all at the same time from the other direction.
Skew
To calculate the state for this red pixel where we depend on these two, we can do a convolution on these two, but it's hard to do this computationally so what they do is, skew this over by one.

They shift each row by one. And now these two pixels are aligned and so we can just do a 1x2 convolution to generate the red pixel and then we'll unskew it back whenever we're done.

We did it for one direction, now we need to do it for the other direction, so we skew it the other way and now we can do a convolution of these two. However, we're using this pixel here which is not right it's the future pixel, so we shouldn't look at it.

How they fix this is, they shift down the input map by one spot and they just use these two pixels to compute the hidden state for the red pixel.
Finished State-to-State Component
Now the finished state-to-state component is we just add up the two input maps together so that takes into account both directions at the same time.

Advantages

Advantages of this is you can compute the state for an entire diagonal at once which is fast and it's about as fast as a rowLSTM but still not as fast as pixelCNN.
It has a global receptive field which means it takes into account all of the available contexts, all of these pixels have been generated already. and it's using all of them which is excellent exactly what we want.
'Research > Generative Model' 카테고리의 다른 글
Variational Inference with Normalizing Flows (0) 2024.05.15 [Gated PixelCNN] PixelCNN's Blind Spot (0) 2024.05.14 Pixel Recurrent Neural Networks (0) 2024.05.14 What is a variational autoencoder? (0) 2024.05.11 Variational autoencoders (0) 2024.05.10