-
Transformers*NLP/NLP_CMU 2024. 7. 5. 09:42
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=QkGwxtALTLU&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=5
https://phontron.com/class/anlp2024/assets/slides/anlp-05-transformers.pdf


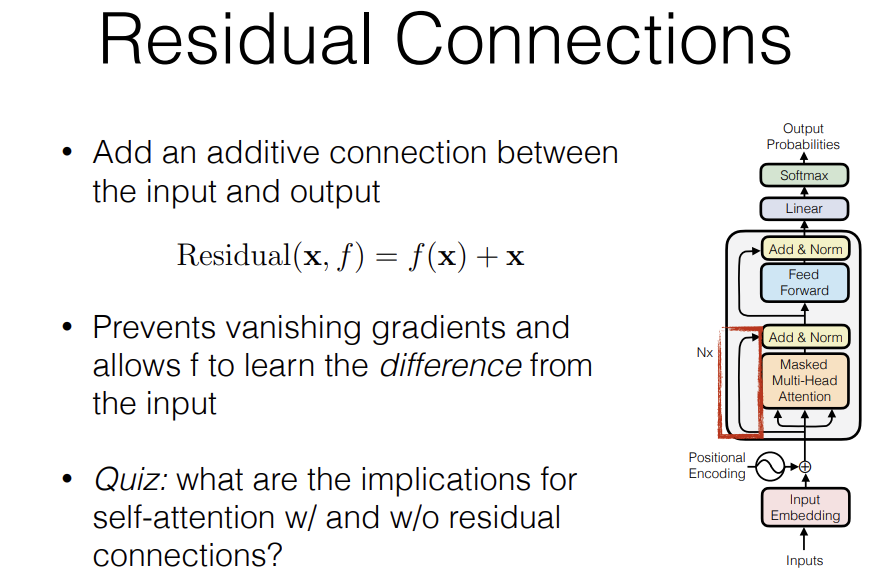
Residual Connection allows f to learn the "difference" from the input - instead of learning how the input should be mapped into the output, you learn what difference should I apply to the outputs.
=> What are the implications for self-attention w/ and w/o residual connections?
Because we now have the residual connection, it "deprioritizes" looking at itself, looks at the surrounding to understand what do I have to add as context. It de-prioritizes attending to yourself because you get yourself for free through the residual connection, you get the information from yourself for free, so you just need to pull in the other information that's useful for contextualizing the current factors.

Post-Layer Norm breaks the residual connection!
Hurting gradient propagation, because you have a function other than the identity in the middle of the layers and that's bad for propagating across many layers.
So a modification to this is Pre-Layer Norm where layer Norm is applied previously to all of the multi-head attention and FF layers which gives us direct residual connection all the way from the beginning to the end and that improves gradient propagation.
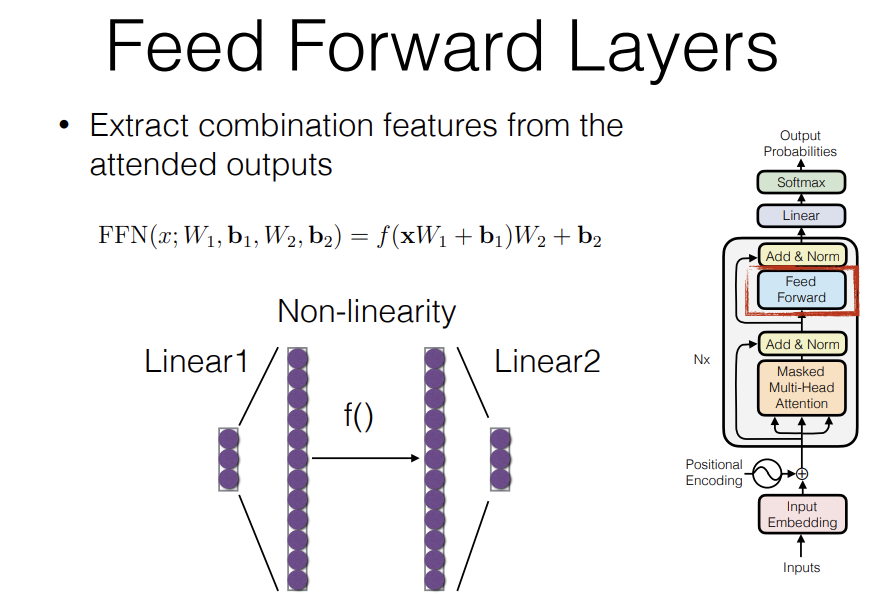
Feed Forward network is applied independently to each vector in the sequence.
It's pretty common nowadays to remove the bias also mostly because it's just extra parameters and not useful and it can lead to some degree of instability in training so you'll often see linear layers that have the bias off and it's just because it's not necessary to learn the network well.
Usually the Feed Forward Network in Transformers upscales to a very large vector to extract lots of features, so each one of these elements is a feature and a lot of people when they do interpretation of Transformer models, they look at these features because they tend to correspond more directly with the information that we would expect to see.







Great lecture!
'*NLP > NLP_CMU' 카테고리의 다른 글
Long-context Transformers (0) 2024.07.07 Retrieval & RAG (0) 2024.07.06 Fine-tuning & Instruction Tuning (0) 2024.07.06 Prompting (0) 2024.07.05 Generation Algorithms (0) 2024.07.05