-
Deep Networks are Kernel MachinesBayesian 2025. 7. 1. 12:43
https://arxiv.org/pdf/2012.00152
* Neural Tangent Kernel
https://lilianweng.github.io/posts/2022-09-08-ntk/
Some Math behind Neural Tangent Kernel
Neural networks are well known to be over-parameterized and can often easily fit data with near-zero training loss with decent generalization performance on test dataset. Although all these parameters are initialized at random, the optimization process can
lilianweng.github.io
https://www.youtube.com/watch?v=_vk_82dNMNI
↑ 강추! NTK가 가지는 의미를 분명하게 전달해주신다. background knowledge는 덤!
https://www.youtube.com/watch?v=DObobAnELkU&t=1399s
https://www.youtube.com/watch?v=btphvvnad0A&t=930s
https://www.youtube.com/watch?v=VUX2bsrYag8
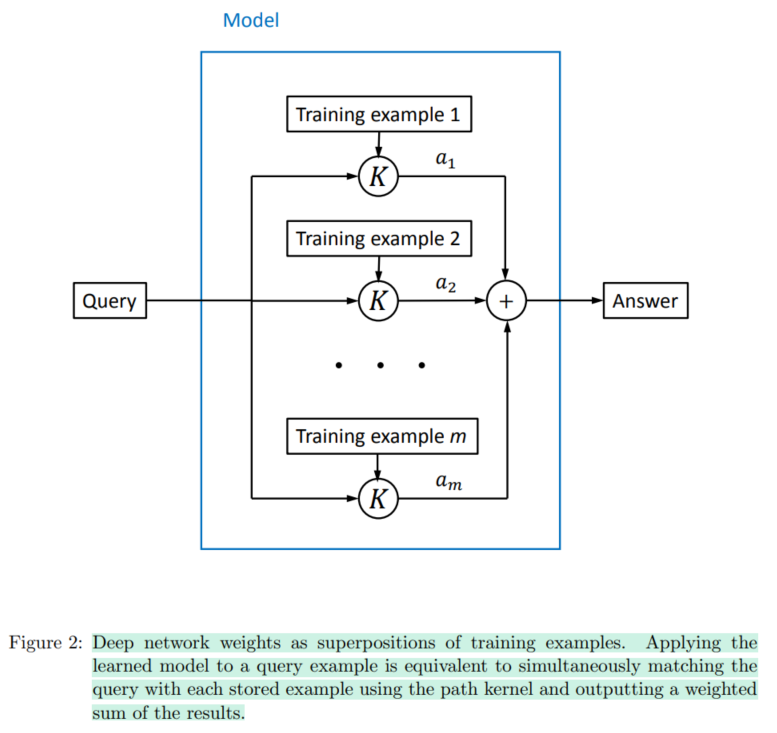
Every training datapoint 의 similarity (kernel ft - inner product between two datapoints)를 담고 있는 Gram matrix에 new datapoint 를 query 하여서 similarity 를 measure하는 건..
이거슨 어디서 많이 본 거 아닌감?
이건 Attention이잖아.
"그렇다면 attention도 kernel로 interprete할 수 있겠다. kernel 에 따라서 attention을 다르게 design하여서 inductive bias를 다르게 줄 수도 있겠다."
라는 생각이 자연스럽게 직관적으로 떠오르게 되네.
저만 그런거 아니죠?
분명 검색해보면 뭔가 나올 거라는 확신이 들었는데, 역시나 나온다! ㅎㅎ
흥미로운 논문들이 검색되었다.
(내가 짝사랑하는 분의 논문이 검색되어서 깜놀했다.)







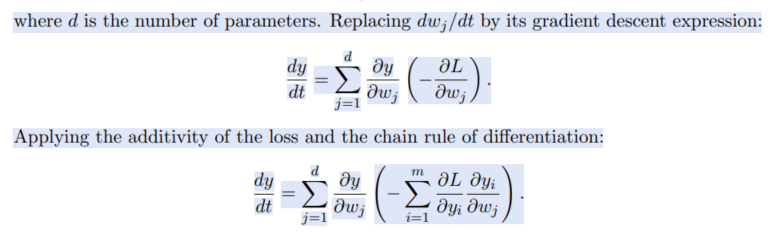







'Bayesian' 카테고리의 다른 글
[Q][Deep Ensembles] Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles (0) 2025.07.03 [SWAG] A simple Baseline for Bayesian Uncertainty in Deep Learning (0) 2025.07.01 Deep Neural Networks as Gaussian Processes (0) 2025.06.30 Kernel Methods (0) 2025.06.30 GP를 결정적으로 이해하게 된 (0) 2025.06.30