-
Quantization, Pruning, Distillation*NLP/NLP_CMU 2024. 7. 7. 13:25
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=s9yyH3RPhdM&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=11
https://phontron.com/class/anlp2024/assets/slides/anlp-11-distillation.pdf




NLP models now are really deployed at a large scale and training big model is expensive. But something that is overlooked is that inference, so once you have a trained model, now deploying it and making predictions for users is arguably even more expensive. If you look at the lifetime of a model, it probably exceeds the training costs according to this analysis within just one week of use and so if your model is being used for months or years of many people, the cost will greatly eclipse the training costs which is more of a onetime cost.
And this is a problem because if we want to make AI systems able to help lots of different people in different places, people without as much resources or access to power, we want to be able to reduce the cost of serving AI systems to the public. And this is also getting harder because models are getting bigger. There's been a slight shift towards reducing model size a little bit in the last two years but these models are still like billions of parameters in size and that is expensive to serve.
So the main question of this is "how can we cheaply, efficiently, and equitably deploy NLP systems without sacrificing performance and there's a clear answer here that "model compression."


Model compression means taking a trained model and then reducing the size of that model before deploying it and there's three high-level ways for how we can compress models.
The first is quantization which is you don't really change the architecture or parameters of the model up to a certain amount of precision and then you throw away the remainder of the precision. The second is pruning, throwing out entire components or parameters of a model, and the third is distillation where you might change all of the parameters but you're condensing the knowledge of a big model into a smaller model, that is, retraining often from scratch to replicate the behavior of the big model.

So I've motivated this idea of model compression which is very tempting, just take a model, make it smaller, get the same performance. And it's just cheaper to serve. Nothing about that seems bad, so there's a natural question of "why is this even possible?" And specifically, a natural question is, instead of taking a big model and making it smaller, "why not just start with a small model and train it as such?" That seems a little more intuitive.
So that's the first question is "why not just start with a small model that we train?" and then the second question would be "why is it possible to take a big model and throw piece of it away without sacrificing accuracy?" That does not seem like a given that should be even possible and I'll just give you a little intuition for why this is possible.
This term "Overparameterized" means, you have a model that has usually more parameters than you have training data or you just have a lot of parameters like way more than statistical machine learning would say you need. So for example, GPT3 model had 170 billion parameters which is definitely overparameterized and so there's been a lot of work shows that overparameterized models that have a huge number of parameters are actually much easier to train, especially for very complicated tasks.
And the basic idea is that training deep neural networks for most tasks requires optimizing a non-convex objective which is not guaranteed to find the global optimum of a non-convex objective, but when you have a bunch of parameters and you're trying to tune the parameters to find the best value of your objective, having a lot of parameters lets you side-step around saddle points or local optima that are not global optima. You can take shortcuts around barriers in the optimization space. This is the intuition.
The intuition here is that, models with a lot of parameters are easier to train and they lead to better models. But you probably don't need all those parameters for inference. They're more of a training time trick.

The most obvious way to do this is, Post-Training Quantization. So you train a model as big as you want and then you just reduce the precision of all of the weights in that model.
For example, if you have a 65 billion parameter model like LLaMa2 and you have 4 byte precision, so like 32 bit floats, just loading that model into memory would take 260 Gigabytes of GPU memory which is more than most single GPUs that you could have, but if you instead of reduce the precision of the parameters of the weights in that model, you see a pretty massive decrease which is linear to the reduction in precision. At the most extreme case, if you replace each float 32 with a single bit, so zero or one, then you would only have like an 8 gigabytes model which you could probably load into most GPUs and there's a clearly an attractive proposition in terms of the costs.

Neural nets are typically represent weights as Floating point numbers in order to express a broader range of values in the model, so floating points is the most common. You have three pieces, a sign bit which says is it positive or negative, a fractional bit which specifies the range of the values and then, the exponent which scales how big or small the float is.

Here we have float16 where we have 10 bits of fraction, so this gives a lot more range of what the number could be, then the exponent bit is 5, so you have up to 2^5 as the scaling factor, and then the sign which is positive one or negative one. So float16 is pretty common but for machine learning, it's often not enough, because especially when you're trying to train a Neural net, you often have very small or very big values like underflow or overflow.
And therefore, a really popular data type that was designed just for machine learning is called bfloat16, which just moving some of the bits from the fractional part to the exponential part. So you can have a larger range but within that range, you may have a fewer choice of values to choose from. But it works. It supports some of the problems that we face in machine learning.
Once you get below 16, you're really impacting the amount of things you can represent in a float. Given that, you need one thing for the sign and then if you're range of the exponent is small, then you don't have that much of a range of values. You can't represent at all.

So a really popular way to get really small amounts of footprint in models is by quantizing to integers.
This is not that obvious because you're taking a float and turning it into an int, so one way this is done is called Absmax, or Absolute Maximum quantization, where you map each number in a list of floats to a range of integers.

The most extreme example which should also now highlight some of the issues with this idea of Post-training quantization is, what if we just had a binary value for every parameter - zero or one, and so instead of we might train a model using floats and we get these parameters, the purple here is the hidden states and the red would be the activations, and these are all between zero and one, but if we now round them to the nearest value zero or one, we get a list of binary values and this seems really attractive, because you only need one bit per vector, it's really small.

But now let's consider a real example here, where we are trying to do translation, and then we are producing these float valued hidden states and activations.
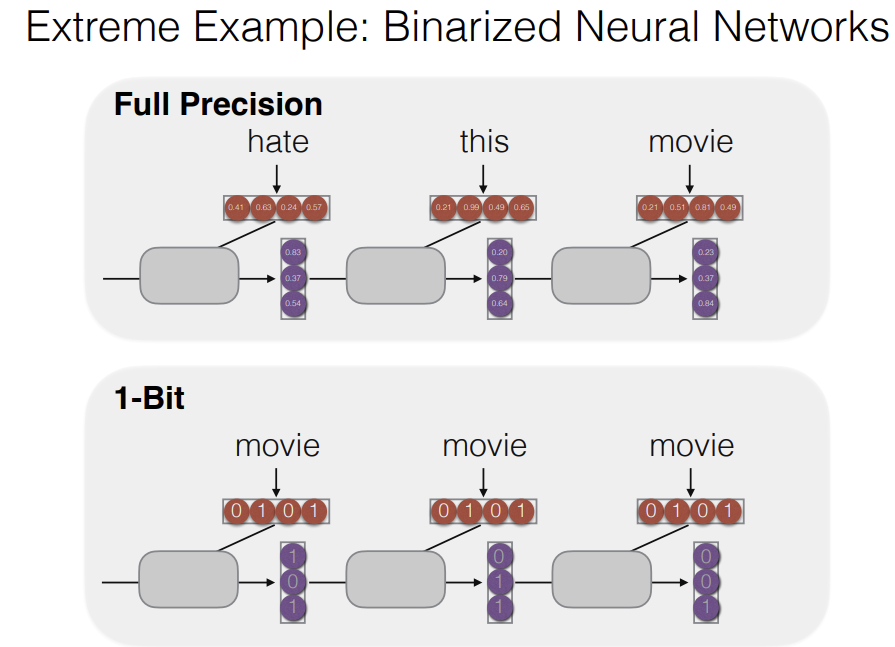
if I just rounded up or down each of the values, the output vectors that would be the embedding vectors, then we would decode to outputs, even though they're very different in the original float space, they actually become all the same thing which is definitely not what you want.
So basically by reducing the precision, you might be significantly impacting the range of things you can express and this does not work. Turning a complex set of floats of high precision floats to binary numbers does not work.

The idea of Model-Aware Quantization is, if you can study the statistics of your model, you can learn ways to represent values in a way that is matching the actual distribution of weights in that model, for example, with BERT, most of the weights in each layer are concentrated around the mean value and you have a few weights that are very far from that mean value.
So you can fit a Gaussian distribution to the distribution of weights and then, only a few weights in each layer will be at the tails of this distribution. If you have values at the tails of the distribution, they pose issues for quantization because if you're using the AbsMax quantization, you're now defining your range according to the minimum and maximum values and then everything in between which might be close together will now be grouped into the same bucket and that throws away a lot of the ability to distinguish between weights in your network.
So the idea here is that, you store the outliers separately, and you store them in full precision. So you're paying the full storage cost for a few parameters and then everything else that's concentrated together gets quantized into a much lower precision space.
I think this is at least in theory very effective and they have strong results here, however a problem with that approach is that, you're defining the outliers and the minimum and maximum for each layer uniformly.

So instead this, LLM.int8 which is very popular in NLP, go a little step further and they instead of quantizing each layer uniformly, they quantize each row or column of a vector in matrix multiplication separately with the motivation that most of the parameters in Transformers are for matrix multiplication and so by doing this, they're able to get a better quantization, because you're able to have a more precise space range of the valeus for each row or column of a matrix.
There is an overhead you're paying when you're doing this kind of quantization where you have to map each vector to a list of numbers and you need to then decode those numbers back into floats. So there's an overhead that costs time when you're doing inference. So if you have a small model, this is not going to help you go faster most likely, but if you have a really big model, it can double your inference speed at least and it also lets you load models into memory that you otherwise would not be able to to so.
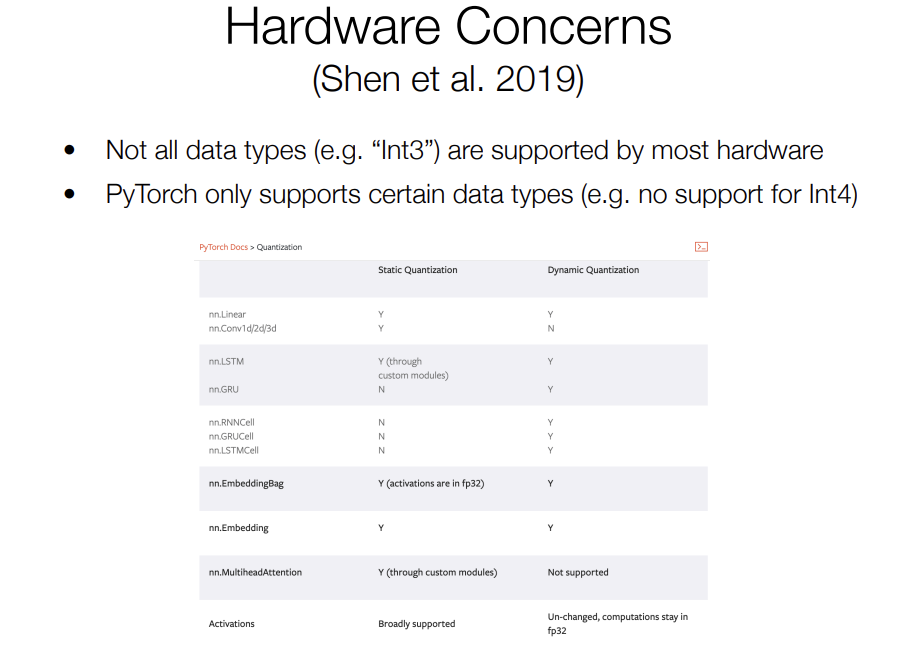

The problem is that the ability for quantization to actually be effective or make things faster is largely limited by both hardware and low-level systems like the framework.

I've motivated why Post-training quantization is hard, because you're throwing away precision which can make it hard to get the most out of the network that you have trained. So attempting idea here is now, let's train the model with quantization in mind.
Now we can revisit the example of binarized neural networks which like didn't work but it actually can work, if you train with the binarization in mind. So a paper in 2016, they considered a case where all of your weights were negative one or one, activation were also negative one or one, and they do some clever statistics to make that work and then the gradients that you back propagate through the model are also discrete.
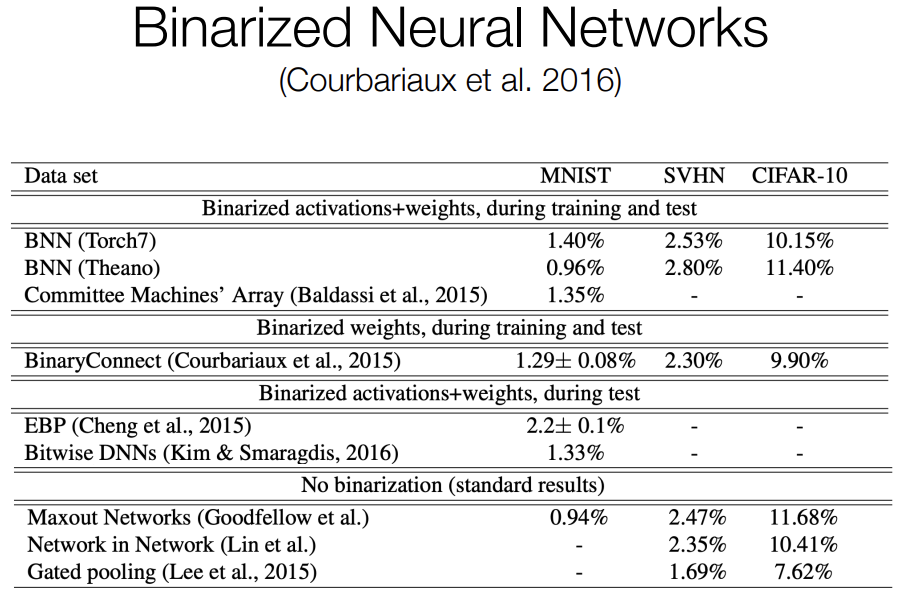
This was sort of a proof of concept that if you quantize during training, you can match performance and get a much smaller model which was a really surprising finding.
이게 되네. 신기하다. 정말 Neural Network의 세계는 불가사의하구나.. counter intuitive한 게 많아.. 이게 어떻게 되지? ㅋㅋㅋㅋ

And then a more recent work is, for doing quantization, another thing you can do is you can start with your model that is full precision, not quantized, and then you can train each layer one layer at a time to replicate its counterpart in the full precision space. So you can run inputs through the full precision model, you get the output probabiliites of each word, and then you replicate your quantized model to reproduce to get very close to those same weights. Then you do this at the second layer so now you have like the logits from the hidden state from the second to last layer and then you train your quantized layer to match those hidden states, and you keep doing that all the way down.
The intuition here is that by doing like layer-by-layer distillation, you're replicating not just the output which is sparse and hard to replicate but even the flow of data throughout the whole model step by step. And you can replicate that into the quantized model which may run into issues when training just end to end.
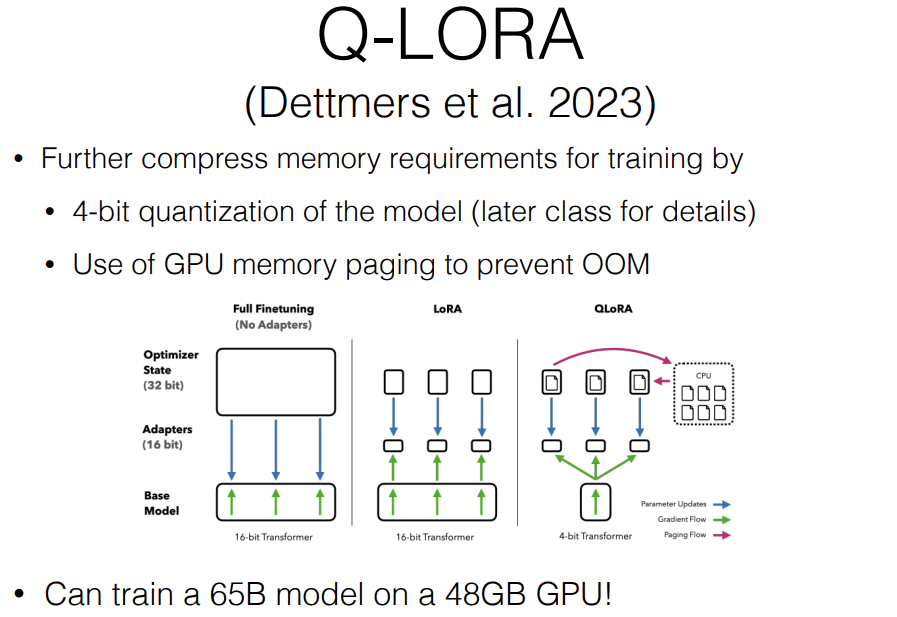
Q-LORA use parameter efficient finetuning to train a highly quantized like 4bit model and they do a bunch of other fancy tricks. Q-LORA is super popular right now. So if you're going to use the quantization method today, this probably would be it.


Pruning is pretty different than quantization. In quantization, you are chipping away at every parameter in your model, instead in pruning, you're completely eliminating some parameters and completely not changing everything else.
So a number of parameters set to zero and the rest are completely unchanged. The most intuitive way to do this is, if you have a bunch of parameters, some of them are probably close to zero in which case they're not doing anything anyways so just make them completely set to zero that way you can ignore those parameters effectively. They effectively are not doing anything and it's as if they don't exist.

In Magnitude Pruning, you set to zero some percentage of parameters that have the least magnitude, and in machine translation, people have seen that you can remove almost half the parameters in a model and get almost zero change in your downstream performance which goes back to the earlier point about overparameterization, you need a lot of these parameters for training the model, but in practice, they're not really doing too much and so you can just get rid of them. This is a type of unstructured pruning where you're just removing parameters throughout the model anywhere you see fit. There's no structure to how you're doing the pruning.

This is related to the lottery ticket hypothesis. The idea is that when you're training a big model, there are sub networks that are actually a better initialization than the inital model.
Here, they prune the model, then they retrain it and they find that surprisingly, a model pruned to 20% of the original models parameters and retrained is actually more effective and generalizes better than original model.
So the idea here is, finding really good initializations of these sub-networks can be better than random initialization of a big model.
This is a step beyond pruning where you're pruning a model then training on top of that and that can improve performance.
But generally, pruning, is not a method to improve performance, method to maintain performance while improving the efficiency and the size of your model.


More immediately useful idea is called "Structured Pruning" and the idea here is that, instead of just picking parameters across the whole model, you remove entire components or entire layers and therefore you're pruning the model in a way that is structured, and really going to make a difference on your overall runtime.

They showed that if you're training a Transformer model like BERT, you usually have many heads of attention, but in practice, most of these heads of attention can be removed without really any negative impact on the performance of your model.

Generalizing this, recent work has proposed controlling even other compoents of your model, so this paper from two years ago, they propose masking. Having two levels of masks on your model. First is what they call, a coarse mask which is turning off large components like entire self attention layers or full feedforward layers where you replace them with identity matrix, and these are like really big things to turn off, and then you could also have fine masks control like individual heads or removing individual dimensions, so changing your hidden state to be from 512 dimensions to 200 dimensions.
So the idea here is, they give two different levels of granularity at which you can turn off different components and then these masks learned using some held out validation data to learn what can we turn off without totally destroying the performance of this model.

They randomly mask out all the different modules in the network, so they create 100 or thousand variants of this model with different masks turned off, then they measure the performance of those like perturbed models and then they learn a regression of how much does each module affect the performance of the full system and then you can use these regression weights to figure out which modules you can turn off without impacting the performance too much.
사람은 다 비슷한가봐 ㅎㅎㅎ 나 처음에 이 Lottery Ticket Hypothesis 논문 보고, pruning을 접했을 때, 이게 Dropout이랑 뭐가 다른거지..? 생각했는데, 혹은 parameter의 일부를 freezing한다던지 뭐 그런거랑 뭐가 다를까 싶었는데, 역시 "Dropout이랑 뭐가 다르냐"는 질문이 나왔다. 오오 덕분에 설명을 들었다! ㅎㅎ
You can see Dropout as a version of pruning where at each step of optimization, you perform a random pruning, you like randomly prune your network at each update and you train, update the parameters that have not been dropped out, but then in the next step you have a totally different prune network. But here, you're doing pruning "once" and then you're training it this "fixed" pruned network for all the iterations whereas in dropout, you're doing a random pruning each time. And they serve different purposes, the main difference where pruning is primarily for reducing the size of your model whereas dropout is primarily for regularizaing your model to avoid overfitting, like individual weights having too much correlation with the label.
오 이해했다! ㅎㅎㅎㅎ Thank you~! ㅎㅎ


In distillation, the core idea is that you're training one model to replicate the behavior of another model. This is fundamentally different than the other two methods we talked about so far. In distillation, you're probably changing every parameter in your model, you might even be having a totally different architecture. In the other two methods, in quantization, you are not changing any of your parameters up to a certain amount of precision and, in pruning, you were keeping a set of your parameters completely fixed whereas in distillation, you're changing everything but hopefully doing it in a way that requires many fewer parameters.

And distillation is related to really cool idea that is more classic machine learning called "Weak Supervision" which is the idea that, if you have unlabeled text or it could be images or whatever, whatever data you want to process, you can produce things that are like-labels that you could use like-labels but maybe are not actually written by humans and then you can train on these as if they were labels and actually get pretty good performance. So a few famous examples of this is, one is self-training where you initialize a model with a handful of points like three or five examples, you train a classifier on that very small number of points which is going to be really bad because it's not enough data to learn, then you have that model make its own predictions which are probably pretty bad on a bunch of unlabeled text, you use those pseudo labels to update the model again and you can do this iteratively so you're using a model to produce its own training data to train itself and you do this over and over and this is a pretty classic method at this point, it's 30 years old and that's self training.
And then there's a few others that are related to this, and all pseudo labels are also used. If you don't have the ability to annotate thousands of examples, but you can write a basic rule, you can use these rules to construct pseudo labels that you then train an actual full vocabulary model and if you have enough of these pseudo labels with enough of these rules, you can actually get pretty far.
I'm mentioning "weak supervision" because this to me forms the basis of knowledge distillation.

In knowledge distillation, you train a small model to just replicate the predictions of a big model, so the big model is producing pseudo labels on unlabeled text and then that becomes the target for your small model to match.
The one requirement here that is really important to note is that you do need unlabeled text that matches what you expect as input. So let's say you're doing a movie review classification, you definitely would need to somehow find thousands of movie reviews that look like that your model is goinng to expect and that's most of these methods require to work.
There's broadly two kinds of ways you can train knowledge distillation. The first is called "hard targets" where you take your unlabeled text, you produce a label from your teacher model and then you now use that predicted like that the teacher's prediction as the target for your model. This is really easy, convenient, intuitive.
Another type of distillation that's even more effective pretty consistently is called "soft target" distillation which is, instead of trying to do a supervised learning objective where you're trying to match the label predicted by your teacher, instead want your student model to produce probabilities over the full distribution of labels that matches the teacher distribution over labels.
A cool thing here is that this is usually not possible with supervised learning when you have an annotator they usually just give you one answer, they don't tell you how likely it is, if they were wrong about that answer, they don't tell you what the next best answer. But with a neural network teaching you, you can ask that, you have a lot more flexibility.
This also changes how it's optimized. So intead of optimizing for the probability of the correct answer, you can optimize for the difference in your distributions over the answers.
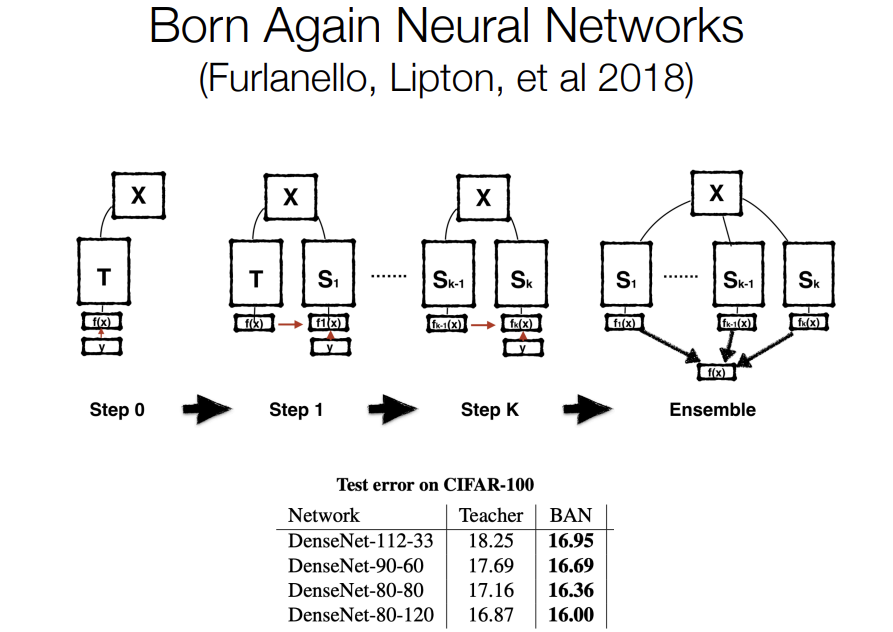
The idea here is that, you can take a model that is trained with supervised learning and they train it on an image classification task, then you can repeatly distill it to itself using soft targets, so you take a bunch of images and then predict the distribution over the labels of those images and then train the model in a soft target distillation objective using itself as a teacher. This pretty consistently improves performance of a model.
The intuition here is that, this soft target objective which is different than what you would train using supervised learning, it's a different objective that is somehow conveying more information to your model, it's conveying uncertainties about the labels and it's a richer knowledge interface between the teacher and the student than just giving a single answer and that this rich interface of knowledge can be really effective.
이거 뭔가 신기하면서도, 모델 성능낼 때, 일단 앙상블하면 성능 향상이 거의 보장되는 현상이랑 비슷하면서, soft vote로 앙상블하는 거랑 비슷하네. 근데 그 앙상블을 다른 친구들이랑 하는 게 아니라, 자기자신이랑 recursive하게 하는..??
아니면.. distribution 에 대한 정보를 줌으로써 calibration이 나아지는 걸까?

Distillation was originally designed for, when you had a single label per input, but in text we often have seqeunces. Maybe we want to generate a sentence. So how do we extend distillation to this sequence labeling setting? There's two ways.
The first is that you want to match the distribution of words that the teacher suggested at each point in your generation process, so given prefix like "This movie is (blank)", you then see the teacher distribution over the words and try to replicate that in your student model.
The problem here is that, as you keep generating the text, the teacher and the student might diverge dramatically, like the teacher might be generating consistent text and it starts to look very different than what the student could have possibly generated, this is related an idea called "exposure bias."
So the second idea is, sequence level distillation where you instead just generate a hard target from the teacher, use a soft targets at the word level and then at the sequence level, you generate a full sentence from teacher and you want to maximize the probability of that, like pseudo labeled gold sentence. They show that if you combine these two objectives together, it's really effective.

One really popular distilled model in NLP is called DistillBERT. The idea here was, can we reduce the size of BERT in half and get the same performance? So they use a couple tricks to do this. First, they took every other layer of BERT, so if you had a 12 layers BERT model, they took 6 layers. And they initialized each layer from one of the layers of the initial BERT model. So it's not a random initialization.
Then, they did effectively soft target distillation which was effective. They also use combined soft target distillation with real supervised objective from laguage modeling. They masked tokens of text and they tried to train on both, like what was behind the mask but also what the teacher would have predicted for that mask. And they found surprisingly that the supervised objective doesn't really help much at all. So if you have a good teacher, that's probably enough for distillation.
(human이든 model이든 좋은 스승을 만나는 게 이렇게 중요하구나..!! ㅎㅎㅎ)

And then they did something else to make sure that the embedding space had a similar geometry in the small model and the big model.
The main finding here is that, you can do this and get a model that is pretty much just as good or very close to it in most tasks as the big model.
DistllBERT is super popular, people use it all the time.


Now, I'm going to go a little bit off of this initial motivation of efficiency, and talk about how distillation can be used do things that you cannot do otherwise like unlocking capabilities and performance that are pretty much impossible using traditional learning.
The idea here is that, they're doing self distillation, where they're taking a model, making it generate data, and then training that same model on that data.
That's the basic idea but here, they're doing something very specific where they take a vanilla language model that's just trained to generate text and, they're trying to teach it to follow instructions using instruction finetuning. And the way they accomplish this is, by having this vanilla language model first generate instructions arbitrarily like, write a poem about dogs and then produce responses to those instructions like a poem about dogs. And then training that same model to now imitate its own behavior.
They use some tricks that make this work, and one of the key tricks that, when you're doing dataset generation, the most obvious thing to do is you first generate the inputs then your outputs, pseudo label, but the issue here is that the quality of your labels is only as good as your teacher is, so if I first generate a text and then I generate the class that I think corresponds to that text, if this class label is bad in systematic ways, then created data will be bad and you're not going to be able to learn anything useful, but when you're generating data, you don't need to do this linear process. You can instead, first generate the class and then generate inputs conditon on that class. So this is kind of doing things backwards and you can't do this when you're doing real prediction, because you don't know the class, but for generating data, you don't need to do things linearly and so this idea is really important in data generation that you can decompose your task into different patterns or orders and then generate your data from the ground up that way and hopefully this way by reducing a hard problem to an easy problem, you can do a lot better.
In this paper, they call this idea "task asymmetry," If you have a task of going from X to Y, that is really hard but going from Y to X is easy, then you can start with a bunch of Y's generate syntetic X's because this direction is easy, you can do pretty good at this, and then you can now flip the data again and train your model to generate Y from X. You have a lot of data that is pretty good and then you can do really surprisingly well using this strategy.
So in this paper, they were doing information extraction where you're given sentences and you wanted to extract triples so here like you had, what film, who is, what's the location of that film and instead of doing this, sentence to information extraction is pretty hard, but it's easy to get be given a bunch of entities and generate sentence about those entities, that's trivial to do with large language models, so they went to backwards and they took a bunch of triples, generated text synthetically and then flipped the order of the labels and inputs. And then what they found is that, in terms of the performance, it's double as good as the previous best model.
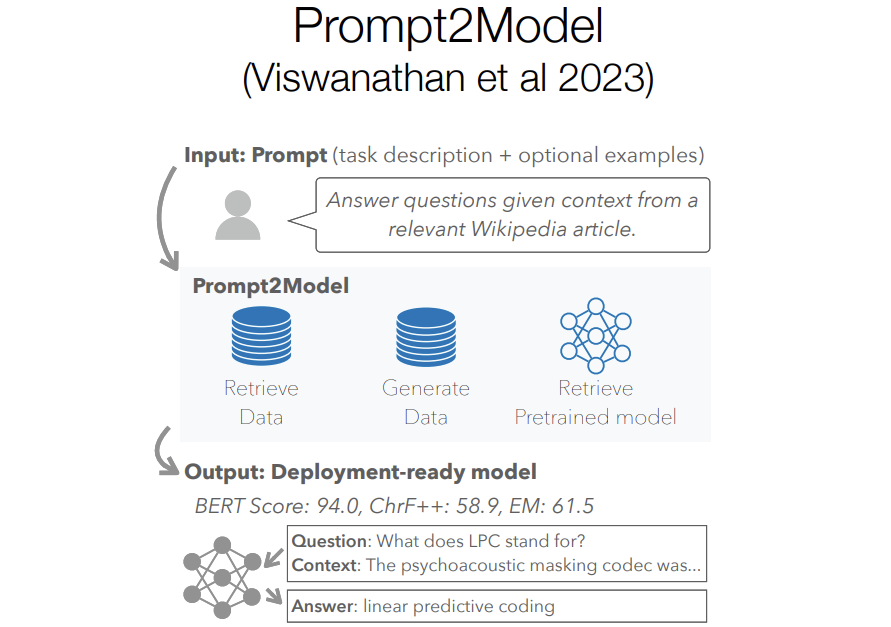
Going a little further in this idea of using distillation to do things that you couldn't do before is, which is called Prompt2Model. The idea here is that, now distillation is one way to get training data for your model but there might be other ways to get data as well. So the key idea here is, can we combine retrieved data, existing data that exists on the internet with data generated from LLM? can we put these two things together and do even better?
So in this paper, we ask the user to specify their task in a prompt like what you use for GPT3 and they can give a couple examples if they want and then given this prompt, we first retrieve existing datasets that might be relevant to that prompt. So we had like a method for dataset retrieval in a previous paper that just uses text to find similar datasets. So if I say answer biomedical questions about for cancer doctors it might find like the bioasq dataset.
And then we take that retrieved dataset which is likely to be high quality but may not match the task that the user actually cares about, it might be like a little bit different than what the user actually wants.
We then complement this retrieved dataset with generated data generated by a language model which is potentially like not that high quality but is much more likely to match the user's intentions.
We then did one other thing which is retrieving like a pre-trained model as well like maybe you have a pre-trained model that is in your domain that you want to that you can actually benefit from. Then we just put all these things together fine-tune this small model on your generated and retrieved datasets.
And then, we were able to obtain small models that often outperform GPT3 even though GPT3 was the model used to generate data.
So like we were beating the teacher by leveraging both distillation but also taking advantage of existing datasets that were available on the internet.
So I think that generally this is a direction I'm really excited about distillation for the purpose of advancing model capabilities.

I think that this kind of came at a time when distillation was becoming really popular but now it's often used by a different name which is called syntetic data generation.
It's effectively the same things as hard target distillation, but this is like probably one of the hottest research topics in NLP right now. And just last week I saw this paper on the internet that provides a sort of Pytorch like toolkit for doing distillation. So they define different primitive operations like generating stuff from prompt or from RAG doing retrieval, doing filtering and ranking of examples or judging your generated examples using another LLM and they also integrate model training into this loop.
I think that this is a really exciting direction in terms of making dataset generation something that can be very mature and managed like a real engineering problem.
'*NLP > NLP_CMU' 카테고리의 다른 글
Ensembling & Mixture of Experts (0) 2024.07.08 Reinforcement Learning from Human Feedback (0) 2024.07.08 Long-context Transformers (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Fine-tuning & Instruction Tuning (0) 2024.07.06