-
Generation Algorithms*NLP/NLP_CMU 2024. 7. 5. 11:43
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=96MMXDA7F74&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=6
https://phontron.com/class/anlp2024/assets/slides/anlp-06-generation.pdf

A model M gives you a probability distribution over all tokens in its vocabulary to predict what token you would output next.
Given some input X and everything that you've predicted so far, you get the probability of the next token in Yj and if you multiply this out over all the probabilities in your sequence, you can calculate the probability of any output y given your input X.

So what this like super fancy model that you spend a lot of money to train is really just a conditional probability distribution. But this turns out to be okay because you can use a conditional probability distribution to do any task that we're interested in NLP, pretty much any task.
So by changing what you consider your input X and output y to be, you can get outputs from this model for things like translation, for summarization, for reasoning task.

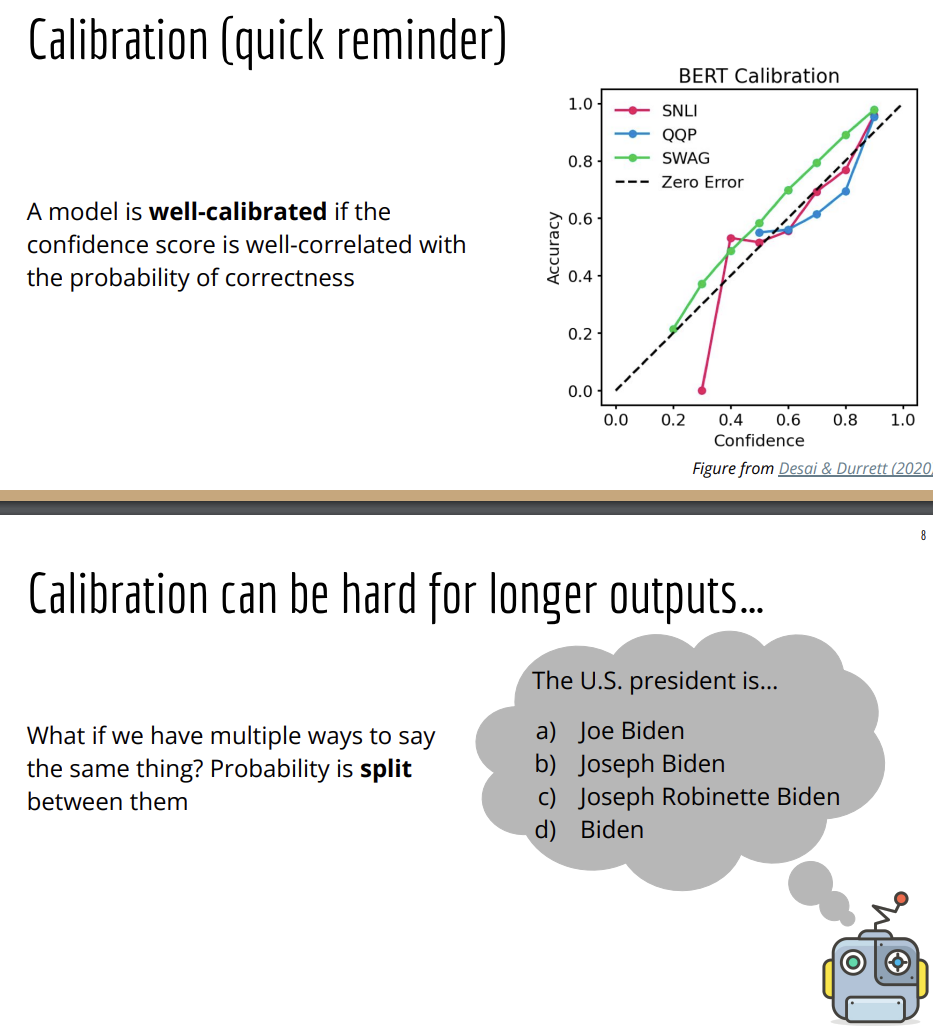
There's both good and bad things about your model being a probability distribution instead of just an oracle that gives you a single answer for every input. One nice thing about this distribution is that you can get an idea of confidence. If you give your model the input 2 plus 2 equals and almost all the probability mass is on the token of four, you can say the model predicts with pretty high confidence that 2 plus 2 equals four versus if you give it something that's a little more open-ended like you ask it to predict Graham's favorite color and you see the distribution that's a lot flatter. The most likely output is green but maybe we don't have a lot of confidence that that's the correct answer.
This is closely tied into the idea of calibration. The flip side of this though is that for this case like 2 plus 2 equals 4, not all of the probability mass is on four.
So models that are conditional probability distributions can hallucinate pretty much no matter what you do there's going to be some nonzero probability to some output that's incorrect or undesirable in some cases maybe even offensive something that you don't want the model to output.
And this is an artifact of the way these models are trained. And there's some great work more on the theory side here that shows that this is actually true even if everything in your input training data is correct and factual and doesn't have any errors, you'll still wind up with a situation where some nonzero probability mass is on some outputs that are undesirable or hallucinatory for most inputs that you care about evaluating. So if we have these issues, how do we actually get a good output out of the model?
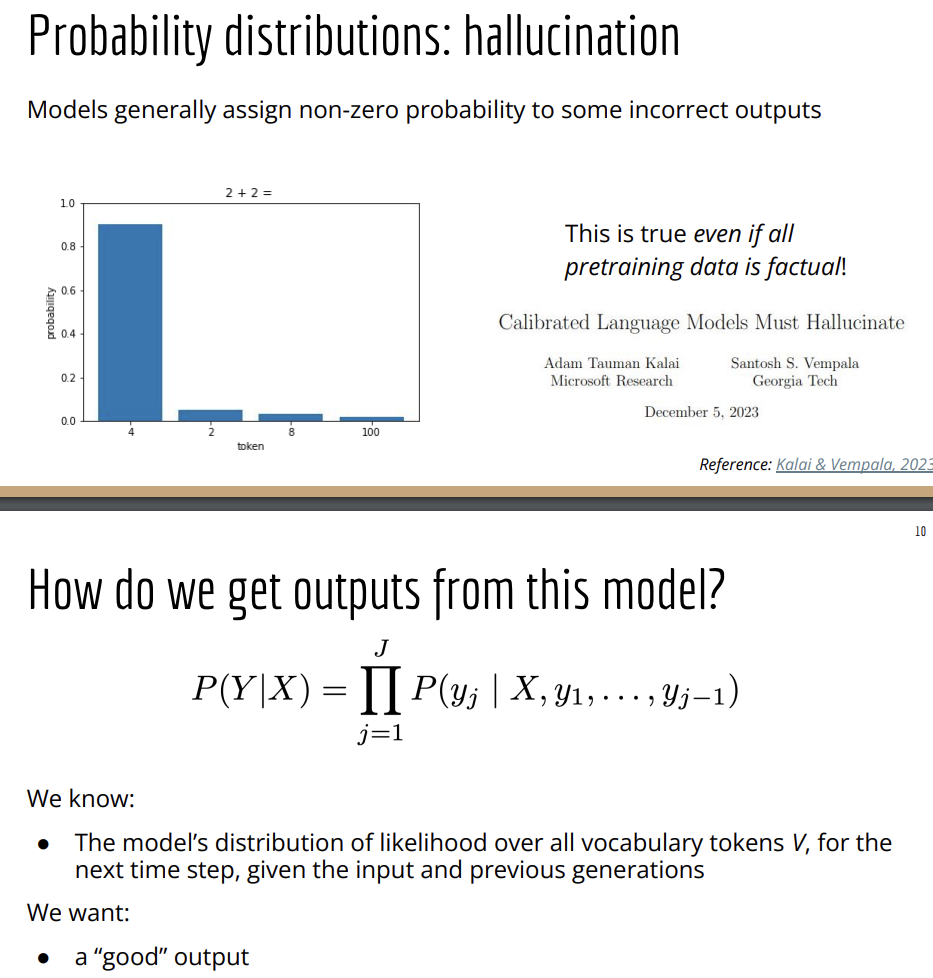


This is a really longtailed distribution and the green part of the distribution which is a lot of tokens with high likelihood has 50% of the total probability, the yellow part which is all a lot of things that are all individually not super likely is the other 50% of the probability.
So what that means is, if you're doing something like anscestral sampling, 50% of the time, you'll be sampling something really unlikely from this long tail that seems not like what we want.
So is there anything we can do about this? And the obvious for solution is, can we just cut off that tail like if we know these tokens are not super likely, can we just ignore them? And there's a couple of different ways to do that.
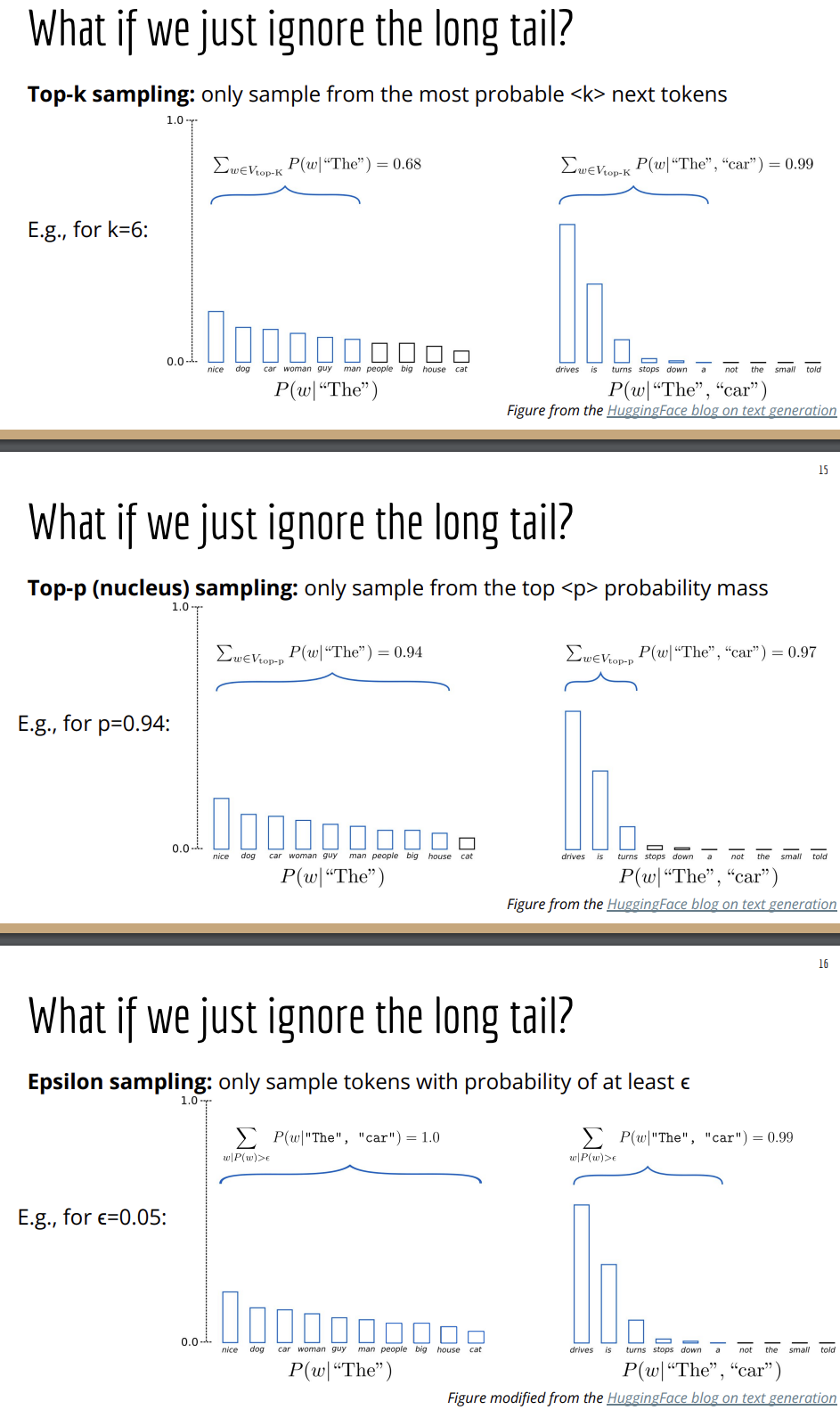
These methods are differnt ways of trying to cut off the long tail using different characteristics. The tail of the distribution isn't the only thing we could choose to modify. We could also choose to modify peakness of the distribution.

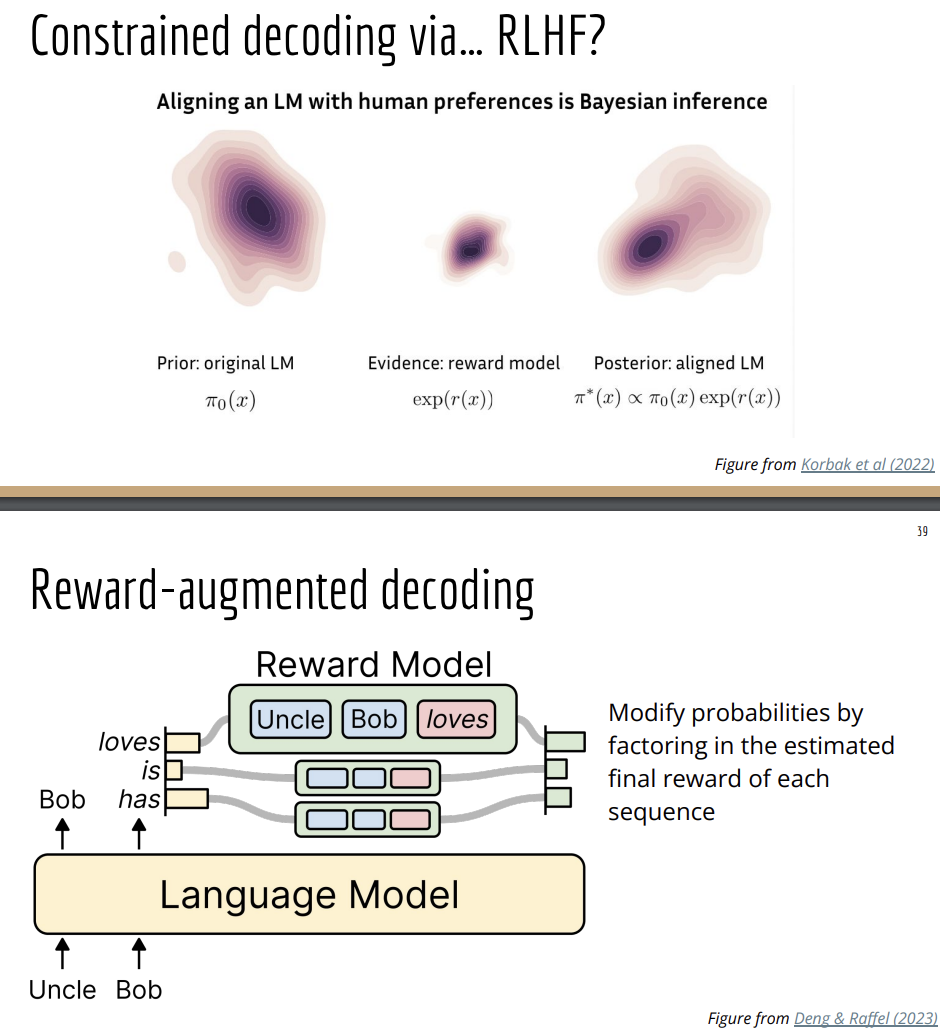
The idea of Contrastive decoding is that we could incorporate some extra information at decoding time using some other distribution, some other data or some other model.
If you've ever played around with a relatively small language model, something like GPT2-small, you probably noticed you try to give it some inputs and maybe it degenerates into just repeating the same sequence over and over, maybe it gives you outputs that are completely incorrect like you ask it a factual question and it gets it wrong. And you don't see those problems if you look at a larger model that's trained on more data.
So the question here is, can you use what that smaller model is getting wrong to make you larger model even better? And the way we do this is by the intuition that if the smaller model doesn't have a lot of probability on some answer but the larger model does, it's likely because that larger model has learned something with the smaller model didn't know.
So here we modify the probability distribution coming out of the larger model to choose outputs that model thinks are very likely and the amateur or the weaker model thinks are not likely.

We don't want something from the model distribution or something from a modified distribution, maybe we actually just want the quote, unquote best thing the single most likely output given our input.








'*NLP > NLP_CMU' 카테고리의 다른 글
Long-context Transformers (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Fine-tuning & Instruction Tuning (0) 2024.07.06 Prompting (0) 2024.07.05 Transformers (0) 2024.07.05