-
Prompting*NLP/NLP_Stanford 2024. 6. 24. 07:10
※ Writing while taking a course 「Stanford CS224N NLP with Deep Learning」
※ https://www.youtube.com/watch?v=SXpJ9EmG3s4&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=10
Lecture 10 - Prompting & Reinforcement Learning from Human Feedback (RLHF)


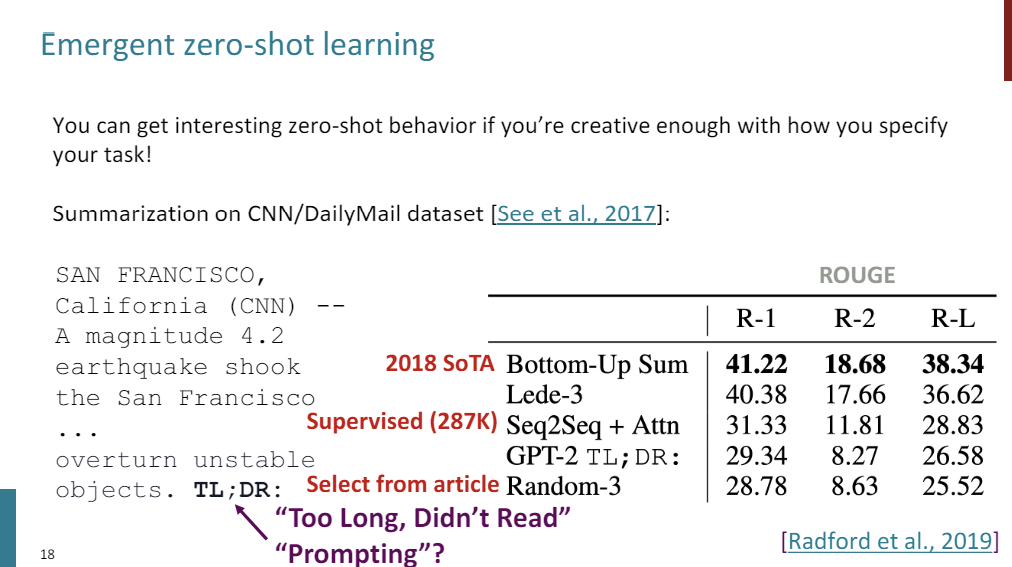

GPT-3 is 175 billion parameters. So it's another increase in size by an order of magnitude.
And at the time, it was unprecedented. I think it still is kind of overwhelmingly large for most people and data.
So they scaled up the data once again. The key takeaway from GPT-3 was emergent Few-Shot learning.
The idea is, GPT can still do Zero-Shot learning, but now, you can specify a task by basically giving examples of the task before asking it to predict the example that you care about.
This is often called in-context learning to stress that there are no gradient updates being performed when you learn a new task. You're basically constructing a tiny little training data set, and just including it in the prompt, including it in the context window of your transformer, and then asking it to pick up on what the task is and then predict the right answer.
This is in contrast to a separate literature on Few-Shot learning, which assumes that you can do gradient updates. In this case, it's really just a frozen language model.


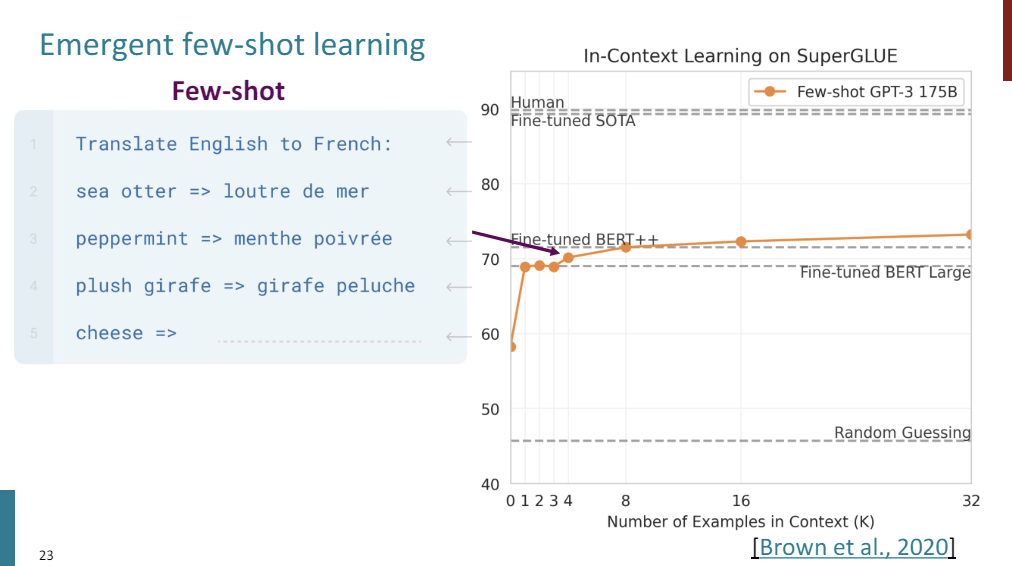
Few-Shot learning works, and it's really impressive. SuperGLUE is a wide coverage natural language understanding benchmark, and what they did was they took GPT-3, and this data point here is what you get when you just do Zero-Shot learning with GPT-3.
So you provide an English description of the task to be completed, and then you ask it to complete the task. Just by providing one example, so one shot, you get like a 10% accuracy increase. So you give, not only the natural language task description, but also an example input and an example output, and you ask it to decode the next output.
And as you increase to more shots, you do get better and better scores, although, of course, you get diminishing returns after a while. But what you can noitice is that Few-Shot GPT-3, so no gradient updates, is doing as well as or outperforming BERT fine tuned on the SuperGLUE task explicitly.

So one thing that I think is really exciting is that you might think, OK, in Few-Shot learning, whatever, it's just memorizing. Maybe there's a lot of examples of needing to do a Few-Shot learning in the internet text data, right? And that's true, but I think there's also evidence that GPT-3 is really learning to do some sort of on the fly optimization or reasoning.
And so the evidence for this comes in the form of these synthetic word unscrambling tasks. So the authors came up with a bunch of simple kind of letter manipulation tasks that are probably unlikely to exist in internet text data.
So these include thing like cycling through the letters to get the kind of uncycled version of a word, so converting from pleap to apple, removing characters added to a word or even just reversing words. And what you see here is performance as you do a Few-Shot learning, as you increase the model size.
And what you can see is that the ability to do Few-Shot learning is kind of an emergent property of model scale, so at the very largest model, we're actually seeing a model be able to do this exclusively in context.
※ Is there's some intuition for why this emerges as a result of model scale?
I think that's a highly active area of research, and there's been papers published every week on this. So I think there's a lot of interesting experiments that really try to dissect either with like synthetic tasks, like, can GPT-3 learn linear regression in context?
And there's some model interpretability tasks, like, what in the attention layers, or what in the hidden states are resulting in this kind of emergent learning?
But I'd have to just refer you to the recent literature on that.
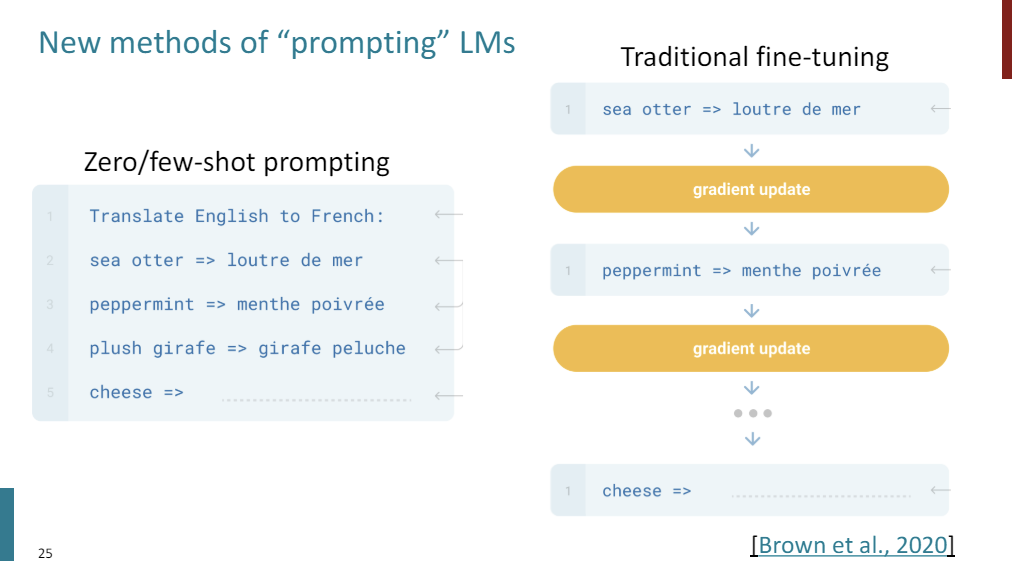
To summarize, traditional fine tuning, we take a bunch of examples of a task that we care about, we give it to our model, and then we do a gradient step on each example. And then at the end, we hopefully, get a model that can do well on some output.
And in this new kind of paradigm of just prompting a language model, we just have a frozen language model, and we just give some examples and ask the model to predict the right answer.

There's a lot of limits of prompting, but especially for tasks that are too hard. There are a lot of tasks that maybe seem to difficult, especially ones that involve maybe richer reasoning steps or needing to synthesize multiple pieces of information. And these are tasks that humans struggle with too.
So one example is GPT-3 was famously bad at doing addition for much larger digits. And so if you prompt GPT-3 with a bunch of examples of addition, it won't do it correct, but part of the reason is because humans are also pretty bad at doing this in one step. Like, if I asked you to just add these two numbers on the fly and didn't give you a pencil and paper, you'd have a pretty hard time with it.
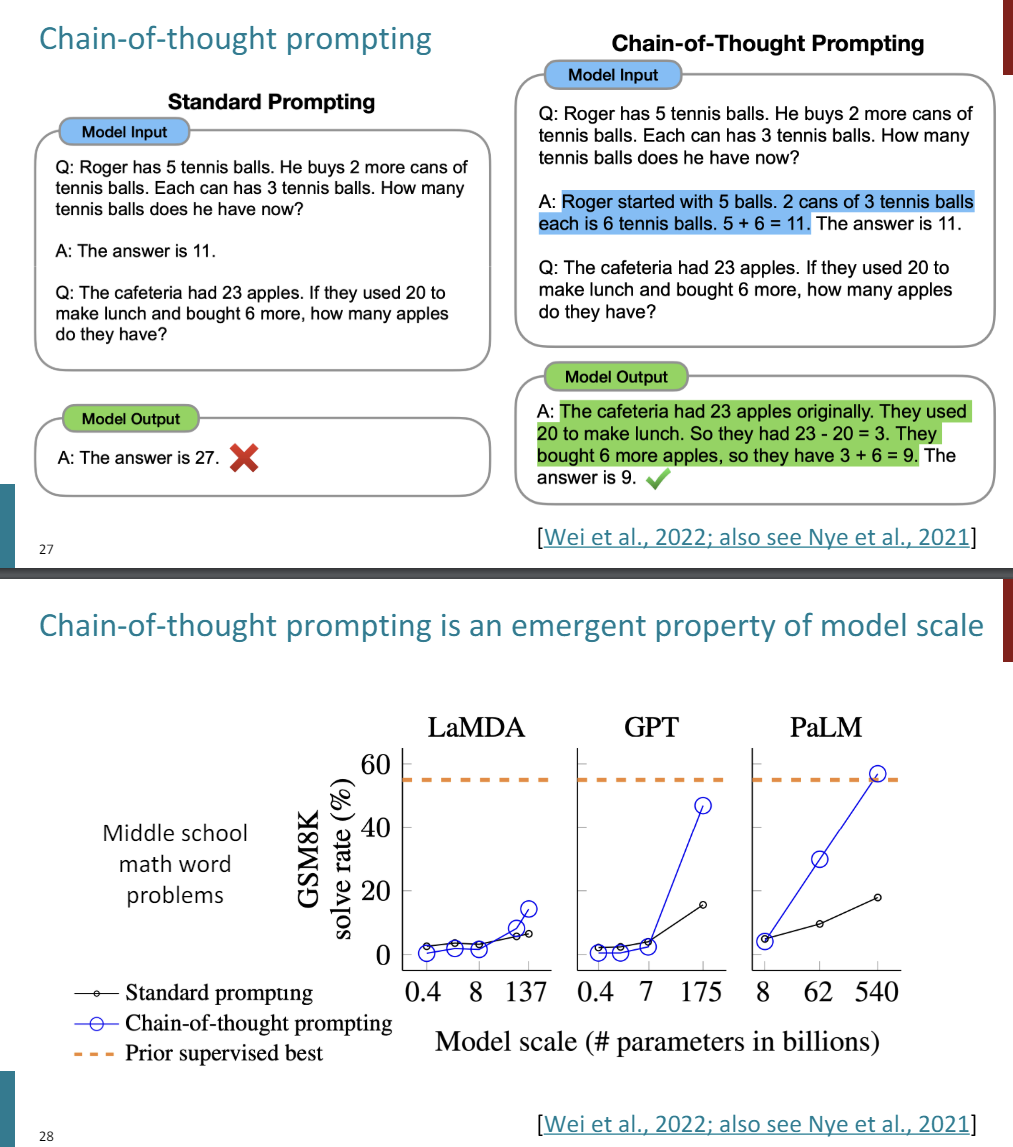
So one observation is that you can just change the prompts and hopefully get some better performance out of this. So there's this idea of doing Chain-of-Thoughts prompting.
Where in standard prompting, we give some examples of a task that we'd like to complete. So here is an example of a math word problem. And I told you that what we would do is we would give the question and then the answer, and then for a data point that we actually care about, we ask the model to predict the answer.
And the model will try to produce the right answer, and it's just wrong. So the idea of chain-of-thought prompting is to actually demonstrate what kind of reasoning you want the model to complete.
So in your prompt, you not only put the question, but you also put an answer and the kinds of reasoning steps that are required to arrive at the correct answer.
And because a language model is incentivized to just follow the pattern and continue the prompt, if you give it another question, it will, in turn, produce a rationale followed by an answer. So you're asking the language model to work through the steps yourself. And by doing so, you end up getting some questions right when you otherwise might not.
So super simple idea, but it's shown to be extremely effective. So here is this middle school math word problems benchmark, and again, as we scale up the model for GPT and some other kinds of models, being able to do chain-of-thought prompting emerges. So we really see a performance approaching that of supervised baselines for these larger and larger models.

Follow up work to this asks the question of, do we actually even need examples of reasoning? Do we actually need to collect humans working through these problems?
Can we actually just ask the model to reason through things? Just ask it nicely.
So this introduced idea called "Zero-Shot Chain-of-Thought prompting". And it was honestly, I think probably the highest impact to simple idea ratio I've seen in a paper. Where it's like, the simplest possible thing where instead of doing this chain-of-thought stuff, you just ask the question. And then the answer.
You first prepend the token, "let's think step by step."
And the model will decode as if it had said, let's think step by step, and it will work through some reasoning and produce the right answer.
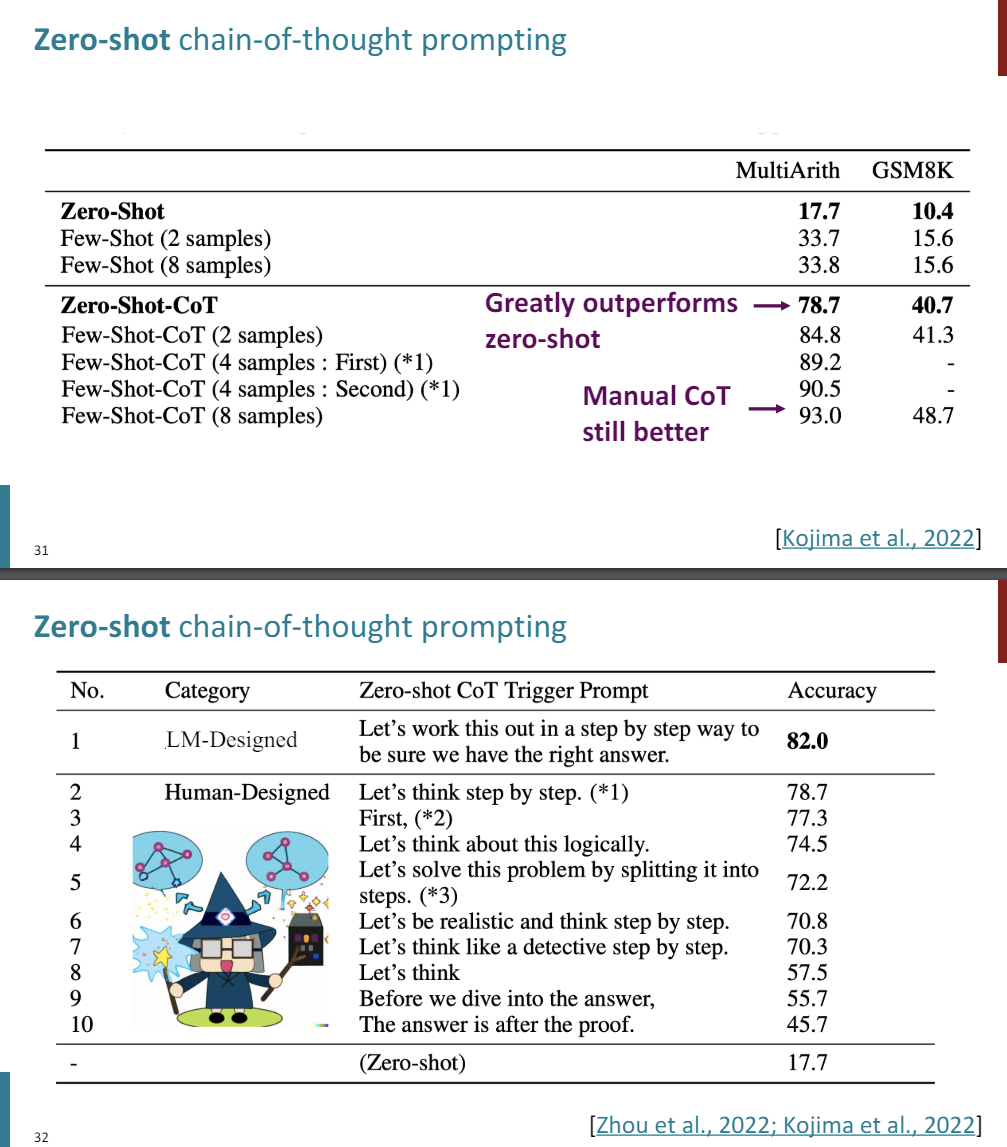
So does this work on some arithmetic benchmarks?
Here's what happens when you prompt the model, just Zero-Shot, so just asking it to produce the answer right away without any reasoning.
Few-Shots, so giving some examples of inputs and outputs. And this is Zero-Shot chain-of-thought, so just asking the model to think through things, you get crazy good accuracy.
When we compare it to actually doing manual chain-of-thought, you still do better with manual chain-of-thought, but that just goes to show you how simple of an idea this is, and ends up producing improved performance numbers.
So the funny part of this paper was, why use "let's think by step by step"? They used actually a lot of prompts and tried them out. So here, Zero-Shot baseline performance.
They tried out a bunch of different prefixes, the answers after the proof, let's think about this logically. And they fould that let's think step by step was the best one. It turns out, this was actually built upon-- later in the year, where they actually used a language model to search through the best possible strings that would maximize performance on this task, which is probably like gross overfitting, but the best prompt they found was let's work this out step by step in a step by step way to be sure that we have the right answer.
It's like giving the model some confidence in itself.
We really have no intuition as to what's going on here, or we're trying to build some intuition. As as result, there's this whole new idea of prompt engineering being an emerging science and profession.
So this includes things like asking a model for reasoning, it includes jailbreaking language models, so telling them to do things that they otherwise aren't trained to do. Even AI art, like, DALL-e or stable difusion, this idea of constructing these really complex prompts to get model outputs that you want, that's also prompting.
Anecdotally, I've heard of peaple saying, I'm going to use a code generation model, but I'm going to include the Google code header in first because that will make more professional or bug free code, depending on how much you believe in Google. And there's a Wikipedia article on this now, and there's even startups that are hiring for prompt engineers, and they pay quite well. So if you want to be a prompt engineer, definitely pratice your GPT whispering skills. ^^;

Talking about these three things, I'm going to talk about the benefits and limitations of the various different things that we could be doing here.
So for Zero-shot and Few-Shot In-Context Learning, the benefit is you don't need any fine tuning, and you can carefully construct your prompts to hopefully get better performance.
The downsides are there are limits to what you can fit in context. Transformers have a fixed context window of say 1,000 or a few thousand tokens. And, I think, as you will probably find out, for really complex tasks, you are indeed going to need some gradient steps. So you're going to need some sort of fine tuning.
But that brings us the next part, "Instruction finetuning."

So the idea of instruction finetuning is that, these models are pretty good at doing prompting, you can get them to do really interesting things, but there is still a problem, which is that language models are trained to predict the most likely continuation of tokens, and that is not the same as what we want language models to do, which is to assist people.
So as an example, if I give GPT-3 this kind of prompt, explain the moon landing, GPT-3 is trained to predict, if I saw this on the internet somewhere, what is the most likely continuation? Well, maybe someone was coming up with a list of things to do with a six-year-old. So it's just predicting a list of other tasks, it's not answering your question.
And so the issue here is that language models are not aligned with user intent.
So how might we better align models with user intent for this case?
Well, super simple asnwer. We're machine learners, let's do machine learning. So we're going to collect-- you'd ask a human, give me the right answer. Give me the way that a language model should respond according to this prompt. And let's just do finetuning.

Again, pre-training can improve NLP applications by serving as parameter initialization. And the difference here is that instead of finetuning on a single downstream task of interest, like, sentiment analysis, what we're going to do is we're going to finetune on many tasks.
So we have a lot of tasks, and hope is that we can then generalize to other unseen tasks at test time.
So as you might expect, data and scale is key for this to work.
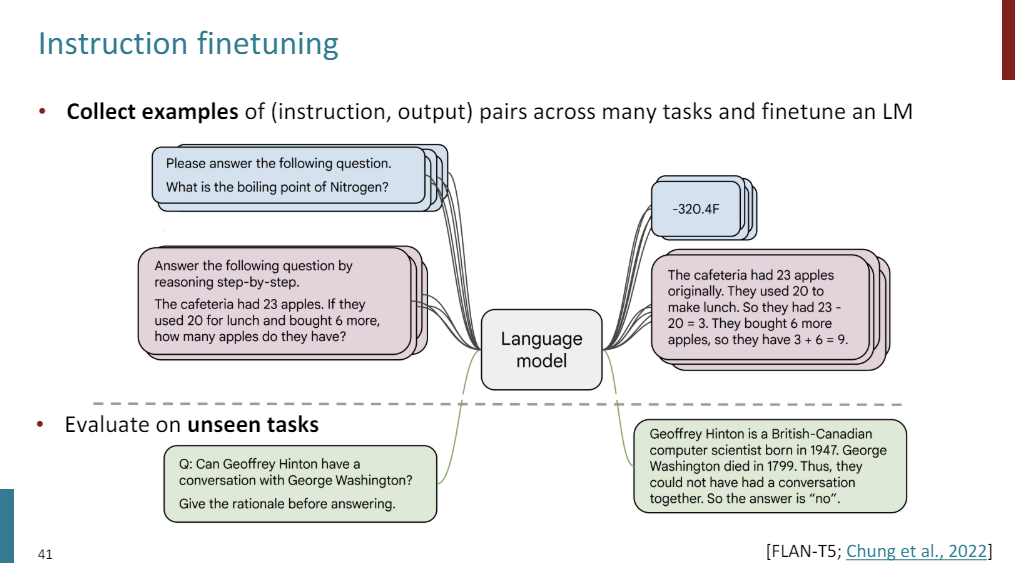
So we're going to collect a bunch of examples of instruction & output pairs across many tasks and then finetune our language model, and then evaluate generalization to unseen tasks.
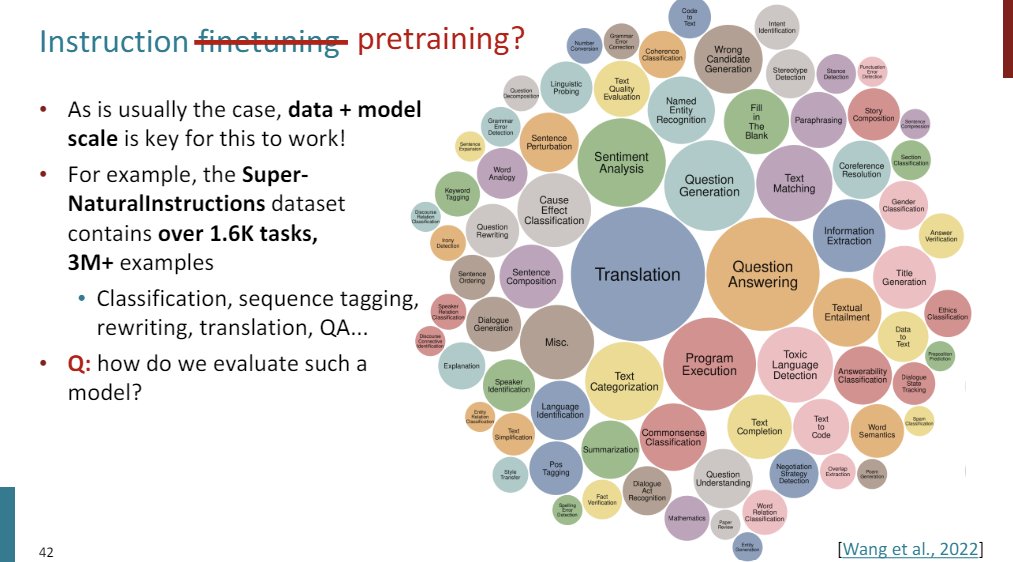
So data and scale is important. So as an example, one recent data set that was published for this is called the Super-NaturalInstructions data set, it contains over 1,600 tasks, containing 3 million examples.
So this includes translation, question answering, question generation, even coding, mathematical reasoning, et cetera.
And when you look at this, you really begin to think, well, is this actually finetuning or is this just more pre-training? And it's actually both, right? The amount of scale that we're training this on, basically, it is a still general, but slightly more specific than language modeling type of pre-training task.


Now that we are training our model on so many tasks, how do we evaluate such a model?
The scale of tasks that you want to evaluate this language model on is much greater. a lot of research has been going into building up these benchmarks for these massive multitask language models, and seeing to what degree they can do, not only just one task, but just a variety of tasks.
So this is the massive multitask language understanding benchmark or MMLU. It consists of a bunch of benchmarks for measuring language model performance on a bunch of knowledge intensive tasks that you would expect a high shool or college student to complete. So you're testing a language model, not only on sentiment analysis, but on astronomy, and logic, and European history.
And here are some numbers where, at the time, GPT-3 is like not that good, but it's certainly above a random baseline on all of these tasks.
Here's another example. So this is the beyond the Imitation Game benchmark, or Big-Bench. This has like a billion authors because it was a huge collaborative effort, and this is a word cloud of the tasks that were evaluated.
And it really contains some very esoteric tasks. So this is an example of one task included, where you have to -- given Kanji or Japanese character in ASCII Art, you need to predict the meaning of the character.
So we're really stress testing these language models. ^^;;

So instruction finetuning, does it work? Recall there's a T5 encoder-decoder model where it's pre-trained on span corruption task. The authors release a newer version called FLAN-T5, so FLAN stands for finetuning language models. And this is T5 models trained on an additional 1,800 tasks, which include the natural instructions data set that I just mentioned. And if we average across both the Big-Bench and MMLU performance and normalize it, what we see is that instruction finetuning works.
And crucially, the bigger the model, the bigger the benefit that you get from doing instruction finetuning. So it's really the large models that stand to do well from finetuning. And you might look at this and say, this is kind of sad for academics or anyone without a massive GPU cluster. It's like, who can run an 11 billion parameter model?
I guess the one silver lining, if you look at the results here, are the 80 million model, which is the smallest one, if you look at after finetuning, it ends up performing about as well as the un-finetuned 11 billion parameter model. So there's a lot of examples in the literature about smaller instruction finetuned pre-trained models outperforming larger models that are many, many more times the size.
So hopefully, there's still some hope for people with just like a few GPUs. ^^;;;

In order to really understand the capabilities, I highly recommend that you just try it out yourself. So FLAN-T5 is hosted on Hugging Face. I think, Hugging Face has a demo where you can just type in a littler query, ask it to do anything, see what it does, but there are qualitative examples of this working. So for questions where a non-instruction finetuned model will just kind of waffle on and not answer the question, doing instruction finetuning will get your model to much more accurately reason through things and give you the right answer.



That was instruction finetuning. Positives of this method, super simple, super straightforward, it's just doing finetuning. And this really cool ability to generalize to unseen tasks.
In terms of negatives, it's hard and annoying to get human labels, and it's expensive. That's something that definitely matters. And humans might disagree on what the right label is, that's increasingly a problem.
So what are the limitations? The obvious limitation is money. Collecting ground truth data for so may tasks costs a lot of money. Subtler limitations include, as we begin to ask for more creative and open ended tasks from our models, there are tasks where there is no right answer, and it's a little bit weird to say, this is an example of how to write some story. So write me a story about a dog and our pet grasshopper. Like, there is not one answer to this, but if we were to only to collect one or two demonstrations, the langauge modeling objective would say, you should put all of your probability mass on the two ways that two humans wrote this answer, right? When in reality, there's no right answer.
Another problem, which is related fundamentally to language modeling in the first place, is that language modeling as an objective, penalizes all token level mistakes equally. So what I mean by that is, if you were asking a language model, for example, to predict the sentence, Avartar is a fantasy TV show. And you were asking it, and let's imagine that the LM mispredicted adventure instead of fantasy. So adventure is a mistake, it's not the right word, but it is equally as bad as if the model were to predict something like musical. But the problem is that Avartar is an adventure TV show is still true. So it's not necessarily a bad thing.
Whereas, Avartar is a musical is just false. So under the language modeling objective, if the model were equally confidence, you would pay an equal penalty, an equal loss penalty, for predicting either of those tokens wrong.
But it's clear that this objective is not actually aligned with what users want, which is maybe truth for creativity, or generally, just this idea of human preferences.
'*NLP > NLP_Stanford' 카테고리의 다른 글
Model Analysis & Explanation (0) 2024.06.29 Reinforcement Learning from Human Feedback (RLHF) (0) 2024.06.24 Pretraining (0) 2024.06.23 Self-Attention & Transformers (0) 2024.06.22 Neural Machine Translation (0) 2024.06.22