-
[CausalPFN] Amortized Causal Effect Estimation via In-Context LearningCausality/paper 2026. 1. 10. 20:30
https://neurips.cc/virtual/2025/loc/san-diego/poster/118013
NeurIPS Poster CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
Causal effect estimation from observational data is fundamental across various applications. However, selecting an appropriate estimator from dozens of specialized methods demands substantial manual effort and domain expertise. We present CausalPFN, a sing
neurips.cc
https://github.com/vdblm/CausalPFN/
GitHub - vdblm/CausalPFN: CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
CausalPFN: Amortized Causal Effect Estimation via In-Context Learning - vdblm/CausalPFN
github.com
https://openreview.net/pdf?id=RblaNJGx8C
(NeurIPS 2025)
※ 참고: PFN (my essay)
https://letter-night.tistory.com/1031
PFN의 idea는 powerful하다.
prior distribution에서 sampling한 다양한 synthetic datasets로 in-context learning하는 pre-train으로써 "task를 수행하는 방법"을 "meta-learn"한다.
Test time에는 주어진 unseen dataset에 대하여 in-context leraning을 (context를 보고 completion) 수행한다.
이렇게, task를 meta-learn 하게 되면, inference 시에 주어진 어떤 dataset에 대해서도 generalize하여서, task 를 수행할 수 있다.
PFN framework을 바탕으로,
다양한 causal structure에 대해서 interventional effect를 구하는 방법을 meta learn한 후에,
inference 시에는 새로운 dataset에서 interventional effect를 구할 수 있는,"pre-trained foundation model for causal effect estimation" 가 가능하겠구나! 라는 생각을 했다.
그 idea가 적용된 논문 - DoPFN을 흥미롭게 보았었다.DoPFN에서 몇가지 아쉬운 점들이 있었다.
1. 가장 기본적으로, 어떻게 scaling-up 할 수 있을까?
DoPFN에서는 기본적인 DAG structure로 case study를 한다. 현실 세계의 DAG는 훨씬 크고 복잡하다.
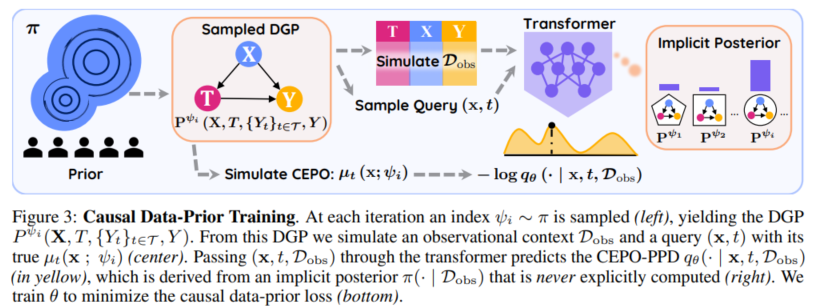
PFN은 일종의 amortized Bayesian inference framework이기 때문에, 제목 그대로 "prior-fitting"이 정말 중요하다고 생각된다.
아주 대량의 diverse한 dataset을 simulate하여서 pre-training하는 것이 핵심일 것이다.그렇다면, 아주 복잡한 DAG structure를 prior에서 sampling해서 in-context learning을 수행하여야 할텐데, 이게 가능할까?
2. DoPFN에서는 causal inference에 기본적으로 등장하는 assumption이 violate되는 상황 하에서도,
model이 어느정도(?) causal effect를 estimate함을 보였다. 그리고 그에 따른 uncertainty가 반영됨을 보였다.
현실에서는 violate되는 경우가 훨씬 많을 것이다. (hidden confounder 등).
우리가 주어진 observational data를 그대로 model에 넣고 interventional effect를 estimate하는 foundation model을 만든다고 생각한다면,
기본적인 assumption이 violate되었을 때의 uncertainty를 정량화해서 보여줘야 한다고 생각한다.
그걸 구체적으로 정량화하는 방법과 결과가 궁금하다.
3. DoPFN에서 실험을 할 때 baseline이 다소 빈약하다고 느껴졌다. doubly robust도 등장하지 않았고, 그 많은 learner 들 중에 아주 기본적인 learner만 등장했다.더 강력한 baseline과의 비교가 궁금했다.(appendix에 좀더 상세한 experiment result가 나와있다)(물론 이런 baseline은 task specific하게 tuning하긴 하지만 말이다)
이런 아쉬운 점들을 어떻게 개선할까? 뭔가 더 나아갈 여지가 없을까? 하는 궁금증에
아래의 논문 - CausalPFN을 보게 되었다.
Do-PFN과 동일한 목적 (PFN framework로 causal effect estimation)을 추구하지만,
앞서 내가 가진 궁금증들에 대한 힌트를 얻을 수 있지 않을까? 더 발전된 방법이 있지 않을까? 하는 생각에 읽게 되었다.
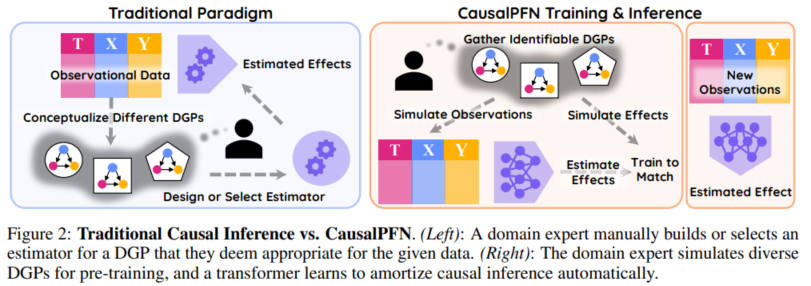
CausalPFN의 장점은,
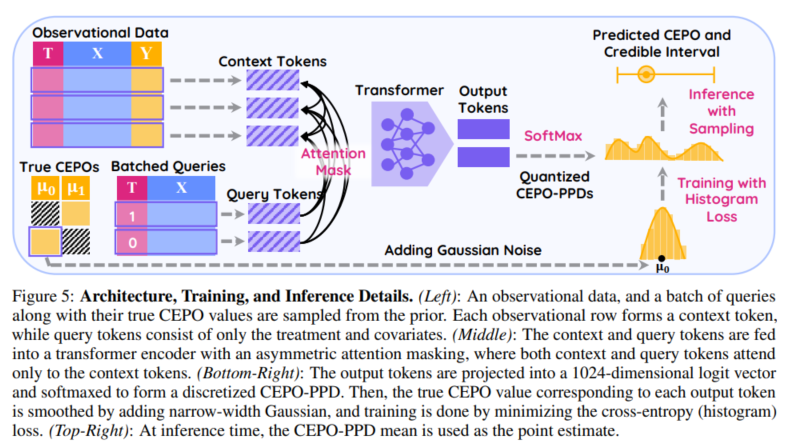
1. 가장 큰 장점은 Problem setting이 훨씬 수학적으로 엄밀하다.(훨씬 엄밀하다는 말은 취소. Do-PFN Appendix를 보니, mathematical framework가 상세히 나와있었다.)2. 또 다른 큰 장점은, 역시 Bayesian Causal inference 답게, credible interval을 구했다.
estimate의 uncertainty를 반영해서 정량적으로 보여준다.
그리고 uncertainty가 잘 calibrate되어있는지 평가한다!
추가적으로 calibrate하는 방법도 제시했다!
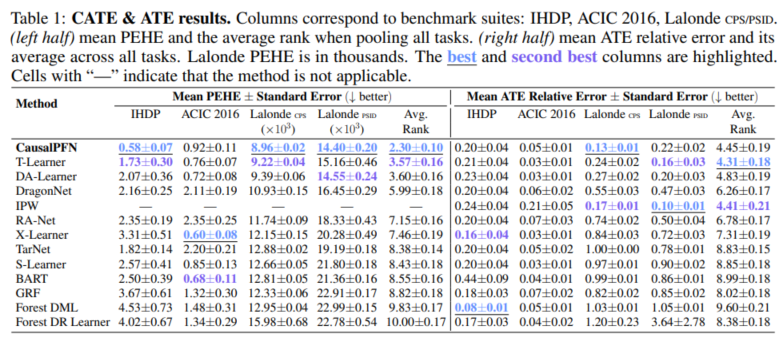
3. 다양한 실험과 다양한 baseline을 보여준다.
아쉬운 점이 있다면,
1. prior를 "assumption을 만족하는 하" (identifiable) 만으로 제한한다. ㅠㅠ (내가 느낀 가장 큰 단점!)
물론, 이건 본 논문에서 제시한 proposition에 기인한 prior design choice 때문이다.
identifiable한 경우에만, consistent estimator가 된다는 것을 보였다. 따라서 이를 충족하기 위해 이런 strong assumption을 강제했다.
사실 이건 장점인데, theoretically rigorous하기 때문이다. guarantee할 수 있는 범위 내에서 보여준거니까..
하지만.. 현실에서는..
assumption이 violate되는 상황까지 고려해서, empirically 어디까지 confidence를 가지고, estimate할 수 있는지, 보여줬음 좋겠다..
2. Prior-generation process가 잘 이해가 되지 않는다.
앞선 PFN series에서는 SCM prior로 prior dataset을 generate했는데, 이 과정은 단순명확해서 쉽게 이해가 되었다. '다양한 SCM, DAG structure를 generate해서 prior dataset을 scaling, diversify할 수 있겠구나' 하는 직관적인 생각이 들었는데,
본 논문에서는 tabular dataset (table)을 가져와서 prior를 generate한다.
이 경우에는 strong ignorability assumption을 쉽게 만족할 수 있다. 그런데, 이렇게 prior를 정의하는 방식이 합당한건가용..? 아직 낯설다.
이게 맞나요..? 물어보고 싶다 ㅠㅠ
data generating mechanism 없이, 그냥 table에서 covariate, potential outcome을 assign하는 방식도 괜찮은 건가요..?

물론 이 경우에도 tabular dataset은 이미 앞선 tabular foundation model들이, dataset을 diverse하고 large-scale로 synthesize할 수 있도록 하였기 때문에, 쉽게 prior space를 enrich 할 수 있긴 하다.
(사실 이 방법이 더 쉬워 보이기도 한다. 다만 이해가 잘 안가서 그렇지.. ㅋㅋ)
3. calibration 측정과 calibration을 개선하는 방법이 본 논문의 중요한 장점으로 여겨지는데, 내가 잘 이해하지 못했다 ㅋㅋ ㅠㅠ 천천히 다시 봐야지.





















'Causality > paper' 카테고리의 다른 글
[TimePFN] MTS Forecasting with Synthetic Data (0) 2026.01.17 [CausalFM] Foundation Models for Causal Inference via PFNs (0) 2026.01.14 [DAG-GFlowNet] Bayesian Structure Learning with Generative Flow Networks (0) 2025.12.25 A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms (0) 2025.12.24 [DiBS] Differentiable Bayesian Structure Learning (0) 2025.12.22