-
Large Language Models*NLP/NLP_CMU 2024. 7. 9. 15:20
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=2rOSrDtg7HQ
https://phontron.com/class/anlp2024/assets/slides/anlp-15-tourofllms.pdf

I'll be talking about a tour of modern LLMs and the idea here is that, there is many many large language models available nowadays but I wanted to go through some of the ones that are particularly interesting for various reasons either because they disclose a lot of information about how they were trained, so we can get an idea about what is involved in training a state-of-the-art language model or because they're the strongest models that you can download and use on your own, the best open weights language models that are available or because they're specialized to some particular topic or because they're the best closed language models.
What is going into all the models that you're using for whatever tasks that you're trying to solve? so, one important thing is, what makes a model? It's basically the model architecture so what architecture do you decide to use, what data do you decide to use and what training algorithm or training method do you decide to use. And all of these are important.
You'll see today is that almost all of the mdoels that we're using use very similar architectures that's very similar LLaMa, but despite the fact that they use very similar architectures, their accuracy is vastly different or their abilities are vastly different. So that must come from the data or the training decisions. So that's an argument for the fact that architecture decisions are a lot less important.
My counterargument to that is, we spent 9 to 10 years fine-tuning and finding the LLaMa architecture. So now we have the LLaMa architecture which is a really good architecture, it works really well when training very large models on lots of data and so now we don't need to use another architecture because the architecture we're using is good, but if we were trying to do the same thing with the LSTM from 2014, then none of the stuff we're doing today would work. Also architectures can make things faster and that's included in decisions.

First thing I'd like to talk about before I get into any of the details is, Open versus Closed access. This is not like modeling stuff, but it's important and also helps you understand the environment a little bit.
They discuss several different varieties of openness of release of language models in advanced AI systems and there are some things that se can talk about. We can talk about the weights being open? described? closed? Inference code or inference methods being open being described? or being fully closed? traning being open? described? closed? and data being open? described? or closed?
And in general, we have the open weights models that are on huggingface that might just mean the weights are open, the inference code also needs to be open because otherwise you can't do inference on them. If they're on huggingface, but that doesn't mean that the training code is open. It also doesn't mean that the data is open.
So there's various degrees of openness. Of course there are things like GPT models where all of this is closed and we don't know anything about it, or know very little about it.

Another thing is about licenses and permissiveness. This is important if you want to do a research project to know because it impact on the things that you legally can do or can't do. In universities, we should be following the law, but maybe people think about this a little bit less. If you're in a big company, this is something that becomes really important. So it's important to think about. I'm going to go through several degrees of licenses that if you've done anything in open source, you probably know a lot of these.
The first one is public domain or CC-0 and this means you can do anything with it, like, I could download it and this includes the download it and redistribute it not give you any credit, modify it in anyway I want.
Next, MIT and BSD. These are very common software licenses. You'll see them on a lot of research projects. These have very few restrictions other than maintaining the copyright.
There's also Apache, CC-BY, here you must acknowledge the owner of the original creators. So you need to say this person actually created this originally.
GPL, CC-BY-SA, these are licenses where if you use them, you need to reshare under that license.
CC, Creative Commons licenses are more for data. There's also Creative Commons Non-commercial licenses or software non-commecial licenses, you can't use them for commercial purposes.
Once you start getting down here, this is no longer called open source. There are these licenses that a lot of people like meta or huggingface come up with for their models recently, so LLaMa license.
The original LLaMa license has some interesting things. Number one, you cannot use LLaMa to train any language model that is not derived from LLaMa. So you can't generate data from LLaMa in training Mistral. That's not allowed according to the LLaMa.
Basically they created that license so their competitors don't take their language model and just use it for free.
Final thing is no license. So let's say, you have some code that you upload to GitHub and you don't put a license on your code, this means that you have only agreed to the GitHub licensing terms which means that actually nobody can use your code. They can view it possibly but they can't download it, use it, they can't incorporate it into their own system.
So if you release research code, I would highly encourage you to use MIT or BSD or one of these permissive licenses, so other people can use it and follow up and your code can be effectful. This is important thing to know about.

Most data on the internet is copyrighted, so right now most model training, not all model training, but most model training is done assuming fair use which means that training an AI model on copyrighted data is, number one, it cannot reproduce the material easily, so it's instead of quoting material directly, it's kind of combining the material together to create a new thing. They're saying it doesn't diminish the commercial value of the original data. And then, non-commercial purposes is a secondary concern, since the first two hold.

Another question is, why restrict model access? Why do we number one, make models closed, number two, maybe not even describe what we did in our model? There's three main reasons. The first reason is, commercial concerns and so they want to make money from the models. So Google makes money from the Gemini API and Antropic makes money from the Claude API. These are all models that I'm going to talk about.
Number two, safety. There are very legitimate concerns where if you release strong models, people might use them for bad things. Creating fake content online or doing spear fishing attack against people and trying to scam them out of money. And then the final one is legal liability. So training models on copyrighted data is a legal gray area as I just mentioned. So they don't want to say what data they trained on because if they say what data they trained on, then they might get sued.
OpenAI has been doing sketchy things for a long time and look where they are.


I'm going to talk about five different models and I picked them for a reason the first two are because they're open source and fully reproducible namely Pythia amd OLMo and the reason why I want to talk about these is, everything about them including what data they were trained on, what their training procedures are, you can download all the stuff so you can know exactly what goes into making a strong model. Pythia has many sizes in checkpoints which is pretty interesting. OLMo is maybe the strongest reproducible model at the moment.
Then we have open weights models and these are models that aren't fully open, they don't disclose everything, they don't release their training data or code. But I'm going to talk about LLaMa2 which is the most popular, it's also heavily safety tuned. And Mistral/Mixtral which is a strong and fast model, and it's somewhat multilingual. And also Qwen which is a very strong model. It's more multilingual and specifically it's good in English and Chinese because it was trained down of that.

First going into Pythia. For each of them, I'm going to give an overview and then talk about some interesting points about them. So Pythia was created by EleutherAI. EleutherAI is one of the first open-source AI organizations. They've created a huge number of really useful things including training code, models, training datasets and also evaluation that's used pretty widely. The goal of Pythia was basically joint understanding model training dynamics and scaling and so from that point of view, they released eight model sizes from 70 million parameters to 12 billion parameters. For each size, they have 154 checkpoints throughout the training process. They trained on 300 billion tokens and did checkpoints periodically during the training process.
So you can do interesting things like "how quickly do small models learn things?", "how quickly do large models learn things?" and other stuff like that. In terms of the architecture, as I mentioned at the very beginning, the architectures are very similar between them, so it's almost easier to point out their differences than their similarities.
I mainly focused on the 7 billion models because almost everybody trains a 7 billion model. It's kind of one of the standard sizes. It's the smallest size of LLaMa. It's one of the largest size of OLMo and one of the largest sizes of Pythia.
7 billion models are generally 4096 wide, 32 deep, 32 attention heads, and their hidden layer size is about 83 of the size. This is a standard LLaMa 7B architecture. As you scale up to larger sizes, you just increase the number of layers. You increase the width and other thing like that.
The other standard is, everybody uses a Transformer. Everybody uses pre-layer norm like I talked about before. Everybody uses RoPE embeddings. And almost everybody uses a SwiGLU activation. So this is kind of standard recipe that almost everybody uses.
Where things start to change a little bit between architectures which arguably might not be very important is, how long is the context length. So Pythia is 2K context compared to LLaMa. LLaMa2's 4K context. Actually LLaMa1 is 2K context.
Another thing is where do they put biases in the model, most people don't use biases anywhere, but sometimes they put them in various places.
The other thing is, a variety of LayerNorm that people use and Pythia was using standard parametric LayerNorm, but gradually people are stepping back from that and they're using like RMSNorm or even nonparametric LN. So small architecture differences but almost everybody uses something pretty similar.
The data,this was trained on 300 billion tokens of the pile. One interesting thing is that, they also did a duplicated training run on 207 billion tokens and the idea is that they wanted to test how important it is to duplicate, how much do you gain by de-duplicating in terms of training efficiency.
And they have different learning rates for different model sizes. The 7B model is 1.2 *e-4 in contrast, LLaMa is 3*e-4. So this is potentially big change. Because the learning rate is actually half the size here.
Batch size, they use 2 million tokens and LLaMa2 uses 4 millon tokens for the batch size. So there are some small differences.
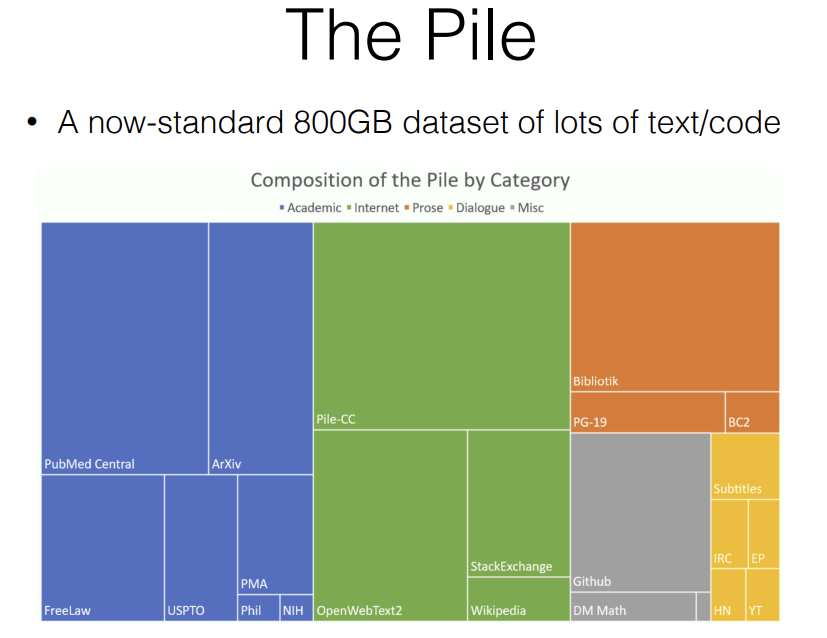
Next, I'd like to talk about The Pile. This is the original open datasets for training large language models that being said. It's really nice dataset made out of lots of different types of data and namely it's trained on academic data so that includes things like PubMed, ArXiv, FreeLaw, the US patent office other stuff like that. It's also trained on internet data so this is data that's just scraped from parts of the internet but also StackExchange, in Wikipedia. It also has some prose, so these are like book datasets. It has some code datasets and it has some subtitle dialog datasets in it. So this overall is 800 gigabytes or about 300 billion tokens.

Some of the findings from the Pythia paper in addition to just being one of the original strong open language models is, they have some interesting analysis into model memorization and how quickly models learn based on the number of tokens that you show them. And this graph is, the left side is one of their smaller models 160 million, the right side is their biggest model 12 billion, the different lines are different steps of the training process, and the x-axis is the frequency of a fact in a training data, and y-axis is question-answering accuracy about the fact.So what this is showing is, as you scale up the model, the larger model learn faster up to a point, so the 2.8 billion model is about the same as the 12 billion model at earlier parts of the training process. But as you get later in the training process, the 12 billion model is memorizing and being able to recall more facts so at the very beginning you need to scale up to about 2.8 billion to learn efficiently but at the end, this model(12B) is like better further on.
So this is really nice, all of these checkpoints, all this data is open. They even made the data loaders. So it's reproducible. So you can look at the actual data that the model was trained on, at each of the checkopints. So if want to do this sort of analysis, this is a good set of models to look at.
Another thing that they did is, they did intervention on the data. So they tried to intervene on the data to modify it. Because male or masculine pronouns were much more frequent than feminine pronouns in the data, so they intervened on the data to try to balance out the distribution of masculine and feminine pronouns and demonstrated that the model became less baised towards generating masculine pronouns later. So they also were able to do those sorts of intervention studies.

OLMo is a more recent model. Pythia came out around a year ago, OLMo is very recent, about a month ago. This is created by AI2, the Allen Institute for AI. One thing you'll notice is the two completely open models that I'm talking about, both came from non-profit organizations. So EleutherAI is non-profit, AI2 is nonprofit, so they're maybe a little bit less worried about people trying to sue them for lots of money for fair use violations. So that's the cynical point of view. The non cynical point of view is, they have nothing to profit by creating a better model by having other poeple create a better model. So they're willing to do this for open in good science. Their goal is better science of state-of-the-art LLMs.
Some of the unique feature are top performance of a fully documented model. And they also have instruction tuned models etc.
Looking at the parameters, basically similar to LLaMa. The one big difference is, they're using non-parametric LayerNorm instead of RMSNorm. So this is LayerNorm with no parameters. They didn't super clearly justify why they decided to do this. One difference from Pythia, this was trained on 2.46 trillion tokens, so compare this to Pythia which was trained on 300 billion tokens and so they trained it for a lot longer. They trained it on something called the Dolma Corpus which they also created at AI2.
They use 3e-4 learning rate which is the same as LLaMa. And batch size is 4 million tokens which is also the same as LLaMa.

Dolma that they created is, pretty similar to the Pile, but it's a larger corpus. It's 3 trillion tokens. This is also fully open, so you can download it from Huggingface if you could find some disk to put three trillion tokens on.Another thing is that, they have a data processing pipeline of language filtering, quality filtering, content filtering, deduplication, multi-source mixing and tokenization. So the nice thing about this is, a lot of this stuff is usually proprietary for most language modeling creators, so if you want to see all of the data processing pipeline, that goes into training a model, this is a pretty good example of that.
The document types that are included are the common crawl and so the common crawl is just data crawled from the internet. It's about 2.2 trillion tokens. They also have the stack which is lots of code about 400 billion tokens of code. C4 which is also web data, Reddit, stem papers, books and Wikipedia, encyclopedia. So you can see that is has a fairly large amount of coverage, although mostly in English.
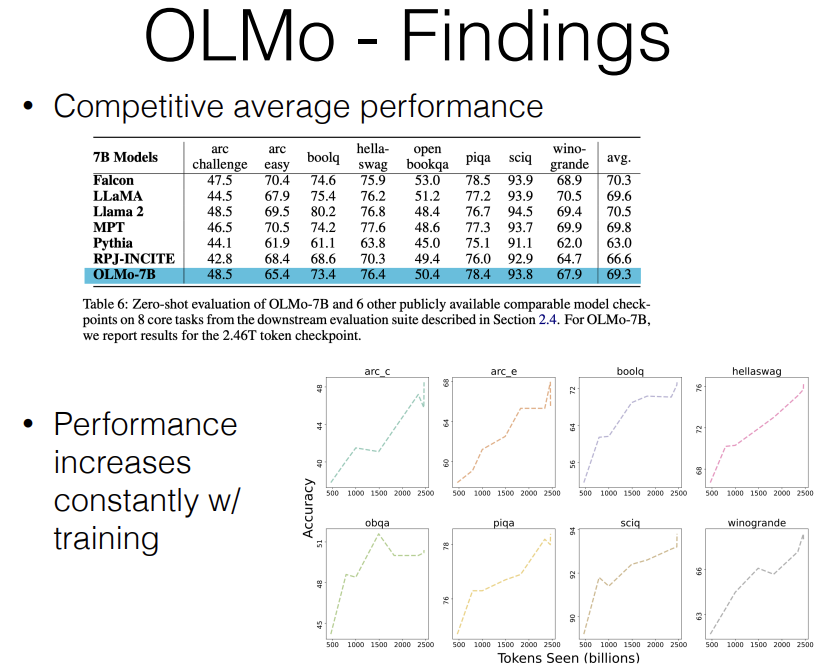
Some findings from OLMo that I found interesting, number one, it has competitive average performance. As I mentioned, this is the first fully open and documented language model on the 7 billion range that is competitive with all the other less open models in this range. For example, LLaMa2 is 70.5 average on all of the datasets that they're evaluating on. Falcon is 70.3, MPT is 69.8 and OLMo is 69.3. So it's not a slouch with respect to accuracy compared to Pythia which had 63.
Much of the issue with Pythia could just be that they didn't train for long enough and some evidence of this is where they measured performance constantly as they train for longer. So the left side is training on 500 billion tokens which is already more than what Pythia trained on, the right side is 2.4 or 2.5 trillion tokens and you can see interestingly that the numbers are just continuing to increase as they train for longer. So it seems that training for longer and longer just kind of helps.
One question is, whether they're overfitting to the dataset, like is any of the test data included in their training data here, they did de-duplication to some extent to try to remove the test data. So it's quite probable that these are real gains and if they train for longer, they might get an even better model. But I'm not 100% sure about that.
One other thing that I noticed which might be interesting is, all of these have a learning rate schedule. And typically they have a learning rate schedule where they do this standard warmup where they increase and then decrease, but they stop decreasing at a floor, and usually that floor is about 1 time the size of the original learning rate (3e-4). So if they start out 3e-4, they'll decrease it but only to 3e-2. That might be another good thing to put it out.

LLaMa2 is a model that probably most people have heard about, it was created by Meta, it's one of the strongest open language models now, although arguably there might be stronger open language models. And the goal is a strong and safe open LM, and they have base and chat versions of it.
Some unique features are, this is the open model with the strongest safeguards. If I were to pick one model that I wanted to use in an actual system that was directly conversing with users, I would probabily pick this one over something like Mistral even though Mistral shows superior performance some of the time, it might say things that you don't want it to be saying to like users. So I think that's one of the nice things about the model.
So I've been comparing everything else to it, that's pretty normal. One thing about the data is, the data is not open. They didn't say what data they trained on for reasons that I talked about before. What they did say is, it was trained on public sources up-samping the most factual sources. So that's what they said.
The LLaMa1 paper has more information, so I'll talk about what they did in the LLaMa1 paper, and we can maybe extrapolate that they did something similar in the LLaMa2 paper.
Total training amount is 2 trillion tokens. So that's actually less than OLMo.
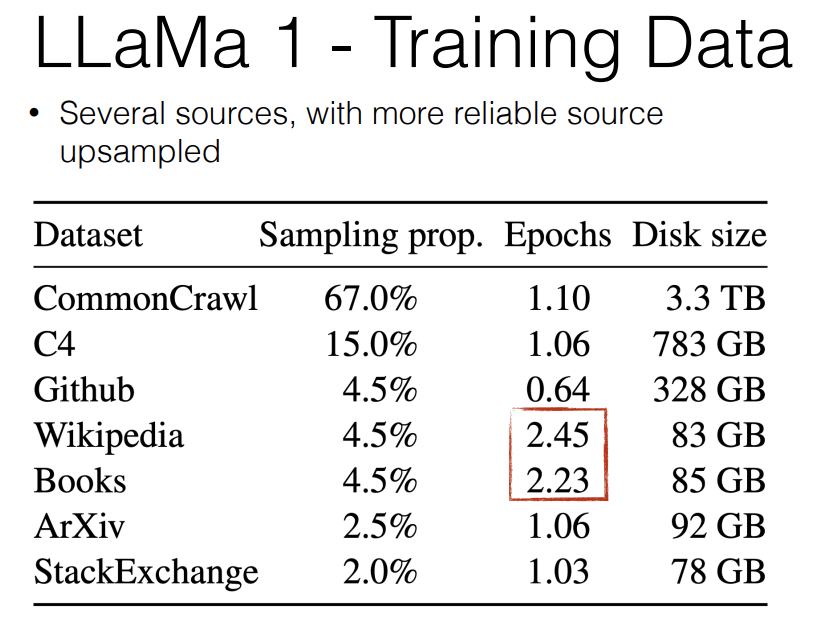
If we look at the LLaMa1 training data, it looks very much like OLMo training data. It's CommonCrawl, C4, Github, Wikipedia, Books, ArXiv, StackExchange.
And one thing you'll notice is that, they up-sampled Wikipedia and Books and down-sampled Github compared to the amount of data that they actually had. So they did 2.4 epochs over Wikipedia, 2.2 epochs over Books and only one epoch over the standard web data and ArXiv and StackExchange and 0.6 epoch over the Github data that they had. So obviously they thought that this Wikipedia and Books data was more valuable for some reason and they really wanted the model to learn well out it. So I think that they upsampled fatual data, I assuming that that's also what they did in mind.

Now I'd like to talk a little bit about the safety tuing that goes into the LLaMa models. The LLaMa2 developers put a lot of effort into training the model to be safe because they're a big company and they don't want any PR design disasters and also they want an actual safe model that they can use and to deploy their products. So I think they have the dual motivation there.
The first thing that they did was, they collected lots of data for reward modeling, and what they're calling "reward modeling" is, preference modeling, so they have multiple outouts where the two outputs are ranked for preferences.
A lot of these exist. So there's the Anthropic Helpful and Harmless datasets and OpenAI datasets from WebGPT, StackExchange they have helpful answers and not helpful answers, so one that you give thumbs up and thumbs down to.
And the Stanford human preferences dataset, this is where they tried to find Reddit posts that got more upvotes despite the fact that they were posted later than a previous one. So the idea is usually the first post get more upvotes, so if you get more upvotes for a later post, that indicates that you're probably more valuable than the earlier post, so clever way of creating data. I'm not sure what the Synthetic GPT-J data, I didn't look at that.
And then separately from that, Meta collected a very large amount of internal data that they didn't release for tuning LLaMa.
And they did this through various iterations. So what they did is, they created a first version of the model, they let it use loose on users, they also did some data collection with people who were actually trying to break the model and getting it to say bad things, they collected preference data from these people and then they iterated over and over again to collect more and more of these data on various versions of the model.
So as the model gets better, it's going to be harder to collect this data. But they want to try to improve the current model that they have.
So the next step that they did was, they trained a model to follow these preferences and so they trained a model that can predict human preference given language model outputs. And this is a hard problem because these are language model outputs. The language model thought it was a good output regardless because otherwise it wouldn't be sampling, so you need to distinguish between two very fluent looking outputs where one is preferred and one is not preferred.
There are some open reward models like this Open Assistant, is publicly available and you can go and download it if you want. But if you evaluate it on this Anthropic helpful and harmless dataset, this gets about 67 or 68 accuracy. If you evaluate the public models including GPT4 on the Meta dataset, actually it's pretty hard to distinguish between the things. Here they're evaluating both helpful and harmless or helpful and safety.
The reason why is, because it's very easy to create a very safe but not helpful at all model, by saying I don't know all the time. It's relatively easy to create a helpful model that's very unsafe like, it will do anything you want.
So they want to balance between the two and they evaluate them separately. They also created two different separate reward models. So they created one reward model to distinguish safety and another reward model to distinguish helpfulness. And they use these separately to train the model.
And you can see that the helpfulness model does a lot better on discriminating between helpful things, and the safety model does a little better on discriminating between safe and unsafe things.
They also have an interesting graph that demonstrates how good the reward models are based on their size and it turns out that, this is a place where it's really important to use a large and powerful language model to determine your reward. Because, they demonstrate that the 70 billion parameter model that they used is actually far better than the smaller models that they used it predicting this reward.
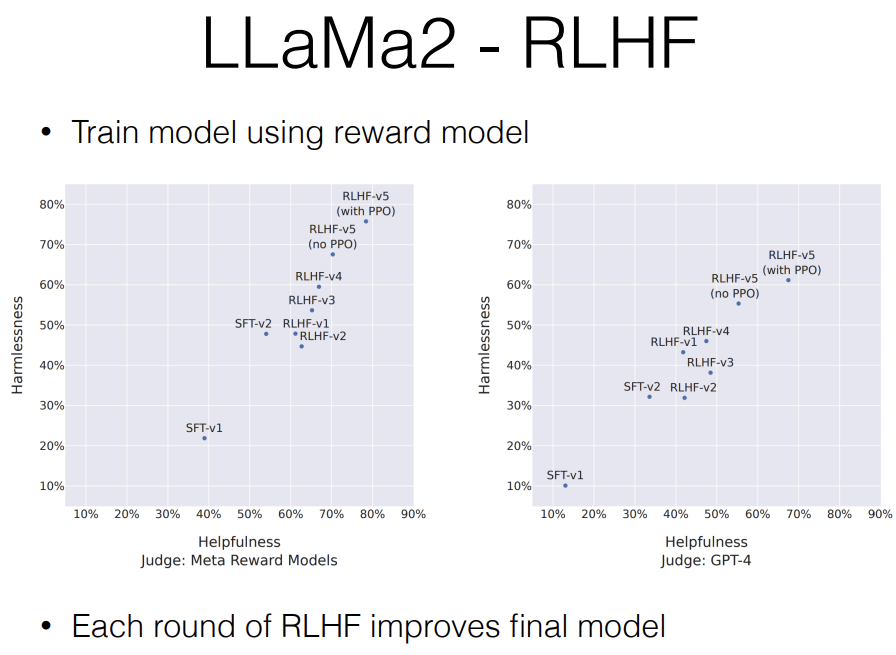
So this is a graph of their incremental training process for safety tuning. And you can see they have their first supervised fine-tuned model with no RL (SFT-v1), this is a second model (SFT-v2) and it improves a lot with respect to helpfulness. And then, they do more and more RLHF where they start with supervised fine-tuned model (SFT) and gradually add more reward data, train with a better reward model and get to the end where they finally have the best model. I believe this is the one that they actually released.
So you can see that they really put a lot of effort into making this model safe. And that's one of the main points of the paper that they had here.

Another interesting part of the LLaMa2 paper is, how they got it to follow Chat instructions. Prompting where they prompt the language model using a system message and a user message and an assistant message.
So the characteristic of the system message is, this is something that you want to be obeyed throughout the entire conversation. And in order to get this obeyed throughout the entire conversation, you need a model that's good at paying particular attention to the system message.
In this example, I'm saying "Write in only emojis." So you no matter how long this conversation gets, you want your model to continue writing in emojis and model don't do this spontaneously, so what they did here and I'm 90~95% certain that my interpretation of the paper is correct, the paper is a little bit hard to understand with respect to this, but what they do is, they take the system message and then they have a data generation step where they ask an existing model to "write in only emojis" and then "Say hello" and then the model generates something and then they say again "write in only emojis. How are you doing." and then they generate it again.
Because this is so close in the context, the assistant will be continue paying attention to these directions and then after that, now you have a dataset that you can train your model on.
You can train your model on this generated dataset that looks like write in only emojis "say hello", "how are you doing" and stuff like this, and they try this with a whole bunch of rules, like "write as if you're explaining to a 5-year-old" or "write in a very polite manner" or "write in very informal manner" and stuff like that.
So they generate a whole bunch of synthetic data and in doing this, they are able to train the model to pay very close attention to the system message because it needs to do so in order to do better.
So these are the unique characteristics from LLaMa2.
I'd love to tell you more about it's training data and all that other stuff, but they didn't tell us what they did with respect to that, so we'll just have to infer on. ^^;;;

Mistral and Mixtral. This is going to be a little bit short because they didn't tell you very much about the training process. It was created by MistralAI and it's a strong and multilingual open language model. It has some unique features like speed optimizations, including Grouped Query Attention and Mixture of Experts.
Unlike other ones, it makes some architectural modifications including sliding window attention and Mixture of Experts.
The data as far as I could tell was not disclosed very completely but one important thing is, it includes English and European languages. So at least theoretically it should be better than LLaMa at this. One interesting thing about LLaMa is, if I remember correctly the actual numbers are in the paper, but, it's something like 85% English, 8% code and then like 0.3% other languages, so it's not very multilingual at all. They were really only aiming to create a good English model.
Also the training details were not disclosed here I wasn't able to find the back sides as far as I know.
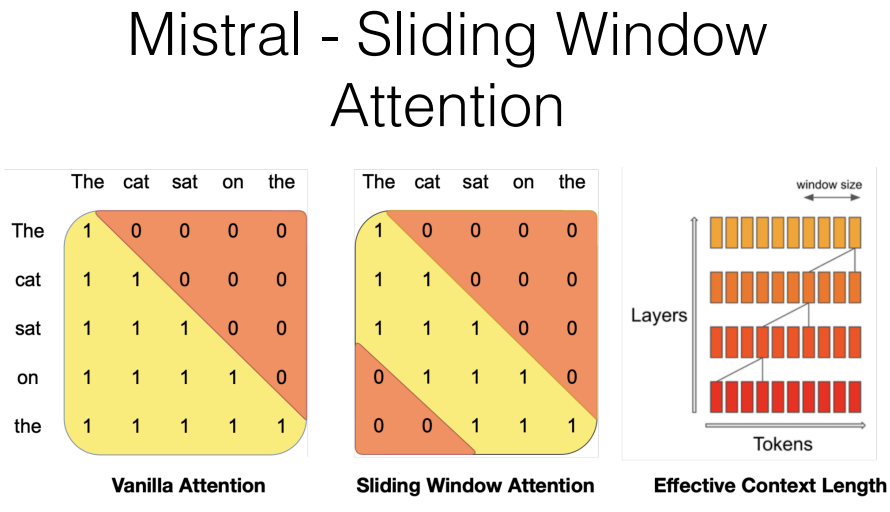
Mistral uses sliding window attention. Vanilla attention you always attend to all of the previous things in the sequence, what Mistral does is, it attends to the previous n examples where n is equal to 4096. What this means is, you can attend 4096 back and then in the next layer you can attend 4096 back then you can atend 4096 back. So as many layers as you have times 4096, you can attend that many tokens back for a minimal training penalty because still the length of attention for any particular token is the same. So that's one feature.
The other feature is, Mixtral is using a Mixture of Experts. These are very strong models, they're generally stronger than LLaMa at a lot of things. And Mixtral is a lot faster and easier to deploy than LLaMa 70B. It's smaller, it only has 45 billion parameters. So it's definitely a good choice if you want to use it.

Next I'd like to go into other models. First is Code Models. So code models are models that were specifically trained on code. Actually right now every model is a code model like nobody pre-trains a large language model and is serious about it and doesn't train on code because generating code is a huge use case and also some work has demonstrated that training on code seems to improve reasoning abilities of language models as well. But these models were very heavily trained on code.
We have StarCoder2, this is a very recent entry. This is a fully open model, so you can see the data it was trained on, all the training details are released and other stuff like that. So this is kind of in the Pythia, OLMo category. But it's a very strong model. So it's a good one to know about.
Separately, there's CodeLlama by Meta which is a code adaptation of LLaMa. It also gets quite a good performance.
There's also another model called DeepSeek Coder. I would say all three of these are topping some variety of leaderboard where DeepSeek Coder maybe is topping a few more learderboards than the other ones are. But all of them are very competitive and might be the best in class for code things.


Closed models, we don't know a whole lot about them. Most of what we know about them in their training data and other things like that is, conjecture.
The standard format for releasing in a closed model or not releasing but publicizing a closed model is people will write a blog post and they'll write a paper and generally what the paper does is, it only talks about evaluation. It only talks about how good the model is on various things, how safe it is, how they put a lot of effort into ran teeming the model so that it doesn't do bad things.
It tells you nothing about how they actually built the model, so mostly what I can talk about are capabilities as opposed to what actually went into the model.
There's GPT4. It's the de-facto standard strong language mdoel. It used to be the only strong language model and there were no real competitors to GPT4 from that point of view, I think still if I wanted a strong language model for just something that I'm going to do randomly I still trust GPT4 more than anything else to give me a really good answer.
But there are now other competitors I'd like to talk about.
So GPT4, it powers the pro version of ChatGPT, it was tuned to be good as a Chat-based assistant. It accepts image inputs. And it supports calling external tools through function calling interface.

이게 뭔가요!!?!?? Graham 교수님 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 진지하게 보다가 저항없이 터졌네 ㅋㅋㅋㅋ
아 진짜 한참 웃었네 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ

These are the kind of things that I now expect. So it's not just like reasoning ability and other stuff like that. It's also multimodality being able to generate code.

So it can do code generation and display the results for you. There are efforts to make open source language mdoels be able to do these things, and in order to do this, you need multimodality. You need also the ability to use tools. So actually the way that this (Table image를 JSON file로 변환) worked here is very different than the way that this worked (image 생성). So this is actually using a image input into GPT4. So what it's doing is, it's encoding the image and then feeding it in as tokens into GPT4.
What this is doing here is this is rather calling a tool. This is calling a Dalle3 as a tool and it's providing the caption to Dalle3. You can even see the caption that was provided to Dalle3.

So GPT4 what it did is, it said, it wanted to call a tool and then it provided the caption and then it called completely separate tool as an API in order to generate the image.

Because Open AI has become a standard, a lot of people want to compete with. Also I would say, Gemini and Claude are maybe the two models that can compete with GPT4 in terms of accuracy.
Gemini is much newer model by Google that comes in two varieties - Gemini Pro and Gemini Ultra.
One interesting thing about Gemini Pro is that, it supports very long inputs, 1 to 10 million tokens. It also supports image and video inputs and image outputs. I actually put a video into it recently, and the video recognition capabilities are pretty nice.

Finally, there's Claude3. It supports a context window of up to 200k. Also allows for processing images and overall has strong results competitive with GPT4.
So if you're looking for models to use to try out better closed models, you can definitely use these.
Another thing I'm really excited about is, how can we get open models to demonstrate some of the interesting capabilities that we see in closed models? So everyone can benefit and everyone knows recipes to make models lke this.
There is an interface called the GodMode that allows you to put all of the Chat Apps next to each other and write the same chat query into them and get the result from all of them. So you can compare all of them in an interactive settings. So if you want to look at all of the models, you can do that and log into all of your accounts and then press go on a query and see how they all this. That might be a good way to compare all of the models qualitatively.
'*NLP > NLP_CMU' 카테고리의 다른 글
Complex Reasoning (0) 2024.07.11 Code Generation (0) 2024.07.10 Ensembling & Mixture of Experts (0) 2024.07.08 Reinforcement Learning from Human Feedback (0) 2024.07.08 Quantization, Pruning, Distillation (0) 2024.07.07