-
Reinforcement Learning from Human Feedback (RLHF)Research/NLP_Stanford 2024. 6. 24. 12:31
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=SXpJ9EmG3s4&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=10
Lecture 10 - Prompting & Reinforcement Learning from Human Feedback (RLHF)

So we're going to explicitly try to satisfy human preferences, and come up with a mathematical framework for doing so.
These are the limitations as I just mentioned. So this is where we get into reinforcement learning from human feedback.
So RLHF. Let's say we were training a language model on some task, like, summarization. And let's imagine that for each language model sample, S, let's imagine that we had a way to obtain a human reward of that summary. So we could score this summary with a reward function, which we'll call R of S, and the higher the reward, the better.
So let's imagine we're summarizing this article, and we have this summary, which maybe is pretty good. Let's say we had another summary, maybe it's a bit worse. And if we were able to ask a human to just rate all these outputs, then the objective that we want to maximize or satisfy is very obvious.
We just want to maximize the expected reward of samples from our language model. So in expectation, as we take samples from our language model, P_theta, we just want to maximize the reward of those samples.
This kind of task is the domain of reinforcement learning. The field of reinforcement learning has studies these kinds of optimization problems, of how to optimize something while you're simulating the optimization.
For many years now, and in 2013, there was a resurgence of interest in reinforcement learning for deep learning specifically. So you might have seen these results from DeepMind about an agent learning to play Atari games, an agent mastering go, much earlier than expected. But interestingly, I think, the interest in applying reinforcement learning to modern LMs is a bit newer on the other hand. And I think the earliest success story, or one of the earliest success stories was only in 2019, for example.
Why might this be the case? There's a few reasons. I think in general, the field had this sense that reinforcement learning with language models was really hard to get right, partially, because language models are very complicated.
And if you think of language models as actors that have an action space where they can spit out any sentence, that's a lot of sentences. So it's like a very complex space to expore in. So it still is a really hard problem. So that's part of the reason.
But also practically, there have been these newer algorithms that seem to work much better for deep neural models, including language models, and these include algorithms like proximal policy optimization. These are the reasons why we've been really interested in this idea of doing RL with language models.

How do we actually maximize this objective? We should change our parameters theta so that reward is high. But it's not really clear how to do so. So when we think about it, we know that we can do gradient descent or gradient ascent.
So let's try doing gradient ascent. We're going to maximize this objective, so we're going to step in the direction of steepest gradient. But this quickly becomes a problem, which is, what is this quantity and how do we evaluate it? How do we estimate this expectation given that the variables of the gradient that we're taking, theta, appear in the samples of the expectation.
And the second is, what if our reward function is not differentiable? Like, human judgements are not differentiable, we can't backprop through them. And so we need this to be able to work with a Black box reward function.
So there's a class of methods in reinforcement learning called policy gradient methods that gives us tools for estimating and optimizing this objective.

We want to obtain this gradient, so it's the gradient of the expectation of the reward of samples from our language model. And if we do the math, if we break this apart, this is our definition of what an expectation is. We're going to sum over all sentences weighted by the probability. And due to the linearity of the gradient, we can put the gradient operator inside of the sum.
Now what we're going to do is we're going to use a very handy trick known as a log derivative trick. And this is called a trick, but it's really just the chain rule. But let's just see what happens when we take the gradient of the log probability of a sample from our language model.
So if I take the gradient, then how do we use the chain rule? So the gradient of the log of something is going to be 1 over that something times the gradient of the middle of that something. So 1 over P_theta of s times the gradient. And if we rearrange, we see that we can alternatively write the gradient of P_theta of s as this product, so P_theta of s times the gradient of the log P_theta of s. And we can plug this back in.
And the reason why we're doing this is because we're going to convert this into a form where the expectation is easy to estimate.
So we plug it back in, that gives us this, and if you squint quite closely at this last equation here, this first part here, is the definition of an expectation. We are summing over a bunch of samples from our model, and we are weighting it by the probability of that sample, which means that we can rewrite it as an expectation. And in particular, it's an expectation of this quantity here. So let's rewrite it. And this gives us newer form of this objective.
So these two are equivalent the top here and the bottom. And what has happened here is we've shoved the gradient inside of the expectation. So why is this useful?
We've put the gradient inside the expectation, which means we can now approximate this objective with Monte Carlo samples. So the way to approximate any expectation is to just take a bunch of samples and then average them.
So approximately, this is equal to sampling a finite number of samples from our model, and then summing up the average of the reward times the gradient of the log probability of that sample.
And that gives us this update rule, plugging it back in for that gradient ascent step that we wanted. So what is this? What does this mean?
Let's think about a very simple case, imagine the reward was a binary reward. So it was either 0 or 1. So for example, imagine we were trying to train a language model to talk about cats. So whenever it utters a sentence with a word cat, we give it a one reward, otherwise, we give it a 0 reward.
Now if our reward is binary, what this objective reduces to, the reward would be 0 everywhere, except for sentences that contain the word cat. And in that case, it would be 1. So basically, that would just look like kind of vanilla gradient descent, just on sentences that contain the word cat.
To generalize this to the more general case where the reward is scalar, what this is looking like, if you look at it, if R is very high, very positive, then we're multiplying the gradient of that sample by a large number. And so our objective will try to take gradient steps in the direction of maximizing the probability of producing that sample again, producing the sample that led to high reward.
And on the other hand, if R is low or even negative, then we will actively take steps to minimize the probability of that happening again.
The reason why we call it reinforcement learning is because we want to reinforce good actions and increase the probability that they happen again in the future.

So now we are set. We have a bunch of samples from a language model, and for any arbitrary reward function, like, we're just asking a human to rate these samples, we can maximize that reward. Not so fast. There's a few problems.
The first is the same as in the instruction fine tuning case, which is that keeping a human in the loop is expensive. Like, I don't really want to supervise every single output from a language model. So what can we do to fix this?
One idea is, instead of needing to ask humans for preferences every single time, you can actually build a model of their preferences. Like, literally, just train an NLP model of their preferences. So this idea was first introduces outside of language modeling by this paper, Knox and Stone. And they called it TAMER, but we're going to see it re-implemented in this idea where we're going to train a language model. We'll call it a reward model, RM, just parameterized by phi, to predict human preferences from an annotated data set. And then when doing RLHF, we're going to optimize for the reward model rewards, instead of actual human rewards.

Here's another conceptual problem. So here's a new sample for our summarization task. What is the score of this sample? What scale are we using?
The issue here is that human judgements can be noisy and miscalibrated when you ask people for things alone. So one workaround for this problem is instead of asking for direct ratings, ask humans to compare two summaries and judge which one is better.
This has been shown in a variety of fields where people work with human subjects and human responses to be more reliable. This includes psychology and medicine, et cetera. So in other words, instead of asking humans to just give absolute scores, we're going to ask humans to compare different samples, and rate which one is better.
So as an example, maybe this first sample is better than the middle sample, and it's better than the last sample. Now that we have these pairwise comparisons, our reward model is going to generate latent scores.
So implicit scores based on this pairwise comparison data. So our reward model is a language model that takes in a possible sample, and then it's going to produce a number, which is the score, or the reward.
And the way that we're going to train this model, this is a classic statistical comparison model, is via the following loss where the reward model should predict a higher score if a sample is judged to be better than another sample. So in expectation, if we sample winning samples and losing samples from our data set, then if you look at this term here, the score of the winning sample should be higher than the score of the losing sample.
And in doing so, by just training on this objective, you will get a language model that will learn to assign numerical scores to things, which indicate their relative preference over other samples, and we can use those outputs as rewards.

So does the reward model work? Can we actually learn to model human preferences in this way? This is obviously an important sanity check before we actually try to optimize this objective. And they measured this.
So this is evaluating the reward model on a standard validation set. Can the reward model predict outcomes for data points that they have not seen during training, and does it change based on model size or amount of data?
And if you noticed here, there's one dash line, which is the human baseline, which is, if you ask a human to predict the outcome, a human does not get 100% accuracy because humans disagree, and even in ensemble of five humans also doesn't get 100% accuracy because humans have different preferences.
But the key takeaway here is that for the largest possible model, and for enough data, a reward model, at least some of the validation set that they used is approaching the performance of a single human person.
That's a green light that maybe we can try this out and see what happens.
So this is the components of RLHF.
We have a pre-trained model, maybe it's instruction fine-tuned, which we're going to call p_PT. We have a reward model, which produces scalar rewards for language model outputs, and it is trained on a data set of human comparisons. And we have a method, policy gradient, for arbitrarily optimizing language model parameters towards some reward function. And so now, if you want to do RLHF, you clone the pre-trained model. We're going to call this a copy of the model, which is the RM model, with parameters theta that we're actually going to optimize.
And we're going to optimize the following reward with reinforcement learning. This reward looks a little bit more complicated than just using the reward model. The extra term is a penalty, which prevents us from diverging too far from the pre-trained model. So in expectation, this is known as the Kullback-Leibler divergence between the RL model and the pre-trained model.
I'll explain why we need this, but basically, if you overoptimize the reward model, you end up producing like gibberish. And what happens is you pay a price.
So this quantity is large, if the probability of a sample under the RL tuned model is much higher than the probability of the sample under the pre-trained model. So the pre-trained model would say this is a very unlikely sequence of characters for anyone to say. That's when you would pay a price here. And beta is a tunable parameter.
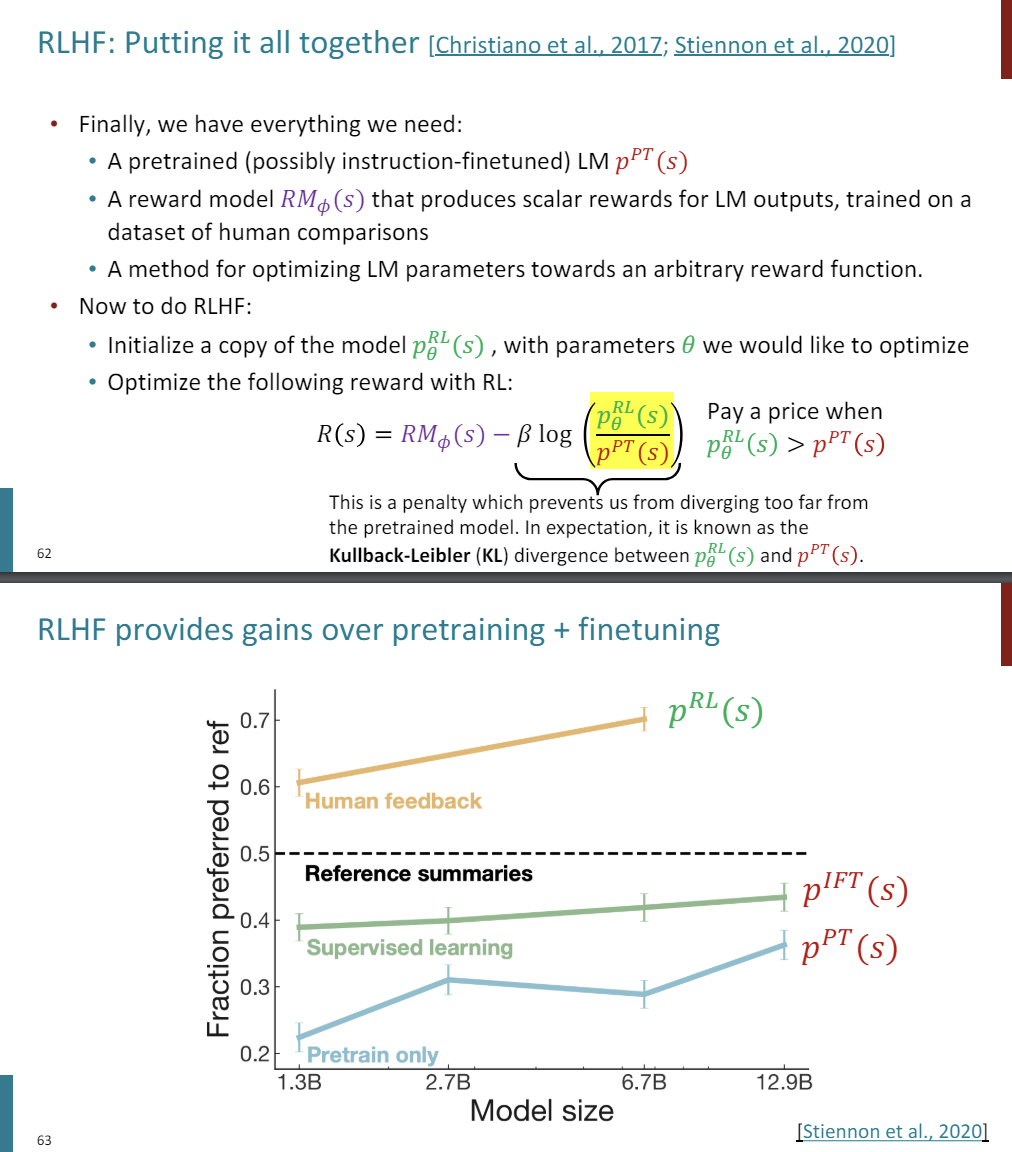
Does it work? The answer is, yes. Here is the key takeaways, at least for the task summarization on this Daily Mail data set. So again, we're looking at different model sizes, but at the end here, we see that if we do just pre-training, so just like the typical language modeling objective that GPT uses, you end up producing summaries that in general are not preferred to the reference summaries.
So this is on the y-axis here, is the amount of times that a human prefers the model generated summary to a summary that a human actually wrote or the one that's in the data set. So pre-training doesn't work well, even if you do supervised learning.
So supervised learning in this case is, let's actually finetune our model on the summaries that were in our data sets. Even if you do that, you still underperform the reference summaries, because you're not perfectly modeling those summaries.
But it's only with this human feedback that we end up producing a language model that actually ends up producing summaries that are judged to be better than the summaries in the data set that you were training on in the first place.

We're getting closer and closer to somethin like InstructGPT or ChatGPT, the basic idea of InstructGPT is that we are scaling up RLHF to not just one prompt, but tens of thousands of prompts.
If you look at these three pieces, these are the three pieces that we've just described. The first piece here being instruction fine tuning. The second part being reward model training, and the last part being RLHF.
The difference here is that they use 30,000 tasks. So again, with the same instruction finetuning idea, it's really about the scale and diversity of tasks that really matters for getting good performance for these things.

30,000 tasks. We're getting into very recent stuff where increasingly commpanies like OpenAI are sharing less and less details about what actually happens in training these models.
So we have a little bit less clarity as to what's going on here than maybe we have had in the past, but they do share- the data sets not public, but they do share the tasks that they collected from labelers.
So they collected a bunch of prompts from people who were already using the GPT-3 API. So they had the benefit of having many, many users of their API, and taking the kinds of tasks that users would ask GPT to do. And so these include things like brainstorming, or open end generation, et cetera.

The key results of InstructGPT, which is the backbone of ChatGPT, really just needs to be seen and played with to understand, so you can-- you'll feel free to play with either ChatGPT or one of the OpenAI APIs. But again, this example of a language model, not necessarily following tasks. By doing this kind of instruction finetuning followed by RLHF, you get a model that is much better at adhering to user commands.
Similarly, a language model can be very good at generating super interesting, open ended creative text as well.

This brings us to ChatGPT, which is even newer, and we have even less information about what's actually going on or what's being trained here. They're keeping their secret saurce secret. But we do have a blog post where they wrote two paragraphs.
In the first paragraph, they said that they did instruction finetuning. So we trained an initial model using supervised finetuning. So human AI trainers provided conversations where they played both sides, and then we asked them to act as an AI assistant, and then we finetuned our model on acting like an AI asistant from humans. That's part one.
Second paragraph, to create a reward model for RL, we collected comparison data. So we took conversations with an earlier version of the chatbot, so the one that's pre-trained on instruction following or instruction finetuning. And then take multiple samples, and then rate the quality of the samples. And then using these reward models, we finetune it with RL, in particular, they used PPO, which is a fancier version of RL.


You're directly modeling what you care about, which is human preferences. Not, is the collection of the demonstration that I collected-- is that the highest probability mass in your model. You're saying, how well am I satisfying human preferences? So that's a clear benefit over something like instruction finetuning.
In terms of negatives, one is that RL is hard. It's very tricky to get right. I think it will get easier in the future as we explore the design space of possible options.

When we talk about limitations of RLHF, we also need to talk about just limitations in general of RL, and also this idea that we can model or capture human reward in this single data point.
So human preferences can be very unreliable. The RL people have known this for a very long time, they have a term called "Reward hacking", which is when an agent is optimizing for something that the developer specified, but it is not what we actually care about.
So one of the classic examples is this example from OpenAI, where they were training this agent to race boats. And they were training it to maximize the score, which you can see at the bottom left. But implicitly, the score actually isn't what you care about, what you care about is just finishing the race ahead of everyone else, and the score is just kind of this bonus. But what the agent found out was that there are these turbo boost things that you can collect which boost your score. And so what it ends up doing is it ends up just driving in the middle, collecting these turbo boosts over and over again.
So it's racking up an insane score, but it is not doing the race, it is continuously crashing into objects, and its boat is always on fire.
This is a pretty salient example of what we call AI misalignment.
You might think, well, they made a dumb mistake, they shouldn't have used score as a reward function. But I think it's even more naive to think that we can capture all of human preferences in a single number, and assign certain scalar values to things.
So one example where I think this is already happening and you can see, is maybe you have played with chatbots before and you noticed that they do a lot of hallucination, they make up a lot of facts. And this might be because of RLHF.
Chatbots are rewarded to produce responses that seem authoritative or seem helpful, but they don't care about whether it's actually true or not, they just want to seem helpful. So this results in making up facts.
You maybe seeing the news about chatbots-- companies are in this race to deploy chatbots,, and they make mistakes. Even Bing also has been hallucinating a lot.

In general, when you think about that, models of human preferences are even more unreliable. Like, we're not even just using human preferences by themselves, we're also training a model, a deep model, that we have no idea how that works. We're going to use that instead. And that can obviously be quite dangerous.
Where I was describing why we need this KL penalty term, here's a concrete example of what actually happens, of a language model overfitting to the reward model.
What this is showing is in this case, they took off the KL penalty. So they were just trying to maximize reward. They trained this reward model, let's just push those numbers up as high as possible. And on the x-axis here is what happens as training continues, you diverge further and further. This is the KL divergence or the distance from where you started. And the golden dashed line is what the reward model predicts your language model is doing. So your reward model is thinking, you are killing it. Like, they are going to love these summaries. They are going to love them way more than the reference summaries. But in reality, when you actually ask humans, the preferences peak, and then they just crater. So this can be an example of over optimizing for a metric that you care about. It ceases to become a good metric to optimize for.
So there's this real concern of what people are calling the AI alignment problem. I'll let Percy Liang talk about this. He tweeted that the main tool that we have for alignment is RLHF. But reward hacking happens a lot, humans are not very good supervisors of rewards, so this strategy is probably going to result in agents that seem like they're doing the right thing, but they're wrong in subtle inconspicuous ways.
And I think we're already seeing examples of that in the current generation of chatbots.

Here are some positives. But again, RL is tricky to get right. Human preferences are fallible, and models of human preferences are even more so. So I remember seeing a joke on Twitter somewhere where someone was saying that Zero-Shot and Few-Shot learning is the worst way to align an AI. Instruction finetuning is the second worst way to align an AI, and RLHF is the third worst way to align an AI.
So we're getting somewhere, but each of these have clear fundamental limitations.



A recent work that I'm especially interested in, and been thinking about is how we can get the benefits of RLHF without such stringent data requirements.
So there's these newer kind of crazy ideas about doing reinforcement learning from not human feedback but from AI feedback.
So having language models themselves evaluate the output of language models. So as an example of what that might look like, a team from Anthropic, which works on these large language models, came up with this idea called Constitutional AI.
The basic idea here is that if you ask GPT-3 to identify whether a response was not helpful, it would be pretty good at doing so, and you might be able to use that feedback itself to improve a model.
Now by just decoding from a language model, assuming you can do this well, what you have now is a set of data that you can do instruction finetuing on. You have a request, and you have a request that has been revised to make sure it doesn't contain harmful content. So this is pretty interesting.
Another kind of more common idea also is this general idea of finetuning language models on their own outputs. And this has been explored a lot in the context of chain-of-thought reasoning.
And these are provocatively named, Large Language Models Can Self-Improve.
'Research > NLP_Stanford' 카테고리의 다른 글
Multimodal Deep Learning - 1. Early models (0) 2024.06.29 Model Analysis & Explanation (0) 2024.06.29 Prompting (0) 2024.06.24 Pretraining (0) 2024.06.23 Self-Attention & Transformers (0) 2024.06.22