-
Multimodal Deep Learning - 5. Evaluation / 6. Where to next?*NLP/NLP_Stanford 2024. 6. 30. 10:54
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=5vfIT5LOkR0&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=22
Lecture 16 - Multimodal Deep Learning

I also have to tell you how you're going to check that the multimodal system is actually good at multimodal things. And so that's the topic of evaluation, which actually is a super important topic.
A lot of people want to be cool and build big models, but I think it should be way cooler to do a proper evaluation of these models, especially if you're in academia because you only have limited GPUs anyway. So what can you do? So how do you check?
There's this amazing project. So ImageNet really changed the history of deep learning. And this other data set CoCo, also really changed, especially vision and language, but also I think vision, in general, where they have just a bunch of main sort of multimodal tasks.
So these images are very richly annotated with all kinds of different things. So like the segmentation of the objects, the bounding boxes, the labels of the bounding boxes they come at different pixel granularities. It's a huge data set. It's very fine-grained annotated in terms of the categories that it has, and then you have five captions for each of these images.
So this really was the first data set that unlocked a lot of sort of vision and language processing at scale because you had your picture and you had your caption and now you need to figure out, OK, how do I give the right caption for this image? So that's image captioning. Or can I retrieve given some piece of text the right image or the image for the piece of text?
So there's a bunch of very impactful data sets that do this stuff. We already talked about LAION, with CoCo really is the main one still I think that a lot of people use as the canonical instance of this data set category.

And then the other thing that people really care about in vision and language processing is visual question answering. So there really are a bunch of academic groups who are or have been so focused on this task that they didn't really care about anything else. And that's why you see a lot of models that are really optimized just for multimodal and nothing else.
You can see that reflected in the citation counts. So VQA just has way more citations than image captioning data sets even, right? So what you do here is you just have an image and then people ask very simple questions. So annotators, they ask these simple questions, they give the answers, and now we want to be able to answer these questions with machines.
As I alluded to earlier, one of the embarrassing backstories of this data set was that the initial version of the data set was actually found to have images not really matter at all. So you could just look at the question and it could have something like, how many slices of pizza are there? Well, not in that particular case, but in almost all of the data set the right answer for how much or how many question was 2. So if you just predicted 2 to every how much or how many questions, you got 70% accuracy on the counting category.
So careful data set or evaluation benchmark design is also really a skill and you really need to think about what you're doing. You can't just set some data aside and evaluate it on, you have to really think about what you're doing.
And so there's VQA by Chris actually, which is also just I think a better-designed version of this data set maybe. So you might want to use that these days.

There are also kind of very targeted data sets that really try to measure one particular thing. And I think one of the things we really want to get at with these models is what we would call compositionality. So we want to be able to really take the parts and reason about the whole and understand the relationships between the different concepts. So CLEVR was a very clever data set that was designed really to measure the compositionality, both on the language side and on the vision side.
So you have to understand the relationships between all of these different objects in the images. So that's been a pretty impactful data set I think for really forcing people to think about compositionality.

But a lot of these data sets really had big problems. So one of the problems is they were too easy. So VQA is plateauing out. We can talk about that a little bit, too. It wasn't really realistic, so you could solve VQA and that's probably going to make some people's lives better. You're all trying to process the means. I can see everybody.
Let's get to the memes first then. So obviously, these memes are not actually in the data set. So I could put some really hateful memes about sort of Hitler or something which are in the data set but that would be less fun. So these are mean meme examples to demonstrate how the data set was constructed.
And so one of the problems we had as I said like VQA, the V didn't really matter. What we want to have is the data set. If we care about multimodality specifically, it's like how do we get a data set that you can only get right if you are good at multimodal reasoning? And otherwise, you're just going to screw it up.
So this is what we came up with. If you have a meme like this one, love the way you smell today, I mean, that's not very nice if you send this to your friend. So it turns out that if you just swap out the background, now it's a very nice thing to say. And this one is, maybe a bit weird if you like this, but there's nothing wrong with it, right? And so it's the same for this one here, like, look, how many people love you with the tumbleweed that's really sad. If you change just one word suddenly it's like a really nice thing to say.
So if you wan to solve this, if you want to classify this correctly for the meanness, then you have to really understand multimodal reasoning. You have to understand the relationship between the image and the text in order to get to the right label. And so it was really constructed by design to do that.

So how we did it exactly is we used some really highly trained annotators. And then one of the big problems with a lot of these data sets is that nobody really knows who owns the meme, for example. So somebody makes this meme now they technically own the copyright. And so when I made this data set, I was working at Facebook, and they were very afraid of copyright things. So what we actually had to do is we had to pay people to make new memes.
So not from scratch. So we could show them the actual examples and then they had to try to find images that were corresponding to the original source image and try to reacreate the meme but now with an image that we could buy from Getty. And so we gave a lot of money to Getty so that we could then release the data set to the public so that people could do actually research on this and understand for their multimodal models whether they're good or not.
And so we really tried to make it so that we had these benign confounders. So the confounder here is obviously that you have your original meme and then you have your confounder where you swap out one of the modalities and here you have the other one, right? So we had our annotators do that as well.

And so this led to a really nice data set, I think, because it showed some of the intuitions that I think a lot of people in the field had, which is that multimodal pretraining doesn't really work.
All of this stuff that people have been doing with all their fancy visual BERT models actually turned out maybe to not really be that useful anyway.
So maybe it got you one point extra from visual BERT to a different visual BERT, like less than a point just by doing that multimodal pretraining. So that means we still have to figure this stuff out.
This data set is far from solved and we still have a long way to go despite all of these fancy models and a new paper coming out every week that does something new like we're not there yet. And I think that's encouraging, especially for you. You can go out and solve it.
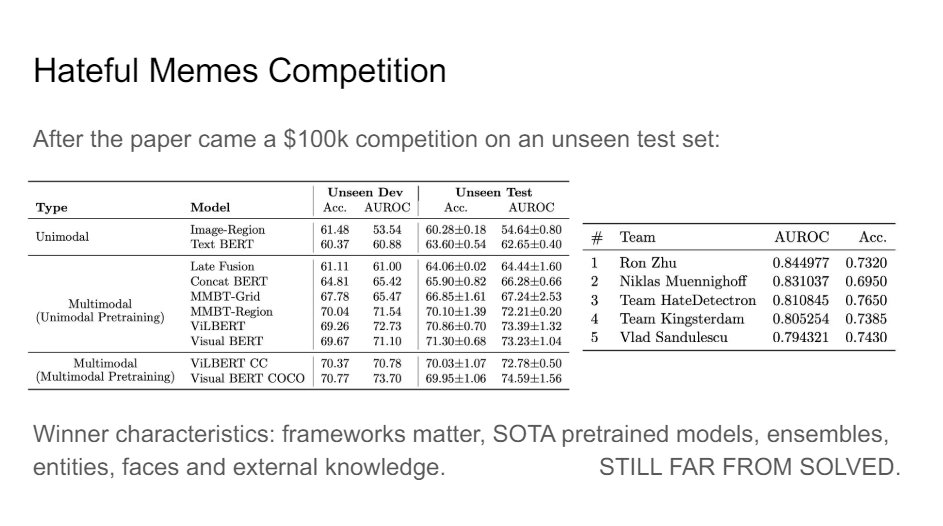
So what we did with this data set is we organized a competition. We had 100K in prize money to try to see what people could come up with. And so there was a lot of nice work coming out of that and we really managed th crank the numbers up by quite a lot. But the solutions were slightly disappointing. So I don't know if you've ever used Kaggle, but if you want to really win on Kaggle you just have to ensemble the hell out of all of the different models that are the current state of the art and then you're very likely to win, right? And so that's what happened here. There wasn't really the fundamental breakthrough we had maybe been hoping for. So that still needs to be built, I think.

This other data set I just want to briefly talk about. So the theme of this section is like if you make a data set, think about it veery carefully, because you can really be very creative with this and really measure the things you're trying to get at.
So this data set Winoground, we were trying to figure out, OK, how good is CLIP actually? So it looks really amazing and it's way better than things that were previously there, but does it understand compositional relationships in the same way that humans would understand it, or is it just sort of fitting onto the data distribution and it can be very good at the head of the distribution but is terrible at the tail?
And you can probably already guess where this is going. So just to give you an illustration of what is in this data set, you would have some plants surrounding a light bulb or you would have a light bulb surrounding some plants. So notice that the words here are exactly the same words but in a different order. So the visual depiction of these words is very, very different.
So if your contrastive model is actually good at understanding the visual semantic or the visual linguistic compositionality of these examples, then it can get it right.
But again, if it's actually just overfitting on the data distribution that is seen and is biased toward what it sees often, then it doesn't really get it.
So one paper that we use as a source of inspiration for this work is this paper here, "Order Word Matters Pre-Training for Little."
So wer actually found that the order of words doesn't even matter that much for general pretraining very often, which is also kind of a scary thing. So this is deep learning for NLP. We think that language is really important, but these models can reason about language even if you shuffle all the words. That's probably not what we want to have. So that doesn't tell you something about how great we are as researchers, it tells you something about how terrible our evaluation benchmarks are. That's what we need to fix.

So what we did with this data set, here are some other nice examples. There's a mug in some grass or there's some grass in a mug. These are verey different pictures. And so for us, these are trivial. So what's the difference between a truck fire and a fire truck? They're pretty important I think also to get that distinction right.

So guess what? State-of-the-art models often perform below random chance.
So as I said, we still have a lot of work to do, which is good. And so when this paper came out, I think the reaction was really nice.
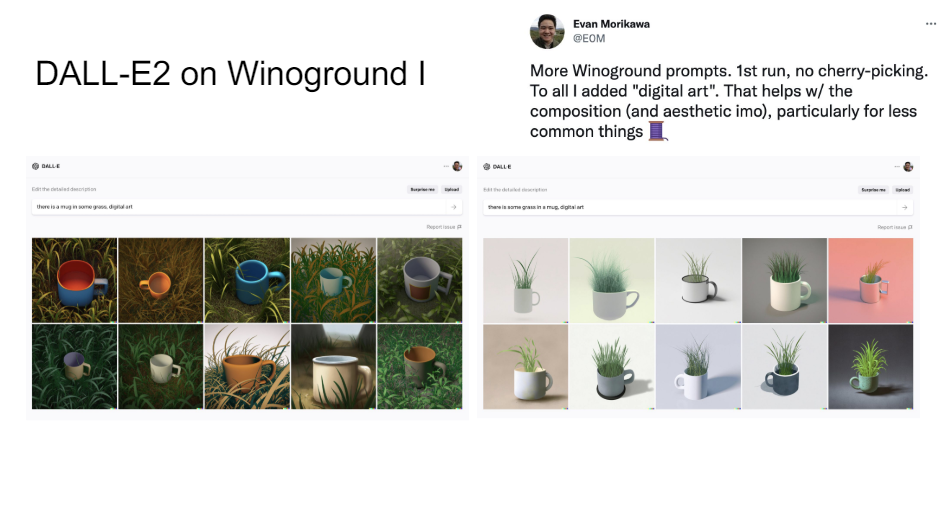
So when DALL-E2 came out-- it's like Stable Difusion but then before Stable Diffusion. And so this was really the first model that really showed just how impressive these generative models can be when they're creating images. So there's a mug in some grass. You do have to kind of cheat a little bit because you have to add digital art here. If you don't add that then it breaks down completely. So it's sort of prompt hacking, I think, or sort of tuning on the test set, but OK.
So this is pretty good. It's definitely is better than I think a lot of people would have expected even a couple of years ago.
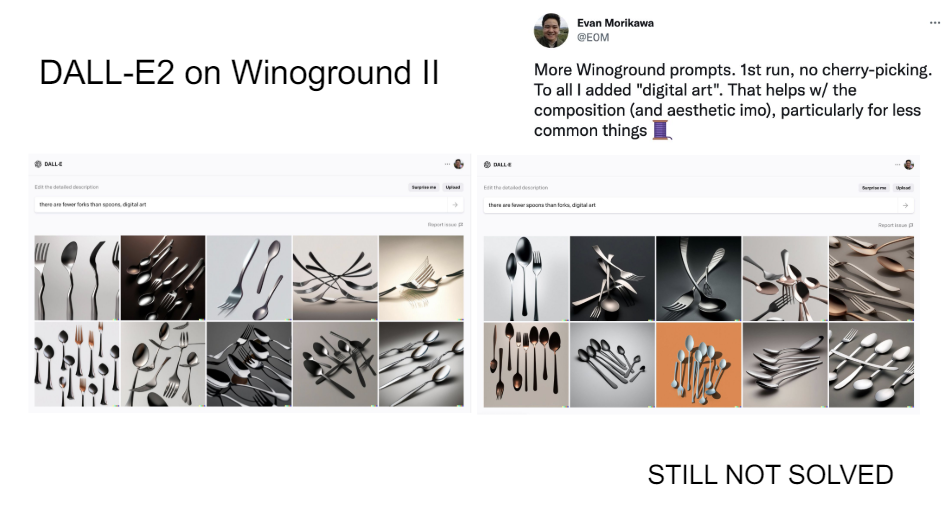
But it's not perfect because people on the internet like to take more pictures of spoons than forks. So if you say there are fewer spoons and forks or there are fewer forks and spoons, it just really like spoons more.
So again, what you can see here is that these models really are just reflections of the data that they're trained on. So models are getting better, but if you've looked at Stable Diffusion, it still can't count fingers and things like that. So again, there's still a lot of cool work to be done.

One foundation model is going to rule them all. So there will be many of these but a lot of them are going to have very similar traits, I think.

We're going to be looking at scaling laws and trying to understand really what is the relationship between the different modalities, which one do we want more of, that sort of stuff.

We're going to have retrieval augmentation. This thing is going to be really huge. So all of these parts of these models can also be multimodal.

We need way better evaluation and better measurement.
'*NLP > NLP_Stanford' 카테고리의 다른 글
Multimodal Deep Learning - 4. Multimodal foundation models (0) 2024.06.29 Multimodal Deep Learning - 2. Features and fusion / 3. Contrastive models (0) 2024.06.29 Multimodal Deep Learning - 1. Early models (0) 2024.06.29 Model Analysis & Explanation (0) 2024.06.29 Reinforcement Learning from Human Feedback (RLHF) (0) 2024.06.24