-
Multimodal Deep Learning - 1. Early models*NLP/NLP_Stanford 2024. 6. 29. 12:50
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=5vfIT5LOkR0&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=22
Lecture 16 - Multimodal Deep Learning


Why do we care about multimodality?
There are a couple of good reasons in general for this. The first one is about faithfulness. If you look at how we humans understand the world, how we make sense of what happens in the world, that is very multimodal. So we perceive the world, not just using vision or just audio, but we synthesize information across all of these different modalities and that's how we understand the world and each other.
There's also a practical argument for doing it. It's because the internet is multimodal. So if you go to, Facebook or something like that, it rarely happens that it's just text or just an image, it's usually a combination of multiple modalities.
And then the final good reason that we're just starting to hit now if you're really following where the field is going, we're kind of running out of text data for these large language models. So one interesting way to keep scaling on the data side is to make use of all of these other modalities. So if you can have your language model also watch all of the videos of cats in the world, it's going to understand the concept of cat much better. And that's what we want to have in these models. We want them to understand the world in the same way that humans understand it. So right now multimodality is really one of the main frontieres of this new foundation model drive that we're all in right now.
So multimodal applications.
When we have multiple modalities, we can do all kinds of interesting things. And as I said, most of the use cases we have on the internet, they're all multimodal. And there are some really kind of obvious things we would be interested in if we have information from these different data sources from different modalities.
Obviously, we might want to do retrieval. Maybe given a bit of text we want to find the right image or maybe given some image we want to find the right text for it so we can match them up.
Obviously, we can also do this in a generative setting. So then we have image captioning, which you probably heard of, we can do text-to-image generation. So that's image synthesis, so stable diffusion. Then we can do visual question answering where we have an image and text and then we need to generate some new text. We have multimodal classification where we have image and text and we need to have a label, for example, whether something is hate speech or not.
And then, in general, we want to be able to have a richer understanding of information, which means that we combine image and text and then use it for downstream applications that require better understanding or better generation.

So this field is super hot right now. So there's this nice paper title. I predict that this paper is going to do really well in terms of citations just because it has such a citable title. I think a lot of people are not actually going to read it. And so, I mean, I've been in this field for quite a while now and people have been saying that for a really long time. So for decades, people have been saying that multimodal is the next big thing, but now it's really true, I think.
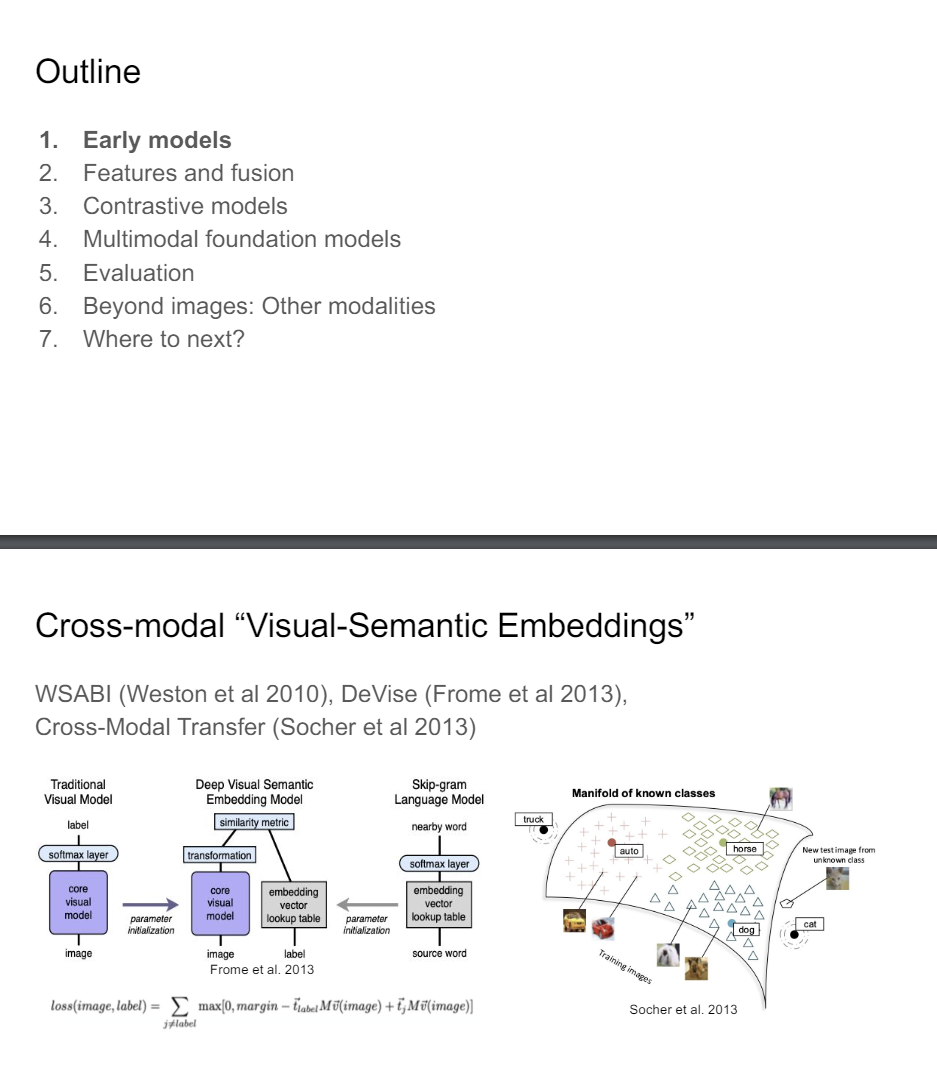
I think if you want to start from the deep learning revolution and what was happening in images and text, then a good starting point is, for example, WSABI or DeVise or Richard Socher has done some cool early work in this that pioneered a lot of these ideas.
The basic gist of this is that we have a vision model, on the one hand, we have a language model. That's just basic word embedding model. And now we need to figure out how to align them in the same multimodal space. So the way you do that is you get some sort of similarity metric, this score function or like a kernel function if you're think about this from a support vector machine literature perspective and now you need to figure out in a max margin or margin loss, how you want to align these two points in your embedding space. So things that are similar, you want to bring them closer together, things thar are not, you want bring them further apart.
And if you do that in this multimodal embedding space that means that you can do interesting cross-modal transfer where you can take the word embedding for something like auto or like horse, and then you can find close images in the embedding space to that thing and now you've solved the retrieval problem. So this is a really nice early application.
And I think a lot of the stuff that I'm going to talk about in the early slides you're going to see this thing come over and over again. You're going to see it get kind of reinvented with fancier models, but it's basically all the same stuff.
So you can do cross-modal transfer where you have image and text, but you can also combine them together so that you get a multimodal word embedding. And so this just gives you a more accurate representation of how humans understand word meaning because when we think about the word moon or cat or something, we can go to Wikipedia and read that a cat is a small carnivorous mammal that people like to keep as pets, or we can just go and look at pictures of cats and now we understand what a cat is. And I would argue that for a lot of people, the picture of the cat is much closer to the meaning of the concept of cat.
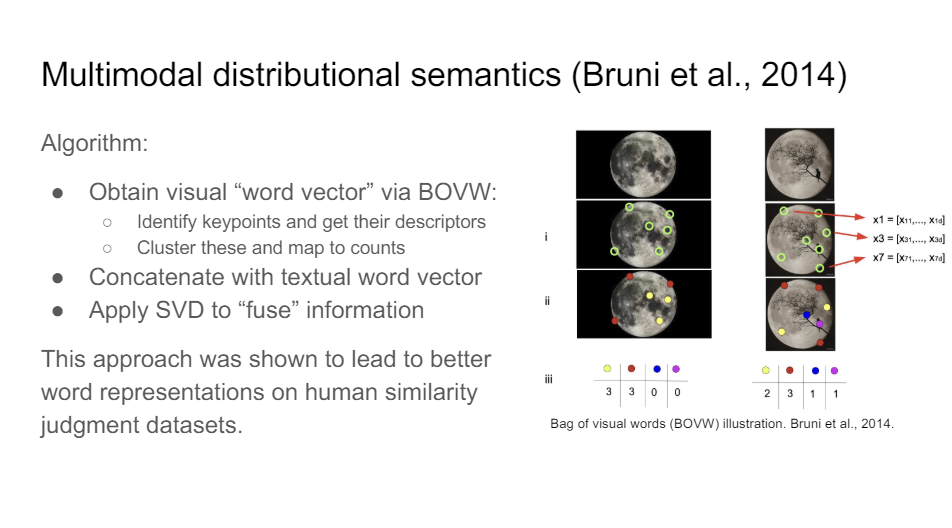
So some early work where people were trying to do this is from Bruni et al, where they did multimodal distributional semantics using this very elegant approach called bag of visual words. It's surprisingly simple.
You take a picture of the moon, in this case. We use an algorithm like SIFT to find interesting key points, so sort of where the difference between the pixels and the pixels next to it, where the difference is big, those are the spots you want to be looking at. And for each of these key points, you get feature descriptors. So relatively small vectors like 32 dimensional. It depends on the implementation of this. And what you can do now with these feature descriptors is you can cluster them using k means and then you assign every one of these points so you can count how often they occur. So in this picture of the moon, there are three red dots. So what that gives you is an idea of the visual words, very similar to the original bag of words model.
That's the visual equivalent of the textual thing. And so if you do this and you then concatenate or apply SVD to fuse the information, what you get is a word embedding that is much more representative of human meaning, as reflected in the data sets that people use to care about at the time.
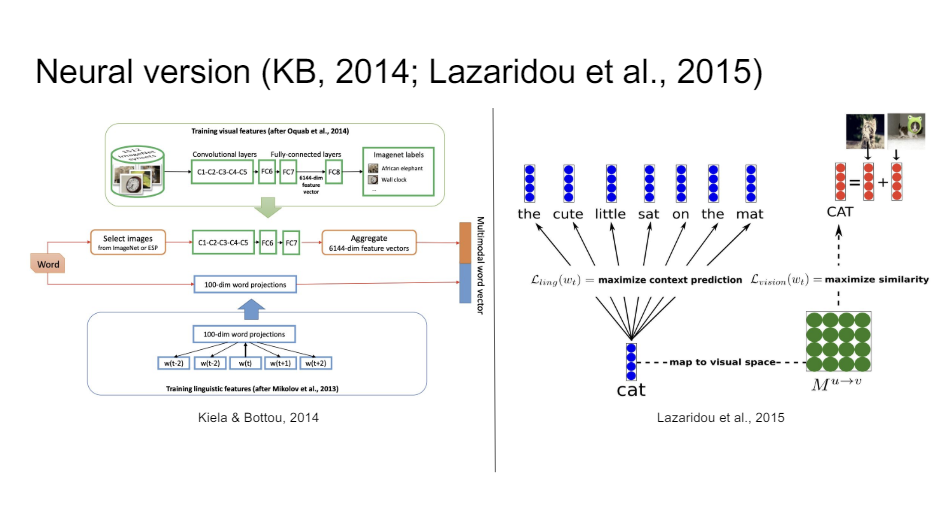
After that, there were a couple of people who tried to take these idea, and then apply deep learning to them. So some of the very early versions of this use convolutional neural networks, and then you can transfer the features from your ConvNet and you take your word embeddings, and then you can concatenate them now you have a multimodal word vector, or you can do something slightly fancier. So you've seen the skip-gram model. You can also try to do skip-gram predictions onto image features. So when you see a word like cat in some context like the cute little cat sat on the mat, then when you see cat you also want to predict cat pictures. So super easy ideas, but it turned out that this gives you much richer word representations.
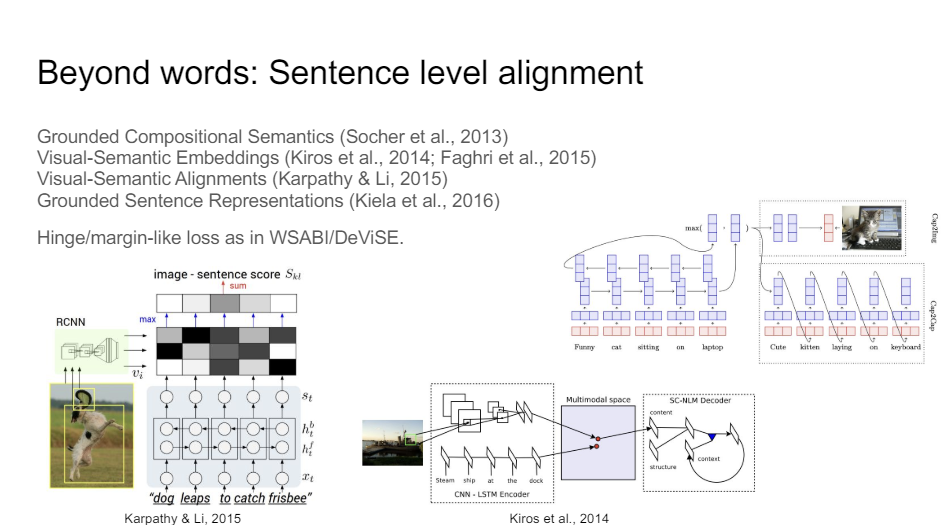
But obviously, words are very limited. What we really care about is not words but sentences. So then people started looking into sentence representations and how can we figure out how to get compositional understanding in these sentence representations and how do we align that with images.
So the loss here is very similar to what we saw with words and pictures but now we have a sentence encoder.
There's some cool early papers from Andrej Karpathy, and Richard Socher also had some work here. The basic idea is that instead of having these word embeddings we now have an LSTM in these papers or some other kind of recurrent neural network, or in the case of this one, recursive neural network, and then we try to align the features together. So these three or four papers are actually very important.
This one by me showed here that grounded sentence representation. So if you use this part here as a sentence encoder for NLP tasks, the ability to predict pictures from it gives you a good sentence representation.
So by predicting pictures you can imagine what things look like and that gives you a really good meaning representation which you can then transfer to, sentiment classification or something else.

And then of course, once we have sentence encoders then we also have decoders. So when the sequence-to-sequence architecture came out, what you can do instead of having a text encoder for your source language if you're doing machine translation is you can plug in a ConvNet instead of an LSTM encoder, and now you can generate captions. So that's exactly what people did. We used to have all of these fancy diagrams in our papers then where we explained the LSTM and how that works.
One of the things that people figured out in machine translation very early on is that you can do alignment of words between your source language and your target language. And you can to the same thing actually with images. So if you want to align a word in your generated sequence with something in your picture, then you can use the same approach for that. And that approach,of course, is called attention.

Attention was one of the building blcoks of these systems as well where you can do very interesting things and really see that when it has to generate stop for the stop sign, that it's really actually looking at the stop sign. So there's a really cool alignment going on there in these models.

And so the final early model we should talk about a little bit is GANs. The basic idea of a GAN is that you have this generator and discriminator and you want to have the generator generate images that the discriminator cannot distinguish. So it cannot distinguish fake and real images. If you do that, you can condition that on a piece of text, and then you can generate images using some text prompts.
That's what the first versions of stable diffusion were doing things like this and it's all a natural progression to that model. So those were the early models.
'*NLP > NLP_Stanford' 카테고리의 다른 글
Multimodal Deep Learning - 4. Multimodal foundation models (0) 2024.06.29 Multimodal Deep Learning - 2. Features and fusion / 3. Contrastive models (0) 2024.06.29 Model Analysis & Explanation (0) 2024.06.29 Reinforcement Learning from Human Feedback (RLHF) (0) 2024.06.24 Prompting (0) 2024.06.24