-
Brief Summary of Prior Studies before Mamba 2*NLP/extra 2024. 9. 9. 18:21
※ (1st version - Sep 10, 2024 @Soyoung, Park)
This is my first summary of Mamba related works. So it's not complete, and written without clear distinction between my writing and the content cited in the paper.
※ I'm planning to work on it again later.
1. Long Range Arena: A Benchmark for Efficient Transformers (2020)
https://arxiv.org/pdf/2011.04006
"Transformers do not scale very well to long sequence lengths largely because of quadratic self-attention complexity."
Given the proliferation of efficient alternatives to Transformers that were emerging at the time, this work proposed a benchmark specifically focused on evaluating model quality under long context scenarios.
Long ListOps
In this task, we are interested in the capability of modeling hierarchically structured data in a long-context scenario.
The dataset is comprised of sequences with a hierarchical structure and operators MAX, MEAN, MEDIAN and SUM MOD that are enclosed by delimiters (brackets). An example (much shorter) sequence is as follows:
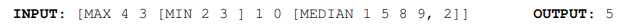
In our task we use a version of ListOps of sequence lengths of up to 2K to test the ability to reason hierarchically while handling long contexts. Naturally, in the above example the model needs to access all tokens and model the logical structure of the inputs in order to make a prediction. The task is a ten-way classification task and is considerably challenging.
PathFinder-X (Long-Range Spatial Dependencies with Extreme Lengths)
Finally, we consider an extreme version of Pathfinder (Pathfinder-X) where examples consist of 16K pixels (i.e., images of 128 × 128).
The key goal here is to observe if a model would fail to solve the 16K extreme version even if it can successfully learn the standard version of 1024 tokens. This is an interesting litmus test to see if the same algorithmic challenges bear a different extent of difficulty when sequence lengths are much longer. We include this in our benchmark as PathX.

Overall Results: No One-Size-Fits-All
For the first time, we conduct an extensive side-by-side comparison of ten recently proposed efficient Transformer models. The experimental results show that these tasks are very challenging even for long-range Transformer models. The overall results show that there is no one-size-fits-all solution and trade-offs have to be made in terms of model quality and speed/memory.

Transformer의 고질병, quadratic 연산량 때문에 long sequence를 처리하기 힘든 거 어떻게 할겨?
우리가 "Long Range Arena"라는 지표를 만들었어. 제대로 해결책을 찾아보자.
"우리에게는 신박한 Architecture가 필요하다."
"Recurrent Network는 sequence length에 linear하다. RNN으로 돌아가보자."
2. Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks (2019)
- A creative approach tackling the long range dependency problem
"We propose a novel memory cell for recurrent neural networks that dynamically maintains information across long windows of time using relatively few resources. The Legendre Memory Unit (LMU) is mathematically derived to orthogonalize its continuous-time history – doing so by solving d coupled ordinary differential equations (ODEs), whose phase space linearly maps onto sliding windows of time via the Legendre polynomials up to degree d − 1."
Legendre Memory Units
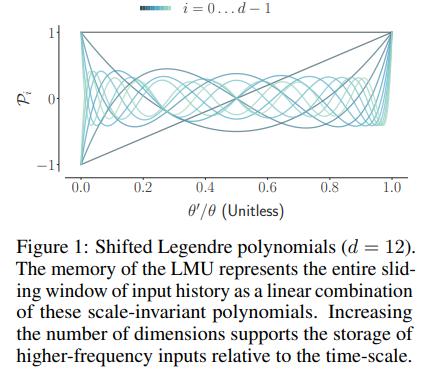

This idea can then be baked into a layer where the memory block is implemented with simple linear operations.

어떻게 이 아름다운 걸 Neural Network에 녹여낼 생각을 했지?
한강의 흐름을 거슬러 올라가다 보면, 물이 솟는 발원지가 있잖아.
SSM의 시발점 (수원지)는 Legendre Memory Unit 인 거 같아.
Legendre Memory Unit이 쏘아올린 작은 공을 HiPPO가 받고, 그걸 다시 S4가 받아서 이어지는 흐름이 무척 아름답다.
3. HiPPO: Recurrent Memory with Optimal Polynomial Projections (2020)
https://arxiv.org/pdf/2008.07669
Building on the above idea and others, HiPPO had the insight that "we can phrase memory as a technical problem of online function approximation where a function is summarized by storing its optimal coefficients in terms of some basis functions".
Using this insights, the authors constructed a simple model based on the Legendre polinomials that worked well on tasks like permuted MNIST outperforming other sequence model-based baselines like LSTM and Dilated RNN.
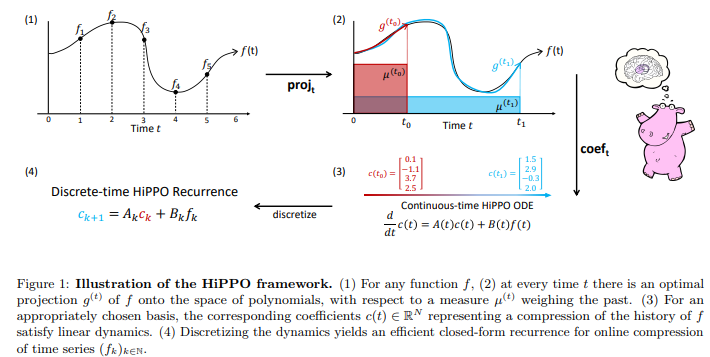
HiPPO는 history를 state에 compression할 수 있는 방법을 도입했다.
4. Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers (2020)
https://arxiv.org/pdf/2110.13985
Following work proposed a unifying framework for sequence modeling based on a standard State Space representation.

This work showed how starting from an implicit continuous time State Space model, discretize to produce a system that can be interpreted as a Recurrent Network with the benefit of efficient inference or as a Convolutional model which benefits from parallelizable training.

Unfortunately, a naive implementation of these models requires a massive amount of memory. In fact for reasonably sized models such as when the state dimension is 256, the LSSL(linear state space layer) uses orders of magnitude more memory than comparably-sized RNN's or CNNs.
LSSL은 SSM을 Recurrent하게도, Convolutional하게도 표현이 가능하게 함으로써, training /inference 시에 각각의 장점을 취할 수가 있게 했다.
5. Efficiently Modeling Long Sequences with Structured State Spaces (2021)
https://arxiv.org/pdf/2111.00396
A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of 10000 or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state space model (SSM) x' (t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t), and showed that for appropriate choices of the state matrix A, this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space sequence model (S4) based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning A with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks.

Training SSMs: The Convolutional Representation

Diagonalization
The authors discuss diagonalization. Unfortunately, it cannot be used directly for the HiPPO matrix due to numerical issues specifically it has entries exponentially large in these State size.
However we can address the HiPPO matrix with an adjustment. The authors note that although the HiPPO matrix is not normal, it can be decomposed as the sum of a normal and low-rank matrix. This is still not useful by itself and additional three new techniques are needed.
First, instead of computing the kernel K_bar directly, they instead compute its spectrum, then determine K_bar by applying an inverse FFT.
Next, we use low-rank trick, the Woodbury identity that let us perform an efficient matrix update.
Third, it is shown that the diagonal matrix case is equivalent to the computation of a Cauchy kernel, a well-studied problem with stable near linear algorithms.
All of this comes together in Theorem 3.
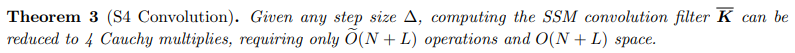
Empirically the proposed S4 architectures does very well on the long range Arena even doing well on the PATH-X task where the model must determine if two points are connected on a fairly large image. This task is not too hard when the input is arranged as an image but it's pretty difficult when it's a flattened sequence as evidenced by the fact that many other models fail on this task.

S4는 실질적으로 연산이 가능하도록 했다.
6. Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2024)
https://arxiv.org/pdf/2312.00752
This work builds on the state space model approach with a few key contributions.
First, a Selection Mechanism. Since previous state space models lack the ability to efficiently select data in an input dependent manner, they design a simple selection mechanism by parameterizing the SSM parameters based on the input.
Unfortunately, this change makes it hard to use the efficient convolutional trick in S4.
So, the second contribution is, a Hardward-aware Algorithm that computes the model recurrently with a scan instead of convolution. This leads to an implementation that is faster than previous methods both in theory (scaling linearly in sequence length, compared to pseudo-linear for all convolution based SSMs) and on moderm hardware (up to three times faster on A100 GPUs).
The third contribution is to simplify prior deep sequence model Architectures by combining the design of prior state space model architectures with the MLP block of transformers into a single block leading to a simple and homogeneous architecture design called Mamba that incorporates selective state spaces.
Motivation: Selection as a Means of Compression
The authors point out that you can view various sequence models as making different trade-offs when tackling a fundamental problem of sequence modeling. i.e. compressing context into a smaller state.
At one extreme, we have attention which is both effective and inefficient because it explicitly does not compress context at all.
At the other extreme, recurrent models are efficient because they have a finite state but their effectiveness is limited by how well this state has compressed the context.
To explore this trade-off, the authors focus on two synthetic tasks. One previously well-studied task is copying. The job of the model is to copy color sequences in the input into the output delayed by some constant offset. Standard convolutional models with fixed kernels can solve this without any problem.

The first of the harder tasks they consider is selective copying. This time we have random spaces symbolized by the white blocks in between the input sequence elements. To successfully copy the color outputs to the output while ignoring the white blocks, we need a mechanism that behaves differently at different inputs.
The second task they look at is induction heads. Here in order to predict the appropriate color at the question mark block, the model needs to be able to perform retrieval back over the input sequence based on the context provided by the black square in order to predict that blue is the next color in the sequence.

To build a model capable of solving these tasks, the models start from the S4 state space model which uses parameters A, B, C and Delta which don't depend on the input sequence.
Now for the proposed algorithm to allow the model to behave differently on different inputs, B, C and Delta are altered to be time varying. They now depend on the input sequence. This gives the model more power but means we can no longer use the efficient S4 convolution trick.
To get around this, the authors develop a selective scan based on hardware-aware state expansion.
In effect the two big challenges to be tackled once we give up on convolution are, the sequential nature of recurrence and the large memory usage.
There are three techniques that come into play. Kernel fusion, parallel scan and recomputation.
A key idea for getting around the sequential processing problem comes from 「Simplified State Space Layers for Sequence Modeling」 or S5 (2023) which highlighted the benefits of using parallel scans to maintain efficiency while avoiding the use of convolutional tricks used in S4.
Mamba uses this parallel scan idea in combination with efficient use of memory. In particular instead of preparing the scan input in GPU HBM(high bandwidth memory), they load the SSM parameters direct from the slow HBM(high bandwidth memory) to fast SRAM, where they perform the discretization and recurrence, then they write the final results back to HBM(high bandwidth memory).
Last, recomputation is used to reduce the memory requirements. This allows them to avoid saving the intermediate states which are necessary for backpropagation.
Putting this all together is
the selective state space model with hardware aware state expansion.
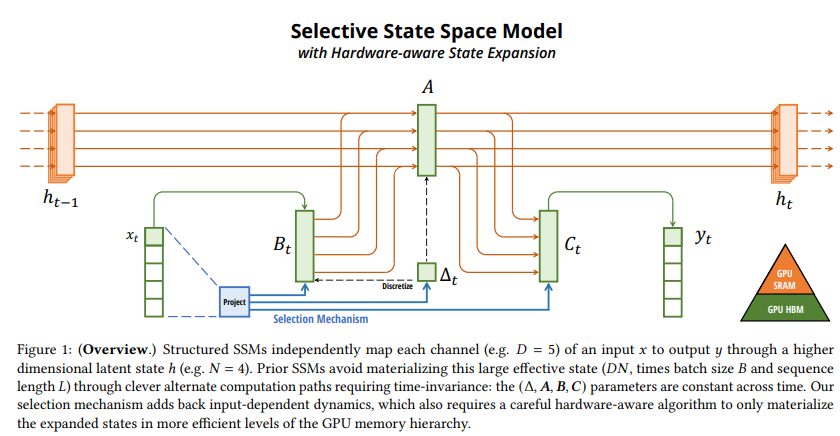
B_t, Delta_t and C_t all depend on the input X_t by the selection mechanism.
The parameters are loaded into fast GPU SRAM where the update is performed then the output is ultimately stored back into GPU HBM.
Simplified SSM architecture

The authors combine the Hungry Hungry HiPPO's block with a gated MLP block to produce their Mamba block. The shapes indicate that the dimensionality is expanded inside the block. This block is repeated and interleaved with standard normalization and residual connections to form the Mamba arhcitecture.
Empirical Evaluation
On the selective copying task, S6 works well with every architecture but S4 and Hyena work comparatively poorly.

On the induction heads task, Mamba succeeds on test sequence lengths of up to a million tokens, which is 4,000 times longer than it saw during training while none of the other methods compared to generalize to beyond twice their training length.

Experiments on language modeling which follow the training recipe described in the GPT3 work and train on the Pile dataset.
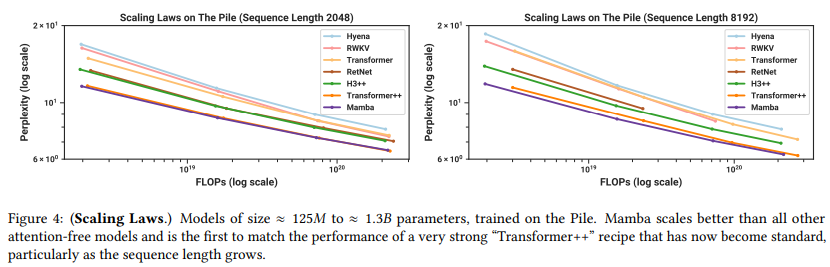
Across sequence length of 2048 and 8,192, Mamba outperforms the other baselines and matches transformer++ which represents the strongest transformer recipe that the authors know of based on the Palm and Llama architectures that means ratary embedding, SwiGLU MLP, RMSNorm instead of LayerNorm, no linear bias and higher learning rates.
On zero shot downstream evaluations, there are lots of comparisons. Generally, Mamba ahcieving an average accuracy of baselines at twice the model size.

Speed and memory benchmarks. The authors provide an implementation of the scan operation that is pretty fast they compare the scan versus convolution and attention on an A100 GPU. Their implementation is considerably below the other mechanisms at longer sequence lengths.
In terms of inference throughput where higher is better, Mamba achieve five times higher throughput than Transformers benefiting from its recurrent nature.
Limitations
The authors highlight that there is no free lunch. On the Continous-Discrete Spectrum, the selection mechanism overcomes the weaknesses of prior SSMs on discrete modalities such as text and DNA but this can impede their performance on data that LTI SSMs excel on which we saw with the audio oblation.
They also note that the empirical evaluation is limited to small model sizes, below the threshold of most strong open-source LLMs. Therefore it ramins to assess whether Mamba still compares favorably at larger sizes.
'*NLP > extra' 카테고리의 다른 글
Simplifying S4 (0) 2024.09.12 Mamba: The Easy Way (0) 2024.09.12 The Annotated S4 (0) 2024.09.09 MAMBA and State Space Models Explained (0) 2024.06.01 A Visual Guide to Mamba and State Space Models (0) 2024.05.30