-
Code Generation*NLP/NLP_CMU 2024. 7. 10. 13:04
※ Summaries after taking 「Advanced NLP - Carnegie Mellon University」 course
https://www.youtube.com/watch?v=bN2ZZieBXsE&list=PL8PYTP1V4I8DZprnWryM4nR8IZl1ZXDjg&index=16
https://phontron.com/class/anlp2024/assets/slides/anlp-17-codegen.pdf

I'm going to be talking about code generation and this is a research topic that I've worked on for a long time, now I like a lot it's become very useful nowadays which is very exciting. So I'd like to talk about some of the basics and frontiers that we're working on right now in this general area.
Before I get into code generation specifically, one thing I'd like to point out is, for the next classes, I'm going to be talking about tasks and up until now I've been focusing on a lot of general things that weren't as much about any specific tasks. I'm going to be covering various things about different tasks and hopefully you can map the same questions onto whatever task you are interested in.
So what I want to talk about is, the task objective like why do we do that task? why is it important? what datasets can we use to train or test our models on these tasks? Evaluation metrics, how do we evaluate both manually and automatically with respect to how good we're doing? and finally, models and methods. How do we solve the problem?

And so for code generation first, I'd like to talk about the overview and objectives for code generation.

Code generation is the task of generating executable code as an interface to a program or to computers and there's a lot of different ways we can do this.
Why do we want to do this? The first thing is that, software engineering is really important and being able to generate code accelerate software engineering. Now code generation is practical and I hope that everybody in the class is using some sort of code generation to accelerate your own workflow. If you are not, I highly encourage you to try it, because it's very useful.
Second, it also does things like enabling models to access tools. Even if you're not specifically working on a software related task, this can be helpful. I want to talk about this when we talk about LLM Agents.
Even if you're not using code at all, training on code has been shown to cause some benefits to leaning models specifically with respect to learning like difficult mult-step reasoning tasks. So that's another reason why you might want to worry about codes.

For this task, our input is some sort of specification of what we want to do and our output is going to be code. So when you write a program, how do you describe the thing that you want to implement in the program before you implement it? like what are some of the specifications that people can give you?
Natural language, Code context, Inputs and outputs, Screenshots.


I think Github Copilot and Claude3 or GPT4 serve very different purposes. Github Copilot is code completion and it mostly works for shorter things so it's like your next thought in your code that you know pretty well. Claude or GPT4 is much better for really long things where you want to build a full class or something like that.
I also have found that if you're coding in a language that you're very familiar with, copilot might be more useful because you want fine-grained control and you want it to fill out things to make it faster whereas if you're coding in a language that you're not very familiar with, something like Claude is good because you can write a whole program.
So these are the differences. Another thing is Github copilot needs to be frighteningly fast because it needs to move at the speed that like programmers are thinking in programming next, whereas something like Claude, it doesn't using it in the way that.
I use Claude here, doesn't really matter because I can say, programming me a web app and then I can go and have dinner and come back and have a web app and I'd be perfectly happy with that. So the latency request are also different.

This was a study that was run by Github shortly after copilot came out. Why do we do code generation? Why are people very excited about it? So the first is, making software is important and I recently calculated what from some labor statistics and the total amount that software developers make in a year is 175 billion dollars. So it's very high value profession. So if we could make it faster, it would have even more value.
Another thing is, code generation leads to large improvements in productivity. So Github ran this study where they randomly assigned developers to groups who would either use copilot or not use copilot and they assigned them the same task and the people who use copilot, their rate of completion went up by 8% and they finished in about 40% of the time of the people who didn't use it. So I think this is, they say 55% less times. So this is very impressive but it's also not at all surprising if you're using coding assistant. It just makes you code faster.
Also if you don't like writing docstrings, it's really good at writing docstrings. So you can write documentation for your code.

There are differences between code and natural language. And I've listed a few of them here. And the differences between code and natural language also affect how we build models for this task.
First one is that code has strict grammar. If you make a small mistake in your code grammar, usually it will just break and your program won't work. So you need to be very careful as opposed to natural language grammar whre you can make small mistakes and it doesn't make a difference.
Another thing is, in code, you know the semantic flow of the code and so we know that certain variables correspond to each other. We know that they're flowing through the program in a certain way.
Another thing is, code is executable so we can actually execute it and observe the result unlike in natural language.
And another important thing is, code is created incrementally. So unlike text, text is also created incrementally but it's not usually. You write it once, you might revise it a little bit and then you're done, you don't need to touch it again. But in code, you touch it over and over and over again as you develop a project.


The most famous dataset for a code generation nowadays is something called HumanEval. This is a very nice dataset for a number of reasons. I think it is used too much nonetheless, and I think there are better datasets that we maybe should be using more.But basically HumanEval has examples of usage of the Python standard library where some are easier, some are harder.
One thing about this, that's important to know is, it only has 164 examples. So it's actually a relatively small number of examples. It's also just the Python standard library. So it's not testing usage of any other libraeis. So these two things together make it not the most realistic. Examination of your programming skills just like leet code is not the most realistic examination of your programming skills.
Then we go into the inputs and outputs. The inputs and outputs usually include a docstring, some input and output exmaples and then they have tests to verify the accuracy of your outputs.

So the metric that's used to evaluate these systems is something called Pass@K and the basic idea is, if we generate K examples, will at least one of them pass the unit tests.
There's a couple reasons why we would care about this. Pass@one is obvious because we generate one and then we measure how likely it is to pass unit tests, but pass@five, why would we care about pass@five? Number one, maybe you could show five programs to a person and they could choose the one that they like the best or maybe you could write unit test in advance and then generate five programs, check which one pass the unit tests and then use the one only that pass the unit test.
So there's also some interest in whether you could generate multiple examples and then pick a good one. There's a little bit of nuance in how this is actually calculated. So if you generate only K and sample only one example, there's a lot of variance in whether you get it right or not. So what they actually do is, they generate 10 outputs or 200 outputs and then they calculate the expected number of cases that would pass by doing a little bit of math calculating the number of combinaitons where one passes or one doesn't.
LLMs are good at code because they intentionally include a lot of code training data in LLM training and the reason for that is twofold. The first one is that, code generation is huge application of LLMs right now and if you had an LLM that couldn't do code generation, it would be embarrassing, so everybody includes this. Number two, code has been shown to improve the reasoning abilities of LLMs and because of that, people include code for that purpose. So it's not that LLMs are inherently good at code. It's that they have lots of lots of code training data. And I'll explain how they construct this. And the Pile is almost half those.

A first improvement or at least change that we can make to HumanEval is going to broader domains and covering a broader variety of libraries. And this is a dataset we created a long time ago but we recently added execution based evaluation to it.It's called CoNaLa and execution based evaluation one is called ODEX. What we did here is, we scraped data from StackOverflow including inputs and output solutions and then based on this scraped data, we did some manual curation to turn these into actual questions and answers about how you could solve programming problems.
Because this is scraped from StackOverflow, there's no restriction that. This is from the Python standard library which also means that it can cover a very wide variety of libraries and it's approximately according to the popularity of the libraries because we took popular posts. So that's a good thing. It is a reasonable way to come up with a realistic distribution of libraries that you should be looking at.
ODEX adds execution based evaluation. Previously what we had was, we only had the snippet that was able to solve the problem as opposed to being able to execute unit tests.
Just to show how this has a broader variety of libraries, On the top, we have the distribution of ODEX libraries and we can see about half of them use libraries and this includes a variety of things including Pandas, Numpy, regex, os, collections, all of these should be libraries that look familiar to you. In contrast if we look at HumanEval, almost all of the questions require no libraries and all of the other ones require libraries that were included in the python standard libraries. So in reality, this is probably more what your program are going to look like.

Originally when we did CoNaLa, we didn't use execution based evaluation. Because creating unit tests for lost of StackOverflow posts is hard. Specifically there's two issues.
The first one is that, it requires that code be easily executable. Now think about how you would do that for Matplotlib for example, how would you create a unit test to test whether Matplotlib successfully created a bar chart or something? It's tough.
So actually coming up with realistic unit tests for real programs can be difficult. Another problem with execution based evaluation is, it ignores stylistic considerations. So I could write very spaghetti code and as long as it executed properly, it would still be judged as correct and sometmes that's actually an issue. So usually it's not a problem because language models write reasonably good code but sometimes you want to match the styles.
So some alternatives are BLEUScore. It's calculating the n-gram overlap between a gold standard human implementation and the system output. There's specifically adapted methods for evaluating code and so there's a method called CodeBLEU.
The way CodeBLEU works is, it also considers the syntax and semantic flow of the code. So it measures overlap between strings in the original code but it also considers overlap between the syntax trees of the code and whether these semantic information flow graphs look similar. So all of these things work together to calculate the CodeBLEU score.
One thing I should mention is, how do we get these syntax trees in the first place?
-_-; 제 말이요.. syntax tree는 갑자기 어디서 나오나요..? ㅋㅋㅋ
For example, if we're talking about python, there's a Python ast library for abstract syntax tree. It's just part of the standard library and it's necessary to run the Python interpreter. So you can just get these trees directly from the Python ast library. Not hard to do.
헉. 생각보다 쉽게 가능하네융..! ㅎㅎㅎ 우왕
One disadvantage of BLUE and CodeBLEU is that, you can write two very different looking programs that actually are both correct and BLEU will underestimate the goodness of those programs. So maybe using both of them together is appropriate if you can write unit test.

There's also CodeBERTScore. It's basically an embedding based metric to compare code.What BERTScore did is, it calculated the cosine similarity between each of the tokens for a generated text and a reference text. We do the same thing for code. So we calculate the cosine similarity between tokens for a reference code and generated code.
And we released a model called CodeBERT which was BERT but continued trained on lots of code that allowed us to do that and we were able to demonstrate that this gave better correlation both with final execution accuracy and with human judgements of whether the code was correct, some people created a dataset of human correctness judgements and we were able to put a little better with that as well.
Why do we care about correlation with execution accuracy? This is important in the cases when we can't create unit tests or when creating unit test would be too expensive. So this gives us a better approximation for what we would get if we ran tests.

Another place where code generation can be useful, we had the example of colab notebooks and this or data science notebooks, this paper was by Google. So this might even be used in the colab thing because colab is a Google thing. But data science notebooks allow for incremental implementation. I'm sure a lot of people here or almost everybody here uses them.
Another interesting thing is, allow for evaluation of code generation in context or incremental code generation and you start out with like a notebook and then you have natural language command and you generate the output etc etc. So this is an actual example from the dataset.
So this paper is very nice. It's nice dataset.

One other thing that was really interesting from this paper is, it demonstrated the problem of data leakage in evaluating models. And this is a relatively large problem, I don't know if we have a silver bullet solution for this, but it's an important thing to be aware of not just for code generation but these are examples from code generation.So here in the ARCADE dataset, they both evaluated existing notebooks that they got from the web and they evaluated notebooks that they created themselves. And there's very very stark difference between the notebooks that were created on the web and the notebooks that they evaluated themselves.
So most of the code generation models except for Palm, which was the best model when they created this dataset, did really well on the existing data and quite poorly on the new data, which is probably an indication of the fact that, this is to some extent leaked into the training data of the language models.
There was very recent paper, this might be 2024, that did a similar thing where they evaluated on HumanEval and then their LiveCodeBench. LiveCodeBench, what they did is, they tried to pick problems from leetcode and other websites that were more recent versus less recent, and they have some nice graphs in their paper where they demonstrate that the less recent ones before the training cut off have a high accuracy and then suddenly it drops right at the training cut off. So this is something to be aware of.





Code generation has some unique things. The basic method that you can always use is a code generating LM. So you feed in previous code or you feed in whatever context you have into the LM and you generate from it. And virtually all serious LMs are trained on code nowadays.One important thing here is, when you're generating something like code generaion, I definitely suggest that you modify your temperature settings appropriately and set it to a low temperature. Otherwise, you'll get kind of crazy code, but if you set it to a low temperature, you can get better anyway.

One really core capability of code LMs, especially ones that you use in your IDE like Copilot is, infilling. What you want to do often is, you have previous code, you have next code and you want to just fill in like a line that's missing, like you want to add an extra if statement or some sort of modification.
So the way that at least this paper proposed it and the way that I think most LMs are actually doing this is, they take a standard left to right LM and what they want to do is, they want to infill this code chunk and so what they do is, they put a mask in the place where they want to fill the chunk which would also be where your cursor is in your IDE at that point. And then, they have MASK: 0, and then at the end they put MASK: 0 again, and then they output all of the code that you want to generate there.
So you can arbitrarily generate these chunks by masking out chunks, putting in the mask token and then moving it to the end of the sequence and then you can just use a standard left to right autoregressive language model to solve this problem.
This is really important if you want to build like a copilot style thing and all of the code language models that I talk about use this technique.

Another thing is, there's lots of available informaiton for learning coding thing, or for solving coding tasks, this includes the current code context, description of the issue that you want to be fixing like if you're solving a full request, repo contxt from other files, what tabs you have open, so that's also an important thing.

When Github copilot came out, they didn't really tell you the details of how they were doing this. But Github copilot is written in JavaScript and there was a Master student from Georgia Tech took the JavaScript and diminifed it, like reverse engineered what was actually happening and wrote a blog about it. This blog is great. ^^;; 멋지다 ㅋㅋㅋㅋ
So what copilot was doing, which also gives you a gold standard way of looking at what kind of information is necessary to create a good model is, first they extract informaiton from the prompt given the current document and the cursor position, so they take the current document, where is the cursor and what is before this, and what is after this.
They identify the relative path of the file and what language it's in. So they identify Python files or JavaScript files or whatever.
They find the most recently accessed 20 files in the same language so like if you've opened 20 tabs, they keep track of which tab you had open.
And then the actual prompt that they send over includes text that is before, text that's after, similar files out of the 20 files that you've opened recently, also information from improted files and metadata about the language and the path.
So all of these are sent to the model and it's really good prompt engineering. They're figuring out a good way to get all of the information that would be useful for getting this model to work into the prompt.
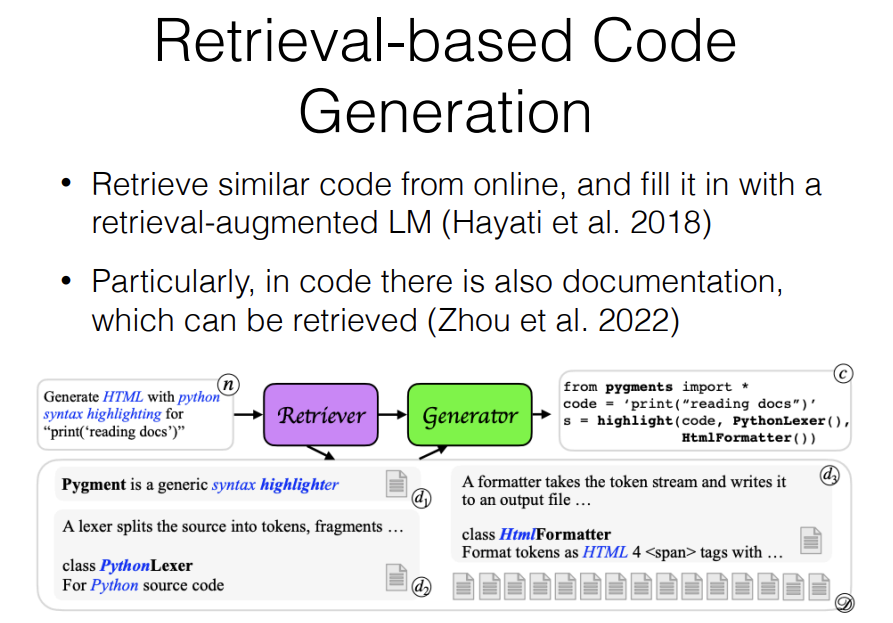
Another thing that you can do is Retrieval-based code generation. Retrieval-based code generation, what it does is, it's like RAG for code generation. This has been around for a while including our work that I cited here and a few more in 2018 and so one way you can do this is, you can retrieve similar code from online and then use it to prompt a retrieval augmented language model.
This is good if you have a model that's not super good at code in the first place or it's making mistakes.
It's also good if you have a large code base like that's internal and the language model was not trained on it but you still want to use that code base for code generation, So it's really good if you're working at like a big company for example that has a very constant coding style but hasn't trained its own LM.
Also particularly, in code there's also documentation which can be retrieved. We have new libraries all the time, and one frustrating thing when using ChatGPT or Claude when you're writing programs is that, it can use old versions of libraries that are no longer compatible.
So in this paper, we called it Doc prompting. The idea is that, you have your natural language input and then you look up similar documentation. Then you can append that to the prompt and then have that generate output. We demonstrate that this is good both in general but also it's particularly good when you're dealing with new libraries that haven't been seen before or libraries that have been updated.
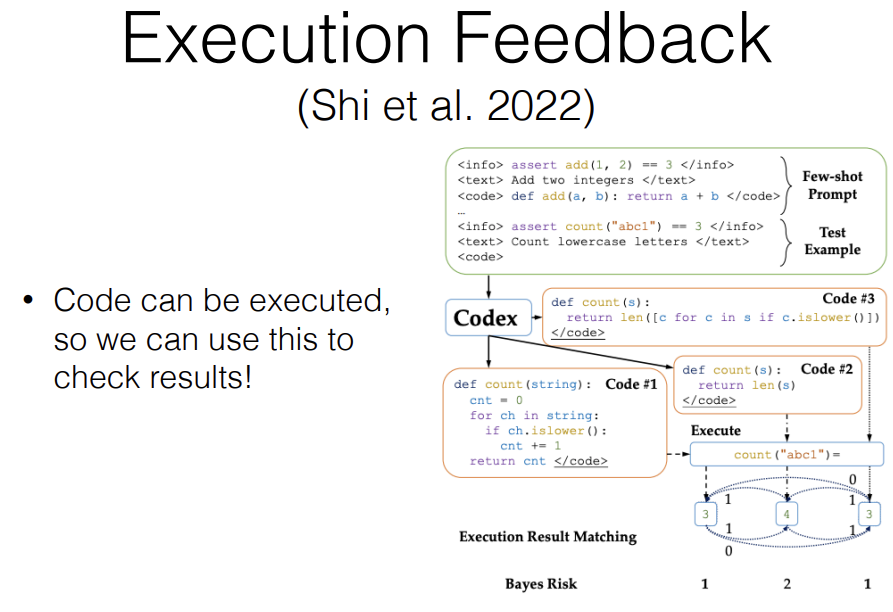
Another thing that you can do with code that you can't do easily with natural language is execution feedback. This is a paper where they do something that's rather simple but they generate multiple instances of code, so they sample different varieties of code and I was talking about like Case@K before, Case@K is good if you have some way to confirm which output is correct like you already have unit tests and you can run the unit test and identify which one passes the unit test or you can have a human check it.
But in the case when you can't do that, what can you do is, you can execute all of the code snippets that the model generated and check if the outputs overlap each other. If you have 30 programs that all generate very similar outputs then those outputs then, that program is probably correct. And then you can just pick one of them according to some criteria. Specifically in this case, they picked the program that has the lowest Bayes risk. They execute a lot and then calculate the Bayes risk of that.

Another interesting thing is there's several lines of work on fixing based on error messages. The idea is, you generate code, you try to run it, you get an error message from it, and then you feed that back to the LLM in order to correct the error. LLMs, if you give them an error and you give them buggy code, they do have some capacity to do that especially as you get stronger LLMs. So this is a nice paradigm.
This paper InterCode actually generalizes this a bit and it's more recent that's why I cited it here. This also says you can do single turn code generation. You can also say could you please try again? You can also do planning and solving. This is a good environment if you're interested in making these more like interactive coding assistance.


Finally, I'd like to talk about code LMs and I'm going to go through about four of them. Actually what I should mention is, all of the LMs that I talked about up until this point are code LMs because every LM trains on code. So I'm mainly going to be talking about one specifically for code this time.
Codex is the first and first really big impact code LM. It was created by OpenAI. I don't know about the deployed model now because they don't release the details of it but this was trained by continued training from GPT3, so they had a text LM and then they just continued training it on lots and lots of code from Github. So the data was lots of data from Github.
Importantly, it still powers Github Copilot. One interesting things is, they had a large version of Codex and then they had a smaller version of Codex called Code kushman, and the thing actually powering Github Copilot is not the largest version, it's not Code Davinci, it's Code kushman which is smaller and much faster.
The reason why is probably twofold. Number one, you need really fast responses when you're working on code and there's actually in Copilot, some cache and other stuff like that to make your responses very fast as well.
The second reason is probably it's just be too expensive for them to run DaVinci over all the code bases for how much they're charging you for Copilot. Like every single time you change something in one of your files, if you're using Copilot, it's rerunning in LLM and that would become very expensive if you look at the token count. So I think they're using a smaller model because of that. But nonetheless it's very good.

Now I want to get into some more modern mdoels, the first one I want to get into is StarCoder2 and the reason why I want to talk about this first is, because not necessarily that it's like absolutely the best one although it's very good but it's one of the models that actually tells us everything about their training data and training process. So we know everything about them.
The creator of this was the Big Science project which was led by HuggingFace and Service Now and includes lots and lots of people from various universities and things. 멋지다 ㄷㄷㄷㄷ
The architecture is mostly LLaMa style. It has 3B, 7B and 15B variants.
One interesting thing about all code LMs is that they all do longer context, and they all reconfigure RoPE for longer context specifically. RoPE has a theta parameter that allows you to tell how long the sine waves, and they all always change the parameters so that the context is longer. So that's another good thing to know about.
The training data section of this paper is really fascinating. It's a really good way to look at how much data enginerring goes into making a good model.
Just very shortly they give a lot more detail in the paper, but it's trained on code including the stack which is a huge amount repository of code that I'll talk about, separately from that, it was trained on Github issues, it was trained on pull requests, jupyter notebooks, Kaggle notebooks, documentation, intermediate representations from LLVM, so LLVM is intermediate compiler style thing that is used fo compiling code and it was also trained on a few code relevant natural language datasets.
For pre-processing, they do something pretty interesting which is they add metadata tags such as the repo name and the file name and other stuff like this, 50% of the time. They do this 50% of the time because they want the model to work with them but also be robust without them. So you can either add them or not add them at test time.
And they also do infilling. Every serious code LM does infilling based training.
One interesting thing about this from the training perspective is, they actually trained it for four to five epochs which is much more than we normally do. So normally we only train for one epoch over all of the data we have. But here, they were training for longer and that's just because the amount of data they can get for code is less than then amount of data they can get for all the natural language.

So the dataset they created is the Stack2 and this is a code pre-training dataset. One interesting thing that they thought about was, license considerations. So I talked about how copyright is a problem when trading large language models, and here they specifically tried to find things with permissive licenses and so what they did is, they looked at the license on Github and if the Github license was permissive, they marked it as permissive then they tried to detect licenses and then if all of them were permissive, they marked it as permissive. This is a huge table that they have in the paper of all of the data that they have.

CodeLLaMA is another competitive model. It came out a little bit before StarCoder and StarCoder2 and DeepSeek Coder. This is created by Meta.
The architecture is the same as LLaMa2. They did continued training from LLaMa2, but they trained it on longer input contexts and they also extended the length of RoPE. So those are standard things for code language models.
It was trained on deduped code and also synthetically created instruction data. So they created instruction tuning data specifically for code.
The training was incremental with various datasets and what I mean by this is, they trained on 500 billion tokens of code and then they did long context fine-tuning on 20 billion tokens and then they also did instruction tuning.
They also have Python specific one, and the reason why they have a Python specific one is not because Python is more important necessarily, but because a lot of the Benchmarks are in Python because machine learning people like who are creating benchmarks they also like Python. So Python is more common in the benchmarks. So they wanted to do well on the benchmarks I think, and created a dataset that does well in the benchmarks. If you are creating Python, you can use the CodeLLaMA-Python, it's better at Python.

Final one I'd like to talk about is, DeepSeek Coder. This is notable because it's a very strong model. It's maybe the strongest model on aveerage over all the code models. They did 87% source code, 10% English from Markdown and StackExchange, and 3% Chinese Because it's from a Chinese company.
Architecture is pretty standard. It's LLaMa like with 1.3 billion, 6.7 billion and 33 B variants.
And they trained on two trillion tokens.

So then a question becomes, which one to use? I created a summary here. All of them have somewhat similar performance. They're compared in the StarCoder2 paper, so you can go in and look at details.
DeepSeekCoder seems to be strong on standard programming tasks, whereas StarCoder seems to be strong on data science notebooks.
All of them are good models, all of them are not quite as good as like GPT4, Claude on more complex tasks but they're available and you can find them and do other things as well.
'*NLP > NLP_CMU' 카테고리의 다른 글
Complex Reasoning (0) 2024.07.11 Large Language Models (0) 2024.07.09 Ensembling & Mixture of Experts (0) 2024.07.08 Reinforcement Learning from Human Feedback (0) 2024.07.08 Quantization, Pruning, Distillation (0) 2024.07.07