-
[RevNets] The Reversible Residual Network: Backpropagation Without Storing ActivationsResearch/Generative Model 2024. 5. 15. 22:30
https://arxiv.org/pdf/1707.04585
Abstract
Deep residual networks (ResNets) have significantly pushed forward the state-of-the-art on image classification, increasing in performance as networks grow both deeper and wider. However, memory consumption becomes a bottleneck, as one needs to store the activations in order to calculate gradients using backpropagation. We present the Reversible Residual Network (RevNet), a variant of ResNets where each layer’s activations can be reconstructed exactly from the next layer’s. Therefore, the activations for most layers need not be stored in memory during backpropagation. We demonstrate the effectiveness of RevNets on CIFAR-10, CIFAR-100, and ImageNet, establishing nearly identical classification accuracy to equally-sized ResNets, even though the activation storage requirements are independent of depth.
1. Introduction
Over the last five years, deep convolutional neural networks have enabled rapid performance improvements across a wide range of visual processing tasks [17, 24, 18]. For the most part, the state-of-the-art networks have been growing deeper. For instance, deep residual networks (ResNets) [11] are the state-of-the-art architecture for a variety of computer vision tasks [17, 24, 18]. The key architectural innovation behind ResNets was the residual block, which allows information to be passed directly through, making the backpropagated error signals less prone to exploding or vanishing. This made it possible to train networks with hundreds of layers, and this vastly increased depth led to significant performance gains.
Nearly all modern neural networks are trained using backpropagation. Since backpropagation requires storing the network’s activations in memory, the memory cost is proportional to the number of units in the network. Unfortunately, this means that as networks grow wider and deeper, storing the activations imposes an increasing memory burden, which has become a bottleneck for many applications [32, 35]. Graphics processing units (GPUs) have limited memory capacity, leading to constraints often exceeded by state-of-the-art architectures, some of which reach over one thousand layers [11]. Training large networks may require parallelization across multiple GPUs [7, 26], which is both expensive and complicated to implement. Due to memory constraints, modern architectures are often trained with a mini-batch size of 1 (e.g. [32, 35]), which is inefficient for stochastic gradient methods. Reducing the memory cost of storing activations would significantly improve our ability to efficiently train wider and deeper networks.
We present Reversible Residual Networks (RevNets), a variant of ResNets which is reversible in the sense that each layer’s activations can be computed from the next layer’s activations. This enables us to perform backpropagation without storing the activations in memory, with the exception of a handful of non-reversible layers. The result is a network architecture whose activation storage requirements are independent of depth, and typically at least an order of magnitude smaller compared with equally sized ResNets. Surprisingly, constraining the architecture to be reversible incurs no noticeable loss in performance: in our experiments, RevNets achieved nearly identical classification accuracy to standard ResNets on CIFAR-10, CIFAR-100, and ImageNet, with only a modest increase in the training time.
2. Background
2.1. Backpropagation
Backpropagation [23] is a classic algorithm for computing the gradient of a cost function with respect to the parameters of a neural network. It is used in nearly all neural network algorithms, and is now taken for granted in light of neural network frameworks which implement automatic differentiation [1, 2]. Because achieving the memory savings of our method requires manual implementation of part of the backprop computations, we briefly review the algorithm.
We treat backprop as an instance of reverse mode automatic differentiation [22]. Let v1, . . . , vK denote a topological ordering of the nodes in the network’s computation graph G, where vK denotes the cost function C. Each node is defined as a function fi of its parents in G. Backprop computes the total derivative dC/dvi for each node in the computation graph. This total derivative defines the the effect on C of an infinitesimal change to vi , taking into account the indirect effects through the descendants of vk in the computation graph. Note that the total derivative is distinct from the partial derivative ∂f /∂xi of a function f with respect to one of its arguments xi , which does not take into account the effect of changes to xi on the other arguments. To avoid using a small typographical difference to represent a significant conceptual difference, we will denote total derivatives using vi = dC/dvi .
Backprop iterates over the nodes in the computation graph in reverse topological order. For each node vi , it computes the total derivative vi using the following rule:

where Child(i) denotes the children of node vi in G and ∂fj/∂vi denotes the Jacobian matrix
2.2. Deep Residual Networks
One of the main difficulties in training very deep networks is the problem of exploding and vanishing gradients, first observed in the context of recurrent neural networks [3]. In particular, because a deep network is a composition of many nonlinear functions, the dependencies across distant layers can be highly complex, making the gradient computations unstable. Highway networks [27] circumvented this problem by introducing skip connections. Similarly, deep residual networks (ResNets) [11] use a functional form which allows information to pass directly through the network, thereby keeping the computations stable. ResNets currently represent the state-of-the-art in object recognition [11], semantic segmentation [33] and image generation [30]. Outside of vision, residuals have displayed impressive performance in audio generation [29] and neural machine translation [14], ResNets are built out of modules called residual blocks, which have the following form:

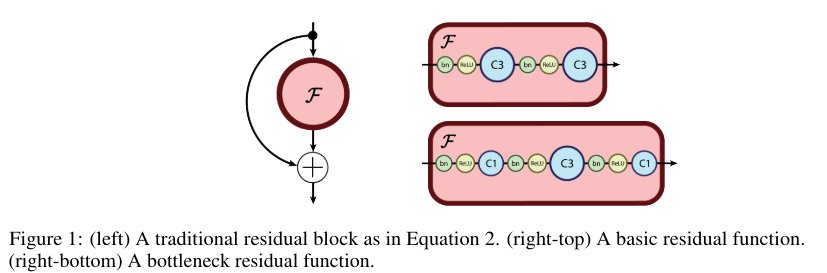
where F, a function called the residual function, is typically a shallow neural net. ResNets are robust to exploding and vanishing gradients because each residual block is able to pass signals directly through, allowing the signals to be propagated faithfully across many layers. As displayed in Figure 1, residual functions for image recognition generally consist of stacked batch normalization ("BN") [12], rectified linear activation ("ReLU") [21] and convolution layers (with filters of shape three "C3" and one "C1").
As in He et al. [11], we use two residual block architectures: the basic residual function (Figure 1 right-top) and the bottleneck residual function (Figure 1 right-bottom). The bottleneck residual consists of three convolutions, the first is a point-wise convolution which reduces the dimensionality of the feature dimension, the second is a standard convolution with filter size 3, and the final point-wise convolution projects into the desired output feature depth.

2.3. Reversible Architectures
Various reversible neural net architectures have been proposed, though for motivations distinct from our own. Maclaurin et al. [19] made use of the reversible nature of stochastic gradient descent to tune hyperparameters via gradient descent. Our proposed method is inspired by nonlinear independent components estimation (NICE) [8, 9], an approach to unsupervised generative modeling. NICE is based on learning a non-linear bijective transformation between the data space and a latent space. The architecture is composed of a series of blocks defined as follows, where x1 and x2 are a partition of the units in each layer:

Because the model is invertible and its Jacobian has unit determinant, the log-likelihood and its gradients can be tractably computed. This architecture imposes some constraints on the functions the network can represent; for instance, it can only represent volume-preserving mappings. Follow-up work by Dinh et al. [9] addressed this limitation by introducing a new reversible transformation:

Here, ⊙ represents the Hadamard or element-wise product. This transformation has a non-unit Jacobian determinant due to multiplication by exp (F(x1)).
3. Methods
We now introduce Reversible Residual Networks (RevNets), a variant of Residual Networks which is reversible in the sense that each layer’s activations can be computed from the next layer’s activations. We discuss how to reconstruct the activations online during backprop, eliminating the need to store the activations in memory.
3.1. Reversible Residual Networks
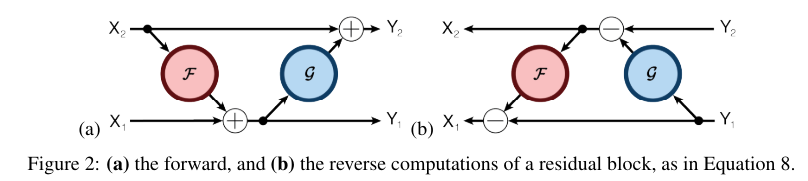
RevNets are composed of a series of reversible blocks, which we now define. We must partition the units in each layer into two groups, denoted x1 and x2; for the remainder of the paper, we assume this is done by partitioning the channels, since we found this to work the best in our experiments.2 Each reversible block takes inputs (x1, x2) and produces outputs (y1, y2) according to the following additive coupling rules – inspired by NICE’s [8] transformation in Equation 4 – and residual functions F and G analogous to those in standard ResNets:

Each layer’s activations can be reconstructed from the next layer’s activations as follows:

Note that unlike residual blocks, reversible blocks must have a stride of 1 because otherwise the layer discards information, and therefore cannot be reversible. Standard ResNet architectures typically have a handful of layers with a larger stride. If we define a RevNet architecture analogously, the activations must be stored explicitly for all non-reversible layers.
4. Conclusion
We introduced RevNets, a neural network architecture where the activations for most layers need not be stored in memory. We found that RevNets provide considerable gains in memory efficiency at little or no cost to performance. As future work, we are currently working on applying RevNets to the task of semantic segmentation, the performance of which is limited by a critical memory bottleneck — the input image patch needs to be large enough to process high resolution images; meanwhile, the batch size also needs to be large enough to perform effective batch normalization (e.g. [34]). We also intend to develop reversible recurrent neural net architectures; this is a particularly interesting use case, because weight sharing implies that most of the memory cost is due to storing the activations (rather than parameters). We envision our reversible block as a module which will soon enable training larger and more powerful networks with limited computational resources.
'Research > Generative Model' 카테고리의 다른 글
Normalizing Flows Tutorial, Part 2: Modern Normalizing Flows (0) 2024.05.16 Normalizing Flows Tutorial, Part 1: Distributions and Determinants (0) 2024.05.16 Variational Inference with Normalizing Flows (0) 2024.05.15 [Gated PixelCNN] PixelCNN's Blind Spot (0) 2024.05.14 Pixel Recurrent Neural Networks (0) 2024.05.14