-
Prompting*NLP/NLP_CMU 2024. 7. 5. 16:05
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=T1YrTbTkUb4&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=7
https://phontron.com/class/anlp2024/assets/slides/anlp-07-prompting.pdf


Prompting is a new paradigm as of a few years ago with interacting with models. It's now kind of the standard in doing so and basically what we do is we encourage a pre-trained model to make predictions by providing a textual prompt specifying the task to be done. This is how you always interact with chatGPT or anything else like this.
The way that basic prompting works is you append a textual string to the beginning of the output and you complete it and how you complete it can be based on any of the generation methods, beam search, it can be sampling, it can be MBR or self-consistency or whatever else.
One thing I should note is when I generated these, I used like actual regular ancestral sampling so I set the temperature to one, I didn't do top feed, didn;t do top K or anything like this, so this is a raw view of what the language model thinks is like actually a reasonable answer. If I modified the code to use a different output, we can see the different result. So I will set top K to 50, top P to 0.95, I changed the generation parameters and I'll run all of them you can see the result. So this is the standard method for prompting, I intentionally use GPT2 small and GPT2 XL here because these are raw based language models they were just pre-trained as language models and so when we prompt them, we're getting a language model that was just trained on lots of texts view of what is likely next text.
There are other ways to train language models like instruction tuning and RLHF, if that's the case you might get a different response.


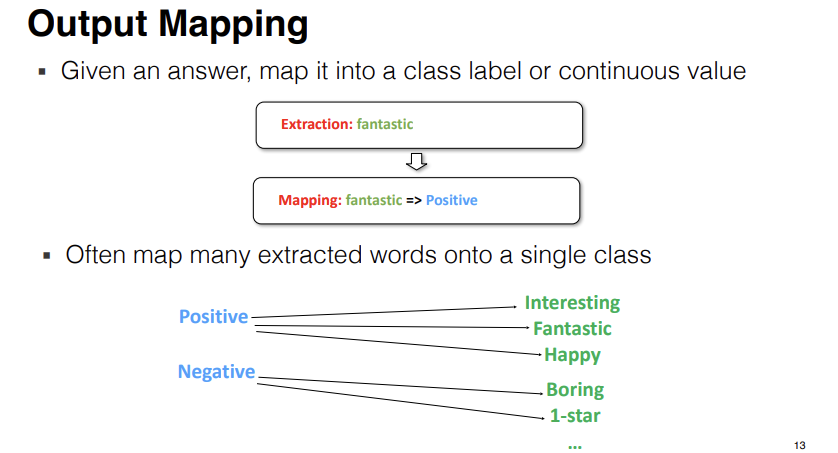
We tend to use prompting to try to solve problems also so it's not just to complete text although completing text is useful and important. Very often we'll use prompting to do things other than just completing texts and when we do this, this is kind of the standard workflow for how we solve NLP tasks with prompting. The way we do this is, we fill in a prompt templete, predict the answer and post-process the answer in some way.









There's a paper by Lu et al. and they examine the sensitivity to example ordering so like if you take the same examples and you just order them in different orders, you can get very wildly different results and this is especially true for smaller models like the GPT2.
Other things that people have looked at are label balance. So how important is it for the labels to be balanced and if you're doing sentiment classification for example, you might have only positive examples or only negative examples and if you have only positive or negative examples, this can help or hurt your accuracy for example on this Amazon review data set, most of the reviews are positive so you actually do better by having lots of positive examples in your in context examples, on the other hand for SST-2, this is label balanced so having only positive or negative is worse on average than having three positive and one negative.
Another thing is label coverage. So if we're talking about multi class classification, having good coverage of all of the classes that you want to include in your multiclass classification is important to some extent but if you have more you can also confuse some model especially if they're minority labels so if you have a whole bunch of random minority labels and that can cause problem.

This paper is a really nice paper examining why in-context learning works. One interesting finding that they have is they take in-context examples but they randomize the labels they make the labels wrong some of the time. So even with completely wrong labels, even with labels that are correct 0% of the time, you still get much better accuracy than if you use no in-context examples.
And why is this probably, it's getting the model formatting correct it's getting like the names of the labels correct even if it's not accurate so it seems like it's not really using these for training data it's using them more just to know the formatting appropriate.
The second thing is more demonstrations can sometimes hurt accuracy. So this is like binary classification versus multiple choice question answering and actually with binary classification, the model ends up getting worse with more examples. Probably just because the longer context confuses the model or moves the instructions that are provided to the model farther away in the context so it starts forgetting them.
So what I want to say is this is more of an art than a science you might not get entirely predictable results.


What Chain-of-thought prompting does is instead of just giving the answer, it gives you an additional reasoning chain, and so then when you feed this in, the model will generate a similar reasoning chain and then it's more likely to get the answer correct.
And this very robustly works for many different problems where a reasoning chain is necessary. And if you think about the reason why this works, there's two reasons. First reason is it allows the model to decompose harder problems into simpler problems and simpler problems are easier, so instead of immediately trying to solve the whole problem in a single go, it is solving simpler sub problems compared to harder ones.
Another reason why is it allows for adaptive computation time. If you think about a Transformer model, a Transformer model has fixed computation time for predicting each token. Based on fixed number of layers, it passes all the information through and makes a prediction. And some problems are harder than others, so it would be very wasteful to have a really big Transformer that could solve really complex math problems in the same amount of time it takes to predict that the next word is dog after the word the big like that.
So there are some things that are easy we can do in a second, there are some things that take us more time and essentially this chain of thought reasoning is doing that it's giving it more time to solve the harder problems.

The question was what happens if we just ask reason and the anwer is it still works. They contrast few shot Chain of thought where you provide chain of thought examples and zero shot chain of thought. So what they do is they just add "let's think step by step" that they add that phrase to the end of the prompt and then that elicits the model to do chain of thought reasoning without any further examples of how that chain of thought reasoning works.
Why does this work? Because on the internet there's a bunch of examples of math problem solving data sets or QA corpora where it says let things step by step and after that consistently have this sort of reasoning chain added there.



Number one, make sure you're using the canonical prompt formatting for the model for sure. Number two, you might want to do a little bit of additional search to see if you can do even better than that.

THis is method that paraphrase an existing prompt to get other candidates. It's rather simple, you take a prompt you put it through a paraphrasing model and it will give you new prompts. This is good because it will tend to give you things that are natural language. You can paraphrase 50 times, try all of them see which one gives you the highest accuracy and then use that one.

The way this works is, you need to have a model that you can calculate gradients for.
And what you do is, you create a seed prompt and then you calculate gradients into that seed prompt. So you treat each of the tokens here like T1, T2, T3, T4, T5 as their own embeddings, you do back prop into those embeddings, and you optimize them to get high accuracy on your dataset. Then after you're done optimizing them to get high accuracy on your dataset, you clamp them onto the nearest neighbor embedding that you already have.



'*NLP > NLP_CMU' 카테고리의 다른 글
Long-context Transformers (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Fine-tuning & Instruction Tuning (0) 2024.07.06 Generation Algorithms (0) 2024.07.05 Transformers (0) 2024.07.05