-
[Q][Deep Ensembles] Simple and Scalable Predictive Uncertainty Estimation using Deep EnsemblesBayesian 2025. 7. 3. 11:29
※ Below is just my personal opinion (not validated)
어지간하면 ensembles로 prediction accuracy를 높일 수 있다는 건 잘 알려진 테크닉이다.
그렇기 때문에, Kaggle과 같은 competition에서는 미세한 점수 차이로 순위가 갈릴 때 보통 ensemble로 마른 수건을 짜내곤 한다.
그런데 놀라웁게도, ensembles은 prediction accuracy 뿐만 아니라, uncertainty estimation에서도 bayesian method보다 좋은 performance를 보여준다.
여기서 좋다는 의미는 여러가지가 있는데, 모르는 걸 모른다고 잘 말하는 것 뿐만 아니라, 구현이 쉽고 large-scale에도 적용이 가능하다.
그렇다면 그간의 Bayesian approach는 무색해지는 걸까?
어떤 차이가 있을까.
bayesian approach에서는 weight distribution을 구하기 위한 온갖 방법을 고안해낸다.
그렇게 하기 위해서 training procedure를 지지고 볶고 한다.
그런데 이것은 궁극적으로 posterior predictive distribution을 구하기 위함이다.
deep ensembles에서는 그런 수고가 필요하지 않다.
model이 well-calibrated output을 내도록 training시키면서,
(중요한 점은 probabilistic한 부분이 여기에 들어왔다는 것이다. NLL)
동시에 data를 noisy하게 만들어서, 직접적으로 predictive distribution을 만들어낸다.
그렇다면 weight distribution은 필요하지 않은 것일까?
weight distribution의 의미는 무엇일까. 생각해볼 필요가 있다.
그리고 왜 deep ensembles이 bayesian method보다 uncertainty estimation을 잘 하는지를 생각해 볼 필요가 있다.
여기서 생각해볼 수 있는 것은, 사실 각각의 M개의 model 또한 weight distribution에서 sampling 된 version이라고 볼 수 있다는 사실이다.
만약 local optimum이 여럿이라면 독립적인 M개의 model은 서로 다른 basin에 존재할 수 있다.
하지만 bayesian에서의 weight distribution은 하나의 optimum 주변은 맴돈다.
이건 loss surface (landscape)를 살펴보아야 확인할 수 있을 것 같다.










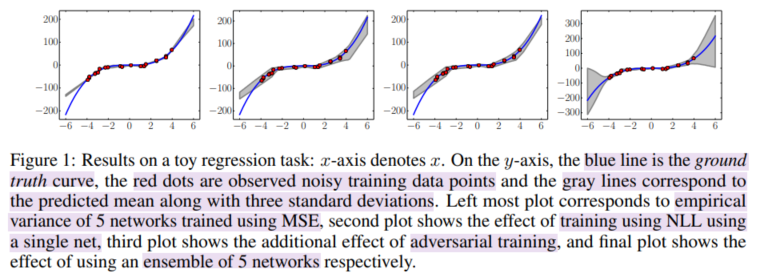


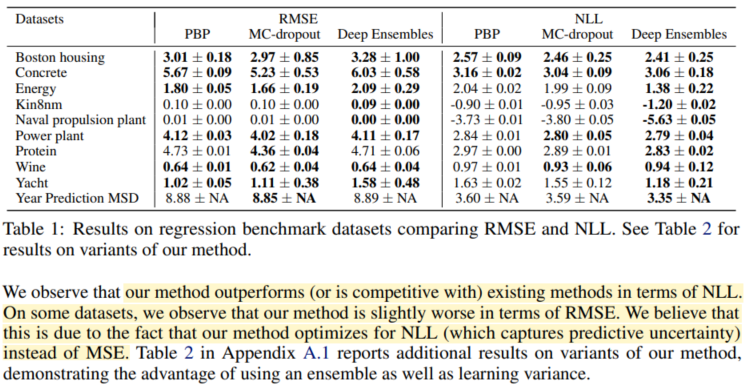


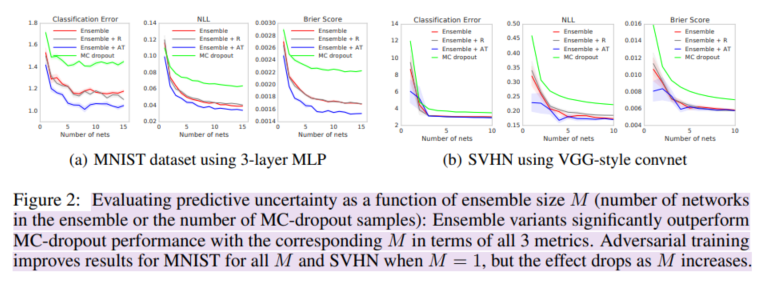



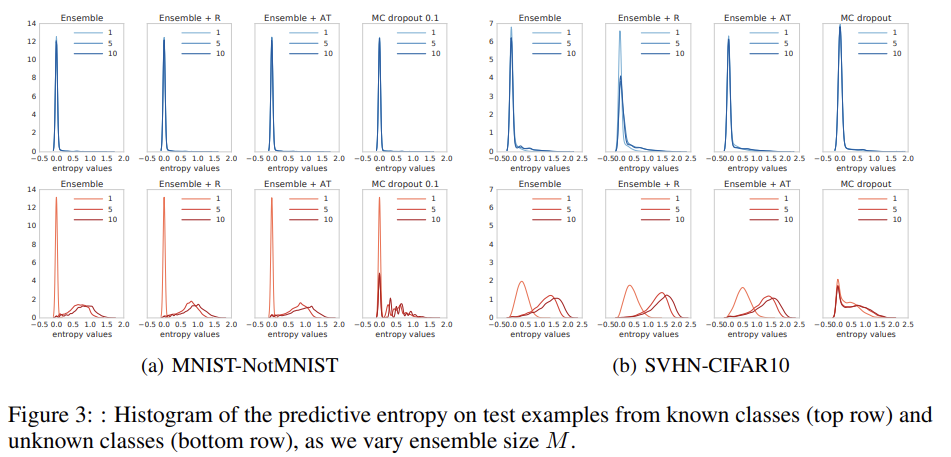







'Bayesian' 카테고리의 다른 글
Notes - Bayesian Optimization (0) 2025.12.04 [A][Deep Ensembles] A Loss Landscape Perspective (0) 2025.07.03 [SWAG] A simple Baseline for Bayesian Uncertainty in Deep Learning (0) 2025.07.01 Deep Networks are Kernel Machines (0) 2025.07.01 Deep Neural Networks as Gaussian Processes (0) 2025.06.30