-
Fine-tuning & Instruction TuningResearch/NLP_CMU 2024. 7. 6. 07:50
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=KLJ3EEo8aPU&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=8
https://phontron.com/class/anlp2024/assets/slides/anlp-08-instructiontuning.pdf

You have some shared parameters between the models that are trained on all tasks. If you're just training a big language model then you'll probably be sharing all of the parameters. If you're training something like BERT, you're pre-training and then fine-tuning. You might train the body the model on multiple tasks but have a separate classification for different tasks. So there's different ways you can do that but the basic idea is that you need to have lots of shared parameters.
One easy way to do this is to train the model and sample one minibatch for one task, another minibatch for another task and just alternate between them and sample for from one task and from another tasks, or you can just mix all of the data together, if you're doing like text, everything is text based, then you don't even need to worry about minibatches.
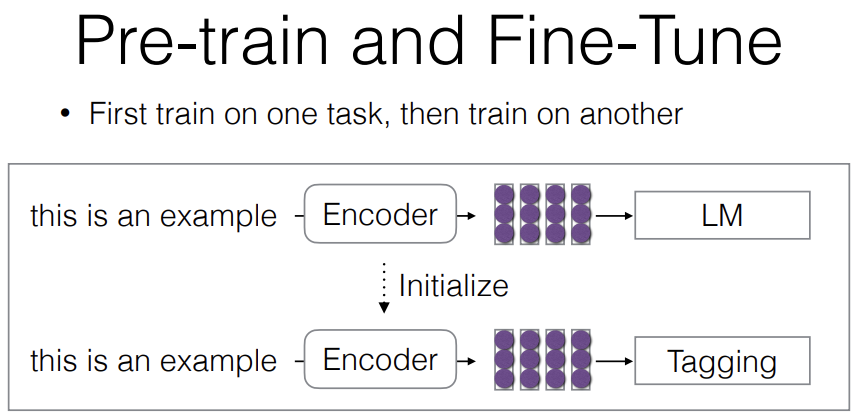
Separately from this, pre-train and fine-tune. You first train on one task and then on another. The way this works is you first train for example language modeling objective and then after you're done training the language modeling objective, you train on something else like tagging.
There're several reasons why you might want to do this. Why you might want to do this as opposed to something like standard multitask learning where you do both of them at the same time?
How many of you have trained a 70 billion parameter language model from scratch? Why not? It's unbelievably expensive and a waste of resources. So if everybody was doing it, it would be a waste of resources, so we actually benefit a lot by a very small number of people doing this free training and then the rest of us doing fine tuning on a smaller amout of data. So if you were doing all the multitasking from scratch, then that could be a waste.
Another reason why you might not want to do this is, for example, if your pre-training data is big and messy like for example, all of the internet and all the internet contains lots of toxic text and text that's in a format that you don't want, you can still train on it and learn from it but then fine-tuning can make your model safer or remove tox.
※ Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative (Lucio et al.)

This is a paper that we wrote previously and basically one interesting thing is that you actually do better if you train on multiple tasks at the same time. And our hypothesis about why the reason you do better on the end task that you finally want to do well on compared to pre-training & fine-tuning which I've also seen a few other works is, if you pre-train on the task that you finally want to solve while you're also solving the language modeling task, essentially the model is learning representations that are useful for both at the same time as opposed to if you're training on the language modeling task, it will be learning representations that are useful for the language modeling task but not necessarily focusing on the representations that would be useful for the end.
So for example, if you're joining training on sentiment analysis and language modeling, the representations that are useful for sentiment analysis will be more salient than for the language modeling.
So that will be particularly a problem when you have a varied optimization landscape in multiple local optima and the language modeling might not get you into the global optimum that you want for the end task that you're solving.
※ Pretraining Language Models with Human Preferences
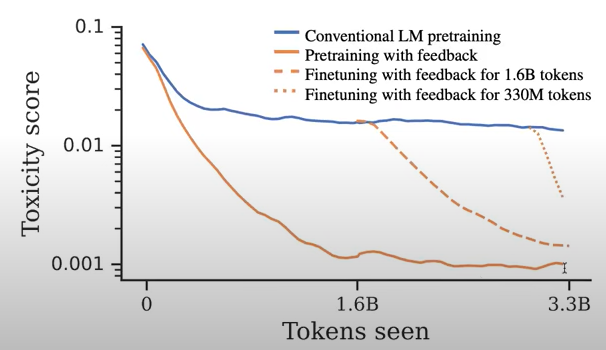
There's also another interesting paper from Anthropic more recently than ours that shows something a little bit similar specifically from the point of view of safety training. They demonstrate that if you start out by having a concept of safety early in your training, you're able to reach better final results than if you start safety training after you trained your model for a while.
So there are downsides to pre-training & fine-tuning. But the upsides of spending lots of compute once and then fine-tuning for lost of different downstream tasks is like large enough so that's still the standard.

When we're prompting, we have an encoder, we train it on language modeling or whatever else but then we freeze it and then we specify the task by a prefix.

Instruction Tuning is a combination of fine-tuning and prompting. You have a prompt for one task, a prompt for another task, and then you train your model specifically so that it does good completions of those prompts.

For full fine-tuning, what we do is we simply continue training the language model on whatever data we want to be fitting to, so this could be like translation pairs, it could be question answering pairs, it could be anything else like that. But the issue is depending on the method, that you're using to optimize your model, the method can take lots of memory and also in some cases, it can be relatively unstable compared to some other alternatives.
Just to give an example, training a 65 billion parameter model which is the largest version of Llama 1 with 16 bit mixed precision actually takes much more memory than you would expect. If you look at the amount of memory required for holding the model in the first place, if we have 65 billion parameters times two, that would be 130 gigabytes of memory already, so that's already a lot of memory, but if we want to hold both the parameters and the gradients of the model, we need to double the number of points here so we also have 130 GB for gradients.
Then we have the optimizer and this could be an optimizer like Adam, remember Adam has first moments and second moments so it has the mean and something that looks like the variance, and these at least according to this paper from 2019, needed to be stored in 32 bits of memory because if you stored them in smaller amounts of meomry, thery would have underflow issues, overflow issues and the numerical precision would destabilize your training.
And then in addition the parameters also needed to be measured in 32-bits so you need a 32-bit copy of the parameters. This is just the parameters of the model and then separately from that, you also need to do the forward and backward passes and so if you do the forward and backward passes depending on how big your batch size is how many tokens you have in each instance this could take significant amounts of memory to 100 to 200 gigabytes, so overall this would take around 1,000 to 1,400 gigabytes of GPU memory in the very naive scenario.
Now this paper was written in 2019 and there's have been some advances since then in optimizing models. So to give some examples of things that can be fixed, previously when we were using FP16, so regular ANSI floating point numbers like we use on our CPU, this was it you needed 32bit floats to make this stable, now it's pretty standard to use BF16, because of that, this can be made more stable, so you can reduce this to things like two bytes instead of four bytes. If we make do that we don't need this extra copy of the parameters so we can get away with about eight bytes per parameter we want to optimize. But that's still a lot of memory.
Full fine-tuning is pretty memory intensive.


How can we overcome this, the first way we can overcome this is using things like multi-GPU training and one solution is just to throw more hardware at the models and distribute the models over multiple places and the canonical or the most well-known version of this that still many people use when they're pre-training or fine-tuning language models is something called DeepSpeed ZeRo.
The way DeepSpeed ZeRo works is it works by partitioning optimization over different devices and so there's different stages of DeepSpeed ZeRo.
The first one is this one right here and this says 2 + 2 + K where K is the size of the optimizer state so two bytes, two bytes plus all of the bytes required for this and the blue is the first two, the orange is the second two and the green is the third one and so basically the baseline you hold all of these on each GPU.
The second thing is you partition the optimizer state across different GPUs and because optimizer state is generally larger or a least as large as all of the others, this can reduce memory requirements significantly, so this went from 120 gigabytes for whatever model they were doing there to 31 gigabytes.
Stage two, this is partitioning the optimizer state and the gradients.

The other option that you can use is "don't tune all the parameters of the model but just some of them and this is really popular nowadays because this further improves your ability to train on many different data sets without huge GPUs or without many GPU devices.

Prefix Tuning is a bridge between parameter efficient tuning and prompting. So it tunes one prefix for each of the layers.

The way the adapter works is you have a standard large representation vector and you have a feed forward down projection that down projects to a very small number of nodes and then you have a nonlinearity and then you have a feed forward up projection that projects it back to the standard space.
This is included within the residual layer and so ideally this will project down from 512 to something like 16 and then back up to 512.
So you would have 16 times less aprameters for the adapters than you would have for the full matrix. So by making these matrices or these vectors very skinny, this allows us to minimize the additional apramters.
There's two advantages to parameter efficient tuing methods, the first one is that they reduce memory for the parameters you're training.
Also, becuase there's fewer parameters, it's harder to overfit, so if you have very small training data, full fine tuning can overfit and become unstable, but because this has fewer parameters, its essentially is less easy to overfit and will generalize better often.

The basic idea is to learn an adapter for various tasks and combine them together. So instead of having just your adapter layer, you have adapters and then you have adapter fusion up here. The basic idea is adapter fusion is "attention over adapters". So you can decide which adapter to use in which case and each of the adapters is trained separately on task specific data.
So you have data from lots of question answering data sets and you train a question answering adapter, you have data from translation data sets, you train a translation adapter, then when you use them, you do attention over which adapter to use and then take the value from that adapter.
It allows you to train modules that are useful for a particular task and then decide which one to use at any particular point.
This is kind of a mixture of experts model.

The way LoRA works is very similar conceptually to adapters, but it has an important implementation difference. The difference is that in contrast to adapters, which had a nonlinear layer, here LoRA has no nonlinear layer, so what it is doing is it taking downscale matrix and upscale matrix and just doing a linear transformation with them.
So in this figure which I took from the LoRA paper, it's showing them as like separate computation paths. You use a normal matrix and then you use the LoRA matrix separately but actually you can just add them together and you get the equivalent result. So you add this matrix times this matrix into the pre-trained weights and that gives you the same result as if you calculated them separately and then added them afterwards.
So why is LoRA so popular because it's super convenient. After you finished training with LoRA, you can just add that the learned matrices back into the original weight matrix and you have a model that's exactly the same shape it doesn't have any other components you don't need any different code path you just have updated parameters and that contrasts to adapters.
Because in adapters, you need to add extra model components you have to have different code to implement this. So I think that's the big reason why LoRA is so popular. It's pretty simple.

Q-LORA combines together quantization with parameter efficient tuning. There are ways to compress the model down to not be in 16 bits but be in 4 bits. So if each parameter of 4 bits that makes the model very compact, it fits on a lots of hardware, so you could run it on a local machine.
The idea is we can press down the model to be much smaller, so the parameters are small and then we have a very compact LORA layer which doen't take very much memory itself, that allows use to train a model on commodity hardware . It also has like paging to page things from CPU to GPU memory to make it even more efficient.
Definitely if you want to train a large model on limited hardware, I'd recommend this, if you're not training a super large model like 65 gigabytes, I think just LORA should be fine.

This is very simple. You basically just train the biases of the model for any model that has biases. This also can fit models. It's very simple because you don't even need to add any extra code, you just need to freeze all the parameters except the biases, so from that point of view, it's very easy.
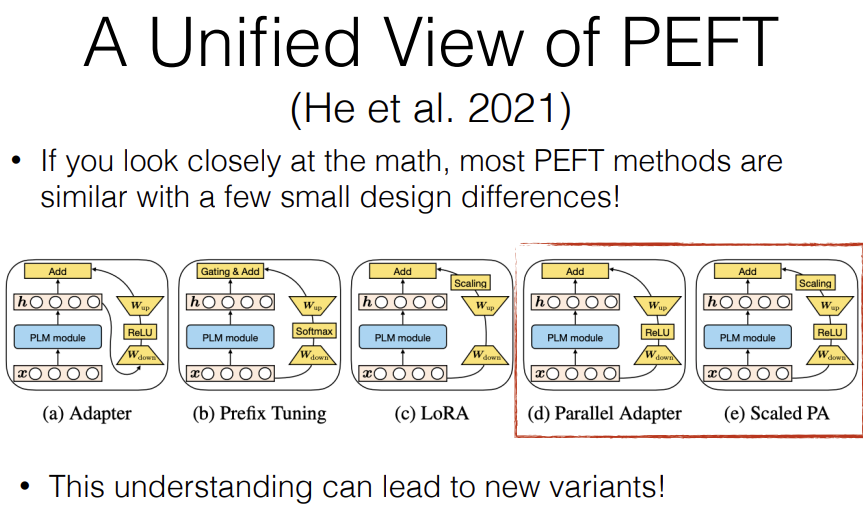
※ Towards a Unified View of Parameter-efficient Transfer Learning
We had a paper where we looked at all of these tuning methods and we decomposed them into several different design components.
What we can find is that things like adapters, LORA and prefix-tuning are very similar to each other but the difference being where do you get the original representation that you're feeding in.
So adapters generally get it from after the module that you're adapting, prefix tuing gets if from before, LORA also gets it from before. Also what's nonlinearity. It's a RELU, a softmax or nothing.
There's also a scalar scaling factor here. Which is a hyperparameter, so that's something to be aware of. So by breaking these down, you can better understand each of modules and how they or each of the methods interact with each other. And also what we show in this paper is that this understanding can lead you to new variants that can be more effective than any of the existing variants.
So we proposed two things called the parallel adapter and the scaled parallel adapter. And we demonstrate that they get better results.


The reason why I'm going to go through some NLP tasks is because when we're fine-tuning, we need to be fine-tuning towards individual tasks we want to solve.
So basic fine-tuning, we build a model that's good at performing a single task. Instruction tuning, we build a generalist model that is good at many tasks.
What I want to go through now is I want to go through some tasks that I've seen people use. Number one being really important, actual applications of NLP models in industry. Number two, what is the set of tasks that people use to evaluate generalist models so like if you look at the GPT papers or you look at the Gemini paper, what is the set of tasks they're using to demonstrate that their models work well.


So the first one is "context-free question answering", also called "open-book QA". This requires answering a question without any specific grounding into documents. It's also what happens when chatGPT answers your questions without looking something up on the web, for example. An example data set that lots of people use is something called "MMLU", this is a "massively multitask language understanding" data set and it has questions in a number of relatively difficult areas like professional law.
The next thing is "contextual question answering", and this is question answering grounded in actual context. One example data set that a lot of people use is something called "natural questions" and this is questions grounded in a Wikipedia document or the Wikipedia document collection. So grounded in Wikipedia document means they give you the actual document, you should be answering the question about and then you need to answer the question about it. This is often called "machine reading" because you expect it to like read and answer questions about the document. Or it could be okay we're going to give you all of Wikipedia, please provide us the answer to this question.
This is often called "retrieval based question answering" or "retrieval augmented", one variety of "retrieval augmented generation" or "RAG". So this is really important, I think, most many people that I talked to who want to build actual systems from language models or NLP systems are trying to do this sort of thing.

The second most popular thing that I talked to people who are trying to build NLP systems of some variety is "code generation." This is generating code like Python, SQL from a natural language command. The most popular data set for this is something called "HumanEval" and it has questions about how you do things with the Python standard library like return a list with elements incremented by one. It gives you the text and several examples of what the inputs and outputs should be and you're supposed to return a program like this. And this is a simpler version of this, there's also more complex ones.
One thing I should note this is an area that I do a lot of research in. HumalEval is a very simple example of this, it doen't use any external library, it doesn't use context and other stuff like that. There's a lot of other more interesting data sets also. So if you're working on code generation, I can recommend those as well.

Summarization, there's a couple varieties of this. One is single document summarization, another is multi-document summarization. Single document compresses a longer document to a shorter one, multi-document compresses multiple documents into one.
Honestly right now, single document summarization in English works pretty well out of the box. It's not perfect but it's close enough to being perfect. Multi-document summarization is definitely not solved.
Multi-document summarization is when you have lots of documents about a particular topic and you want to summarize them down into a coherent summary of that topic. One example of that is"WikiSum". This is a data set where you're provided with all of the links to pages about a Wikipedia article and you're expected to generate the first paragraph or few paragraphs of the article.
So you're expected to take lots of noisy incoherent articles about Barack Obama and write about Barack Obama something like this.

Another class of tasks is "information extraction." There's lots of examples of this, but basically they all boil down to extracting some sort of information in structured format from text.
This is things like "Entity recognition" identifying which words are entities, "Entity linking" linking entities to a knowledge base, "Entity co-reference" finding which entities in an input correspond to each other, "Event recognition/linking/co-reference."
An example data set is something called "OntoNotes" it's an older data set but it has all these things annotated and you can extract things from this. There's lots of other data sets for this too.

For both translation and summarization, evaluation is tricky. Basically you assess quality based on similarity to some reference using things like BLEU score.
An example of this is something called the FLORES data set.

Separately from this, there are general purpose Benchmarks. These benchmarks are not really for the purpose of evaluating any specific task that people think is actually useful, but rather trying to test the language abilities of language models themselves.
A typical example of this is BIGBench and this contains a whole bunch of tasks that test different abilities.
When you look at how language models are being evaluated, they're being evaluated against like many of these tasks not all of them necessarily but many of them. I think Gemini evaluated with respect to every all of these task categories except information extraction. So these are typical task categories that people look at.

Basic Instruction Tuning was proposed almost simultaneously by people at Google and people at HuggingFace. The way it works is, you have tasks and you train on lots of tasks where you append the prompt and you append the input and then you just try to train to generate the output.
This contrast from base language model training, because you're still training a language model based on a prompt and an output but you're specifically formatting them in a particular way so it corresponds to solving tasks. It's essentially supervised training over many many tasks, fine-tuning on many many tasks.
The interesting thing that these papers showed was that basically if you do this instruction tuning, you do well not only on the tasks that you trained on but also on new tasks that you didn't train on. This is really important it's incorporated in every serious language model that's used in a kind of like production setting nowadays.

In-context learning, instead of giving just a prompt, you give training examples in the context.
That's what you do in this paper here as well. You sample a whole bunch of training examples you append them to the context and then you train the model. Why is this good? this is good because it will train a model that's better in context learning basically. So if you want to provide these training examples then you can train it like that.

So these are the two basic ways of doing instruction tuning, all came out around the same time. There are a bunch of data sets that people have compiled and if you want to do instruction tuning, you probably want to use one of these data sets. Because compiling together a bunch of data sets is just annoying, so I very highly recommend this paper FLAN Collection, because it gives a good summary, it has this really nice table that breaks them down based on what's the name of the data set, what is the size of the training data, what prompts do they use Zero-shot or Few-shot, how many tasks are there, and what detailed methods do they use. So you can take a look at this some very popular ones that lots of people use are things like the FLAN Collection from here also natural instructions is a very popular one that still people use a lot and self-instruct is a popular one.

These are examples of Instruction Tuned Models. I can recommend you use now in 2024, they're good bottles to use. FLAN-T5 is a very good model, especially it's a very good model for its size and it comes in various sizes from smaller models to those up to 11 billion parameters and it's an encoder-decoder model based on T5 that was trained on lots of data. My impression is that this is a model that's like consistently good at anything that's like a simple input-output style task not like a Chat-task, so if you just have input-output, you want to do like code generation, you want to do mayby not code generation, you want to do like summarization or other things like that, that's a good model to use.
Another one is LLaMa-2 Chat, was instruction tuned and tuned with human preferences but it is quite good at following instructions.
And then there's also Mixtral instruct, and these are both decoder only models. Mixtral instruct is a decoder only mixture of experts model. Mixtral instruct is smaller and quite strong, so I would recommend that you consider this maybe as a default if you want a decoder only model. And then a FLAN-T5 if you want a encoder-decoder model.

It's possible to automatically generate instruction tuning data sets. The first or typical example of this is "self-instruct." The way "self-instruct" works is, you have a bunch of seed tasks that have one instruction and one instance per task, you throw them into the task pool and then based on this, you do a prompting to try to generate new tasks.
And you identify what type of task it is and then based on the task, you generate inputs and outputs, and from these inputs and outputs, they do a little bit of minimal filtering to de-duplicate the data set and also remove things that require visual information and other stuff like that, and then, feed that back into the task pool.
So they start with 175 examples and then they expand this data set to be veery large to cover many many different tasks. So this is pretty influential.
One interesting thing that they showed here is that you can improve the model that was used to generate these itself. So they took this and they used it to fine-tune GPT3. They used GPT3 to generate the tasks and they use it to fine-tuning.
Some other more recent examples are tuning for "Chain-of-thought." So ORCA is a nice example of this, this is something where they generated explanations for why the model made a particular decision and then they use that to train models and improve their reasoning capabilities.
Another interesting example is, something called "Evol-Instruct." The idea here is they start out with a seed set of instructions from any data set that you want to be using. And they modify those instructions to make them ore complex.
So they say "okay, this is too easy, let's make this harder," and that makes it possible to improve the ability of models to solve complex problems.
So this is actually a really popular area overall nowadays.
'Research > NLP_CMU' 카테고리의 다른 글
Long-context Transformers (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Prompting (0) 2024.07.05 Generation Algorithms (0) 2024.07.05 Transformers (0) 2024.07.05