-
Long-context Transformers*NLP/NLP_CMU 2024. 7. 7. 11:34
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=WQYi-1mvGDM&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=10
https://phontron.com/class/anlp2024/assets/slides/anlp-10-rag.pdf

These are models that are explicitly trained in a way that allows you to attend to longer contexts in an efficient manner.
One way that we can train over longer context is just append all of the context together. In fact, shortly after Transformers came out, this paper by Voita et al. demonstrated that doing this can learn interesting document level phenomena. So it can identify when multiple words refer to the same thing or co-reference and other things like this.
However, the problem with Transformers is that computation is quadratic in the sentence length. Because you're multiplying all of the query vectors by all of the key vectors and that causes a big problem if your sequences become very long.

So if we go back to what we did in RNNs, they don't have this problem, because computation is linear in the length of the sequence. You just pass along the RNN state and every single time, you do the same computation over it. So there's no quadratic term in calculating RNNs.
Another thing is that when doing RNNs, you can pass state infinitely during the forward pass by just calculating the hidden state and then throwing away the rest of the computation graph that was used in calculating that hidden state and there's no approximation that goes on there.
However, there is a problem with doing backprop, because in order to do backprop, you maintain the entire state of the computation graph. So there's a common method to fix this is, you pass along the RNN state from the previous sentence but you just don't do backprop into the previous sentence. This is called "Truncated Backprop" or "Truncated Backpropagation Through Time." This allows you to train models with infinite context or at least models that can pass along context infinitely even if you're not backpropping.
A problem with this over long contexts is, recurrent models can be slow due to the sequential dependence, they're not ideal for running on GPUs and this is improved by recent architectures like Mamba and RWKV which are more conducive to GPU based training, while still maintaining linear time complexity.

If we take this idea of "Truncated Back Propagation Through Time", this can also be applied to Transformers. Transformer-XL attempts to fix vectors from the previous sentence. What we do in the standard Transformer is, each vector attends back to all the other vectors in the current context. What Transformer XL does instead is, when you have a new segment that you want to do backprop into, you have a new segment that you want to train over, you also attend to all of the previous tokens in the previous segment, but you don't do backprop into them. So this is Truncated Back Propagation Through Time from the Transformer perspective.
This is also really nice bacause, what it allows you to do is, if you have a multi-layer Transformer, it allows you to attend far back. So if you look at the last layer, it's attending to things in the previous context window, but the second to last layer is attending to things in not just one context window before, but multiple context windows before. And this allows you to very effectively attend a very long context because each time the context expands in an exponential manner.
So recently there's a popular model called Mistral, this is using sliding window attention which is the same mechanism proposed by Transformer-XL. So this method is still used in very practical systems.
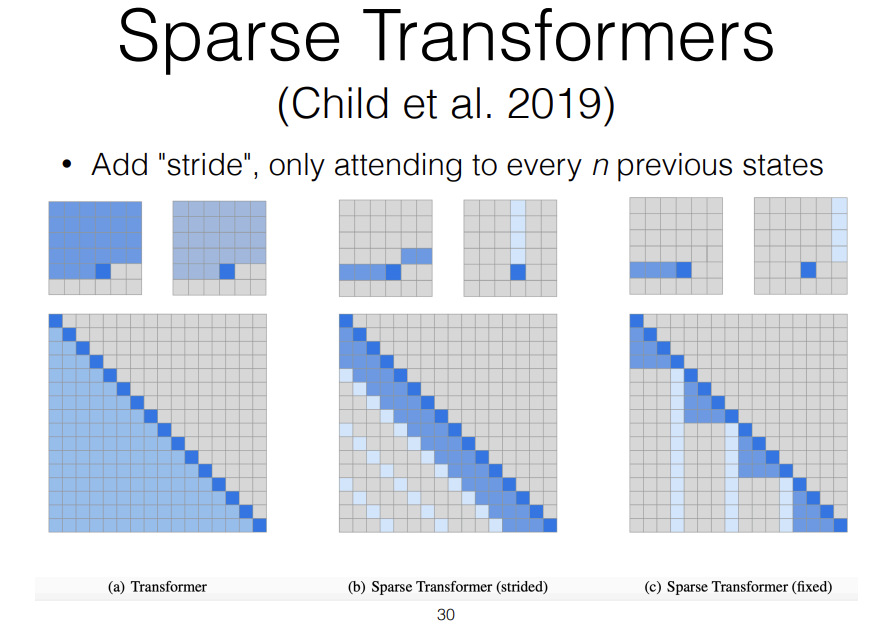
Another paper that has been pretty influential in this general area is something called "Sparse Transformers." The way Sparse Transformers work is, instead of attending to every single previous state, you attend to every n previous states. What this allows you to do is, this allows you to create something like the strided convolutions or pyramidal recurrent neural networks.
So what this looks like is, if you have a particular state, it might attend to all of the previous n tokens but then it also attends to all of the previous m chunks, so you kind of have a combination of local and longer range attention.
This can be veery effective because you can attend to much longer context with a minimal increase in a computational complexity.
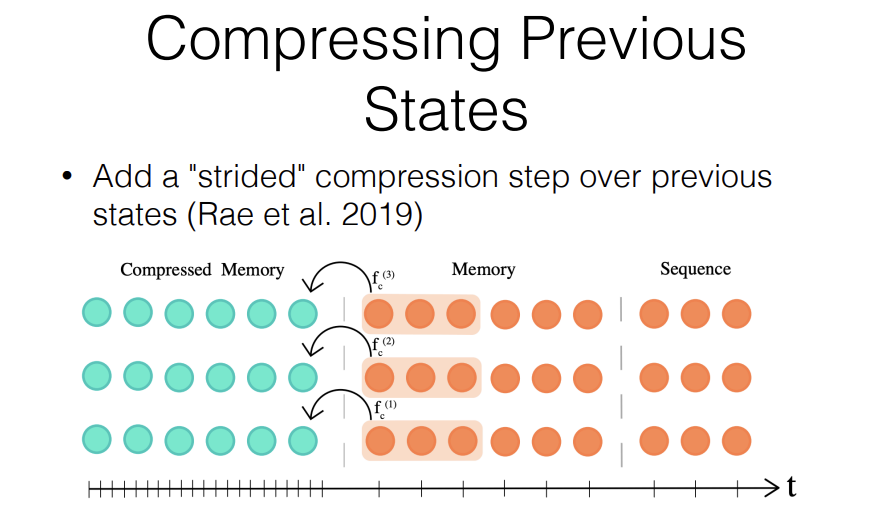
Another method that's very similar in sprit but slightly different in implementation is, something called the "Compressive Transformer." The Compressive Transformer, you also have this idea of a local memory and then a longer term compressed memory, but you have an explicit compression step that directly generates this Compressed Memory itself. So this is a little bit more flexible. It allows you to take all of the relevant things from your local memory and compress it down.

Finally, there are some very interesting methods that do Low-rank Approximation for Transformers. Calculating the attention matrix is expensive but because it's a matrix, we can also approximate it with a lower rank matrix.
There's a couple methods that do thing like this. The first one is something called "Linformer" which adds low rank linear projections into the model at appropriate places. And there's another one called "Nystromformer" which approximates using the Nystrom method which is based on sampling landmark points, but the general idea behind this is normally we do this kind of softmax over a very large attention vector but instead, we can approximate the softmax by having some low-rank vectors.
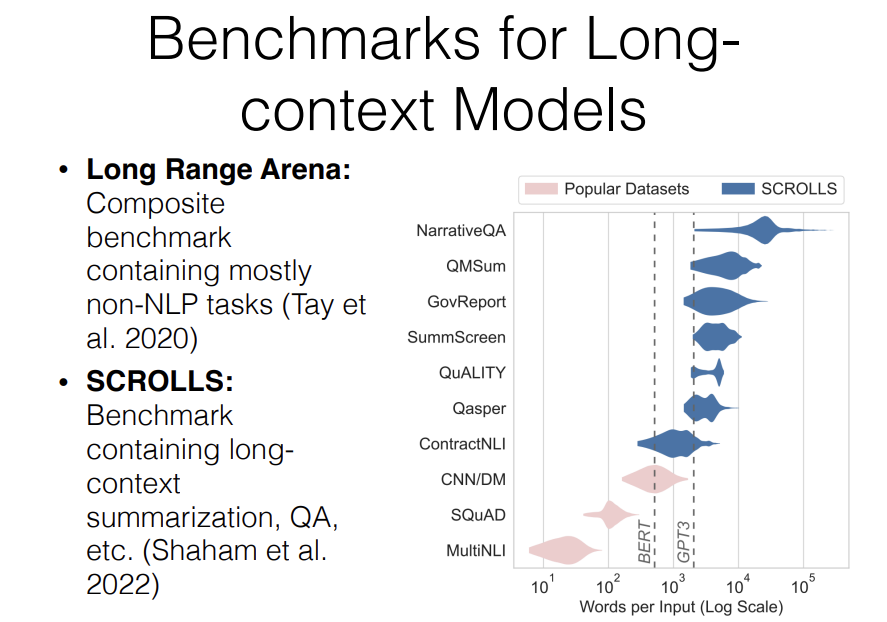
There's a vew benchmarks. One very well-known is something called "Long Range Arena." This is a composite Benchmark containing mostly non-NLP tasks and it's definitely used for long sequence modeling but the results on the Long Range Arena actually tend to diverge somewhat from the results that you get for long distance language modeling.
So in addition to this, another Benchmark that I personally like and have used a bit is something called "SCROLLS" which combines together a whole bunch of QA style or summarization style tasks that have very long contexts including over narratives or books or government reports or other things like that.
Now that we have Retriever models, we have Reader models, we maybe even have Reader models that can effectively use very long contexts like the ones that we retrieve over whole documents, how do we effectively use them in our models?
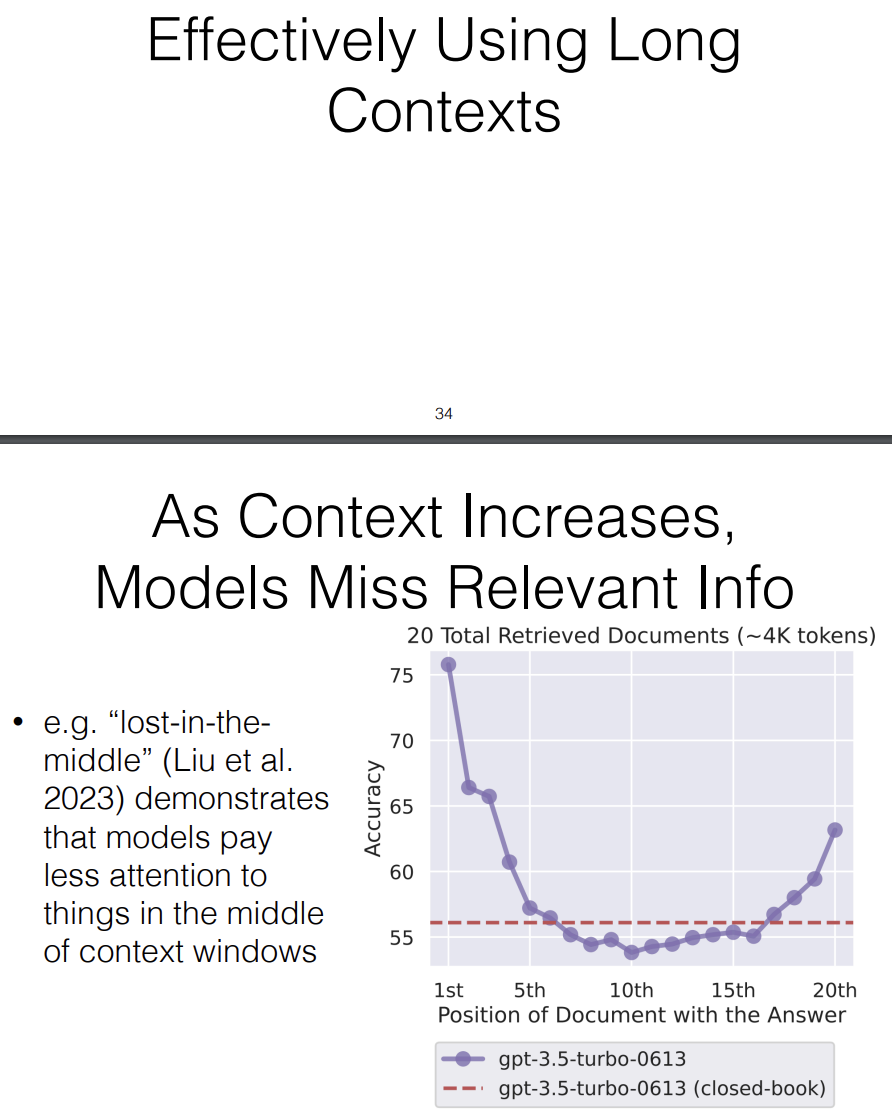
There's a nice paper by Nelson Liu at Stanford that about a phenomenon that "lost in the middle." It demonstrates that mnay different models including state-of-the-art models pay less attention to things in the middle of long context windows.
So if we have an answer and we put it in the first position in a concatenated context or the 20th position in a concatenated context, it tends to attend more to the ones at the beginning or the end in contrast the ones in the middle, kind of get lost, hence the name "lost in the middle."
And the problem with this is, if we are doing something like Retrieval or Reading, that's maybe not such a huge problem, because we could just put the highest scoring documents at the beginning that might even be more effective than concatenating lots of low scoring documents together, but if we want to read a really long document, and synthesize something without doing kind of another scoring step, that can be an issue.
And also our Retriever is not perfect. So we would like the Reader model to do a good job with the outputs that it has. So there are methods to ensure use of relevant context.
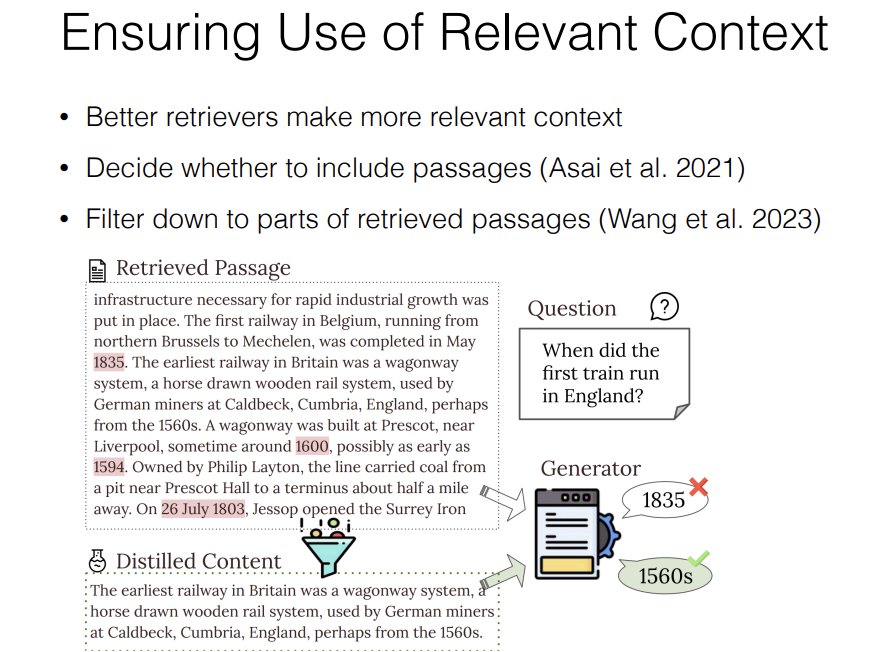
Of course better retrievers make more relevant context. You can do reranking or other things like that, and only include the context that looks most relevant, or refine your reader model.
But there's also methods that can decide whether context should be used in the first place. So there are methods to decide whether to include passages or not.
Recently we proposed a method to filter down to parts of retrieved passages to have only appropriate content and it filters the context down to the most relevant content that we think is appropriate and that allows us to get better results when it's fed to the generator.
'*NLP > NLP_CMU' 카테고리의 다른 글
Reinforcement Learning from Human Feedback (0) 2024.07.08 Quantization, Pruning, Distillation (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Fine-tuning & Instruction Tuning (0) 2024.07.06 Prompting (0) 2024.07.05