-
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion ModelsResearch/Diffusion 2025. 1. 23. 12:37
https://arxiv.org/pdf/2112.10741
(Mar 2022) PMLR 2022
Abstract
Diffusion models have recently been shown to generate high-quality synthetic images, especially when paired with a guidance technique to trade off diversity for fidelity. We explore diffusion models for the problem of text-conditional image synthesis and compare two different guidance strategies: CLIP guidance and classifier-free guidance. We find that the latter is preferred by human evaluators for both photorealism and caption similarity, and often produces photorealistic samples. Samples from a 3.5 billion parameter text-conditional diffusion model using classifier-free guidance are favored by human evaluators to those from DALL-E, even when the latter uses expensive CLIP reranking. Additionally, we find that our models can be fine-tuned to perform image inpainting, enabling powerful text-driven image editing. We train a smaller model on a filtered dataset and release the code and weights at https://github.com/openai/glide-text2im
1. Introduction
Images, such as illustrations, paintings, and photographs, can often be easily described using text, but can require specialized skills and hours of labor to create. Therefore, a tool capable of generating realistic images from natural language can empower humans to create rich and diverse visual content with unprecedented ease. The ability to edit images using natural language further allows for iterative refinement and fine-grained control, both of which are critical for real world applications.
Recent text-conditional image models are capable of synthesizing images from free-form text prompts, and can compose unrelated objects in semantically plausible ways (Xu et al., 2017; Zhu et al., 2019; Tao et al., 2020; Ramesh et al., 2021; Zhang et al., 2021). However, they are not yet able to generate photorealistic images that capture all aspects of their corresponding text prompts.
On the other hand, unconditional image models can synthesize photorealistic images (Brock et al., 2018; Karras et al., 2019a;b; Razavi et al., 2019), sometimes with enough fidelity that humans can’t distinguish them from real images (Zhou et al., 2019). Within this line of research, diffusion models (Sohl-Dickstein et al., 2015; Song & Ermon, 2020b) have emerged as a promising family of generative models, achieving state-of-the-art sample quality on a number of image generation benchmarks (Ho et al., 2020; Dhariwal & Nichol, 2021; Ho et al., 2021).
To achieve photorealism in the class-conditional setting, Dhariwal & Nichol (2021) augmented diffusion models with classifier guidance, a technique which allows diffusion models to condition on a classifier’s labels. The classifier is first trained on noised images, and during the diffusion sampling process, gradients from the classifier are used to guide the sample towards the label. Ho & Salimans (2021) achieved similar results without a separately trained classifier through the use of classifier-free guidance, a form of guidance that interpolates between predictions from a diffusion model with and without labels.
Motivated by the ability of guided diffusion models to generate photorealistic samples and the ability of text-to-image models to handle free-form prompts, we apply guided diffusion to the problem of text-conditional image synthesis. First, we train a 3.5 billion parameter diffusion model that uses a text encoder to condition on natural language descriptions. Next, we compare two techniques for guiding diffusion models towards text prompts: CLIP guidance and classifier-free guidance. Using human and automated evaluations, we find that classifier-free guidance yields higher-quality images.
We find that samples from our model generated with classifier-free guidance are both photorealistic and reflect a wide breadth of world knowledge. When evaluated by human judges, our samples are preferred to those from DALL-E (Ramesh et al., 2021) 87% of the time when evaluated for photorealism, and 69% of the time when evaluated for caption similarity.
While our model can render a wide variety of text prompts zero-shot, it can have difficulty producing realistic images for complex prompts. Therefore, we provide our model with editing capabilities in addition to zero-shot generation, which allows humans to iteratively improve model samples until they match more complex prompts. Specifically, we fine-tune our model to perform image inpainting, finding that it is capable of making realistic edits to existing images using natural language prompts. Edits produced by the model match the style and lighting of the surrounding context, including convincing shadows and reflections. Future applications of these models could potentially aid humans in creating compelling custom images with unprecedented speed and ease.
We observe that our resulting model can significantly reduce the effort required to produce convincing disinformation or Deepfakes. To safeguard against these use cases while aiding future research, we release a smaller diffusion model and a noised CLIP model trained on filtered datasets.
We refer to our system as GLIDE, which stands for Guided Language to Image Diffusion for Generation and Editing. We refer to our small filtered model as GLIDE (filtered).





2. Background
In the following sections, we outline the components of the final models we will evaluate: diffusion, classifier-free guidance, and CLIP guidance.
2.1. Diffusion Models



2.2. Guided Diffusion


2.3. Classifier-free guidance

2.4. CLIP Guidance


3. Related Work
Many works have approached the problem of text-conditional image generation. Xu et al. (2017); Zhu et al. (2019); Tao et al. (2020); Zhang et al. (2021); Ye et al. (2021) train GANs with text-conditioning using publicly available image captioning datasets. Ramesh et al. (2021) synthesize images conditioned on text by building on the approach of van den Oord et al. (2017), wherein an autoregressive generative model is trained on top of discrete latent codes. Concurrently with our work, Gu et al. (2021) train text-conditional discrete diffusion models on top of discrete latent codes, finding that the resulting system can produce competitive image samples.
Several works have explored image inpainting with diffusion models. Meng et al. (2021) finds that diffusion models can not only inpaint regions of an image, but can do so conditioned on a rough sketch (or set of colors) for the image. Saharia et al. (2021a) finds that, when trained directly on the inpainting task, diffusion models can smoothly inpaint regions of an image without edge artifacts.
CLIP has previously been used to guide image generation. Galatolo et al. (2021); Patashnik et al. (2021); Murdock (2021); Gal et al. (2021) use CLIP to guide GAN generation towards text prompts. The online AI-generated art community has produced promising early results using unnoised CLIP-guided diffusion (Crowson, 2021a;b). Kim & Ye (2021) edits images using text prompts by fine-tuning a diffusion model to target a CLIP loss while reconstructing the original image’s DDIM (Song et al., 2020a) latent. Zhou et al. (2021) trains GAN models conditioned on perturbed CLIP image embeddings, resulting in a model which can condition images on CLIP text embeddings. None of these works explore noised CLIP models, and often rely on data augmentations and perceptual losses as a result.
Several works have explored text-based image editing. Zhang et al. (2020) propose a dual attention mechanism for using text embeddings to inpaint missing regions of an image. Stap et al. (2020) propose a method for editing images of faces using feature vectors grounded in text. Bau et al. (2021) pair CLIP with state-of-the-art GAN models to inpaint images using text targets. Concurrently with our work, Avrahami et al. (2021) use CLIP-guided diffusion to inpaint regions of images conditioned on text.
4. Training
For our main experiments, we train a 3.5 billion parameter text-conditional diffusion model at 64 × 64 resolution, and another 1.5 billion parameter text-conditional upsampling diffusion model to increase the resolution to 256 × 256. For CLIP guidance, we also train a noised 64 × 64 ViT-L CLIP model (Dosovitskiy et al., 2020).
4.1. Text-Conditional Diffusion Models
We adopt the ADM model architecture proposed by Dhariwal & Nichol (2021), but augment it with text conditioning information. For each noised image xt and corresponding text caption c, our model predicts p(xt−1|xt, c). To condition on the text, we first encode it into a sequence of K tokens, and feed these tokens into a Transformer model (Vaswani et al., 2017). The output of this transformer is used in two ways: first, the final token embedding is used in place of a class embedding in the ADM model; second, the last layer of token embeddings (a sequence of K feature vectors) is separately projected to the dimensionality of each attention layer throughout the ADM model, and then concatenated to the attention context at each layer.
We train our model on the same dataset as DALL-E (Ramesh et al., 2021). We use the same model architecture as the ImageNet 64 × 64 model from Dhariwal & Nichol (2021), but scale the model width to 512 channels, resulting in roughly 2.3 billion parameters for the visual part of the model. For the text encoding Transformer, we use 24 residual blocks of width 2048, resulting in roughly 1.2 billion parameters.
Additionally, we train a 1.5 billion parameter upsampling diffusion model to go from 64 × 64 to 256 × 256 resolution. This model is conditioned on text in the same way as the base model, but uses a smaller text encoder with width 1024 instead of 2048. Otherwise, the architecture matches the ImageNet upsampler from Dhariwal & Nichol (2021), except that we increase the number of base channels to 384.
We train the base model for 2.5M iterations at batch size 2048. We train the upsampling model for 1.6M iterations at batch size 512. We find that these models train stably with 16-bit precision and traditional loss scaling (Micikevicius et al., 2017). The total training compute is roughly equal to that used to train DALL-E.
4.2. Fine-tuning for classifier-free guidance
After the initial training run, we fine-tuned our base model to support unconditional image generation. This training procedure is exactly like pre-training, except 20% of text token sequences are replaced with the empty sequence. This way, the model retains its ability to generate text-conditional outputs, but can also generate images unconditionally.
4.3. Image Inpainting
Most previous work that uses diffusion models for inpainting has not trained diffusion models explicitly for this task (Sohl-Dickstein et al., 2015; Song et al., 2020b; Meng et al., 2021). In particular, diffusion model inpainting can be performed by sampling from the diffusion model as usual, but replacing the known region of the image with a sample from q(xt|x0) after each sampling step. This has the disadvantage that the model cannot see the entire context during the sampling process (only a noised version of it), occasionally resulting in undesired edge artifacts in our early experiments.
To achieve better results, we explicitly fine-tune our model to perform inpainting, similar to Saharia et al. (2021a). During fine-tuning, random regions of training examples are erased, and the remaining portions are fed into the model along with a mask channel as additional conditioning information. We modify the model architecture to have four additional input channels: a second set of RGB channels, and a mask channel. We initialize the corresponding input weights for these new channels to zero before fine-tuning. For the upsampling model, we always provide the full low-resolution image, but only provide the unmasked region of the high-resolution image.
4.4. Noised CLIP models
To better match the classifier guidance technique from Dhariwal & Nichol (2021), we train noised CLIP models with an image encoder f(xt, t) that receives noised images xt and is otherwise trained with the same objective as the original CLIP model. We train these models at 64 × 64 resolution with the same noise schedule as our base model.


5. Results
5.1. Qualitative Results
When visually comparing CLIP guidance to classifier-free guidance in Figure 5, we find that samples from classifier-free guidance often look more realistic than those produced using CLIP guidance. The remainder of our samples are produced using classifier-free guidance, a choice which we justify in the next section.
In Figure 1, we observe that GLIDE with classifier-free guidance is capable of generalizing to a wide variety of prompts. The model often generates realistic shadows and reflections, as well as high-quality textures. It is also capable of producing illustrations in various styles, such as the style of a particular artist or painting, or in general styles like pixel art. Finally, the model is able to compose several concepts (e.g. a corgi, bowtie, and birthday hat), all while binding attributes (e.g. colors) to these objects.
On the inpainting task, we find that GLIDE can realistically modify existing images using text prompts, inserting new objects, shadows and reflections when necessary (Figure 2). The model can even match styles when editing objects into paintings. We also experiment with SDEdit (Meng et al., 2021) in Figure 4, finding that our model is capable of turning sketches into realistic image edits. In Figure 3 we show how we can use GLIDE iteratively to produce a complex scene using a zero-shot generation followed by a series of inpainting edits.
In Figure 5, we compare our model to the previous state-of-the-art text-conditional image generation models on captions from MS-COCO, finding that our model produces more realistic images without CLIP reranking or cherry-picking.
For additional qualitative comparisons, see Appendix C, D, E.
5.2. Quantitative Results
We first evaluate the difference between classifier-free guidance and CLIP guidance by looking at the Pareto frontier of the quality-fidelity trade-off. In Figure 6 we evaluate both approaches on zero-shot MS-COCO generation at 64 × 64 resolution. We look at Precision/Recall (Kynka¨anniemi et al., 2019), FID (Heusel et al., 2017), Inception Score (Salimans et al., 2016), and CLIP score1 (Radford et al., 2021). As we increase both guidance scales, we observe a clean trade-off in FID vs. IS, Precision vs. Recall, and CLIP score vs. FID. In the former two curves, we find that classifier-free guidance is (nearly) Pareto optimal. We see the exact opposite trend when plotting CLIP score against FID; in particular, CLIP guidance seems to be able to boost CLIP score much more than classifier-free guidance.
We hypothesize that CLIP guidance is finding adversarial examples for the evaluation CLIP model, rather than actually outperforming classifier-free guidance when it comes to matching the prompt. To verify this hypothesis, we employed human evaluators to judge the sample quality of generated images. In this setup, human evaluators are presented with two 256 × 256 images and must choose which sample either 1) better matches a given caption, or 2) looks more photorealistic. The human evaluator may also indicate that neither image is significantly better than the other, in which case half of a win is assigned to both models.
Using our human evaluation protocol, we first sweep over guidance scales for both approaches separately (Figure 7), then compare the two methods with the best scales from the previous stage (Table 1). We find that humans disagree with CLIP score, finding classifier-free guidance to yield higher-quality samples that agree more with the corresponding prompt.
We also compare GLIDE with other text-conditional generative image models. We find in Table 2 that our model obtains competitive FID on MS-COCO without ever explicitly training on this dataset. We also compute FID against a subset of the MS-COCO validation set that has been purged of all images similar to images in our training set, as done by Ramesh et al. (2021). This reduces the validation batch by 21%. We find that our FID increases slightly from 12.24 to 12.89 in this case, which could largely be explained by the change in FID bias when using a smaller reference batch.
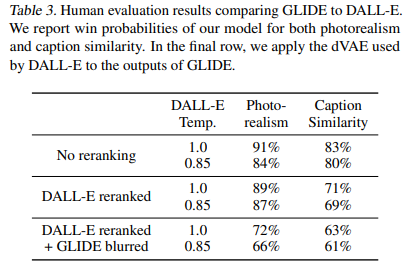
Finally, we compare GLIDE against DALL-E using our human evaluation protocol (Table 3). Note that GLIDE was trained with roughly the same training compute as DALL-E but with a much smaller model (3.5 billion vs. 12 billion parameters). It also requires less sampling latency and no CLIP reranking.
We perform three sets of comparisons between DALL-E and GLIDE. First, we compare both models when using no CLIP reranking. Second, we use CLIP reranking only for DALL-E. Finally, we use CLIP reranking for DALL-E and also project GLIDE samples through the discrete VAE used by DALL-E. The latter allows us to assess how DALLE’s blurry samples affect human judgement. We do all evals using two temperatures for the DALL-E model. Our model is preferred by the human evalautors in all settings, even in the configurations that heavily favor DALL-E by allowing it to use a much larger amount of test-time compute (through CLIP reranking) while reducing GLIDE sample quality (through VAE blurring).
For sample grids from DALL-E with CLIP reranking and GLIDE with various guidance strategies, see Appendix G.




'Research > Diffusion' 카테고리의 다른 글
Progressive Distillation for Fast Sampling of Diffusion Models (0) 2025.01.23 Denoising Diffusion Implicit Models (0) 2025.01.23 High-Resolution Image Synthesis with Latent Diffusion Models (0) 2024.08.23 Diffusion Models Beat GANs on Image Synthesis (0) 2024.08.21 Improved Denoising Diffusion Probabilistic Models (0) 2024.08.20