-
Revisiting Rainbow*RL/paper 2025. 8. 30. 09:26
너무너무 고마운 paper ♡
우선, Rainbow가 Deep Q-learning의 다양한 innovations를 조합하여 performance를 boosting하는 방법을 제시하여 주었다면,
본 논문은 실제로 다양한 experiment를 가능하도록 해준다.
Rainbow에 국한된 것만 아니라, RL 전반에 있어서 empirical research를 어떻게 해야하는지를 알려준다.
이건 중요한 문제인데,
왜냐하면
그간 RL algorithm을 공부하면서, 물론 재미는 있지만
'과연 내가 이걸 실험해볼 수 있을까? infeasible하다면, 공부하는 게 의미가 있긴 한건가? -_-;' 하는 생각을 했기 때문이다.
써먹을 수 없다면 애써 공부한 게 뭔 소용이람?
Deep RL이 발전해온 흐름에 맞추어 공부를 하다보니, 거의 DeepMind와 Berkley 양대 산맥으로 발전이 이루어져 오는 걸 깨달았는데,
워낙 실험의 규모가 넘사벽이라
정작 paper 후반부의 empirical results part에 이르러서는, experimental setting에 집중이 되지가 않았다.
와닿지가 않는달까?
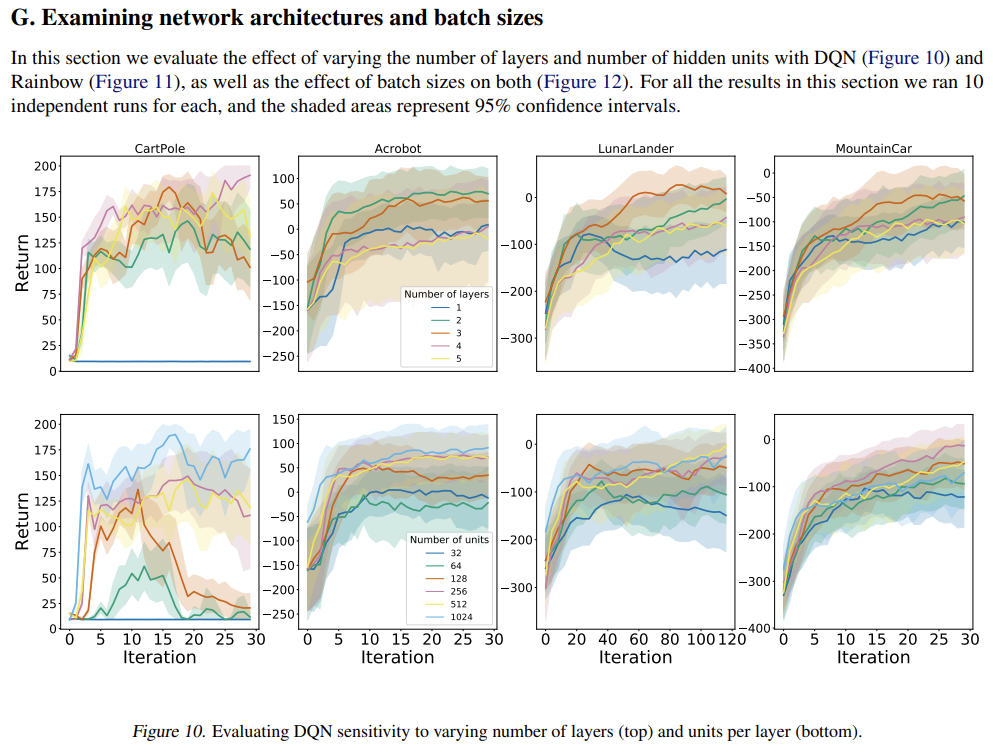
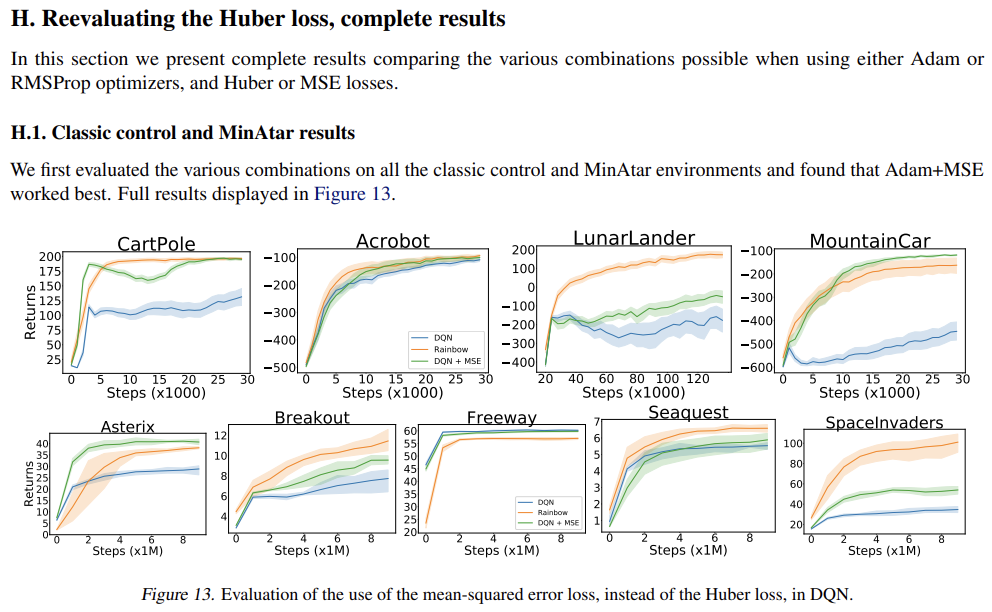
근데 본 논문에서는 이러한 문제점을 지적하면서, small-, med- scale setting의 experiment를 전개한다. 그리고 이러한 environment에서도 valuable insight를 얻을 수 있다는 걸 보인다.
또한 내가 DeepMind, Google paper를 좋아하는 이유인 (굉장히 교과서적으로 잘 정리함) 기본적인 theory와 rainbow를 구성하는 extension들의 algorithm을 다시 정확하게 톺아 준다.
결정적으로!
rainbow 원 논문에서는 Distributional RL의 첫 번째 방법인 C51를 적용하였는데,
사실 Distributional RL의 찐 (?)은 두 번째, 세 번째 (Quantile regression, IQR)이라서, 이걸 적용해야 하지 않을까?했던 나의 바람대로,
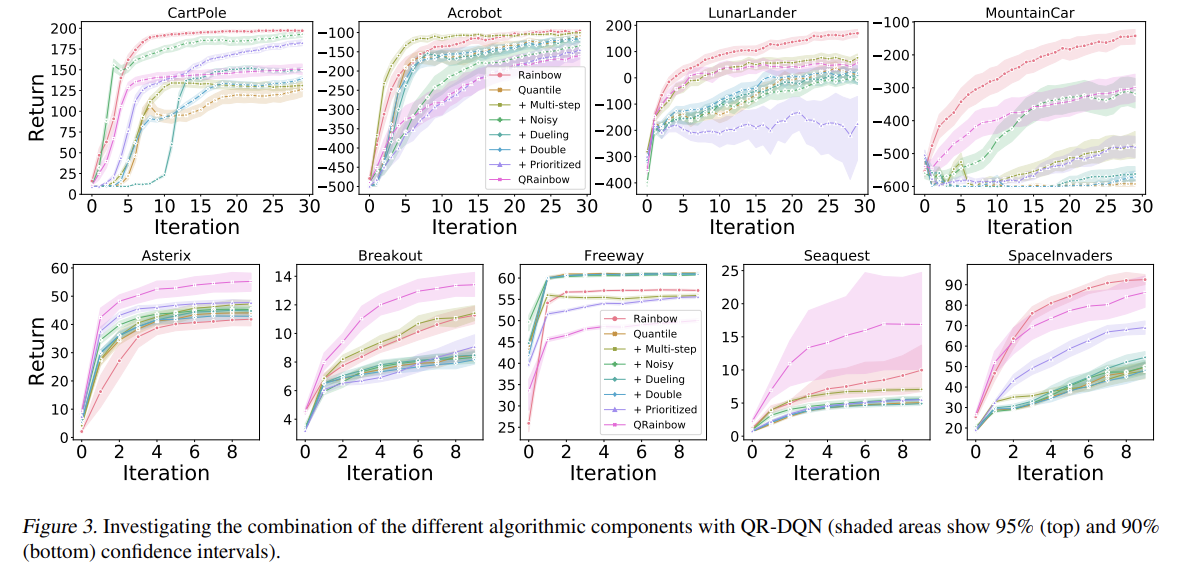
본 논문에서는 QR, IQR 을 적용하여서 sota를 보여준다. (역시 추측이 맞았어!)
(물론 모든 environment에서 performance gain이 있는 건 아니다. 논문 역시, Distributional RL이 gain을 얻을 수 있는 environment에 대한 analysis가 필요하다고 말하고 있다.)
※ Code
https://github.com/johanobandoc/revisiting_rainbow
GitHub - johanobandoc/revisiting_rainbow: Revisiting Rainbow
Revisiting Rainbow. Contribute to johanobandoc/revisiting_rainbow development by creating an account on GitHub.
github.com
※ Environments
* OpenAI environments
https://github.com/openai/gym/wiki
* MinAtar
https://github.com/kenjyoung/MinAtar
※ Reference
* Munchausen Reinforcement Learning
https://arxiv.org/pdf/2007.14430









































'*RL > paper' 카테고리의 다른 글
(2/3) Offline RL (0) 2025.08.30 (1/3) Offline RL (0) 2025.08.30 Rainbow (0) 2025.08.29 (on-going) Distributional RL (0) 2025.08.29 Model-based Reinforcement Learning (0) 2025.08.25