-
Retrieval & RAG*NLP/NLP_CMU 2024. 7. 6. 16:02
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=WQYi-1mvGDM&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=10
https://phontron.com/class/anlp2024/assets/slides/anlp-10-rag.pdf

If we look at our standard prompting templete with an input, we could get a response from a language model, but there are several problems with this.

The first is accuracy issues, the models generally have a "knowledge cutoffs", so the parameters are usually only updated to a particular time, so for example, if a new Vin Diesel TV series comes out, then the model that was trained up to a certain time point won't be able to know anything about it.
There's also issues of private data, so data stored in private text or data repositories is not suitable for training for a number of reasons. Number one, it's not available to particular language model training providers such as OpenAI or Google or anybody else like this. The second thing is access control issues. So even if you're within an organization that has lots of private data and you can train a language model on that, certain people in the organization may have access to certain varieties of data and other people may not. So it's not just solely an issue of third party providers. It's an issue of organization level access control in general.
In addition, there are learning failures. So even for data that the model was trained on, it might not be sufficient to get the right answer and this is particularly the case for very very large training data sets and models that are modestly sized. Because the models very often won't be able to learn from a single look at a particular fact or whatever else like this, especially if early in training.
Another thing is even if the answer is correct, it might not be verifiable. So you might want to be very sure that the model is not making any accuracy problems and so in order to do that, very often a human will want to go back to the source of the data.

So to solve this, there's a method called Retrieval-augmented Generation and the way it works is you retrieve relevant passages efficiently, ones that kind of entail the answer to a question, and then read the passages to answer the query.
So we have documents, we have a query, based on the query, we form retrieval. We get a whole bunch of passages, we do reading and then we get the answer.

THis is in fact implemented in many or even most language modeling providers including OpenAI. So to give an example, I asked the question and ChatGPT gave me an answer, and you can see that ChatGPT's answer includes several places with quotes. If you click on the quote, it tells you where the information source came from.
If we look closer into this answer, we'll see that it's not perfect even though it is performing retrieval augmented generations. For example, I only asked about TV series, but it's giving me lots of things about movies.

Black-box retrieval is just asking a blackbox search engine to retrieve the relevant context and getting the top several results. Nonetheless, this is a pretty reasonable method to do it if you want to do search over lots of data that exists on the internet already And that is what ChatGPT does it looks up on Bing by generating a query.

The first one is sparse retrieval and the way this works is you express the query and document as a sparse word frequency vector, usually normalized by length.
Based on this, we find the document similarity with the highest inner prpoduct or cosine similarity in the document collection. So if we take the inner product between these vectors, we actually see that the first one got the highest score because of its relatively high values for the words "what" and "is". So you can see common words can get a high score regardless of whether a document is very relavant and so one way we can fix this is through something called "Term Weighting."

The way "Term Weighting" works is in addition to having this vector that calculates the frequency within a particular document, we also have an upweighting term that gives higher weight to low frequency words.
Because low frequency words tend to be more informative about whether the document is relevant than high frequency words.

Now that we have this term based sparse vector, we would like to use this to look up relevant documents in a collection very quickly because we might have a collection that's extremely large as large as the entire internet like what Google is doing when it searches. So in order to solve this, we need a data structure that allows for efficient sparse lookup of vectors.
So we have all of these sparse vectors like this, and we turn this into a index where we have something like a python style dictionary or map that has it's key each word we would look up and is the vector the corresponding index of that document.
This is called an inverted index.
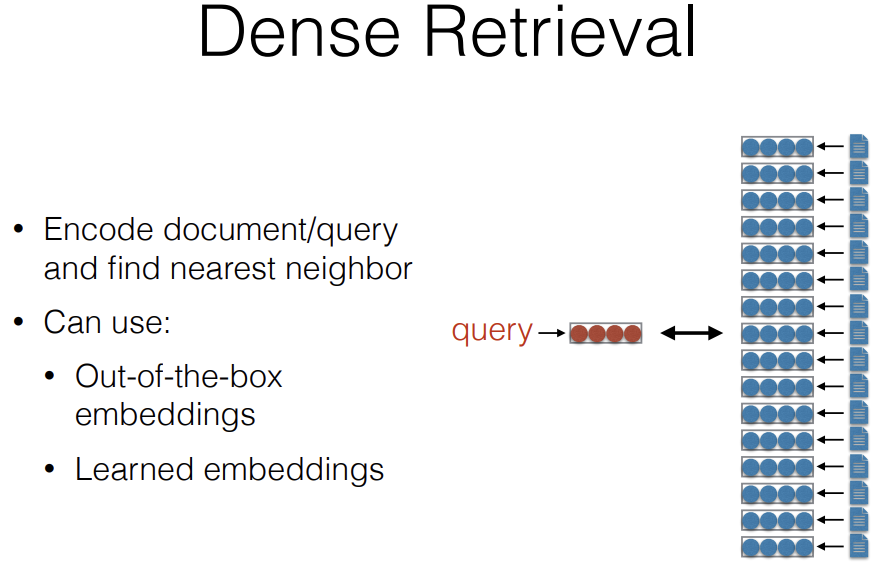
The way Dense Retrieval works is, you encode the document and query into a dense vector, and find the nearest neighbor. In order to do this encoding, you can use a number of things. You can use Out-of-the-box embedings or you can use Learned embeddings specifically created for the purpose of retrieving.
So what we do is we take all of these documents here, we convert them into embeddings using whatever embedding method that we want to use, we then have a query and we take that query and match it and find the nearest neighbor here.
So if you're just using Out-of-the-box embeddings, you don't need to do anything special for retrieval. You can just take your favorite embeddings like the sentenceBERT embeddings or the OpenAI embeddings or something like this.
But actually the type of embeddings you need for retrieval are very special and because of that, it's important to if you're very serious about doing a good job of retrieval, it's important to use embeddings that were specifically tailored for retrieval.
The reason why it is important to do this is severalfold, but the most intuitive way to think about it is if we think about the things that TF-IDF is giving a very high weight to contentful words and rare words and we're not guaranteed that any random embedding that we get is going to do that.
For example, if we just take the average word embeddings of every word in a sequence, it's going to give the same weight to all of the words in the output and in fact common words tend to have slightly higher Norms than infrequent words, so that would actually upweight common words which is exactly the opposite thing we want.

So how we learn Retrieval-oriented Embeddings? The normal way we do this is we select positive and negative documents and then train using a contrastive loss.
So an example of this is we have a query and then we have negative documents for that query and we have positive documents for that query and we formulate a hinge loss or some probabilistic loss similar to the hinge loss and do fine-tuning of the embeddings.
If you have gold standard positive documents, then this is relatively easy to train, because you just need the positive documents and then, you can get negative documents in a number of ways. One common way of getting negative documents is you just form a batch of data and given that batch of data, you take all of the other documents in the batch that are positive for some other query and you use those as negative documents. This is both effective and efficient because you can learn from the query document pairs all at the same time in an efficient implementation. However this is not enough in many cases because that will end up having lots of very obviously wrong documents because they're documents that are relevant for a completely different query and it's easy to distinguish between those you can just at superficial word overlap.
So another common thing to do when you're training these models is to get hard negatives. So hard negatives are negative examples that look plausible but are actually wrong. So here this famous method called DPR is it learns the encoders based on both inbatch negatives and hard negatives that were created by looking up documents with bm25. So the ones that were looked up by bm25 look very similar superficially but they might have subtle errors in them for why they're inappropriate.

We've talked about training these dense product models. These dense models look at dense embedding overlap for nearest neighbors but the problem is in order to calculate this, you would need to calculate it over a very large document base. And just taking a product between the query and all of the other documents in the document base is extremely costly. So in order to fix this, there are methods for approximate nearest neighbor search.
These are methods that allow you to retrieve embeddings that have the maximum inner product between them in sub-linear time and because you're doing the maximum inner product, this is also often called maximum inner product search or MIPS.
So I'm going to introduce on a very high level two common methods to do this. The first one is Locality sensitive hashing. This can also be called kind of inverted index as well. What you do is you make partitions in continuous space and then you use it like an inverted index. So let's say we have a whole bunch of embeddings. I demonstrated two dimensional embeddings here but in reality, this would be as large as your query and document embedding space, so this would be 512 or 1024. And what you do is you define a whole bunch of planes that separate these points into two spaces so if this is our first plane all the points above the plane will get a one for this partition and all the points below the plane will get a zero for this partition. And we do it similarly we create a whole bunch of them and then based on this, we can now assign sparse vectors depending on each of these planes. So based on this, now we have a sparse vector and we already know what to do with a sparse vector. We look it up in an inverted index just like we did for a sparse lookup table so that's one method.
Another method uses a graph-based search and the basic idea behind this is that we create hubs and these hubs are a small number of points that are close to other points in the space and so we create some hubs and then we search from there. So if we have a similar looking set of points in the space, we find these hubs which are something like cluster centroids and then based on the cluster centroids, we then rule down or we greatly reduce the number of points that we need to be looking at and then we search through only those points in a more extensive manner. You can even turn this into a tree where you have hubs and then you have kind of mini hubs and then you have all the points. So this allows you to do a tree-based or graph-based search.
There's lots of good libraries that help you do this, some libraries that people very commonly use I think, FAISS is a very widely used one and ChromaDB is a sepearte one. Both those are good options.

Even with intelligent training of dense embeddings, however there still are problems. The biggest problem that you face when you're looking at dense embeddings is that in order to form a good dense embedding, you need to know in advance what you're looking for. Because you're taking a long document, you are condensing it down into a single embedding, so during condensation process, there's other information that is relevant to a query but you have to throw out because of the limited embedding capacity. This causes you to essentially fail at doing retrieval approprately.
So there's a couple methods that can be used to fix this. The first method is in contrast to the Bi-encoder which is what I've been talking about at this point where you do full encoding of queries, full encoding of documents and then do inner product search for a score, you can use a Cross-encoder. The way the Cross-encoder works is you append the query and document and then you run them through a model like a Transformer model and you calculate the output score.
This is great because it gives you maximum flexibility Transformer models are powerful, you can assess relevance very well. The problem with this precludes approximate nearest neighbor lookup, because now you're running through many nonlinearities here. So this is can only be used for reranking documents or you're doing retrieval over a very very small number of documents. But if you really want maximal accuracy, I definitely would recommend doing something like this. Because it can allow you to do a second pass filtering over the most relevant looking documents to identify the ones you really want to add to your context.
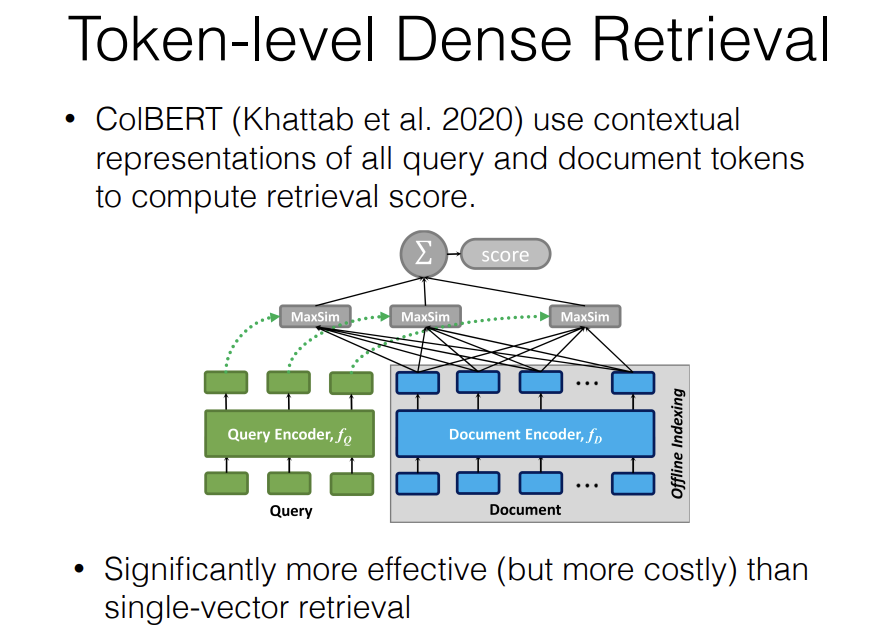
There are also approaches that are in the middle of these two. The most famous one is ColBERT. I call this "Token-level Dense Retrieval", it's also called "late interaction" in the ColBERT paper. The way it works is you use contextualized representations of all query and document tokens to compute a retrieval score.
So you do offline indexing of every token in the document and then based on this offline indexing of every token in the document, you then have a query encoder and you do matching between each token in the query and the highest scoring tokens in each document.
The reason why this is good is it still allows you to encode all of the tokens in the document and but each of these similarity searches is still just a kind of maximum product search and because of this, this allows you to do each of these searches efficiently and doesn't preclude you from running it over an entire database.
The downside to this method may already be obvious but in the traditional bi-encoder we have a single vector for each document but here we have one vector for each token in the document. So your vector database gets n times larger where n is the number of tokens in the document and there are certain methods to make this better like you can compress each document to a smaller number of n but still this is definitely going to be more costly than looking up each token. So this is definitely something to consider if you want to get very good scores and ColBERT is a good implementation of that to start with.
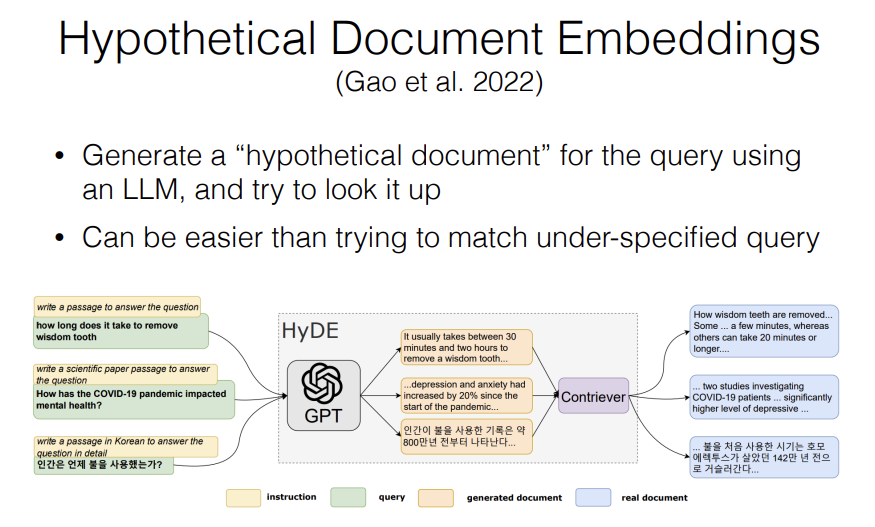
The idea behind a "Hypothetical Document Embeddings" is that its's actually somewhat difficult to match a query and a document. Because a query is a very short possibly ungrammatical output that's asking a question and then a document is a very long output that's written in a different style and, it might have lots of irrelevant information. So the idea behind a Hypothetical Document Embeddings is that it's easier to match a document in a document than it is to match a query in a document.
But the input to our model is a query. So what do we do? What we do is we then take a large language model, we feed it in a query in a prompt and say "generate a document that looks like it should be the answer to this query" and then the LLM goes in and it generates a document and hopefully this document looks more similar to the documents you want to retrieve than the original query does.
And I've actually found this to be relatively effective at improving accuracy on difficult tasks especially ones that are out of domain from the trend models that I'm using.
** ------------------------------------------------------------------------------------------------------------------- **
* I would like to finish up this section by giving some insight about which one you should be using. So my impression right now is that, a good baseline to start out with is, something like BM25. It's very easy to start out and compared to embedding based models, it tends to be relatively robust to new domains. So if you have a new domain, you're more less guaranteed that, BM25 will give you some performance whereas embeddings may be really good but they may be really bad depending on how out of domain that is compared to your underlying embedding model.
However, if you want to get the highest accuracy, definitely tuned models are going to be better. And if you're not worried about computation efficiency, using something like ColBERT, with kind of the token-level retireval will definitely give you good accuracy.
However, there's better support for Bi-encoder style models in kind of standard vector databases like FAISS and ChromaDB and other things like that, so if you want an easier method to get started very quickly, then using a bi-encoder is probably the best way to go.
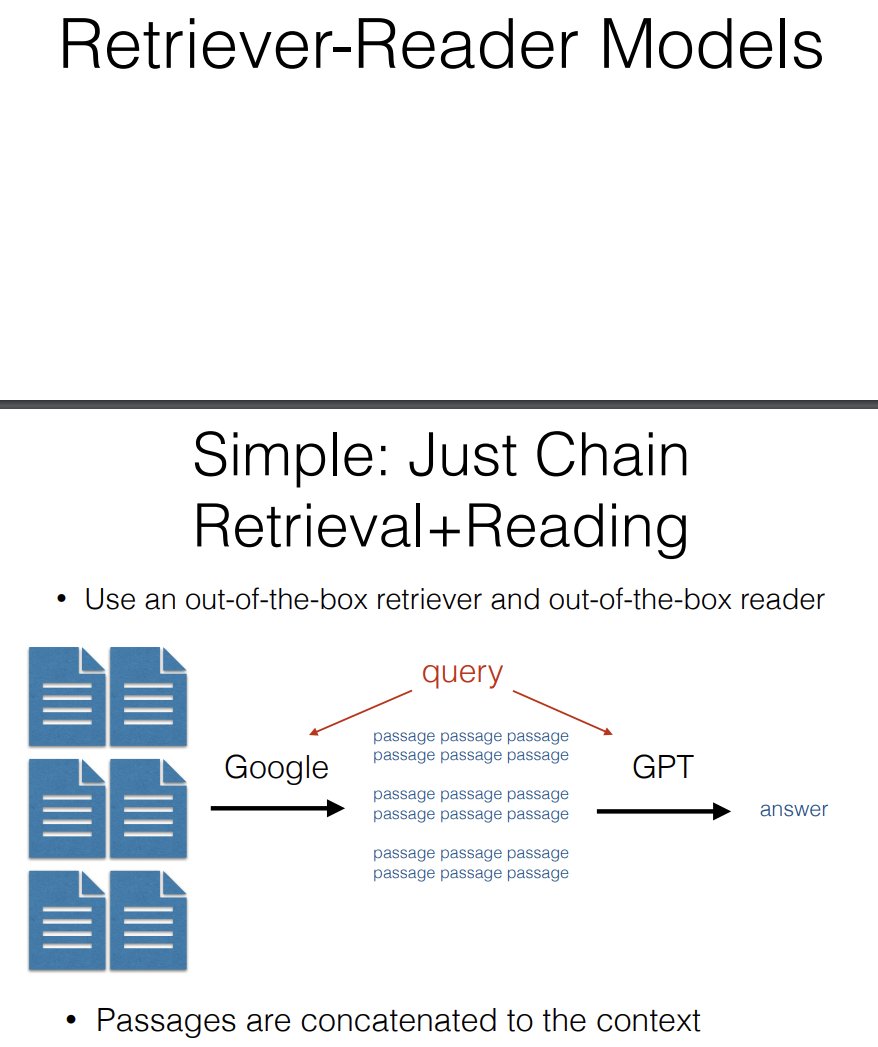
We have Retrieval-Reader models. The simplest way they can work is you just chain retrieval and reading together. So you use an out-of-the-box retriever and out-of-th-box reader model. You have your query, you could look something up on Google, get a whole bunch of passages and then feed them into a GPT model and get an answer. This overall is quite effective, it's easy to implement and it will give you decent results.

There are methods also for Retriever and Geenrator End-to-end training. So this is the paper where the name "RAG" came from. There are several methods that propose to train the Retriever and Reader to improve accuracy.
Specifically the RAG by Lewis et al., the way it trained the Reader was to maximize generation likelihood given a single retrieved document, and for the Retriever, it maximized overall likelihood by optimizing the mixture weight over documents.
So here's a schematic which is you have your query encoder, you run the Retriever with MIPS(maximum inner product search), it gives you several documents and each document has a score, and then based on the documents and the scores, you generate with each document in the context and then sum together the probabilities multiplied by the weights.

Generation is a mixture model. You pick a document and generate from the document. P_eta z given x is the probability of picking that document given the query x. And then this p_theta y given x, z, and all of the previous tokens is the probability of the next token given that particular document.
So this is linearly interpolating between the multiple documents. And this can be considered the Retriever and the Generator.
One important thing that enables end-to-end training is, they have this probability of the Retriever be based on embeddings and so we have the document embedding and the query embedding and the probability is proportional to the inner product of these exponentiated. So you're taking a Softmax over the inner product between the two.
And this adjusts the Retriever to give higher similarities to helpful documents.
So because the probability of the Retriever model is included in the end-to-end probability, you don't need any annotations about which documents are useful. You can just train all of this end-to-end and let backprop do its thing to update the Retriever as well.
One important issue when training models like this is that, the search index will become stale so what do I mean by this, it's fine to do lookup over big index but if you start updating this document embedding, you need to recreate the entire index and that would be very computationally costly.
So the solution to this proposed in this RAG paper by Lewis et al. is, we only train the query embeddings and we keep the document embedding fixed.
Another thing to think about is when do we do Retrieve? There's a bunch of different methods. The RAG paper that I mentioned before did this only one right at the very beginning of generation. It grabbed a single document and generated the entire output. This is the default method used by most systems.
However, there's other options as well. You can retrieve several times during generation as necessary and the way this works, we can do this either by generating a search token saying that "we should start searching" or searching when the model is uncertain.
And another way is to do this every token. So we can do this by finding similar final embeddings and using this to influence the probabilities or approximating attention with nearest neighbors.

"Triggering Retrieval with Token Embeddings" was proposed by Toolformer Schick et al. The way it works is you generate tokens that trigger retrieval or other tools. So in this particular method, it had several tools including asking a QA model or getting a calculator or having a machine translation system but with respect to retrieval augmented generation, it had this Wiki search functionality that would look up something in Wikipedia and then use that to influence the final probabilites.
The way this was trained is, training was done in an iterative manner where it generated examples of tools being useful and when the tools improve the probability of the following output, then that would be treated as a positive example and used to further train the model.
So this was really influential and in fact this is how things are implemented in ChatGPT nowadays, not only for doing retrieval but also doing other tools like for example, generating code or generating images or other thing like this.
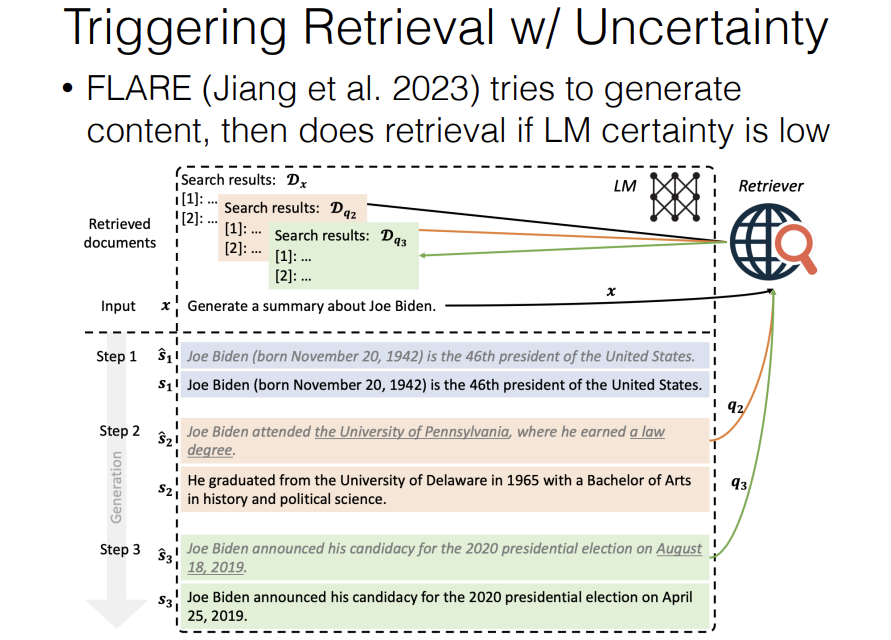
Another option is, to trigger retrieval with uncertainty estimates. So FLARE where we try to generate content and then do retrieval if the language model certainty is low.

The original or one of the methods that popularized this idea of token by token retrieval is something called KNN-LM and the way it works is it retrieves similar examples and then uses the following tokens from these examples. And this is like a very powerful count-based Bi-gram models. When we were talking about count-based bi-gram models, what we would do is we would take the previous token and we would calculate the probability of the next token by summing up together all of the next tokens and dividing by the total number of times that previous token occured and so given that background, we can talk about how the KNN-LM works.
So we have the text Context X and we want to generate a Target output. Separately from this, we have all of the training contexts, so this is all of the contexts that appeared in our training data, and we encode all of these training contexts specifically by calculating the representation of the final layer or near the final layer of the model, and so we encode that as representations. Separately from that, we remember the next word that appeared after this context.
So now we have a data store consisting of representations in next words. We then take the representation of the current context and we calculate the distance between the current context and all of the other similar context in the database. We take the nearest K, so we take the top K examples here which would be Hawaii, Illinois and Hawaii. We then do some normalization based on the distance and this gives us a probability distribution over all the next tokens.
Sometimes these tokens are duplicated multiple times and so we aggregate all of these counts to be Hawaii for example 0.8 and Illinois 0.2 and then we interpolate this with the probability given by the standard language model using an interpolation coefficient Lambda. This gives us our final probability.
The nice thing about this is, this allows us to explicitly ground our outputs in individual examples and it's pretty effective way to improve the probability of models, improve translation and other stuff like this.
The disadvantage of doing this is, that it adds an extra component of the model. It adds extra hyperparameters like Lambda. So it is a little bit finicky and it doesn't work in all situations.

....
'*NLP > NLP_CMU' 카테고리의 다른 글
Quantization, Pruning, Distillation (0) 2024.07.07 Long-context Transformers (0) 2024.07.07 Fine-tuning & Instruction Tuning (0) 2024.07.06 Prompting (0) 2024.07.05 Generation Algorithms (0) 2024.07.05