-
Multimodal Deep Learning - 4. Multimodal foundation models*NLP/NLP_Stanford 2024. 6. 29. 21:58
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=5vfIT5LOkR0&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=22
Lecture 16 - Multimodal Deep Learning
If you have a BERT model and you have a bunch of images, how are you going to turn that BERT model into something multimodal?
There are a bunch of obvious things you could do given the kind of features I told you about and the fusion process. So how are you going to do that?
You could take the ConvNet features and give them to the BERT model in lots of different ways. We can use the region features. So I think a lot of people when BERT came out who were working in vision and language processing were thinking exactly about OK, so do we do middle fusion, late fusion? Do we do early fusion? How do we do the fusion? And so there were a lot of papers all coming out at around the same time where people were doing versions of this.
So BERT was the innovation and then everybody just plugged it into their own thing because of Hugging Face transformers and things like that.
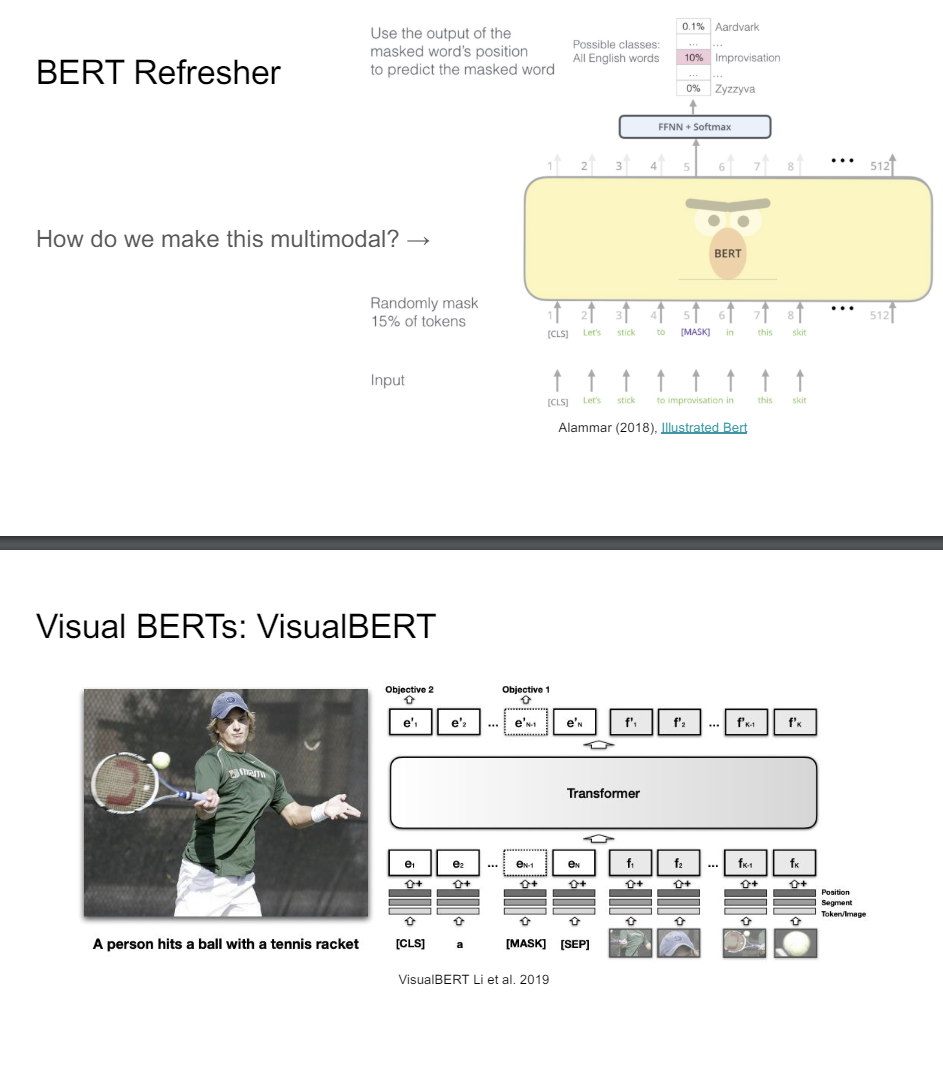
So the first thing is visual BERT. This was one of the very early ones where you have this image and people would do object detection on this. So you get lke a hat and a racket and a shirt and things like that. So you can just really take these features and then plug them into your transformer model and then you try to recover the features.
This really is probably the simplest way to do it. And so this is what we call a single-stream architecture where you have all of these concatenating the original input features and then putting them through the same transformer.
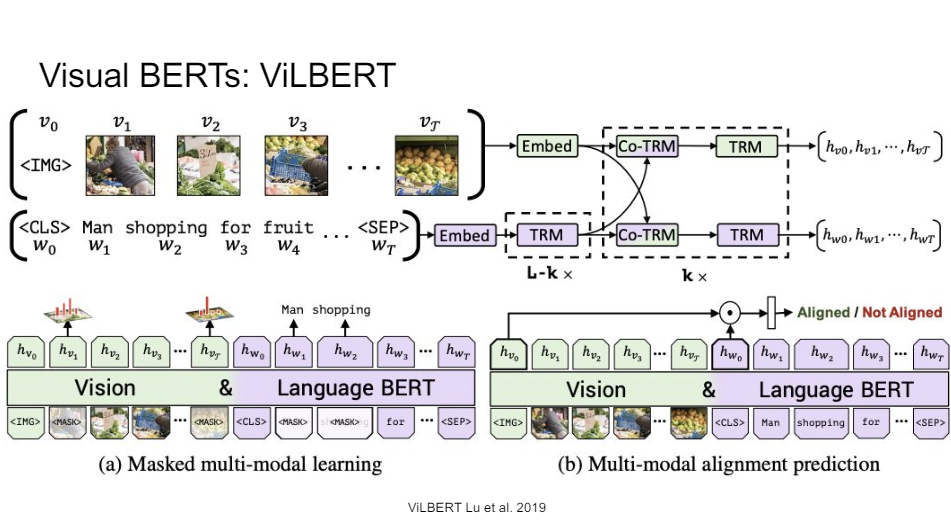
What you can also do and that's something that this model called ViLBERT did is where you have two different streams. So you have these two parallel transformers, but at every layer, you give them cross-attention, or co-attention as they call it.
So you just make sure you have an attention map that spans both and then do your full normal transformer layer again.
So this, you can train just like your regular BERT. So you have your masked language model here and you do some equivalent of that. And then you also have your next sentence prediction, but instead, here, we're saying, OK, is this image aligned with this piece of text or not?
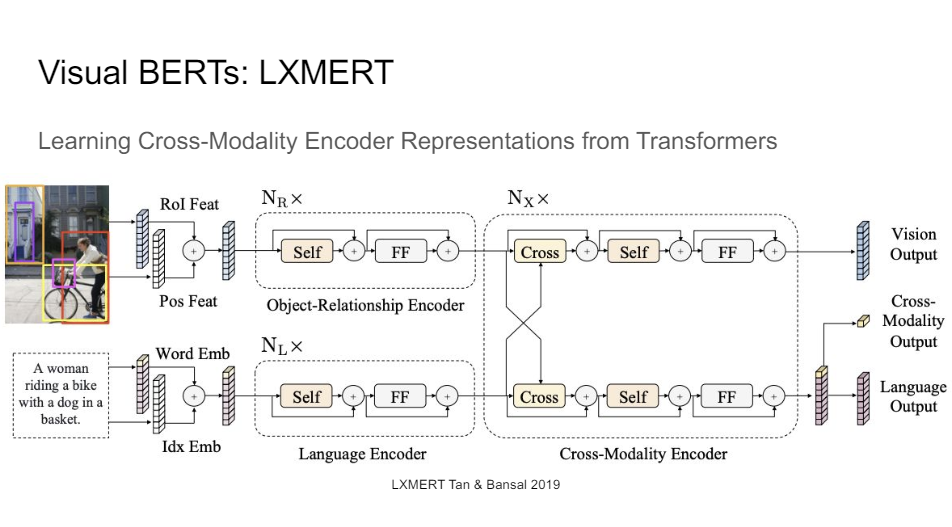
There's also LXMERT. There are like 100 papers that came out that did this all at the same time. So LXMERT had a different cross-modal output encoder, a bunch of different ways of encoding the positional information. So you could say, OK, I just have a bunch of bounding boxes that are featurized but I don't care about where they are in the image. So it's just a bag of bounding boxes. Or you could say, I found it here like this is the particular top left and bottom right coordinate and that's what you featurize into your network.
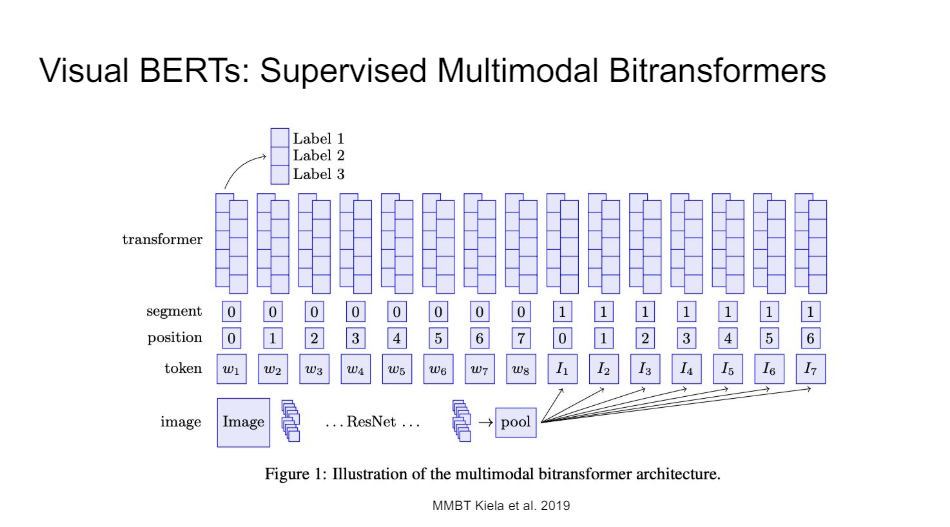
You can also just take the image itself, you put it through a ResNet, and then you do a little bit of pooling on the final feature maps and you just give those feature maps to BERT. So you then need to distinguish between your text segment embeddings and your vision segment embeddings.
So this actually works surprisingly well. You don't have to do any additional training. you can just take BERT out of the box. Initially, you freeze it. You learn to project into BERT token space, then you unfreeze your ResNet, and then finally you unfreeze your BERT, and now you have a very good multimodal classifier on the problem you care about.
So a lot of these other papers, they're doing what they call multimodal pretraining where first, you have a BERT model and a ResNet. So they're unimodal pretrained. And then you couple them together and then you have a multimodal intermediary pretraining step before you fine-tune it on the problem you care about.
And what we showed here is that you don't really need that actually in many cases. That's a very strong baseline.
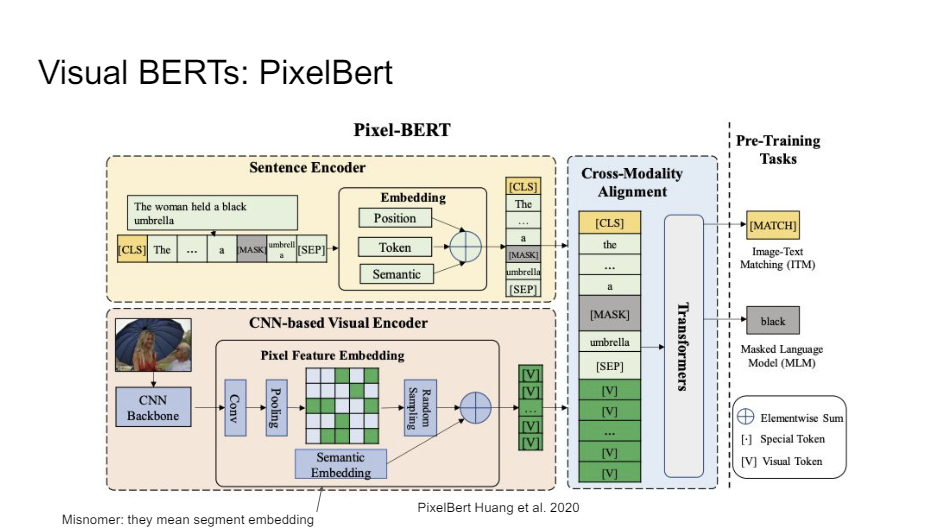
You can also go to the pixel level completely. That's what they did in this other paper called PixelBERT, exactly MMBT. So the previous supervised on, but here they do the multimodal pretraining step and show that for VQA it helps a little bit.
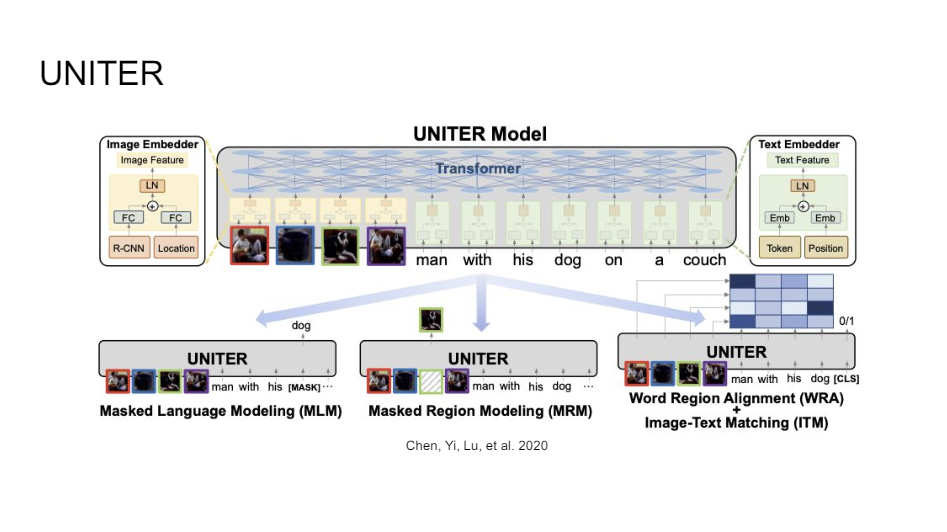
So there are many of these BERTs doing visual things. People really tried everything. Here's another one caled UNITER, where they added a bunch of different losses.
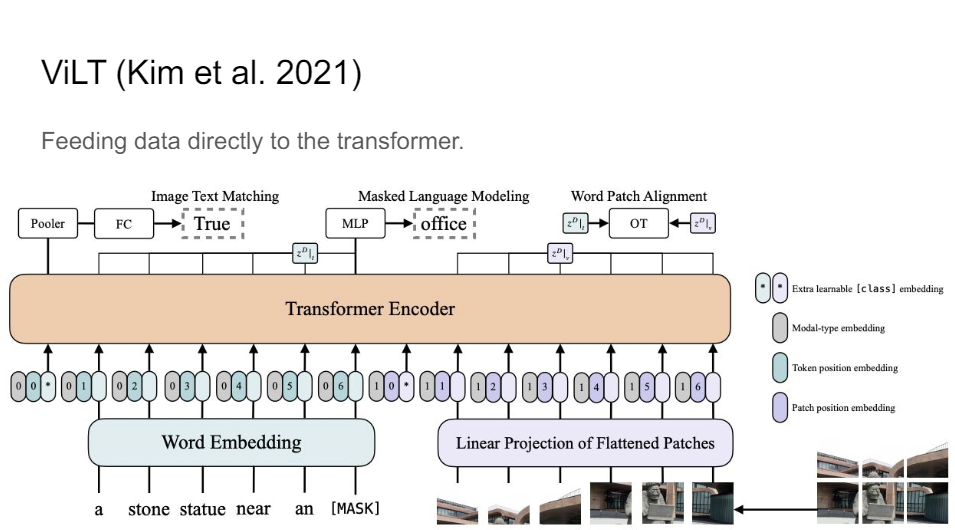
This is one I think is quite interesting. ViLT, because here this is really the first instance where we are completely gone from ConvNet features. So we don't do any pre-processing on the image, no region features, no backbone that it featurizes the parts of the image we care about.
We just have these patches of the image. So really in a grid. We flatten those patches. We just pumped them into the transformer straight away.
So this really is BERT and ViT together in one model and this worked really very well.
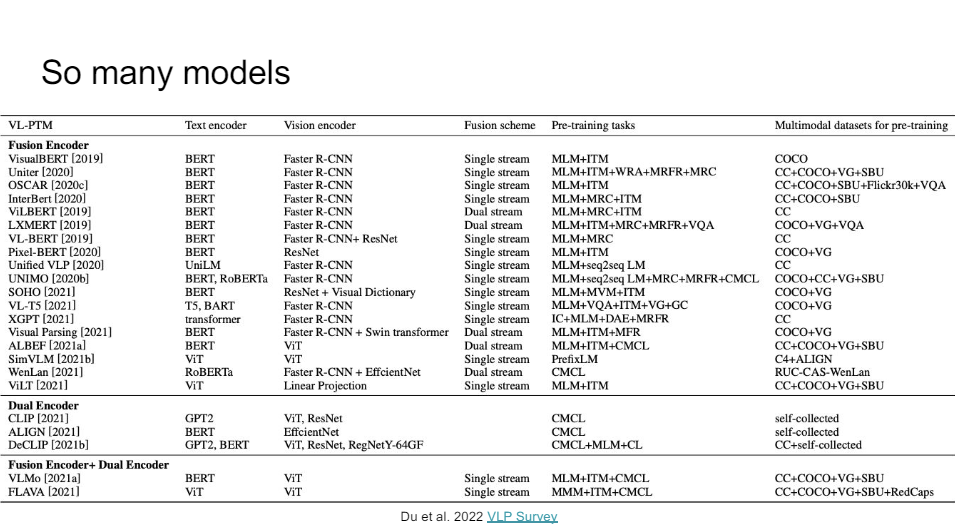
So that's been the trend. Here's a nice very long list of all of these different models and what they do. So really the distinctions are just in what is the text encoder thta you use.
So do you use BERT or something fancier or better, RoBERTa? What is your vision encoder? In many cases, you have these region features. You would do an R-CNN style thing, or you could just do a ResNet or a ViT. You have different kinds of fusion. Either single or dual stream, as we talked about. So visual BERT or ViLBERT. Different pretraining tasks. So masked language modeling, image text matching. There's a bunch of funkier ones you can do. And then finally, you can do multimodal pretraining on all of these different data sets that have aligned data.

You are probably wondering, so what is really the interesting difference between a lot of these?
This is a well-done paper, where they unmasked multimodal pretraining. Basically, they say if you take all of these little model inventions and you train these different models on exactly the same data in exactly the same way, it turns out that they're all basically the same.
So that's a lot of wasted effort on the part of the field because everybody is saying, my model is better, but it's actually just because you trained it on different data and there's no real model innovation going on in a lot of these things. That's why this paper is really nice and really important is because it just shows us what really matters.

THis is also work that I did myself called FLAVA with my team, where we wanted to take these ideas really to the limit. So a lot of the things that you've seen now, so the visual BERTs and the ViLBERTs and things like that, they're all about multimodal questions. So how can we do visual question answering, something like that, where we just have these two modalities. We only care about problems that always involve these two modalities.
And where we want to go, and this is the basic premise I think of foundation models in general, is that we have one model to rule them all. So this one model can consume data from all of these different modalities and it can synthesize across all of these different modalities and then do useful things with that information.
So with FLAVA, that's exactly what we try to build. We wanted to have one foundation model that is good at vision and language, and computer vision and natural language processing is jointly pretrained on all of these different data sources.
So it's also trained on just CCNews, Common Crawl, and BookCorpus. So it's very good at things you would expect BERT to be good at. It's trained on ImageNet for image data, so it's good at the things that you would expect a basic image model to be good at.

And then you have this PMD data set that we created out of publicly available image text pairs that we also trained it on. So this PMD data set is really just- if you take all the data sets that were ever created that have image text pairs that are publicly available.
Unfortunately, the CLIP data and the Google align data and all of these data sets, they haven't been open source. So this is before LAION. So now there's a good alternative to this. But so this PMD data set, if you combine all of these image text pairs, you get 70 million of them. So that's still a pretty decent size.
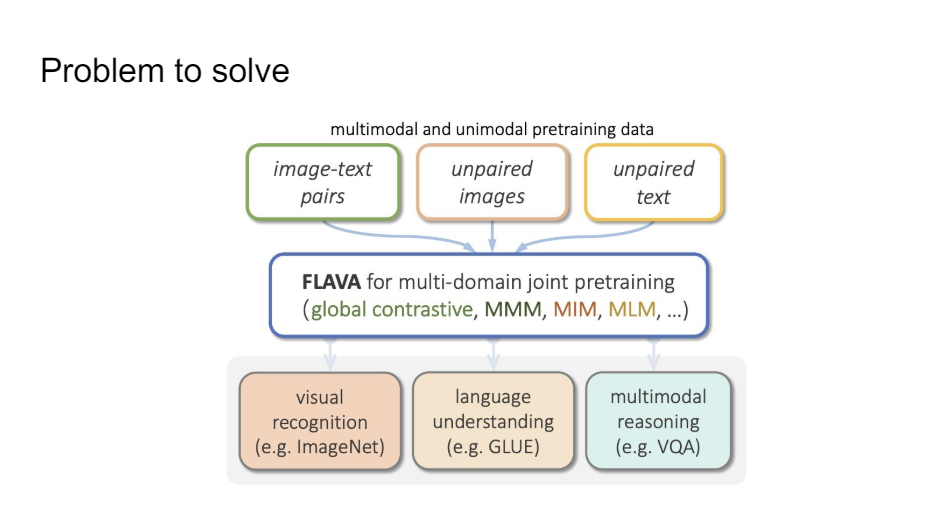
And then you can take all of this data basically to solve all of these problems that we know and we care about in these different fields. So you can do multimodal reasoning, you can do language understanding, you can do visual recognition all with exactly the same model.
That's a very powerful idea. I think if you work at a company like Facebook you don't want to have different models for all kinds of different things, you want to have one model that you can use for everything that's going to make your life a lot easier.
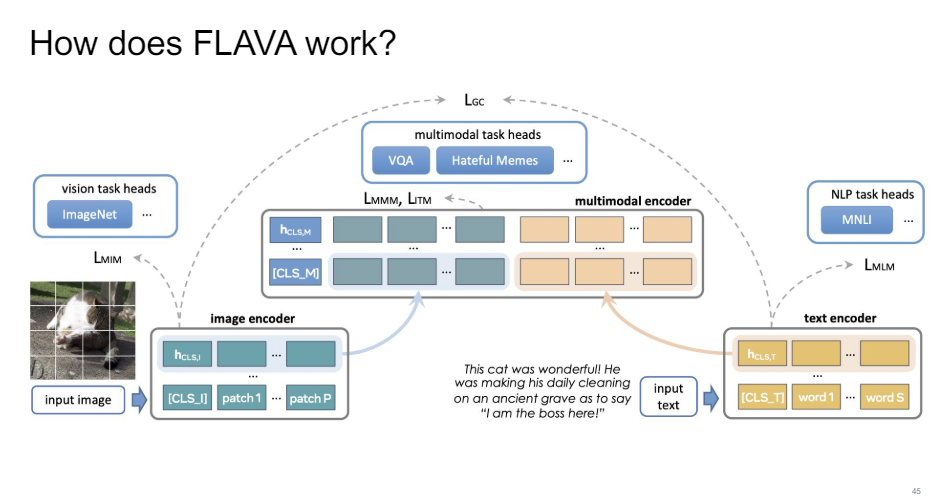
The exact architecture is that on the one hand, we have this image encoder where we take the image, we encode it as patches, and we just do what we call masked image modeling, but it's basically masked language modeling just on the image tokens. And then on the other side, we have the masked language modeling on the language. So your regular sort of BERT thing.
And then we have a multimodal part where all of this information gets combined. So we have a masked multimodal modeling loss term where you can also do image text matching. So this is lke your BERT next sentence prediction thing.
And then we also have a global contrastive loss, which is exactly like a CLIP.
So if you do all of this stuff, it's just all transformers all the way down. It's a very elegant way to combine a lot of this information.
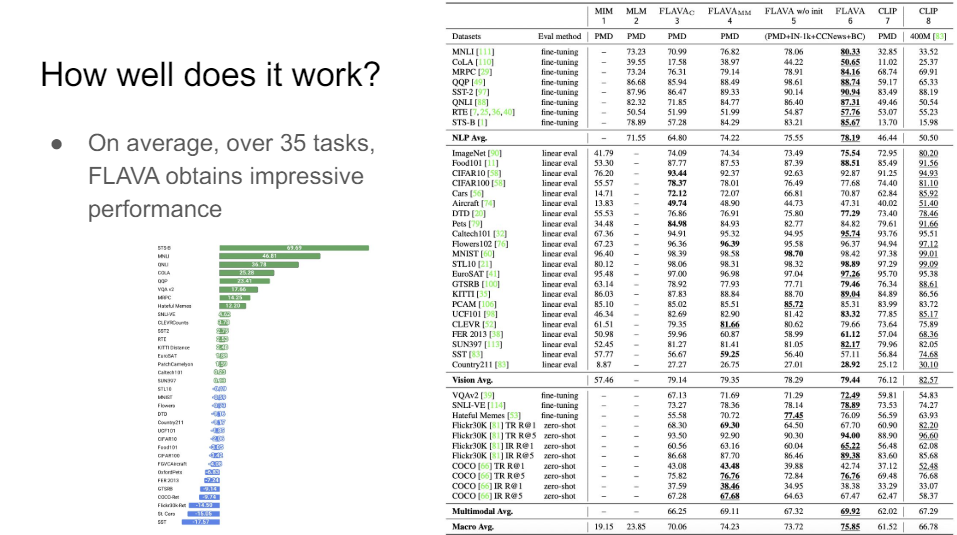
When you do that, you get something that can really do a lot of things very well. Over 35 different tasks if you compare FLAVA to all kinds of different ablations in terms fo CLIP models, then this is just a much better way to get to this information.
So I think this is a nice example of where we're probably going to go with the field in the near future.
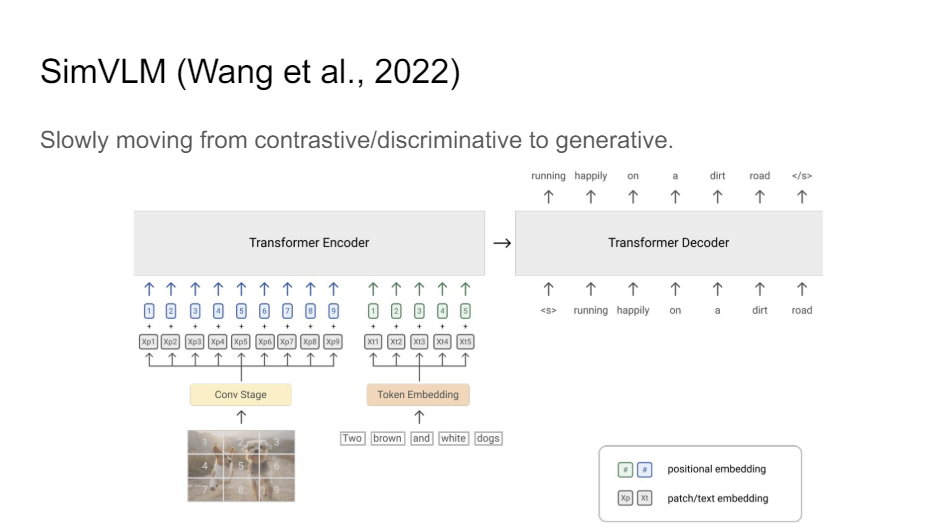
The other trend that we see very obviously in the field right now is that everybody cares about generative models. So language models and image generative models. There's just a trend where we want to be generative.
We want to move away from this contrastive/discriminative stuff to the more interesting, more richer representations maybe that you get out of generating sequences or images.
So this SimVLM paper was one of the first ones where they really had this separate decoder that was trying to generate or compete captions, which they showed gives you a lot richer representations.
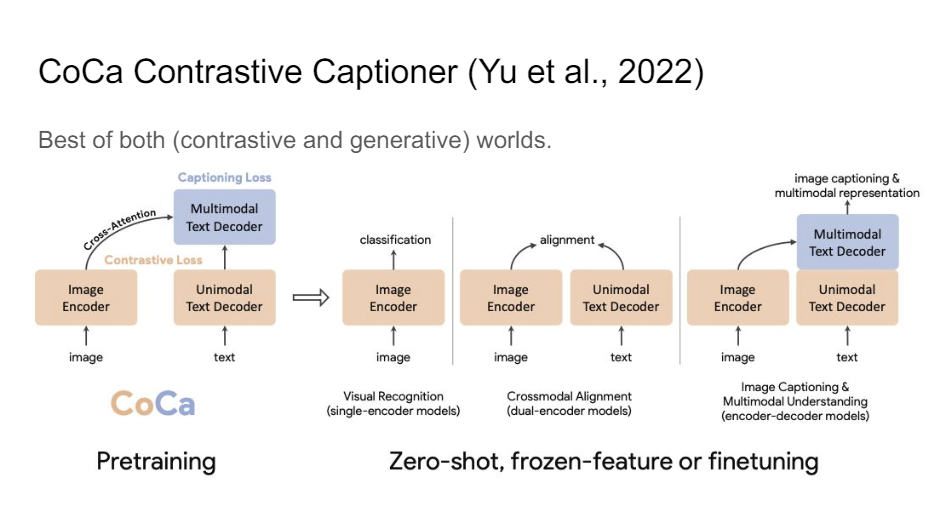
I think this is actually the current state of the art now. It's called CoCa. So a lot of these models. They all again look very similar, but in this case, now we're starting to really see these text decoders. So initially, with CLIP, I think that's also what they were trying to go for, like OpenAI being a company that really likes generative models, but they couldn't really get it to work. And I think it took us a while as a field to really figure out how to do this the right way.
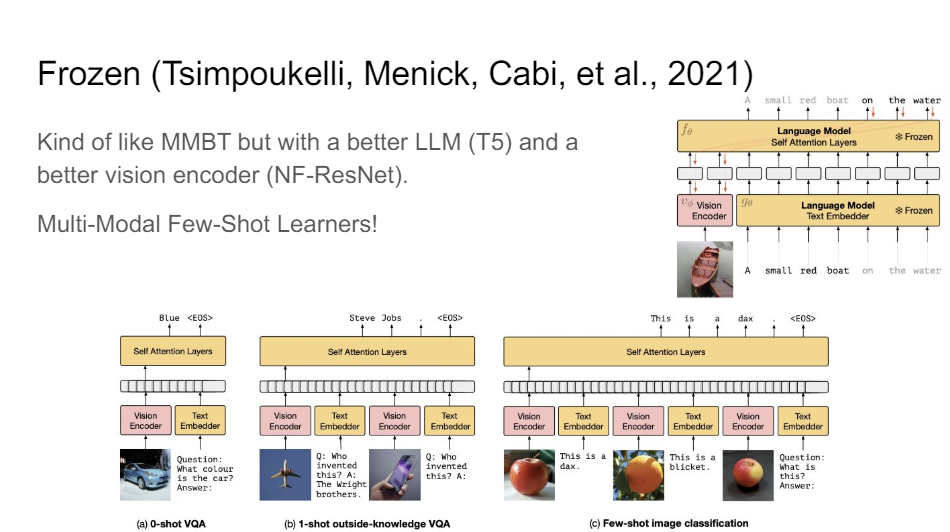
And so right now we're really in the age of language models. So one of the interesting things you can do with language models is just keep them frozen and then lean how to project into the language models. So the MMBT architecture I talked about where we had this BERT model, we kept it frozen, and we learn to project into the BERT token space.
You can do exactly the same thing but then with a much fancier model or something like T5 even where you just have an encoder-decoder or some kind of generative part of this. You keep that thing frozen, and then you learn to project into the token space of that frozen language model, and then you can do lots of fun stuff it turns out.
So what they show in this paper is that you then get few-shot learners. So all of the things you see with GPT-3 where you can just give it some in-context examples and it's going to figure out binding on the fly.
So it says like this is a dax and this is a blicket. So what is this? And then it gives you the answer that it's a dax.
So it really learns in context how you decide the feature mappings, which is really solving the grounding problem that a lot of this multimodal stuff started with.
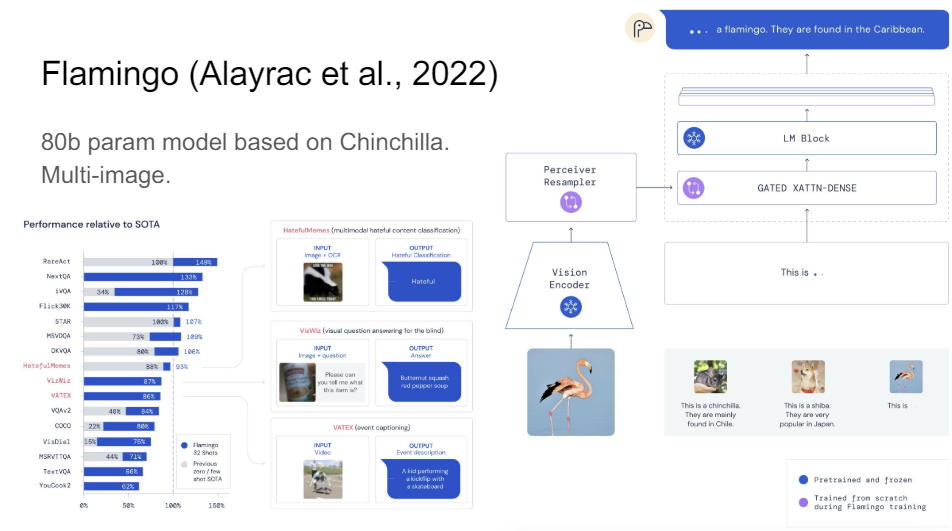
So I think that's very cool. Then probably one of the coolest papers right now or models right now that you might have heard of if you follow the field is Flamingo, out of DeepMind, where they take a Chinchilla language model. So this is really an optimal language model.
And now you have this vision encoder that encodes multiple different images that you can then do reasoning over and then autocomplete. So what this gets you is just a much more powerful model because you can do your generative over lots of different images.
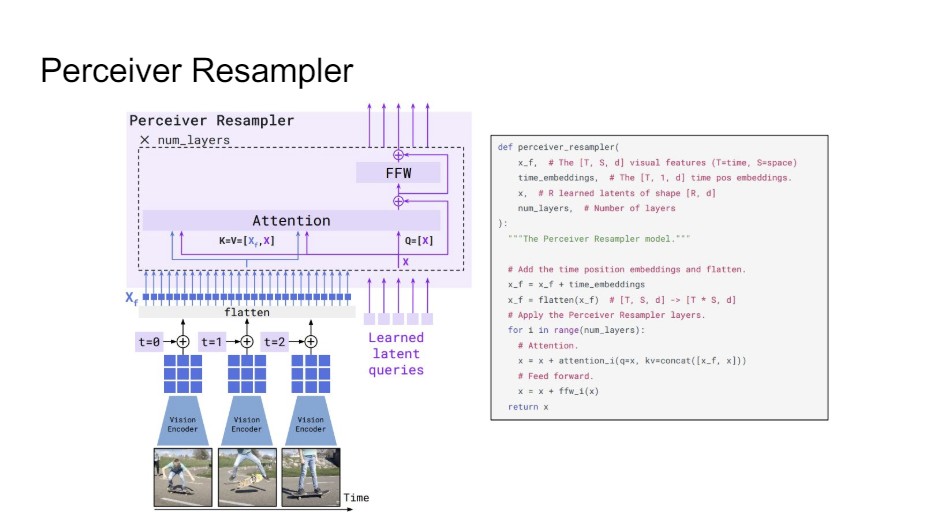
So it's really like step-wise. You can see it. We started off with veery simple transformers and now we're actually at something that is starting to get pretty complicated because we have these building blocks like a perceiver resampler where we have a bunch of different images that we featurized and now we need to compress the information because sometimes we have three images, sometimes we have five images.
So we want to make sure that we can compress it so that it's always ready for consumption by the next layer of the language model.
This paper again is a really good paper to read. They have the diagram together with the code so that you can really understand what it's doing, which I think is really great.
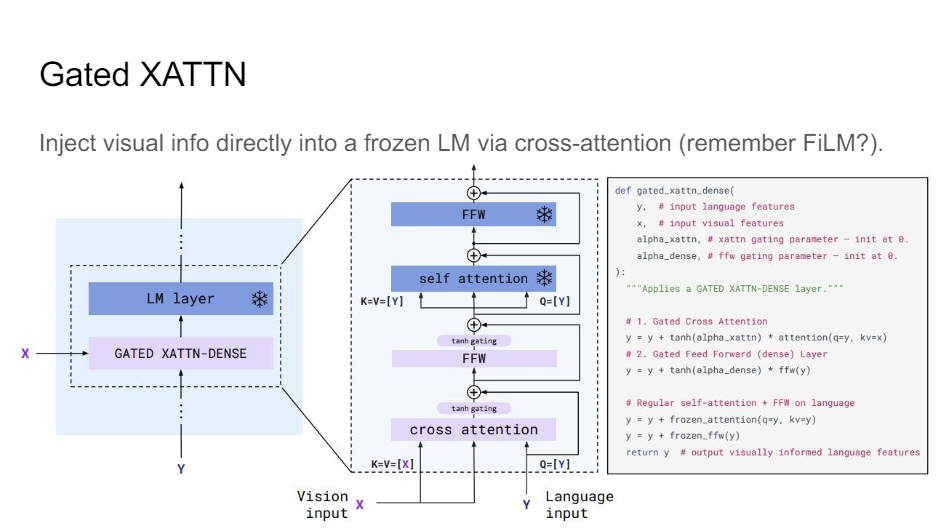
So once you have your perceiver resampling step, what you then do is you do gated cross-attention. This is how you implement it. This gated cross-attention you do that before your frozen language model layer.
So you really just have a frozen Chinchilla language model and you learn to modulate the information that goes into that language model. You propagate the gradients all the way back, you just don't update the language model.
So you're really trying to figure out like, how am I going to design my signal so that my language model can do the most with it, right?
How am I going to combine the information? So you'll notice that now we do it before the layer. And a lot of this other stuff you would do the attention after the layer, but here you do it before.
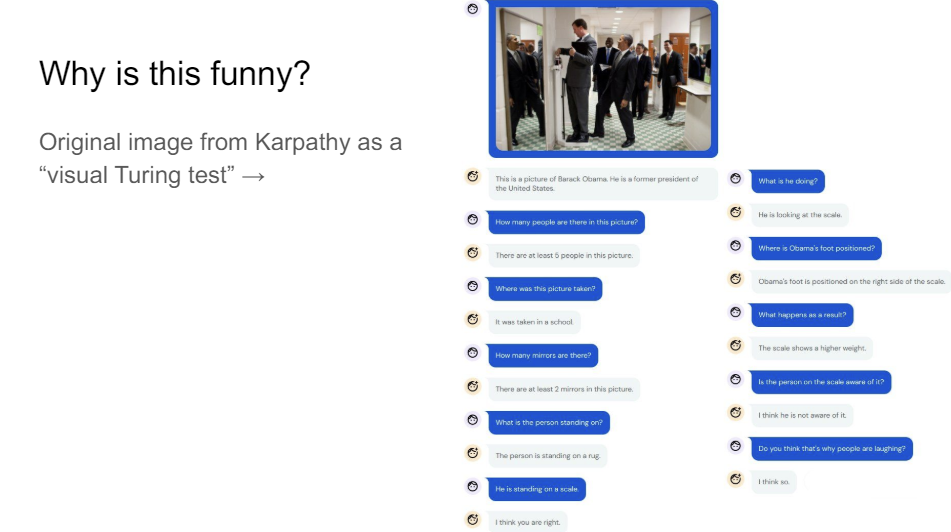
So Karpathy, I think, more than 10 years ago had this image. It's Barack Obama setting his foot here on the scale to make somebody think they're a lot heavier than they really are. So this is obviously funny to us, nt not to an AI system, I think, unless it really understands the scene. And so that's why Karpathy at the time said this would be a really good visual Turing test. If a system can figure this out, then it's actually really samrt. And so obviously, it's been a bit of a challenge for everybody working in the field than to get something that actually works on this.
Flamingo, as it turns out, gets the joke. It's a bit unclear if it really gets the joke because if you read this conversation, it's sort of getting steered in the right direction. But at least we're making progress, let's put it that way.
And then so in Flamingo, you still have a lot of moving parts, but you can really take this almost to the full extreme where you try to freeze almost everything. And you just want to learn this kind of mapping between your image encoder and your language model, or your image encoder and your encoder-decoder architecture, and all you really do is just the projections between the two.
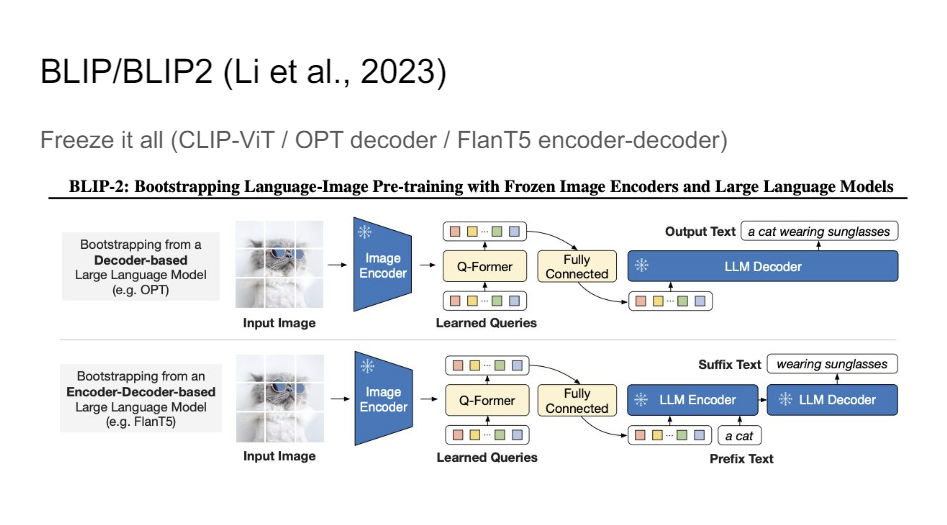
There's this nice model called BLIP2, where they experiment with OPT for the language model and FlanT5 for the encoder-decoder architecture. This just gives you amazing results.
It gives you really complex captions and things like that without any real direct supervision on the captions itself, which is pretty impressive. So that just shows you the power of language models in general.

Here are some examples. It can really do different things from captioning to reasoning to visual question answering to lacation detection. So you can have a long conversation with this system.
This is the future of where we're going, where we're going to have a ChatGPT but it's also going to be able to see the world in a way.
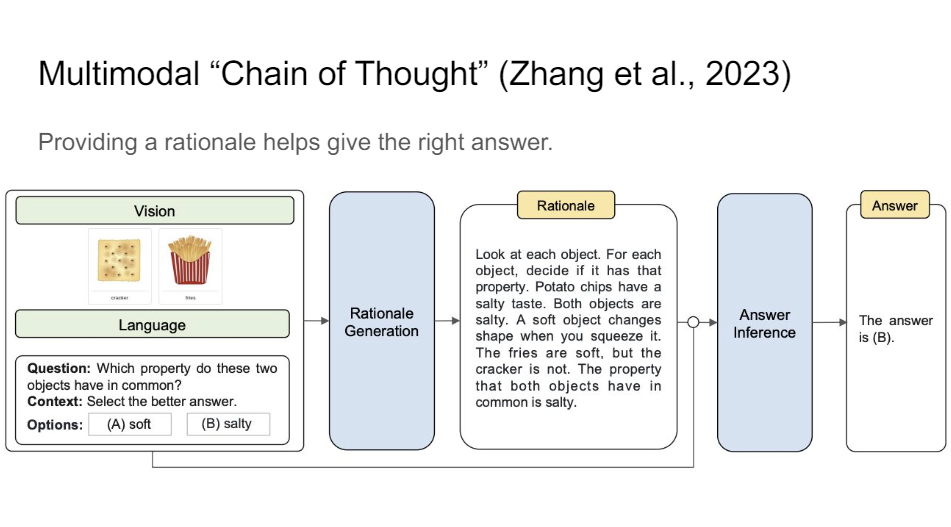
You've probably heard of chain of thought prompting and things like that where you ask the language model like let's think step by step. And you can tell a vision and language model, generate a rationale for why something might be the case. So you generate a potential explanation for what your answer might be. And then after that, you ask it to answer the question. And it turns out that if you do that multimodal chain of thought prompting, then the system gets much better. This is the new state of the art on ScienceQA or benchmarks like that just because it learns to unpack the information.
So I think we're really as a field just starting to figure out what the potential is of this.
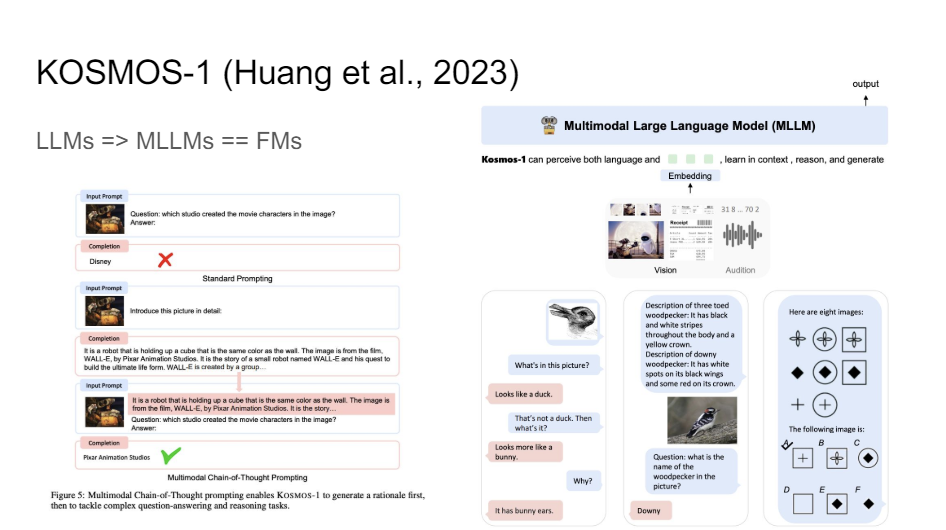
I think this paper is where they also show that multimodal chain of thought prompting really gets you pretty amazing results. They show very nice results on Raven matrices and very complicated IQ tests sort of things that humans are supposed to be really good at but you have to be a pretty smart human to really be good at this and the system just nails it.
So we're making super fast progress. We started off from a very simple BERT model that was able to look at some pictures and now we're getting to these very sophisticated foundation models. So that was my short history of multimodal foundation models.
'*NLP > NLP_Stanford' 카테고리의 다른 글
Multimodal Deep Learning - 5. Evaluation / 6. Where to next? (0) 2024.06.30 Multimodal Deep Learning - 2. Features and fusion / 3. Contrastive models (0) 2024.06.29 Multimodal Deep Learning - 1. Early models (0) 2024.06.29 Model Analysis & Explanation (0) 2024.06.29 Reinforcement Learning from Human Feedback (RLHF) (0) 2024.06.24